YOLOv5改进 | SPPF篇 | FocalModulation替换SPPF(精度更高的空间金字塔池化)
一、本文介绍
本文给大家带来的改进是用FocalModulation技术来替换了原有的SPPF(快速空间金字塔池化)模块。FocalModulation是今年新提出的特征增强方法,它利用注意力机制来聚焦于图像中的关键区域,从而提高模型对这些区域的识别能力。与SPPF相比,FocalModulation不仅能够处理不同尺寸的输入图像,还能更精确地识别和定位图像中的对象。这一技术特别适用于处理那些难以检测的小对象或在复杂背景中的对象(更多的检测效果请看第二章)。我进行了简单的实验,这个FocalModulation能够提升一定的精度,其不影响任何的计算量和参数所以还是可以尝试的(改进起来也比较简单)。
推荐指数:????
训练结果对比图->??
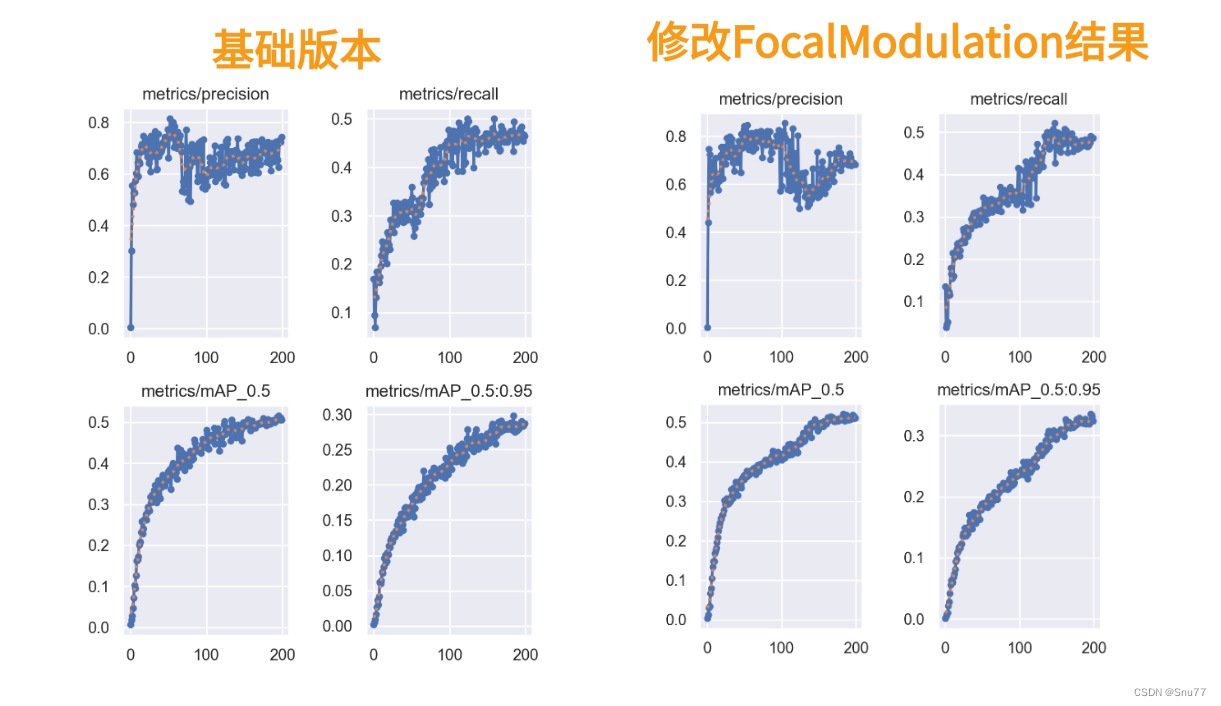
?
目录
二、FocalModulation模型原理
 ?
?
论文地址:官方论文地址
代码地址:官方代码地址?
 ??
??
