大语言模型&向量数据库
大语言模型&向量数据库
文章来源:A Comprehensive Survey on Vector Database:Storage and Retrieval Technique, Challenge
链接: https://arxiv.org/pdf/2310.11703.pdf
LARGE LANGUAGE MODELS
Typically, large language models (LLMs) refer to Transformer language models that contain hundreds of billions (or more) of parameters, which are trained on massive text data. On a suite of traditional NLP benchmarks, GPT-4 outperforms both previous large language models and most state-of-the-art systems.
通常,大型语言模型(LLM)指的是包含数千亿(或更多)参数的 Transformer 语言模型,这些模型是在海量文本数据上训练出来的。在一套传统的 NLP 基准测试中,GPT-4 的表现优于以前的大型语言模型和大多数最先进的系统。
A. Vector Database & LLM Workflow
Databases and large language models sit at opposite ends of the data science research:
Databases are more concerned with storing data efficiently and retrieving it quickly and accurately.Large language models are more concerned with characterizing data and solving semantically related problems.If the database is specified as a vector database, a more ideal workflow can be constructed as follows:
数据库和大型语言模型处于数据科学研究的两端:数据库更关注高效地存储数据以及快速准确地检索数据。大型语言模型更关注数据特征和解决语义相关问题。
如果将数据库指定为矢量数据库,则可以构建如下较为理想的工作流程:
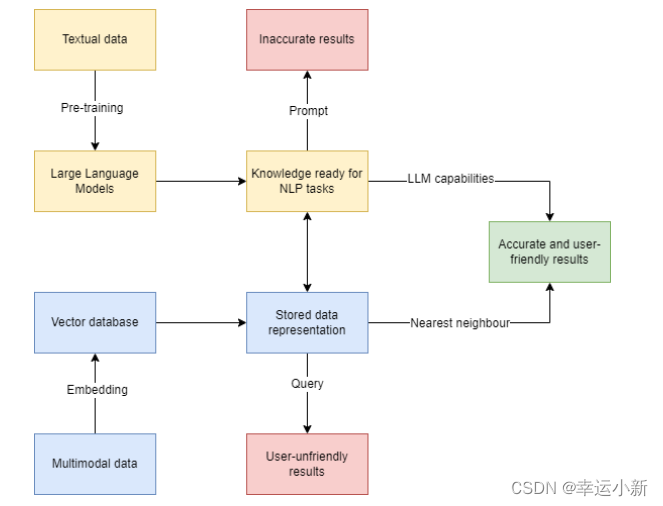
Fig. 1. An ideal workflow for combining vector databases and large language models.
图1。结合矢量数据库和大型语言模型的理想工作流程。
At first, the large language model is pre-trained using textual data, which stores knowledge that can be prepared for use in natural language processing tasks. The multimodal data is embedded and stored in a vector database to obtain vector representations. Next, when the user inputs a serialized textual question, the LLM is responsible for providing NLP capabilities, while the algorithms in the vector database are responsible for finding approximate nearest neighbors.
Combining the two gives more desirable results than using only LLM and the vector database.
If only LLM is used, the results obtained may not be accurate enough, while if only vector databases are used, the results obtained may not be user-friendly.
