十六:爬虫-验证码与字体反爬
一:验证码
验证码(CAPTCHA)是一种计算机程序设计技术,用于确定用户是人类而不是机器。它通常表现为一种图像或声音,要求用户在输入框中输入正确的文本或数字来证明自己是人类。因为机器人和计算机程序无法像人类一样理解和解决这些问题,所以只有真正的人类用户才能通过验证码验证。当然随着技术的发展现在的验证码种类越来越多,不仅仅只限于输入正确的文本或数字还有点选、滑动、旋转,计算,选择等多种验证方式。
1.为什么会用到验证码
验证码(CAPTCHA)主要用于确定用户是人类而不是机器。在互联网上,机器人和计算机程序可以自动进行各种操作,例如恶意攻击、垃圾邮件、网络钓鱼等不良行为。为了保护网站和应用程序的安全,防止这些不良行为的发生,引入了验证码技术。
使用验证码有以下几个主要原因:
- 防止机器人攻击:机器人攻击是一种自动化的攻击手段,攻击者使用自动程序来尝试登录、注册、发送垃圾邮件等行为。验证码可以有效地防止机器人攻击,因为机器人无法像人类一样理解和解决验证码问题。
- 保护用户隐私:有些网站需要用户提供个人信息或数据,例如注册新账户、在线支付、订购商品等。为了保护用户的隐私和数据安全,网站可以使用验证码来确认用户是真实的人类用户,而不是机器人。
