程序媛的mac修炼手册--微博爬虫看江疏影如何被雪球套
呜呜呜,最近真是忙cry了,鸽了好久没来更新技术修炼博客了😭😭 以后如果还出现这种情况,说明我去放羊了,如果迟迟没更新,那一定是羊丢了,去找羊了~~
今天开始讲技术前,先对大A真爱粉们表示崇高敬意,连女明星江疏影都和大伙儿一起关灯吃面,前路依然光明,至于道路嘛,曲折折折······
好了,闲聊结束,今天就以大A真爱粉中的著名代表江疏影微博账号为例,给大伙儿安利怎样爬取微博数据。对于做社交媒体分析的朋友来说,这妥妥的刚需。
对于很多项目而言,学会在大神造的轮子上码注,是起飞第一步!!再说,正经人谁一上来就自造轮子啊,瞧这能耐地干脆从写汇编语言开始吧😒😒 开玩笑、开玩笑,咱不是忽悠大家去抄袭,而是说先用别人的轮子跑一跑,看能否实现一部分项目需求。在此基础上,再有针对性地编程,这项目开发效率不杠杠就上来啦!!
因此,咱们今天借鉴了GitHub上一个7.6k stars 的微博爬虫项目,项目本身已经非常完善了,只需要下载下来改改参数就行。不过由于大神是三年前上传的项目,有部分操作步骤需要更新一下下。接下来,就结合最新操作步骤更新给大家分享:
一. 安装微博爬虫程序
这部分,大神写地很详细了,最新安装不需要啥修改,参见Readme文档跟着步骤操作就行。
二. 程序设置
大神虽在“程序设置”部分写地很详细,但由于微博的反爬虫程序,因此有些步骤有一丢丢变动。
1. 获取微博user_id
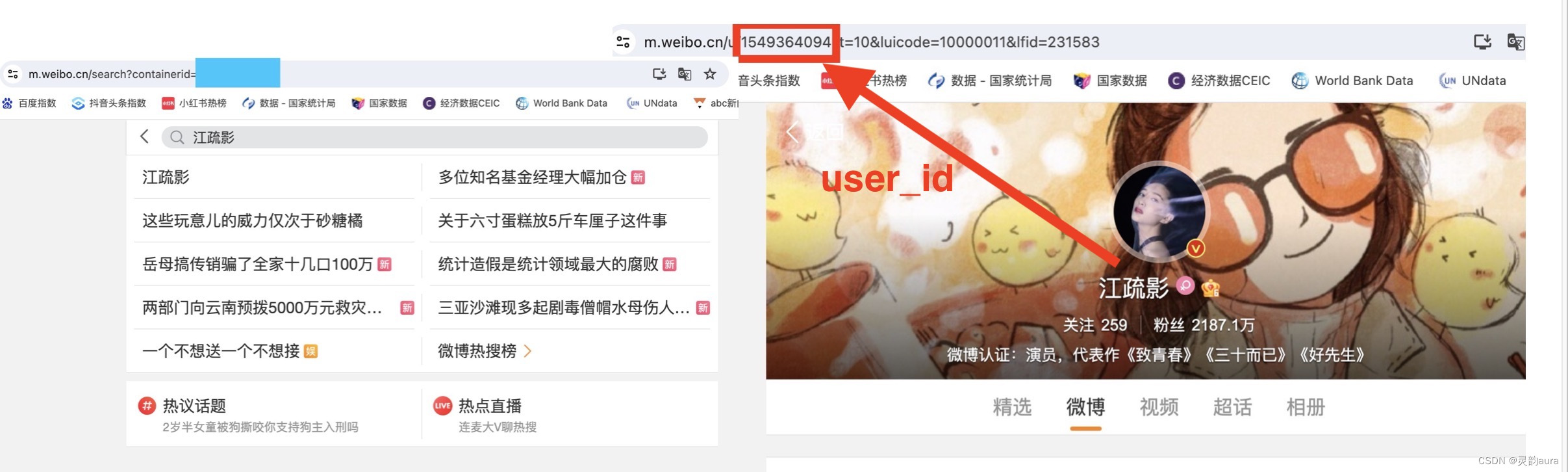
user_id就是目标爬取用户的微博ID。比如,咱今天爬取江疏影的微博,那首先就要找到江疏影的微博ID。我试了大神介绍的几种方法,总结发现最简单直接的方法就是,Chrome打开微博主页,网址:微博,直接在微博的搜索框里搜微博用户名,然后打开其首页,在主页的网页地址栏中找到一串纯数字形式的微博ID,如下图所示:
2. 程序设置中的config.json文档
除了user_id获取外,程序设置中的config.json文档中的?"filter"、?"since_date"、?"end_date"···"result_dir_name"等参数,可以参考大神的原文档。不过大神写的获取cookie方式需要更改一下下。
1)用Chrome打开登录 - 新浪微博;
2)输入微博的用户名、密码,登录,登录成功后会跳转到https://m.weibo.cn;
3)按F12键打开Chrome开发者工具,在地址栏输入并跳转到https://weibo.cn,跳转后会显示如下类似界面:?