2.1 SPP和SPPF回顾
在开始讲FocalModulation模块之前先简单回顾一下SPP和SPPF。
SPPF(Spatial Pyramid Pooling Fast)是一种在深度学习和计算机视觉领域中使用的技术,特别是在目标检测任务中。它是空间金字塔池化(Spatial Pyramid Pooling,简称SPP)的一个变体或快速版本。下面是SPP和SPPF的基本概念:
-
空间金字塔池化(SPP): SPP是一种网络层,用于解决卷积神经网络(CNN)中固定大小输入的限制。在标准CNN中,网络的输入图像需要被调整到固定的尺寸,这可能导致信息丢失或畸变。SPP通过对不同区域进行池化操作来允许网络处理任意大小的输入。这样,SPP层能够生成固定长度的输出,即使输入图像的尺寸不同。这对于图像分类和目标检测任务非常有用。
-
SPPF(快速空间金字塔池化): SPPF是SPP的一个改进版本,旨在提高处理速度和效率。它通常在目标检测框架中用于提高模型在处理不同尺寸输入时的速度和精度。SPPF能够更快地进行区域池化操作,并且通常在现代的目标检测架构中,如YOLO(You Only Look Once)系列网络中被集成。
总结:SPPF就是允许网络处理各种尺寸的输入图像,然后它能够产生相同的输出大小的图像,同时保持较高的处理速度,这就是SPPF的作用。
2.2?FocalModulation模型的基本原理
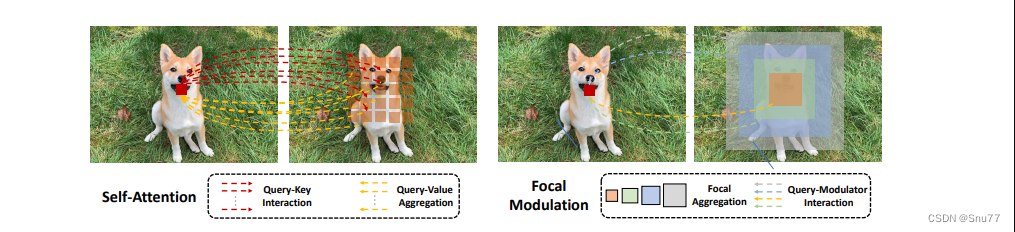
Focal Modulation Networks(FocalNets)的基本原理是替换自注意力(Self-Attention)模块,使用焦点调制(focal modulation)机制来捕捉图像中的长距离依赖和上下文信息。下图是自注意力和焦点调制两种方法的对比。
 ?
?
?
自注意力要求对每个查询令牌(Query Token)与其他令牌进行复杂的查询-键(Query-Key)交互和查询-值(Query-Value)聚合,以计算注意力分数并捕捉上下文。而焦点调制则先将空间上下文以不同粒度聚合到调制器中,然后以查询依赖的方式将这些调制器注入到查询令牌中。焦点调制简化了交互和聚合操作,使其更轻量级。在图中,自注意力部分使用红色虚线表示查询-键交互和黄色虚线表示查询-值聚合,而焦点调制部分则用蓝色表示调制器聚合和黄色表示查询-调制器交互。?
FocalModulation模型通过以下步骤实现:
1. 焦点上下文化:用深度卷积层堆叠来编码不同范围的视觉上下文。
2. 门控聚合:通过门控机制,选择性地将上下文信息聚合到每个查询令牌的调制器中。
3. 逐元素仿射变换:将聚合后的调制器通过仿射变换注入到每个查询令牌中。
下面来分别介绍这三个机制->
2.2.1?焦点上下文化
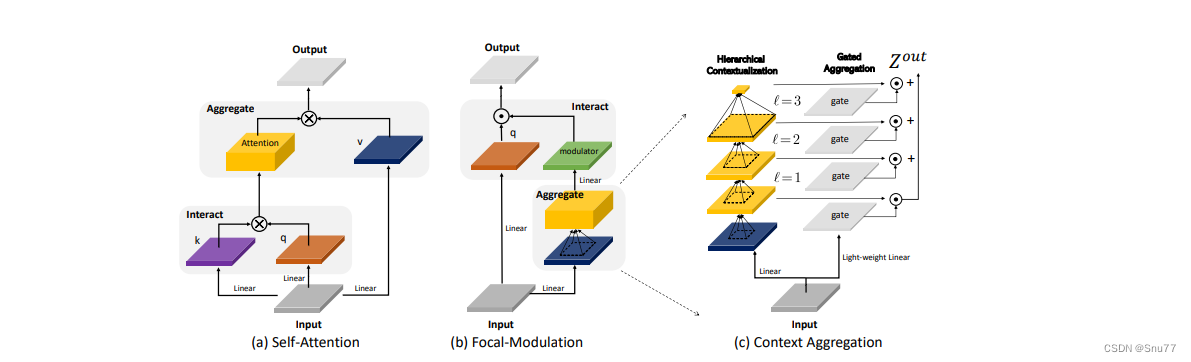
焦点上下文化(Focal Contextualization)是焦点调制(Focal Modulation)的一个组成部分。焦点上下文化使用一系列深度卷积层(depth-wise convolutional layers)来编码不同范围内的视觉上下文信息。这些层可以捕捉从近处到远处的视觉特征,从而允许网络在不同层次上理解图像内容。通过这种方式,网络能够在聚合上下文信息时保持对局部细节的敏感性,并增强对全局结构的认识。
 ?