首先,使用文本数据对大型语言模型进行预训练,这些数据存储了可用于自然语言处理任务的知识。多模态数据被嵌入并存储在矢量数据库中,以获得矢量表示。接下来,当用户输入序列化文本问题时,LLM 负责提供 NLP 功能,而向量数据库中的算法则负责寻找近似近邻。
与只使用 LLM 和矢量数据库相比,将两者结合起来会得到更理想的结果。如果只使用 LLM,得到的结果可能不够准确,而如果只使用向量数据库,得到的结果可能对用户不友好。
B. Vector Database for LLM
1.Data: By learning from massive amounts of pre-training textual data, LLMs can acquire various emerging capabilties,which are not present in smaller models but are present in larger models, e.g.,in-context learning, chain-of-thought, and instruction following.Data plays a crucial role in LLM’s emerging ability, which in turn can unfold at three points:
1.数据: 通过从海量的预训练文本数据中学习,LLM 可以获得各种新兴能力,这些能力在较小的模型中不存在,但在较大的模型中存在,如上下文学习、思维链和指令跟随:
Data scale. This is the amount of data that is used to train the LLMs. According to, LLMs can improve their capabilities predictably with increasing data scale, even without targeted innovation. The larger the data scale, the more diverse and representative the data is, which can help the LLMs learn more patterns and relationships in natural language. LLMs can improve their capabilities predictably with increasing data scale, even without targeted innovation. However, data scale also comes with challenges, such as computational cost,environmental impact, and ethical issues.
数据规模 。这是用于训练LLM的数据量。根据,LLM可以随着数据规模的增加而提高其能力,即使没有针对性的创新。数据规模越大,数据就越具有多样性和代表性,这可以帮助LLM学习更多的自然语言模式和关系。LLM可以随着数据规模的增加而可预测地提高其能力,即使没有针对性的创新。然而,数据规模也带来了挑战,如计算成本、环境影响和道德问题。
Data quality. This is the accuracy, completeness, consistency, and relevance of the data that is used to train the LLMs.The higher the data quality, the more reliable and robust the LLMs are, which can help them avoid errors and biases.LLMs can benefit from data quality improvement techniques,such as data filtering, cleaning, augmentation, and balancing.However, data quality also requires careful evaluation and validation, which can be difficult and subjective.
数据质量。这是用于训练LLM的数据的准确性、完整性、一致性和相关性。数据质量越高,LLM就越可靠和稳健,这可以帮助它们避免错误和偏差。LLM可以受益于数据质量改进技术,如数据过滤、清理、增强和平衡。然而,数据质量也需要仔细的评估和验证,这可能是困难和主观的。
Data diversity. This is the variety and richness of the data that is used to train the LLMs. The more diverse the data,the more inclusive and generalizable the LLMs are, which can help them handle different languages, domains, tasks, and users. LLMs can achieve better performance and robustness by using diverse data sources, such as web text, books, news articles, social media posts, and more. However, data diversity also poses challenges, such as data alignment, integration, and protection.
数据多样性。这就是用于训练LLM的数据的多样性和丰富性。数据越多样化,LLM就越具有包容性和可推广性,这可以帮助它们处理不同的语言、域、任务和用户。LLM可以通过使用不同的数据源,如网络文本、书籍、新闻文章、社交媒体帖子等,实现更好的性能和稳健性。然而,数据多样性也带来了挑战,如数据一致性、集成和保护。
As for vector database, the traditional techniques of database such as cleaning, de-duplication and alignment can help LLM to obtain high-quality and large-scale data, and the storage in
vector form is also suitable for diverse data.
对于矢量数据库,传统的数据库技术,如清理、重复数据消除和对齐,可以帮助LLM获得高质量和大规模的数据,并且矢量形式的存储也适用于各种数据。
2.Model: In addition to the data, LLM has benefited from growth in model size. The large number of parameters creates challenges for model training, and storage. Vector databases can help LLM reduce costs and increase efficiency in this regard.
模型:除了数据之外,LLM还受益于模型规模的增长。大量的参数给模型训练和存储带来了挑战。矢量数据库可以帮助LLM在这方面降低成本并提高效率。
Distributed training. DBMS can help model storage in the context of model segmentation and integration. Vector databases can enable distributed training of LLM by allowing multiple workers to access and update the same vector data in parallel. This can speed up the training process and reduce the communication overhead among workers.