- 防止垃圾邮件和网络钓鱼:垃圾邮件和网络钓鱼是常见的网络安全威胁,攻击者通过自动化程序发送大量垃圾邮件或伪造网站来欺骗用户。验证码可以有效地防止这些不良行为,因为只有真正的人类用户才能通过验证码验证。
- 防止暴力破解:暴力破解是一种攻击方式,攻击者使用自动化程序尝试猜测用户账户密码。验证码可以防止暴力破解,因为攻击者无法通过自动化程序解决验证码问题。
- 防止机器人爬虫:机器人爬虫是一种通过自动化程序获取网站上数据和内容的方式。有些网站希望限制机器人爬虫,以保护他们的知识产权和商业利益。验证码可以防止机器人爬虫,因为只有真正的人类用户才能通过验证码验证。
- 提高用户体验:尽管验证码可能会对用户造成一些不便,但它可以提高用户体验和满意度。通过使用验证码,网站可以保护用户免受垃圾邮件、网络钓鱼和其他恶意攻击的侵害,同时提供更安全和可靠的服务。
- 支持无障碍访问:有些用户可能无法识别验证码中的图像或声音,例如盲人、聋人等。为了支持无障碍访问,一些网站提供替代形式的验证码,例如数学表达式、滑动验证等。
2.目前验证码的分类
验证码(CAPTCHA)可以按照不同的分类标准进行分类。以下是一些常见的验证码分类方式:
- 文字型验证码:文字型验证码通常是一组随机生成的字母或数字,用户需要在输入框中输入正确的答案。这种验证码的优点是易于实现和识别,但容易受到
OCR识别工具的攻击。 - 图片型验证码:图片型验证码通常是一张随机生成的图像,用户需要在输入框中输入正确的文字或数字。这种验证码的优点是更难受到
