Resnet BatchNormalization 迁移学习
时间:2015
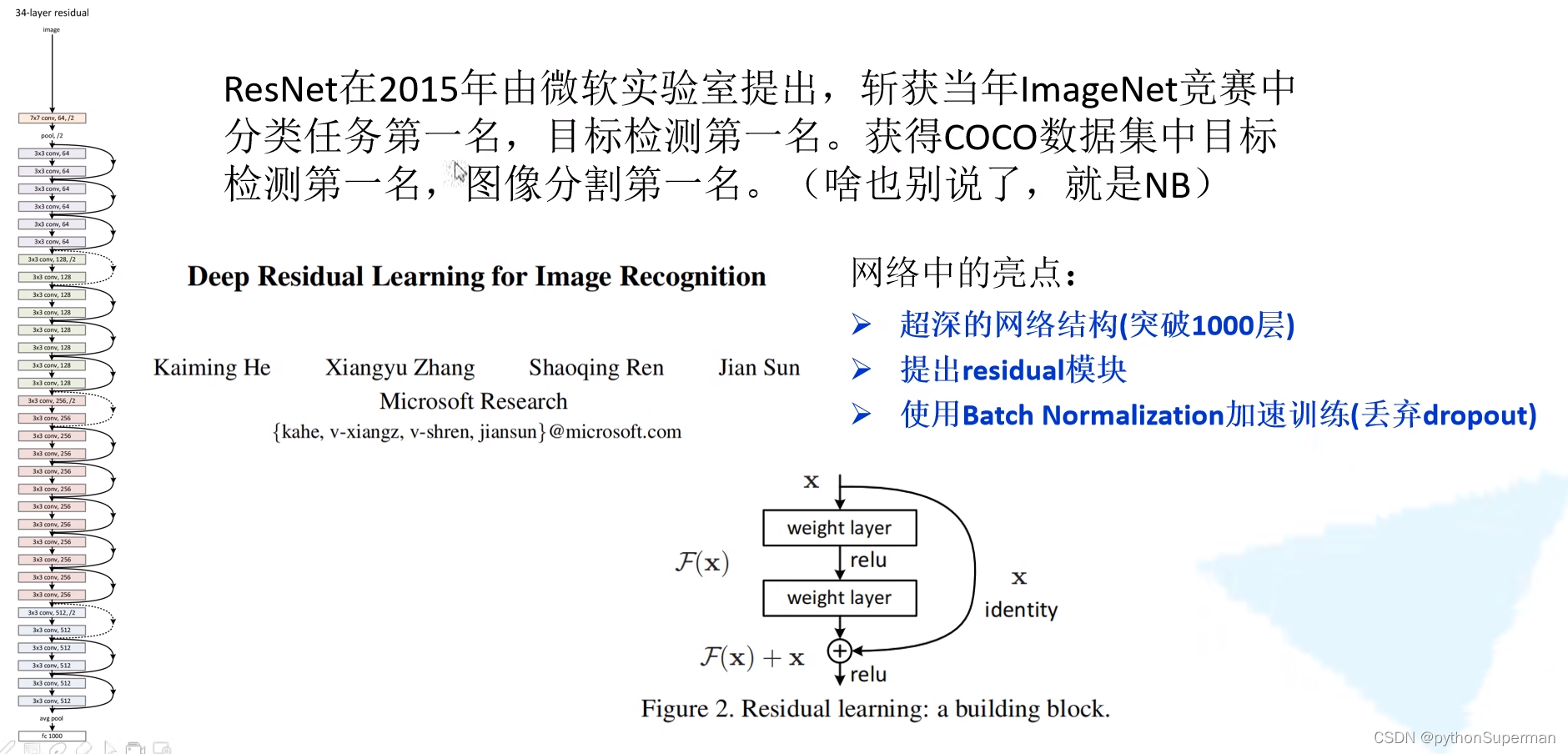
网络中的亮点:
- 超深的网络结构(突破1000层)
- 提出residual模块
- 使用Batch? Normalization加速训练(丢弃dropout)
层数越深效果越好?