分布式训练。数据库管理系统有助于在模型分割和集成的背景下存储模型。矢量数据库可以允许多个工作人员并行访问和更新相同的矢量数据,从而实现 LLM 的分布式训练。这可以加快训练过程,减少工作人员之间的通信开销。
Model compression .The purpose of this is to reduce the complexity of the model and the number of parameters, reduce model storage and computational resources, and improve the efficiency of model computing. The methods used are typically pruning, quantization, grouped convolution, knowledge distillation, neural network compression, low-rank decomposition, and so on. Vector databases can help compress LLM by storing only the most important or representative vectors of the model,instead of the entire model parameters. This can reduce the storage space and memory usage of LLM, as well as the inference latency.
模型压缩。这样做的目的是降低模型的复杂性和参数的数量,减少模型存储和计算资源,提高模型计算的效率。所使用的方法通常是修剪、量化、分组卷积、知识提取、神经网络压缩、低秩分解等。向量数据库可以通过只存储模型中最重要或最具代表性的向量而不是整个模型参数来帮助压缩LLM。这可以减少LLM的存储空间和内存使用,以及推理延迟。
Vector storage. Vector databases can optimize the storage of vector data by using specialized data structures, such as inverted indexes, trees, graphs, or hashing. This can improve the performance and scalability of LLM applications that rely on vector operations, such as semantic search, recommendation,or question answering.
矢量存储。矢量数据库可以通过使用专门的数据结构(如反向索引、树、图或哈希)来优化矢量数据的存储。这可以提高依赖向量操作(如语义搜索、推荐或问答)的LLM应用程序的性能和可扩展性。
3.Retrieval: Users can use a large language model to generate some text based on a query or a prompt, however, the output may not be diversiform, consistent, or factual. Vector databases can ameliorate these problems on a case-by-case basis, improving the user experience.
检索:用户可以使用大型语言模型根据查询或提示生成一些文本,但输出可能不多样、不一致或不真实。矢量数据库可以在个案的基础上改善这些问题,改善用户体验。
Cross-modal support. V ector databases can support cross-modal search, which is the ability to search across different types of data, such as text, images, audio, or video. For example, an LLM can use a vector database to find images that are relevant to a text query, or vice versa. This can enhance the user experience and satisfaction by providing more diverse and rich results.
跨模态支持。矢量数据库可以支持跨模态搜索,即跨不同类型的数据(如文本、图像、音频或视频)进行搜索的能力。例如,LLM可以使用矢量数据库来查找与文本查询相关的图像,反之亦然。这可以通过提供更加多样化和丰富的结果来增强用户体验和满意度。
Real-time knowledge. V ector databases can enable real-time knowledge search, which is the ability to search for the most up-to-date and accurate information from various sources. For example, an LLM can use a vector database to find the latest news, facts, or opinions about a topic or event.This can improve the user’s awareness and understanding by providing more timely and reliable results.
实时知识。矢量数据库可以实现实时知识搜索,这是从各种来源搜索最新和准确信息的能力。例如,LLM可以使用矢量数据库来查找有关主题或事件的最新新闻、事实或意见。这可以通过提供更及时和可靠的结果来提高用户的意识和理解
Less hallucination. V ector databases can help reduce hallucination, which is the tendency of LLM to generate false or misleading statements. For example, an LLM can use a vector database to verify or correct the data that it generates or uses for search. This can increase the user’s trust and confidence by providing more accurate and consistent results.
更少的幻觉。矢量数据库可以帮助减少幻觉,这是LLM产生虚假或误导性陈述的趋势。例如,LLM可以使用矢量数据库来验证或更正其生成或用于搜索的数据。这可以通过提供更准确和一致的结果来增加用户的信任和信心。
C. Potential Applications for Vector Database on LLM
Vector databases and LLMs can work together to enhance each other’s capabilities and create more intelligent and interactive systems. Here are some potential applications for vector databases on LLMs:
矢量数据库和LLM可以协同工作,增强彼此的能力,创建更智能、更交互式的系统。以下是矢量数据库在LLM上的一些潜在应用:
1 Long-term memory: Vector Databases can provide LLMs with long-term memory by storing relevant documents or information in vector form. When a user gives a prompt to an LLM, the V ector Database can quickly retrieve the most similar or related vectors from its index and update the context for the LLM. This way, the LLM can generate more customized and informed responses based on the user’s query and the V ector Database’s content.