4)此时需要点击Chrome开发者工具中的Network,找到name下的这个网址,然后点Headers->Request Headers找到"Cookie"
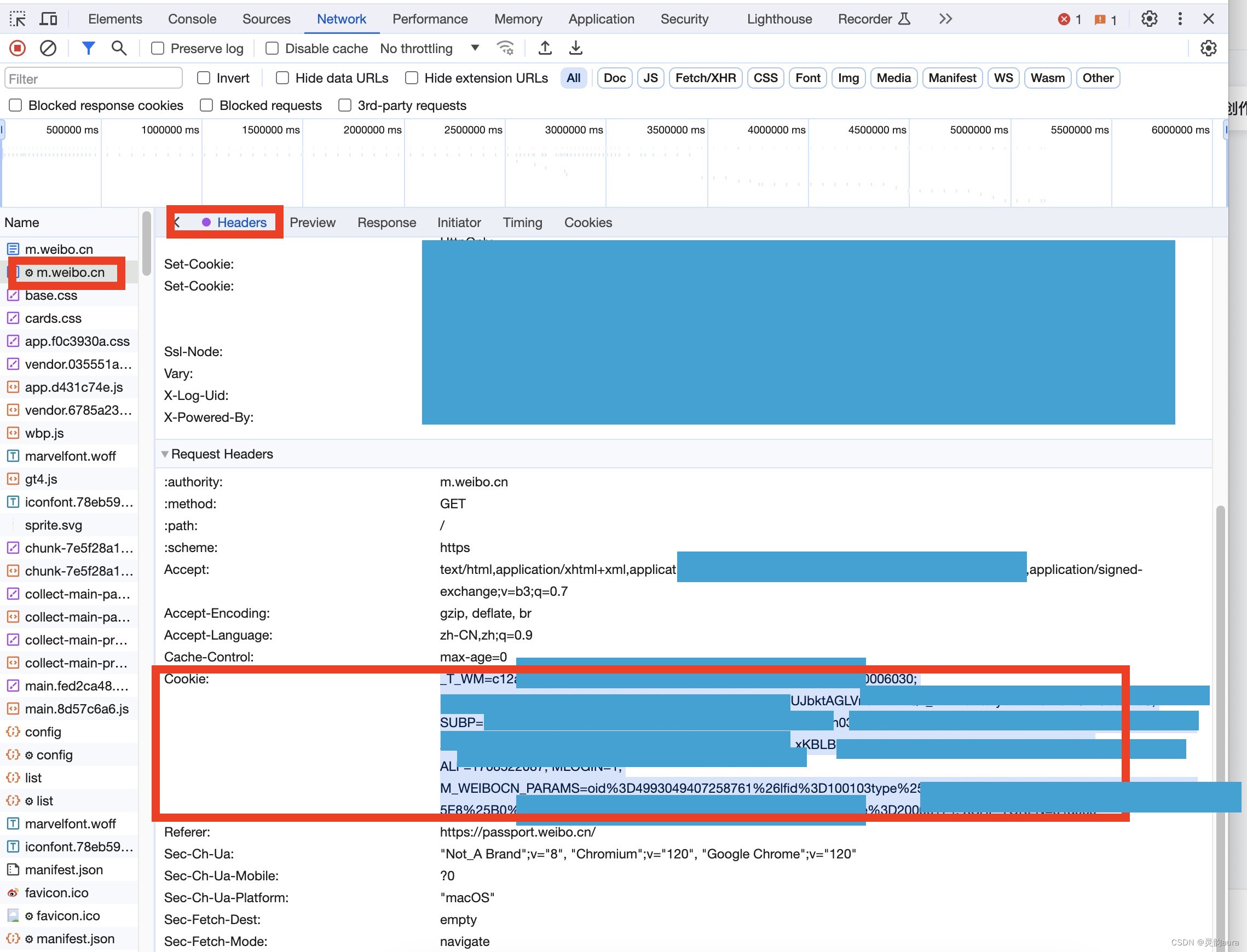
5)注意:粘贴的cookie值由于格式问题,不同字符串间有空格,需要手动排除一下。具体方式是,在cookie值字符串中的每一个分号;前,按一下删除键delete。
三.运行程序
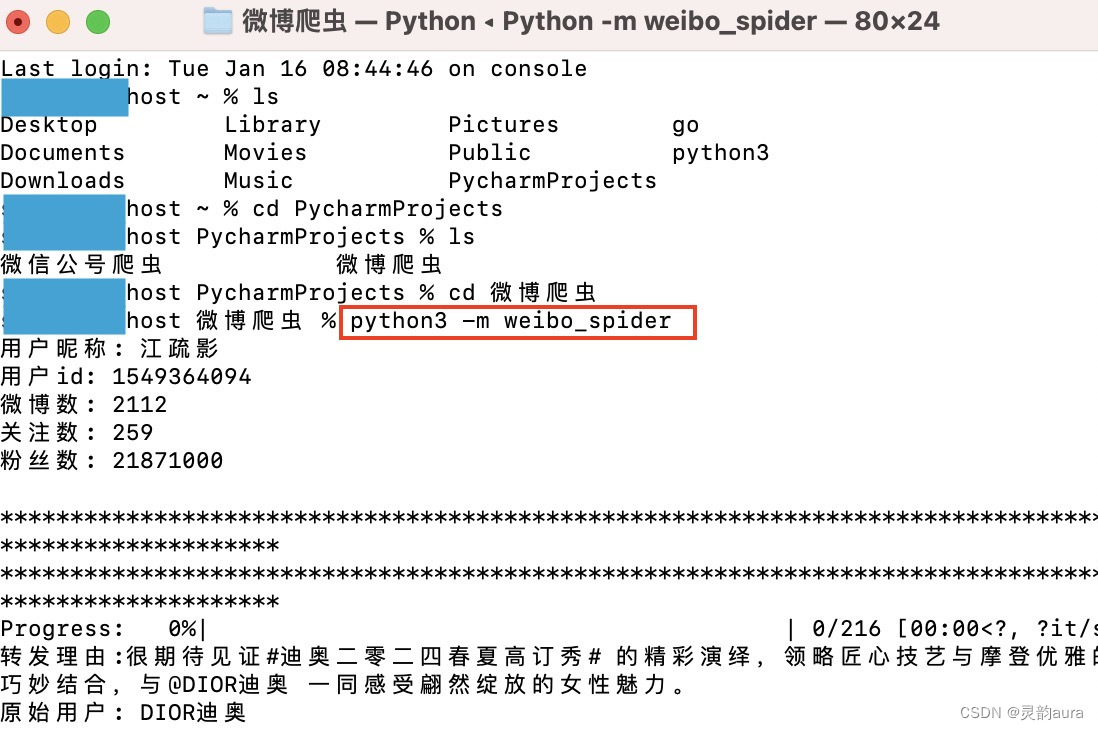
??参见原文档中的“程序运行”,跟着步骤操作就行。对于Mac用户而言,在「终端(terminal)」中依次打开文件目录,在weiboSpider目录下,输入以下命令:
python3 -m weibo_spider打开目标文件目录方式,如下图所示:
运行后,weiboSpider逐条爬取微博动态,按参数设置起始日期爬取结束后,「终端(terminal)」会显示完成,如下图所示:
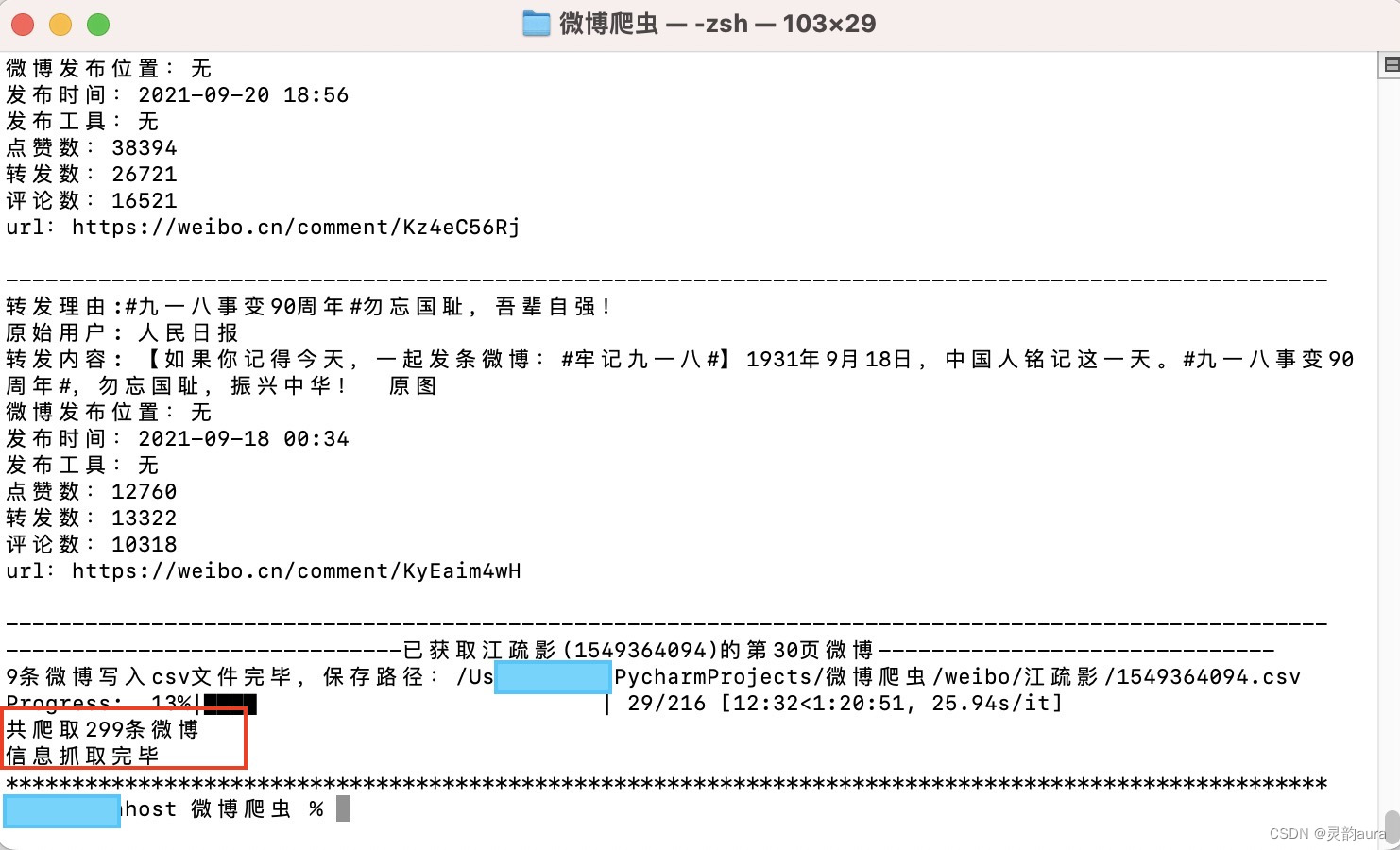
与此同时,weiboSpider目录下,会自动生成一个记录所爬数据结果的汇总文件夹叫“weibo"。
好了,咱今天爬江疏影微博数据,就在此刻大功告成啦!!明天和大家分享,如何分析微博数据,看江疏影是啥时候成为大A真爱粉的,敬请期待~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Linux驱动】驱动程序框架 | LED驱动
- pandas.DataFrame() 数据自动写入Excel
- 【GO语言卵细胞级别教程】02.GO变量和数据类型
- 接口测试是什么?为什么要做接口测试?
- VScode项目文件名变绿解决方法
- Python迭代器:告别循环嵌套,走向优雅编程
- 05鸿蒙APP开发之加载网络列表
- Wargames与bash知识08
- LabVIEW 2023下载安装教程,附安装包和工具,免费使用,无套路获取
- 黑客技术(网络安全)自学1.0