OCR识别工具的攻击,但用户可能需要花费更多的时间来识别和输入正确的答案。 - 数学表达式型验证码:数学表达式型验证码通常是一个数学表达式,用户需要在输入框中输入正确的答案。这种验证码的优点是易于实现和识别,同时可以提高用户的数学能力。
- 滑动型验证码:滑动型验证码通常是一张图片,用户需要在滑块上滑动以显示正确的答案。这种验证码的优点是易于实现和识别,同时可以提高用户的操作体验。
- 声音型验证码:声音型验证码通常是一段随机生成的语音,用户需要听取并在输入框中输入正确的答案。这种验证码的优点是适合视力较差或无法识别图像的用户,但可能对听力有一定要求。
除了上述分类方式,还有其他一些特殊类型的验证码,例如拼图型验证码、颜色型验证码、行为型验证码等。这些验证码根据具体的应用场景和需求进行设计和实现。
二:打码平台的使用
平时常用的打码平台有:超级鹰,云打码,打码兔,联众打码,超人打码,斐斐打码,91打码等。大家可以更加自己的需要自行选择。
1.打码平台进行打码步骤
使用第三方平台进行打码,通常需要四个步骤。我们这里使用超级鹰打码平台进行示范。
- 首先选择一个打码平台进行注册
- 由于不同平台,注册的流程不一样,这里不再截图演示。注册完成后,如果没有提供免费适用的功能,我们需要充值才能正确的使用接口。每个平台,都会有自己的开发文档,我们按照开发文档的示列进行改写就可以直接使用了。