1 长期记忆:矢量数据库可以通过以矢量形式存储相关文档或信息,为LLM提供长期记忆。当用户提示LLM时,矢量数据库可以从其索引中快速检索最相似或最相关的矢量,并更新LLM的上下文。这样,LLM可以根据用户的查询和Vector数据库的内容生成更定制、更明智的响应。
2 Semantic search: Vector Databases can enable semantic search for LLMs by allowing users to search for texts based on their meaning rather than keywords. For example, a user can ask an LLM a natural language question and the Vector Database can return the most relevant documents or passages that answer the question. The LLM can then summarize or paraphrase the answer for the user in natural language.
2 语义搜索:矢量数据库可以允许用户根据文本的含义而不是关键字来搜索文本,从而实现LLM的语义搜索。例如,用户可以向LLM提出自然语言问题,矢量数据库可以返回回答该问题的最相关的文档或段落。LLM然后可以用自然语言为用户总结或转述答案。
3 Recommendation systems: Vector Databases can power recommendation systems for LLMs by finding similar or complementary items based on their vector representations. For example, a user can ask an LLM for a movie recommendation and the Vector Database can suggest movies that have similar plots, genres, actors, or ratings to the user’s preferences. The LLM can then explain why the movies are recommended and provide additional information or reviews.
3 推荐系统:矢量数据库可以根据LLM的矢量表示找到相似或互补的项目,从而为LLM的推荐系统提供动力。例如,用户可以向LLM请求电影推荐,矢量数据库可以建议情节、流派、演员或评分与用户偏好相似的电影。LLM可以解释为什么推荐这些电影,并提供额外的信息或评论。
D. Potential Applications for LLM on Vector Database
LLMs on vector databases are also very interesting and promising. Here are some potential applications for LLMs on vector databases:
矢量数据库上的LLM也是非常有趣和有前景的。以下是LLM在矢量数据库上的一些潜在应用:
1 Text generation: LLMs can generate natural language texts based on vector inputs from Vector Databases. For example, a user can provide a vector that represents a topic, a sentiment, a style, or a genre, and the LLM can generate a text that matches the vector. This can be useful for creating content such as articles, stories, poems, reviews, captions, summaries,etc.
1 文本生成:LLM可以根据矢量数据库中的矢量输入生成自然语言文本。例如,用户可以提供表示主题、情感、风格或流派的向量,LLM可以生成与该向量匹配的文本。这对于创建文章、故事、诗歌、评论、标题、摘要等内容非常有用。
2 Text augmentation: LLMs can augment existing texts with additional information or details from Vector Databases.For example, a user can provide a text that is incomplete, vague, or boring, and the LLM can enrich it with relevant facts, examples, or expressions from Vector Databases. This can be useful for improving the quality and diversity of texts such as essays, reports, emails, blogs, etc.
2 文本扩充:LLM可以使用矢量数据库中的附加信息或详细信息扩充现有文本。例如,用户可以提供不完整、模糊或无聊的文本,LLM可以使用向量数据库中的相关事实、示例或表达式来丰富文本。这有助于提高文章、报告、电子邮件、博客等文本的质量和多样性。
3 Text transformation: LLMs can transform texts from one form to another using VDBs. For example, a user can provide a text that is written in one language, domain, or format, and the LLM can convert it to another language, domain, or format using VDBs. This can be useful for tasks such as translation, paraphrasing, simplification, summarization, etc.
3 文本转换:LLM可以使用VDBs(向量数据库系统)将文本从一种形式转换为另一种形式。例如,用户可以提供以一种语言、域或格式编写的文本,LLM可以使用VDBs(向量数据库系统)将其转换为另一种语言,域或格式。这对于翻译、转述、简化、总结等任务非常有用。
E. Retrieval-Based LLM
1 Definition: Retrieval-based LLM is a language model which retrieves from an external datastore (at least during inference time).
