ES慢查询分析——性能提升6 倍
问题
? ? ? ? 生产环境频繁报警。查询跨度91天的数据,请求耗时已经来到了30+s。报警的阈值为5s。

背景
查询关键词简单,为‘北京’
单次仅检索两个字段
查询时间跨度为91天,覆盖数据为450亿数据
问题分析
使用profle分析,复现监控报警的语句,确实慢。集群分片太多,这里放一个分片的内容。
{
"id" : "[YWAxM5F9Q0G1PXfTtYZKkzQ][_20230921-000001][3]",
"searches" : [
{
"query" : [
{
"type" : "FunctionScoreQuery",
"description" : "function score (+((title:北京)^2.0 | content:北京) +publish_time:[1687431307000 TO 1695254417999] +es_insert_time:[-9223372036854775808 TO 1703084327999], functions: [{scriptScript{type=stored, lang='null', idOrCode='search-score', options=null, params={}}}])",
"time" : "10s",
"time_in_nanos" : 10079315883,
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 150,
"shallow_advance_count" : 0,
"set_min_competitive_score" : 0,
"next_doc" : 2646164,
"match" : 996954485,
"next_doc_count" : 154,
"score_count" : 31,
"compute_max_score_count" : 0,
"compute_max_score" : 0,
"advance" : 1035917137,
"advance_count" : 16,
"score" : 3532211704,
"build_scorer_count" : 40,
"create_weight" : 3965124112,
"shallow_advance" : 0,
"create_weight_count" : 1,
"build_scorer" : 546462281
},
?
在Elasticsearch?Profile?API结果中,主要关注查询的time和breakdown字段,这提供了查询执行的总时间和各个步骤的时间分解。在这个例子中,查询的总时间为10秒。
具体来看,主要的时间花费在FunctionScoreQuery的create_weight步骤上,该步骤耗时为3,965,124,112纳秒(大约3.97秒)。create_weight是在查询执行之前创建用于评分的权重的阶段。