- 需要进行充值
- 如果只是简单的测试,可以充值较小的金额,由于是第三方平台,无法保证网站是持久可用的,充值须谨慎。
- 获取网站的程序
ID- 充值完成后,我们会获得一个程序
ID,把这个ID放入到接口中,方便第三方平台进行校验。
- 充值完成后,我们会获得一个程序
- 上传验证码,返回调用结果。
2.超级鹰的具体使用步骤
超级鹰网址: https://www.chaojiying.com/price.html
1、https://www.chaojiying.com/user/login进入超级鹰登录页面注册账号
2、下载demo包点击开发文档,在各语言sdk例子下载下,下载所需的语言包。
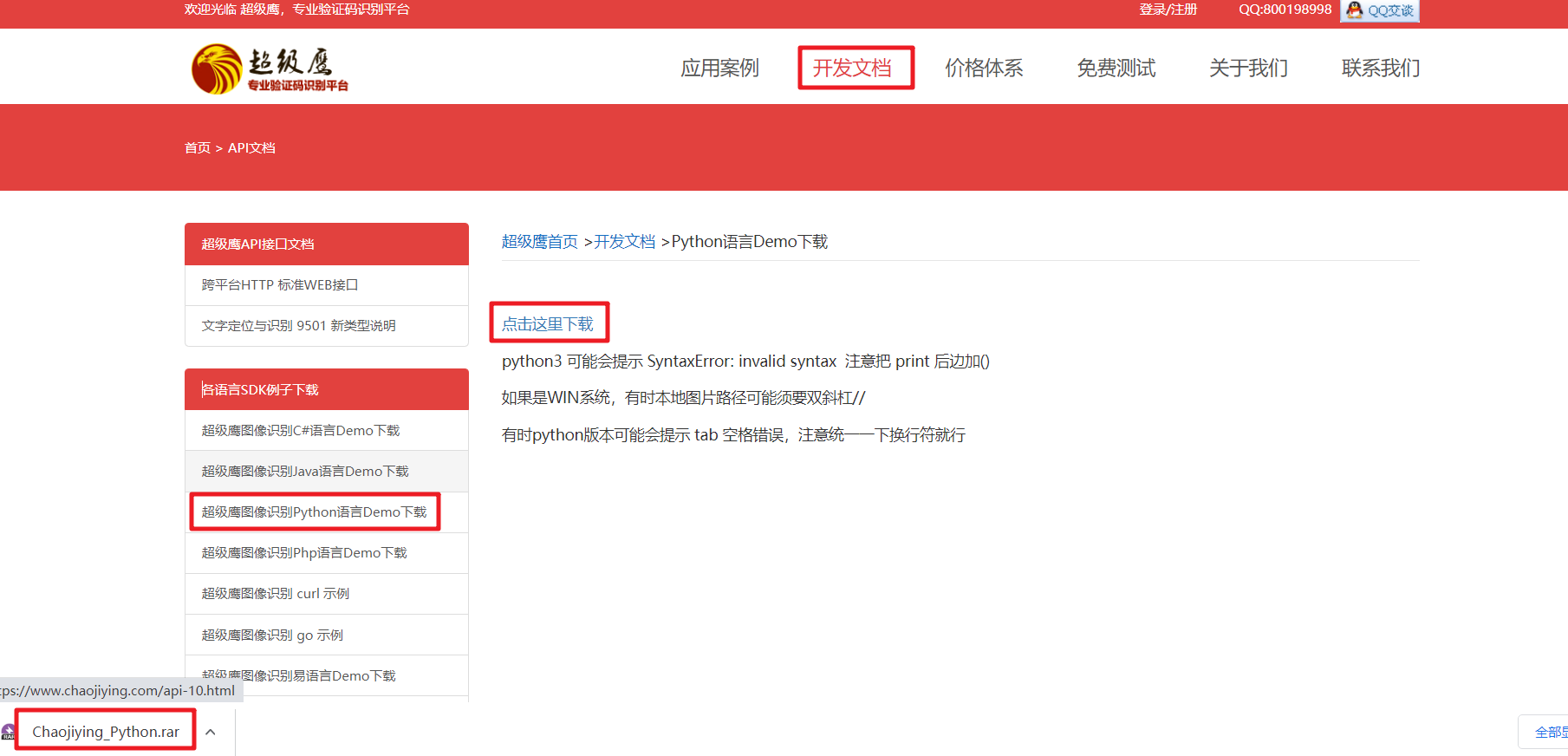
下载完成后解压会有一个chaojiying.py文件,将文件复制到你的项目下。复制完成如果你的python版本是2无需改动,如果是3,需要在print加上括号。

3、获取软件id
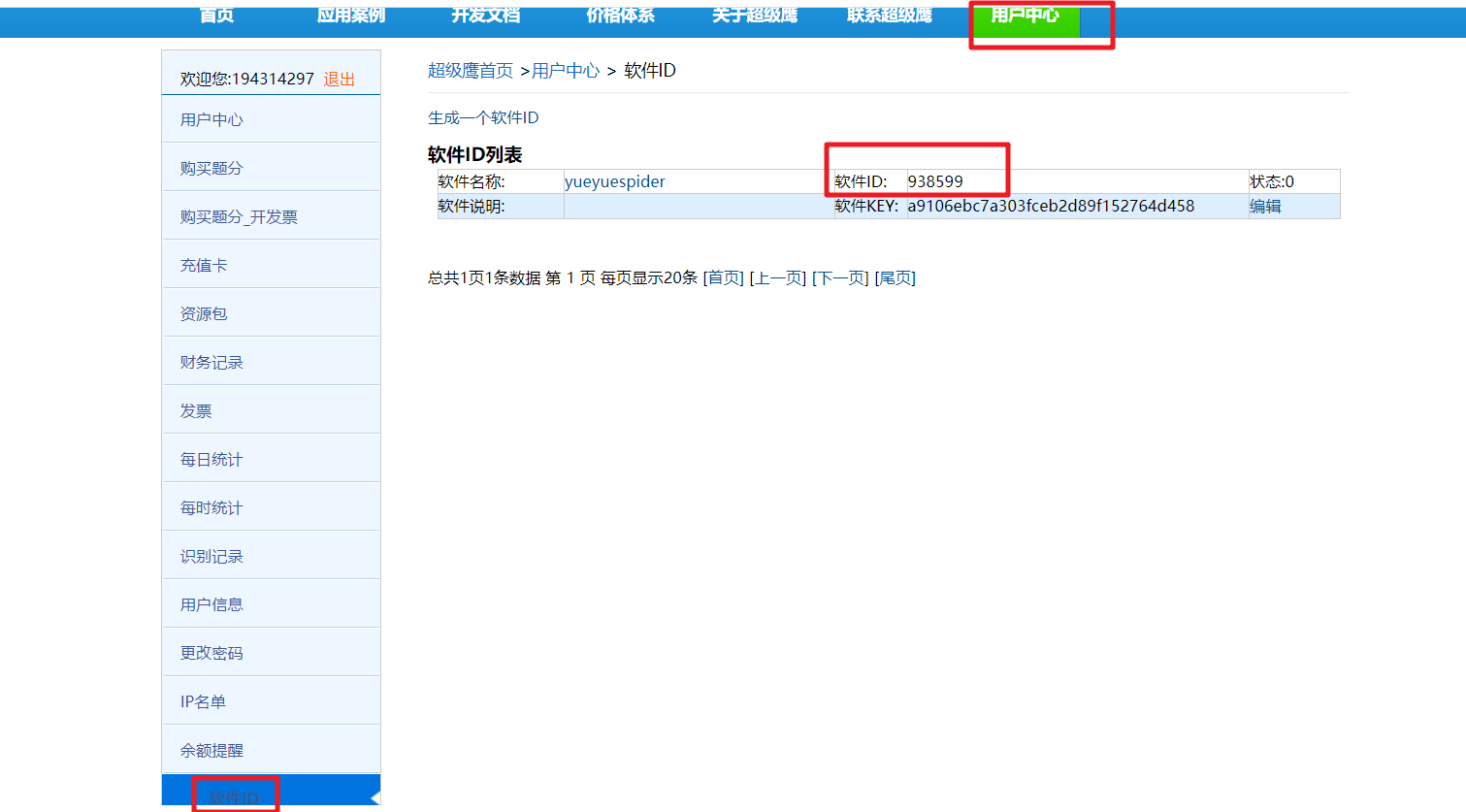
4、导入chaojiying模块下的Chaojiying_Client类,调用PostPic方法完成识别。
from chaojiying import Chaojiying_Client