定义:基于检索的LLM是一种从外部数据存储中检索的语言模型(至少在推理时间内)。
2 Strength: Retrieval-based LLM is a high-level synergy of LLMs and databases, which has several advantages over LLM only.
优势:基于检索的LLM是LLM和数据库的高级协同,与仅LLM相比有几个优势。
Memorize long-tail knowledge. Retrieval-based LLM can access external knowledge sources that contain more specific and diverse information than the pre-trained LLM parameters. This allows retrieval-based LLM to answer in-domain queries that cannot be answered by LLM only. Easily updated. Retrieval-based LLM can dynamically retrieve the most relevant and up-to-date documents from the data sources according to the user input. This avoids the need to fine-tune the LLM on a fixed dataset, which can be costly and time-consuming.
记住长尾知识。基于检索的LLM可以访问外部知识源,这些知识源包含比预先训练的LLM参数更具体、更多样的信息。这允许基于检索的LLM回答仅LLM无法回答的域内查询。易于更新。基于检索的LLM可以根据用户输入从数据源中动态检索最相关和最新的文档。这避免了在固定数据集上微调LLM的需要,这可能是昂贵和耗时的。
Better for interpreting and verifying. Retrieval-based LLM can generate texts that cite their sources of information, which allows the user to validate the information and potentially change or update the underlying information based on requirements. Retrieval-based LLM can also use fact-checking modules to reduce the risk of hallucinations and errors. Improved privacy guarantees. Retrieval-based LLM can protect the user’s privacy by using encryption and anonymization techniques to query the data sources. This prevents the data sources from collecting or leaking the user’s personal information or preferences. Retrieval-based LLM can also use differential privacy methods to add noise to the retrieved documents or the generated texts, which can further enhance the privacy protection.
更适合解释和验证。基于检索的LLM可以生成引用其信息来源的文本,这允许用户验证信息,并可能根据需求更改或更新基础信息。基于检索的LLM还可以使用事实核查模块来降低幻觉和错误的风险。改进了隐私保障。基于检索的LLM可以通过使用加密和匿名技术来查询数据源,从而保护用户的隐私。这防止了数据源收集或泄露用户的个人信息或偏好。基于检索的LLM还可以使用差分隐私方法来给检索到的文档或生成的文本添加噪声,这可以进一步加强隐私保护。
Reduce time and money cost. Retrieval-based LLM can save time and money for the user by reducing the computational and storage resources required for running the LLM.This is because retrieval-based LLM can leverage the existing data sources as external memory, rather than storing all the information in the LLM parameters. Retrieval-based LLM can also use caching and indexing techniques to speed up the document retrieval and passage extraction processes.
减少时间和金钱成本。基于检索的LLM可以通过减少运行LLM所需的计算和存储资源来为用户节省时间和金钱。这是因为基于检索的LLM可以利用现有的数据源作为外部存储器,而不是将所有信息存储在LLM参数中。基于检索的LLM还可以使用缓存和索引技术来加快文档检索和段落提取过程。
3 Inference: Multiple parts of the data flow are involved in the inference session.
推理:推理会话涉及数据流的多个部分。
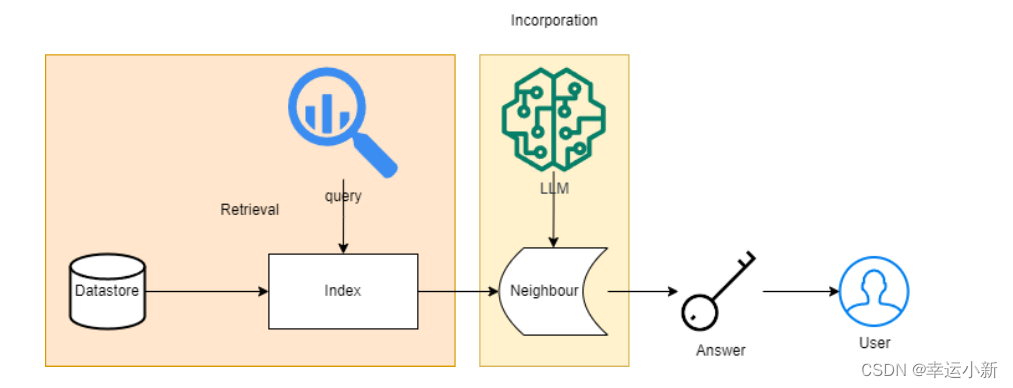
Fig. 2. A retrieval-based LLM inference dataflow.