?
?
这张图详细比较了自注意力(Self-Attention, SA)和焦点调制(Focal Modulation)的机制,并特别展示了焦点调制中的上下文聚合过程。左侧的图展示了自注意力模型如何通过键(k)和查询(q)之间的交互,以及随后的聚合来生成输出。而中间和右侧的图说明了焦点调制如何通过层级化的上下文聚合和门控聚合过程替代自注意力模型的这一过程。在焦点调制中,输入首先通过轻量级线性层进行处理,然后通过层级化的上下文化模块和门控机制来选择性地聚合信息,最终通过调制器与查询(q)进行交互以生成输出。
2.2.2?门控聚合
在Focal Modulation Networks(FocalNets)中的 "门控聚合"(Gated Aggregation)是关键组件之一,这一过程涉及使用门控机制来选择性地聚合上下文信息。以下是这个过程的详细分析:
1. 什么是门控机制?
门控机制在深度学习中常用于控制信息流。它通常用于决定哪些信息应该被传递,哪些应该被阻断。在循环神经网络(RNN)中,特别是在长短期记忆网络(LSTM)和门控循环单元(GRU)中,门控机制用于调节信息在时间序列数据中的流动。
2. 门控聚合的目的
在FocalNets中,门控聚合的目的是为每个查询令牌(即处理中的数据单元)选择性地聚合上下文信息。这意味着网络能够决定哪些特定的上下文信息对于当前处理的查询令牌是重要的,从而专注于那些最相关的信息。
3. 如何实现门控聚合?
实现门控聚合可能涉及一系列计算步骤,其中包括:
- 计算上下文信息:这可能涉及使用深度卷积层(如文中提到的)对输入图像的不同区域进行编码,以捕捉从局部到全局的视觉上下文。
- 门控操作:这一步骤涉及到一个决策过程,根据当前查询令牌的特征来决定哪些上下文信息是相关的。这可能通过一个学习到的权重(门)来实现,该权重决定了不同上下文信息的重要性。
- 信息聚合:最后,根据门控操作的结果,选择性地聚合上下文信息到一个调制器中。这个调制器随后被用于调整或“调制”查询令牌的表示。
4. 门控聚合的好处
通过门控聚合,FocalNets能够更有效地聚焦于对当前任务最关键的信息。这种方法提高了模型的效率和性能,因为它减少了不必要信息的处理,同时增强了对关键特征的关注。在视觉任务中,这可能意味着更好的目标检测和图像分类性能,特别是在复杂或多变的视觉环境中。
总结:门控聚合是FocalNets的一个核心组成部分,它通过选择性地集中处理重要的上下文信息来提升网络的效率和性能。
2.2.3?逐元素仿射变换
在Focal Modulation Networks(FocalNets)中的第三个关键组件是逐元素仿射变换,这个步骤涉及将通过门控聚合得到的调制器注入到每个查询令牌中。以下是该过程的详细分析:
1. 仿射变换的基本概念:
仿射变换是一种线性变换,用于对数据进行缩放、旋转、平移和倾斜等操作。在深度学习中,逐元素的仿射变换通常指的是对每个元素进行线性变换,这种变换可以被描述为y = ax + b,其中x是输入,y是输出,a和b是变换的参数。
2. 逐元素仿射变换的作用:
在FocalNets中,逐元素仿射变换的作用是将聚合后的调制器信息注入到每个查询令牌中。这个步骤对于整合上下文信息和查询令牌的原始特征非常重要。通过这种方式,调制器所包含的上下文信息可以直接影响查询令牌的表示。
3. 执行仿射变换:
执行这一步骤时,聚合后的调制器对每个查询令牌进行逐元素的仿射变换。在实践中,这可能意味着对查询令牌的每个特征应用调制器中的相应权重(a)和偏差(b)。这样,调制器中的每个元素都直接对应于查询令牌的一个特征,通过调整这些特征来改变其表达。
4. 仿射变换的效果:
通过逐元素仿射变换,模型能够更细致地调整每个查询令牌的特征,根据上下文信息来增强或抑制某些特征。这种精细的调整机制允许网络更好地适应复杂的视觉场景,提高对细节的捕捉能力,从而提升了模型在各种视觉任务中的性能,如目标检测和图像分类。
总结:逐元素仿射变换它使得模型能够利用上下文信息来有效地调整查询令牌,增强了模型对关键视觉特征的捕捉和表达能力。
三、FocalModulation的完整代码?
我们将在“ultralytics/nn/modules”目录下面创建一个文件将其复制进去,使用方法在后面会讲。
class FocalModulation(nn.Module):
def __init__(self, dim, focal_window=3, focal_level=2, focal_factor=2, bias=True, proj_drop=0.,