chaojiying = Chaojiying_Client('用户名', '密码', '软件id')
im = open('需要识别的图片', 'rb').read()
print(chaojiying.PostPic(im, 9104)['pic_str']) # 9104为识别的验证码类型
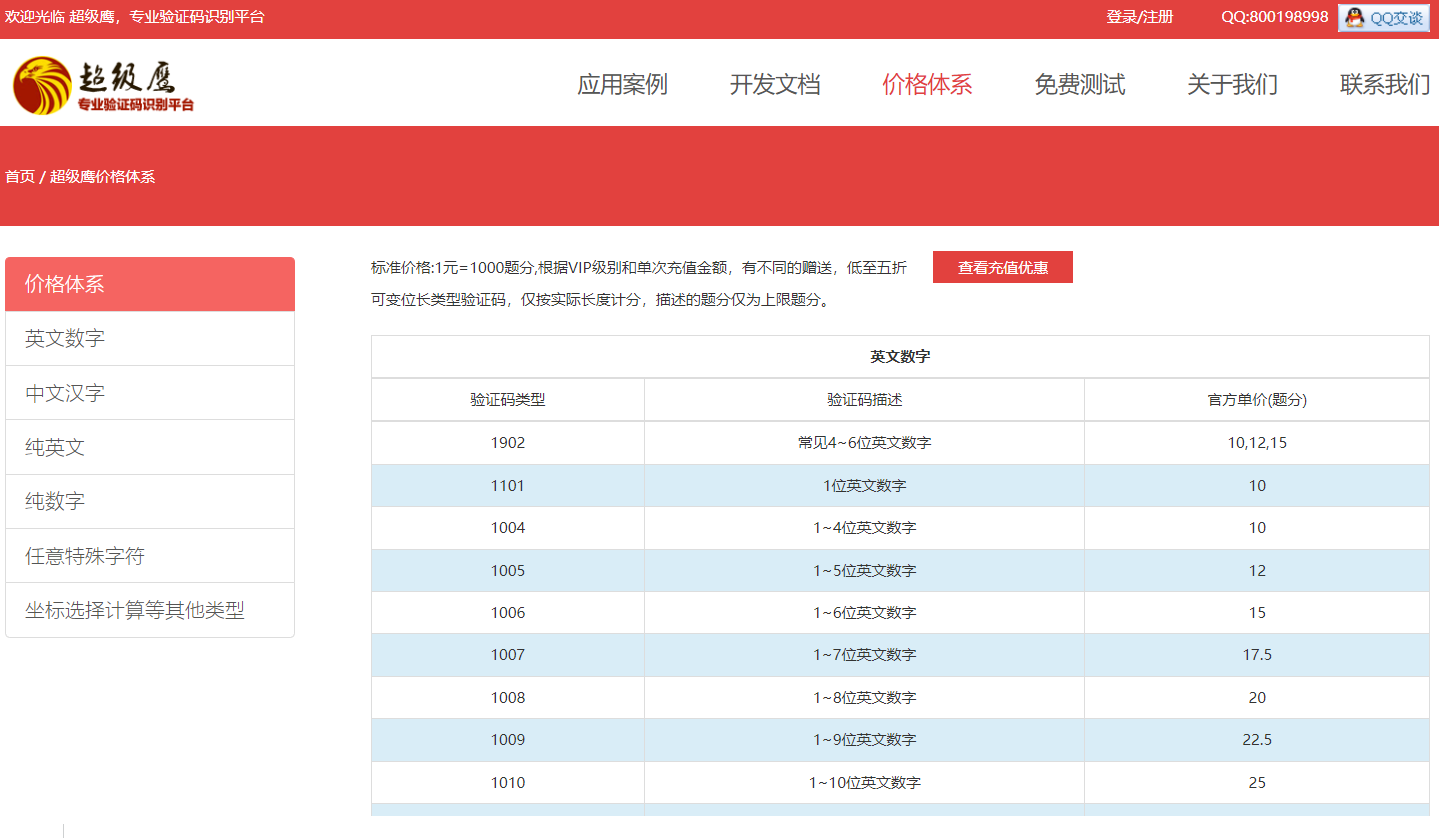
5、验证码在价格体系下查看,根据自己的所需查看。
三:字体反爬
网页开发者自己创造一种字体,因为在字体中每个文字都有其代号,那么以后在网页中不会直接显示这个文字的最终的效果,而是显示他的代号,因此即使获取到了网页中的文本内容,也只是获取到文字的代号,而不是文字本身。简单的说,字体反爬指的就是浏览器页面上的字符和调试窗口或者源码中的内容,显示的不一样,这就是字体反爬。
1.字体反爬原理
在之前,网站开发者在设计网页时只能使用公用的字体来展示网页中的数据。但是,随着CSS样式的深入开发,网站开发者可以将自己的字体放到服务器中。当用户在访问Web界面时,对应的字体就会被浏览器自动下载到用户的计算机中,然后通过CSS样式进行调用。之后,通过一种映射关系,使得网页中的源数据变为真正的数据进行展示。
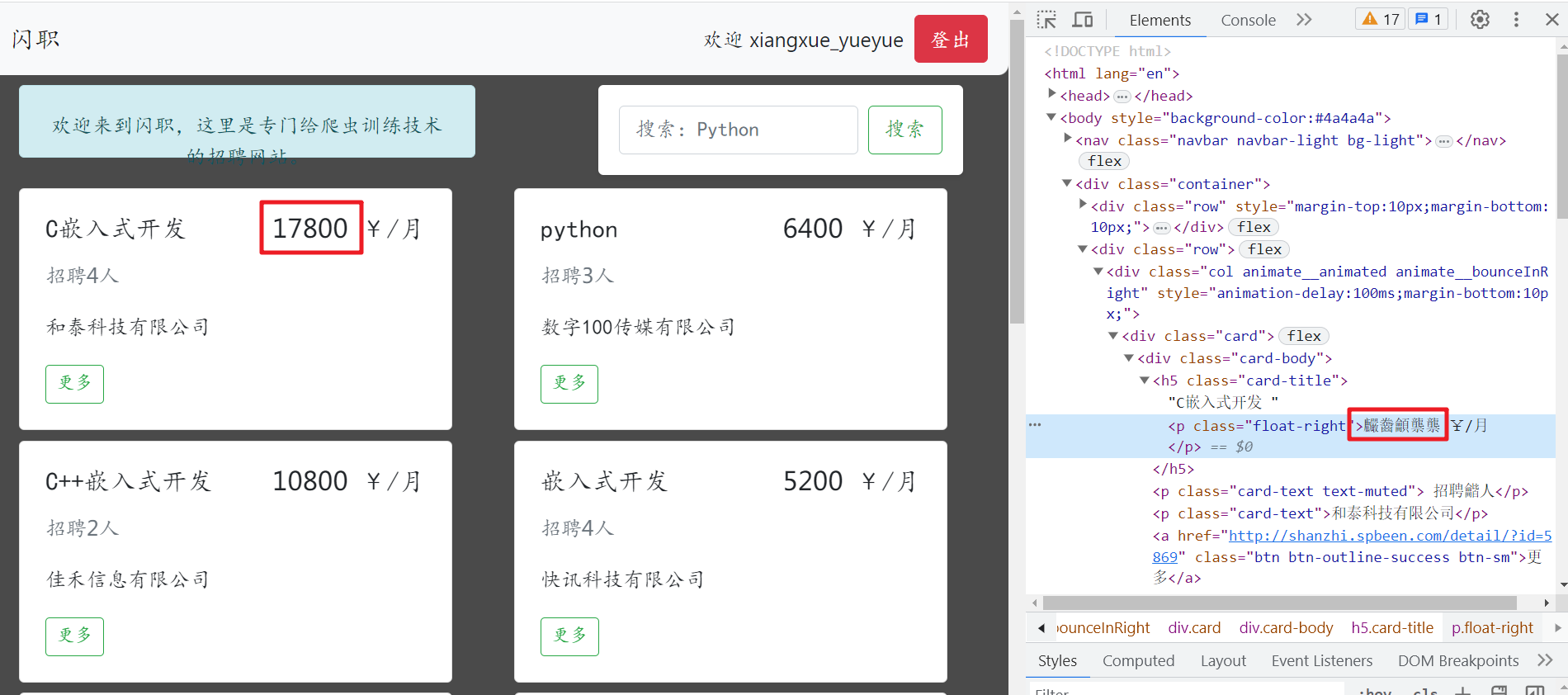