以下是一些步骤的关键信息:
- create_weight步骤耗时最长,可能是性能瓶颈。
- build_scorer步骤也占用了大量时间,这通常是评分过程中的一个重要步骤。
- next_doc步骤的时间比较大,这可能涉及到遍历文档的过程。
疑问?为什么?create_weight?过程耗时会这么长
从我的查询条件来看,请求是很简单的,没有复杂的条件,为什么?create_weight?过程耗时会这么长?
create_weight阶段的耗时主要取决于查询中使用的权重计算方式以及索引的结构和数据量。在你提供的Profile?API结果中,create_weight的耗时非常大,说明这个步骤在整个查询过程中占用了大量的时间。
有几个潜在的原因可能导致create_weight步骤的性能下降:
- 脚本复杂性:?如果你在Function?Score?Query中使用了复杂的脚本,脚本的执行可能会消耗大量的时间。检查你的脚本逻辑,尽量确保它是高效的。
- 文档数和大小:?如果你的索引中包含大量的文档或者文档非常大,创建权重可能会变得更加耗时。在这种情况下,考虑优化索引结构、调整分片数量等。
- Function?Score?Query的配置:?如果在Function?Score?Query中使用了复杂的函数或者过多的函数,计算每个文档的权重可能会更加耗时。检查你的Function?Score?Query配置,确保它符合你的需求。
create_weight?究竟在干什么,源码?
这里主要是lucene去IO底层文件。这里比较明显的是性能问题。
第一个尝试,去掉脚本排序
脚本排序的时间会算在create_weight过程中(猜想,待验证)
测试把我的搜索条件,去掉脚本排序。原来是15s,现在是10s,脚本排序的耗时在我请求中,占据了30%多。
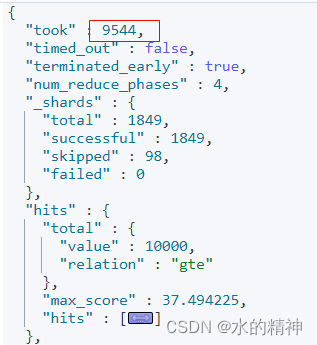
继续分析慢查询的分片
其中,耗时最长的分片还是,create_weight?过程耗时最严重。
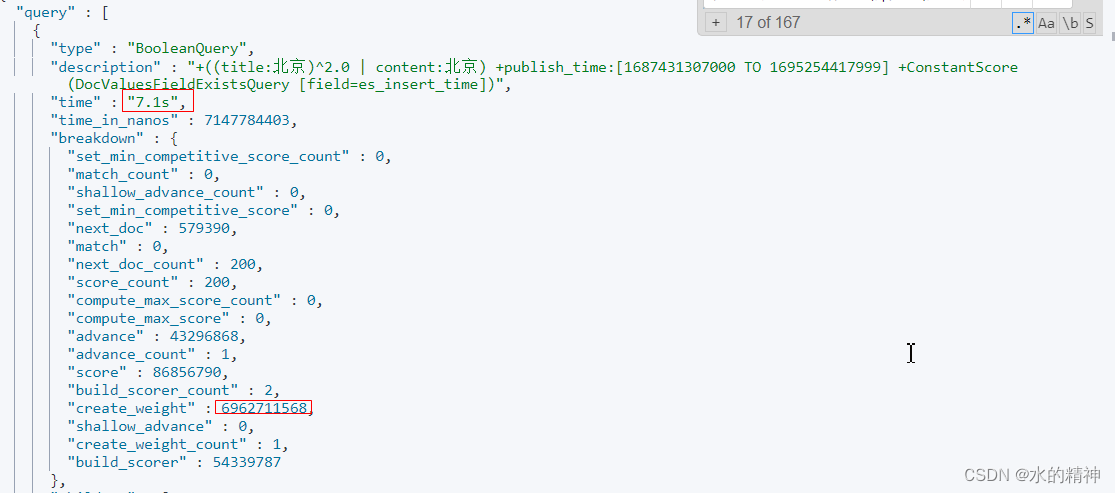
耗时发生在我的title字段上的这个子查询上。
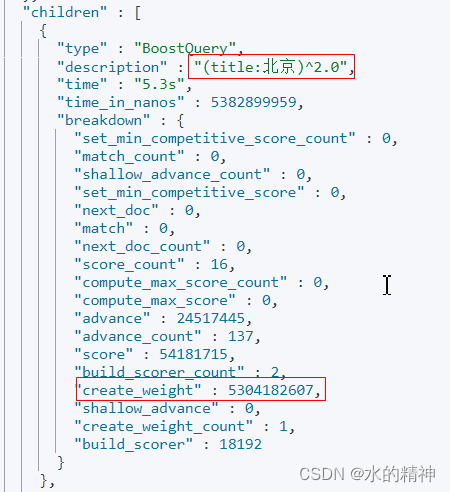
调整terminate_after??从200->10
检索耗时进一步降低。
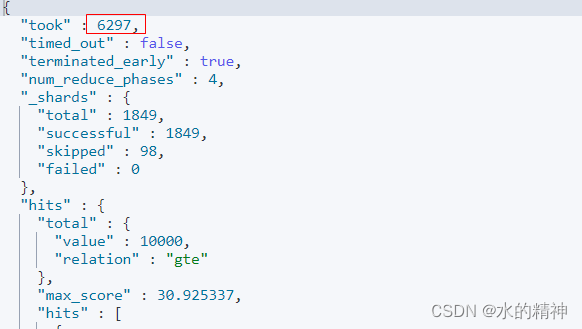
其中还是有耗时长的个别分片
整个请求6.2s,在这个分片上的请求就花了6s,并且时间还是花在了create_weight上。
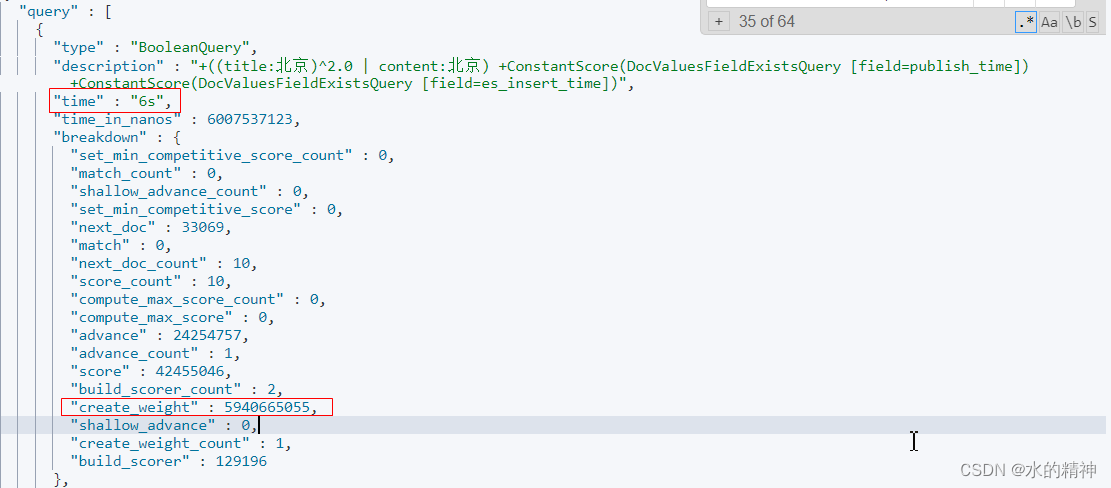
如何才能降低create_weight的耗时?
降低terminate_after的值可以降低,代价是影响整体的排序效果。
减少段的个数,可以减少耗时。通过段合并。因为可以减少段的遍历。
?