use_postln_in_modulation=False, normalize_modulator=False):
super().__init__()
self.dim = dim
self.focal_window = focal_window
self.focal_level = focal_level
self.focal_factor = focal_factor
self.use_postln_in_modulation = use_postln_in_modulation
self.normalize_modulator = normalize_modulator
self.f_linear = nn.Conv2d(dim, 2 * dim + (self.focal_level + 1), kernel_size=1, bias=bias)
self.h = nn.Conv2d(dim, dim, kernel_size=1, stride=1, bias=bias)
self.act = nn.GELU()
self.proj = nn.Conv2d(dim, dim, kernel_size=1)
self.proj_drop = nn.Dropout(proj_drop)
self.focal_layers = nn.ModuleList()
self.kernel_sizes = []
for k in range(self.focal_level):
kernel_size = self.focal_factor * k + self.focal_window
self.focal_layers.append(
nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=kernel_size, stride=1,
groups=dim, padding=kernel_size // 2, bias=False),
nn.GELU(),
)
)
self.kernel_sizes.append(kernel_size)
if self.use_postln_in_modulation:
self.ln = nn.LayerNorm(dim)
def forward(self, x):
"""
Args:
x: input features with shape of (B, H, W, C)
"""
C = x.shape[1]
# pre linear projection
x = self.f_linear(x).contiguous()
q, ctx, gates = torch.split(x, (C, C, self.focal_level + 1), 1)
# context aggreation
ctx_all = 0.0
for l in range(self.focal_level):
ctx = self.focal_layers[l](ctx)
ctx_all = ctx_all + ctx * gates[:, l:l + 1]
ctx_global = self.act(ctx.mean(2, keepdim=True).mean(3, keepdim=True))
ctx_all = ctx_all + ctx_global * gates[:, self.focal_level:]
# normalize context
if self.normalize_modulator:
ctx_all = ctx_all / (self.focal_level + 1)
# focal modulation
x_out = q * self.h(ctx_all)
x_out = x_out.contiguous()
if self.use_postln_in_modulation:
x_out = self.ln(x_out)
# post linear porjection
x_out = self.proj(x_out)
x_out = self.proj_drop(x_out)
return x_out四、手把手教你添加FocalModulation
4.1 细节修改教程
4.1.1 修改一
我们找到如下的目录'yolov5-master/models'在这个目录下创建一整个文件目录(注意是目录,因为我这个专栏会出很多的更新,这里用一种一劳永逸的方法)文件目录起名modules,然后在下面新建一个文件,将我们的代码复制粘贴进去。

?