通过这种方式,使得这样就使得网站开发者进行网页设计时,只需要使用特殊字符进行占位即可,不需要将真正的数据放到页面中去。这样,爬虫程序如果不知道这种映射关系的话,就无法从字体中获取正确的数据,从而实现反爬虫。
2.字体映射表的处理
1、下载对应的字体文件
字体是在服务器上进行存储,并通过浏览器下载到我们的电脑上的,那么我们就可以在网站上找到加载的字体文件,下载下来。
2、寻找映射关系
通过对源网页中的占位数据和字体进行比对找到规律
3、构建映射算法
在上面我们已经找到了字体之间映射关系,那么我们现在就可以开始用Python来构建映射算法,从而使得爬虫可以获取一个正确的数据。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 微信小程序------WXML模板语法之条件渲染和列表渲染
- 什么是网络声誉管理?如何做好声誉管理?
- windows系统安装docker
- node的下载、安装、配置
- 03 MyBatisPlus之条件构造器Wrapper+核心注解
- 继电器模组
- 计算机毕业设计 | node.js(Express)+vue 学科竞赛综合信息管理系统(附源码)
- 字符函数和字符串函数
- 利用 Dynamsoft Panorama 提高效率:多代码读取领域的游戏规则改变者
- 欧式变换、相似变换、仿射变换、射影变换的性质比较