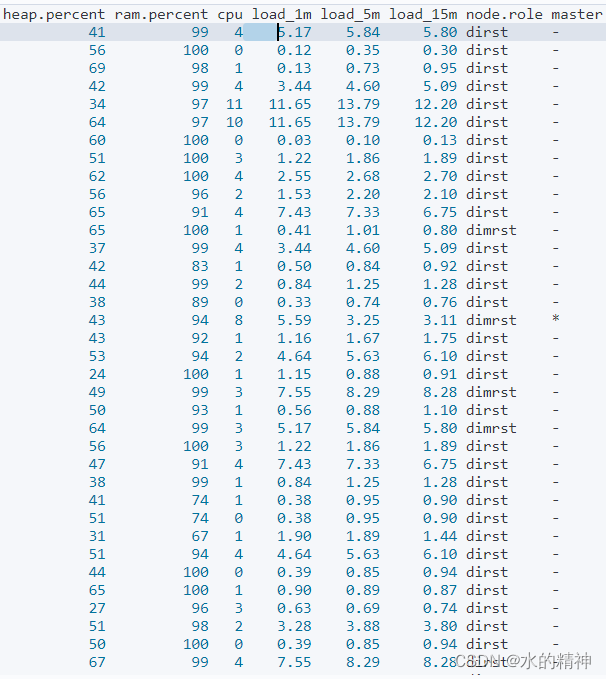
疑问?是不是在查询的时候负载高?
GET?_cat/nodes?v
问题解决方案
动态调整terminate_after
??并非所有的请求,都需要每个分片都200条数据。特别在大的时间跨度下,分片可能会非常多,动辄几千个,以2000个分片算,最多会匹配2000*200=400000数据。加上脚本排序,这40W数据,都需要参与分数的计算,最终才能角逐出top20的数据。最终的结果是请求耗时长。
??实际上,terminate_after的取值,是可以动态调整的。检索分为乐观和悲观情况,乐观情况下,数据分布是均匀的,在分片上分配是均匀的,且检索条件命中的数据较多。在悲观情况下,检索的数据分布不均匀,且搜索的条件比较特殊,命中的数据很少,或者命中的数据在分片上分布不均匀。
??大多数情况下,数据分布是均匀的,检索的数据量越大,分布可能越均匀。例如检索3个月,总数据大约450亿数据,随便一个搜索条件,搜索的数据大概率是大于10000条的。所以可以设计一个动态调整方案,来调整terminate_after的取值,能够获取更好的性能,提升200%-300%。另外需要一个悲观情况下的担保机制,避免在悲观情况下检索丢失数据。
??terminate_after的值是限定在分片上的,假如一个索引有10个分片,如果设置terminate_after为200,则最后返回的数据总量为?10*200=2000条。考虑到分页为500页,每页20条数据,共计可以翻页10000条数据。如何设置terminate_after的值呢?要考虑到翻页的情况。
??请求的入参,一般包含了翻页和每页的条数。?期望数据总量=?页码*?每页的数量。??es的召回总量为=?分片数*terminate_after数量*偏差。偏差可以算0.1,预期10倍可以弥补数据分布不均匀带来的影响。分片数暂时可以按每天15个来算。?页码*?每页的数量?=?分片数*terminate_after数量*偏差?。可以得出??terminate_after数量?=?页码*?每页的数量?/?(分片数*偏差)。terminate_after数量不足10则向上取正为10。?当查询的天数小于7天,则可以直接取值为200。
??担保机制,需要解决悲观情况下的问题。根据es返回的数据总量。?如果返回的数据总量小于期望的数据总量,则触发担保机制。需要调大terminate_after的值(暂定为500),再去搜索一次。
索引段合并
??段合并可以提升减速效果。
最终的检索效果
检索条件
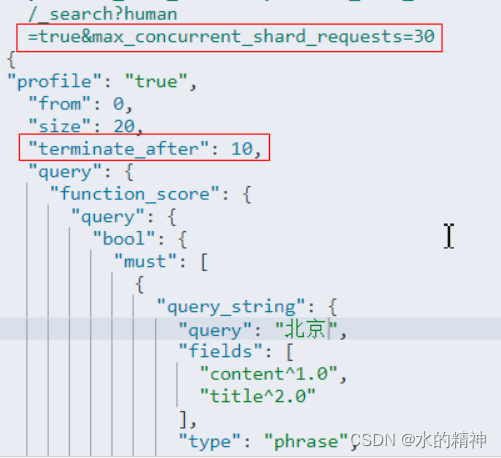
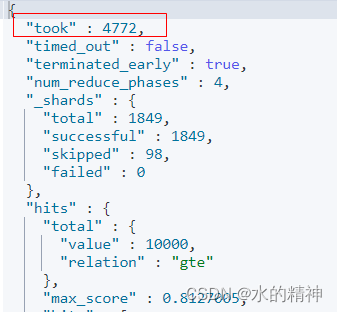
检索耗时情况
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 技术·责任·未来:一个前端开发者的2023年反思
- 程序员跳槽,HR 就喜欢听这样的离职原因。让老实人别再吃亏!
- Python之文件的相关操作
- 第二证券:证监会紧急声明!加密货币大笔爆仓
- 【js逆向】爬虫之进程,线程,协程
- 开发忙的团团转,往往都是研发效能惹的祸:你真的会写README.md吗?
- UVa1318/LA2797 Monster Trap
- 怎样实现安全便捷的网间数据安全交换?
- 深入理解Flutter中的GlobalKey与LocalKey(ValueKey、ObjectKey、UniqueKey)及其使用方法
- node-sass@4.14.1 postinstall: `node scripts/build.js`