是什么样的原因导致更深的网络导致的训练效果更差呢?
梯度消失和梯度爆炸
随着网络层数的不断加深,梯度消失和梯度爆炸的现象会越来越明显,
梯度消失:假设每一层的误差梯度是一个小于1的数,那么在我们反向传播过程中,每向前传播一次,都要乘以小于1的误差梯度。那么当我们网络越来越深的时候,所乘的小于1的系数越多,那么久越趋近于0,这样梯度就会越来越小,造成梯度消失现象。
梯度爆炸:假设每一层的误差梯度是一个大于1的数,那么在我们反向传播过程中,每向前传播一次,都要乘以大于1的误差梯度。那么当我们网络越来越深的时候,所乘的大于1的系数越多,,这样梯度就会越来越大,造成梯度爆炸现象。
退化问题
解决了梯度消失和梯度爆炸的问题后,仍存在层数深的效果还是没有层数小的效果好。怎样解决呢,在我们的resnet当中提出了一个叫做“残差”的结构。
梯度消失和梯度爆炸现象怎么解决呢?
数据标准化处理,权重初始化,以及BN(Batch Normalization).
residual结构

?shotcut:捷径的意思。主分支和侧分支要相加,两个的shape一定要相同。
Batch Normalization
参考链接:Batch Normalization详解以及pytorch实验_pytorch batch normalization-CSDN博客
Bath Normalization的目的是使我们的一批(Batch)feature map满足均值为0,方差为1的分布规律。通过该方法能够加速网络的收敛并提升准确率。

?如下图所示,对于Conv1来说输入的就是满足某一分布的特征矩阵,但对于Conv2而言输入的feature map就不一定满足某一分布规律了(注意这里所说满足某一分布规律并不是指某一个feature map的数据要满足分布规律,理论上是指整个训练样本集所对应feature map的数据要满足分布规律)。而我们Batch Normalization的目的就是使我们的feature map满足均值为0,方差为1的分布规律。
?使用BN时需要注意的问题
(1)训练时要将traning参数设置为True,在验证时将trainning参数设置为False。在pytorch中可通过创建模型的model.train()和model.eval()方法控制。因为在我们训练过程当中,需要我们不断去统计均值和方差,而在我们的验证或者预测过程当中使用的是我们历史统计的均值和方差,而不是当前所计算的均值和方差。
(2)batch size尽可能设置大点,设置小后表现可能很糟糕,设置的越大求的均值和方差越接近整个训练集的均值和方差。值设置得越大,越接近我们整个样本训练集的均值和方差,效果也会越好。设置得很小的时候,比如说它的极限状况也就是batch size设置为1,这种情况使用BN是没有什么作用的,效果可能还会变差。
(3)建议将bn层放在卷积层(Conv)和激活层(例如Relu)之间,且卷积层不要使用偏置bias,因为没有用,参考下图推理,即使使用了偏置bias求出的结果也是一样的。
迁移学习
使用迁移学习的优势:
- 能够快速的训练处一个理想的结果
- 当数据集较小时也能训练处理想的效果
什么是迁移学习

?对于浅层的卷积层而言,所学习到的角点信息和纹理信息等是比较通用的信息,这些信息不仅是在本网络中适用,在其他网络中也同样适用。所以就会有迁移的这么一个概念。就是将我们学习好的一些浅层网络的参数迁移到我们新的网络中去,这样我们新的网络就也拥有了识别底层通用特征的能力了,新的网络拥有了这些底层通用的检测识别能力之后,我们就能更加快速地去学习新的数据集的高维特征。
常见的迁移学习方式:

- 载入权重后训练所有参数
- 最后一层无法载入预训练模型参数
- 载入权重后只训练最后几层参数
- 载入所有模型参数后,固定全连接之前的所有模型参数,只去训练最后三层全连接层,这样我们所需训练的参数就会变少,训练速度也会变快。
- 载入权重后在原网络基础上再添加一层全连接层,进训练最后一个全连接层。
- 由于我们训练集的分类个数和原预训练集的分类个数不一样,所以最后一层是无法载入的。当我们使用第三个方法,也可以将最后一层的参数载入进去,只不过我们在最后的全连接层之后再加上新的全连接层,这个新的全连接层的节点个数也就是我们所采用的训练集的分类个数,然后仅仅去训练最后一层的参数。
自己的硬件条件有限或者训练时间有要求,第二种第三种方法都适合。对于硬件参数不受限,而且希望得到一个最优的结果,那就要采用第一种方法,这种方法相比于后面的两种方法训练时间稍微长一点,但最终达到的效果也要比后两种方法的好。但相比不用迁移学习的方法,还是要快很多的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Flash 的特征缺陷
- watch监听的使用
- Postman/Apifox使用教程
- 第一届能源电子产业创新大赛太阳能光伏赛道决赛及颁奖仪式在宜宾成功举办
- 如何使用 Selenium 实现自动化操作?
- 【数据库】数据库基础理论
- 数据库备份 - automysqlback- Error: Dependency programs are missing. mysql ……没有找到?
- 构建强大的Python后端分离应用:使用Token实现安全身份验证和权限控制
- 2024随身WiFi还能买吗?随身WiFi哪个品牌最靠谱,高性价比高口碑随身wifi推荐
- 使用curl上传文件至服务器的 java servlet简单实现