?
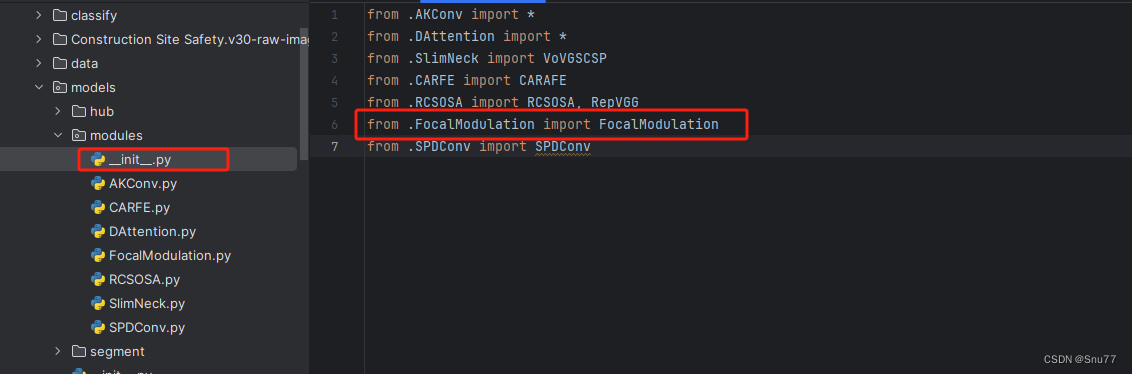
?4.1.2 修改二
然后新建一个__init__.py文件,然后我们在里面添加一行代码。注意标记一个'.'其作用是标记当前目录。
 ?
?
??
4.1.3 修改三?
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加。)
 ???
???
4.1.4 修改四
然后我们找到parse_model方法,按照如下修改->
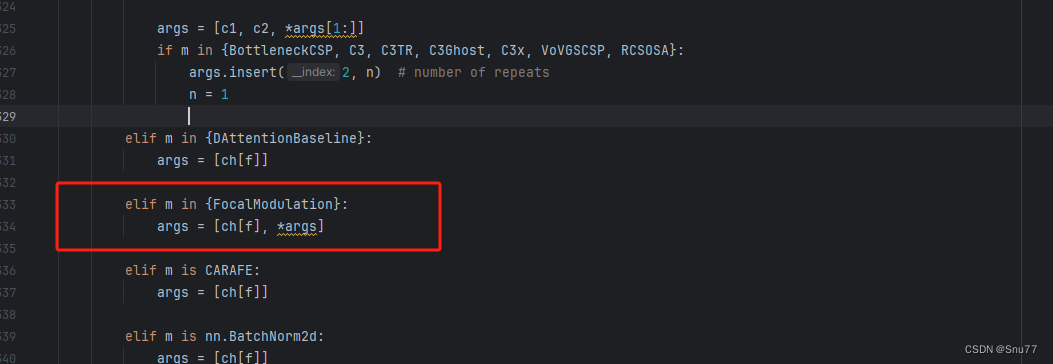
?
到此就修改完成了,复制下面的ymal文件即可运行。
4.2 FocalModulation的yaml文件
复制如下的yaml文件即可运行。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, FocalModulation, []], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
4.3 FocalModulation运行成功截图
附上我的运行记录确保我的教程是可用的。?

五、本文总结?
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv5改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于单片机的火灾报警器 (论文+源码)
- 启动 Mac 时显示闪烁的问号
- AI系统ChatGPT网站系统源码AI绘画详细搭建部署教程,支持GPT语音对话+DALL-E3文生图+GPT-4多模态模型识图理解
- 01.Java绘图坐标体系
- JavaOOP篇----第四篇
- Ef Core花里胡哨系列(9) 阴影属性,有用还是没用?
- 咨询技能!Salesforce从业者脱颖而出的法宝
- TCP/IP 网络模型
- 爬虫三天快速入门
- 【SPA详细介绍】