图 2. 基于检索的 LLM 推理数据流。
Datastore. The data store can be very diverse, it can have only one modality, such as a raw text corpus, or a vector database that integrates data of different modalities, and its treatment of the data determines the specific algorithms for subsequent retrieval. In the case of raw text corpus, which are generally at least a billion to trillion tokens, the dataset itself is unlabeled and unstructured, and can be used as a original knowledge base.
数据存储。数据存储可以是非常多样化的,它可以只有一种模态,例如原始文本语料库,或者集成不同模态数据的矢量数据库,并且它对数据的处理决定了后续检索的特定算法。在原始文本语料库的情况下,数据集本身是未标记的和非结构化的,可以用作原始知识库。
Index. When the user enters a query, it can be taken as the input for retrieval, followed by using a specific algorithm to find a small subset of the datastore that is closest to the query, in the case of vector databases the specific algorithms are the NNS and ANNS algorithms mentioned earlier.
索引。当用户输入查询时,可以将其作为检索的输入,然后使用特定的算法找到最接近查询的数据存储的一小部分,在矢量数据库的情况下,特定的算法是前面提到的NNS和ANNS算法。
F. Synergized Example
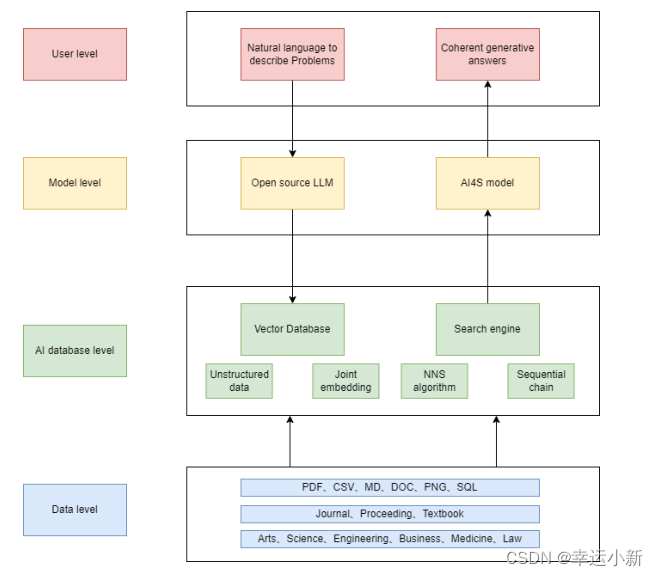
Fig. 3. A complex application of vector database + LLM for scientific research.
图3。一个复杂的应用向量数据库+ LLM的科学研究。
For a workflow that incorporates a large language model and a vector database, it can be understood by splitting it into four levels: the user level, the model level, the AI database level, and the data level, respectively.
对于包含大型语言模型和矢量数据库的工作流,可以通过将其分为四个级别来理解:用户级别、模型级别、人工智能数据库级别和数据级别。
For a user who has never been exposed to large language modeling, it is possible to enter natural language to describe their problem. For a user who is proficient in large language modeling, a well-designed prompt can be entered.
对于从未接触过大型语言建模的用户来说,可以输入自然语言来描述他们的问题。对于精通大型语言建模的用户,可以输入精心设计的提示。
The LLM next processes the problem to extract the key-words in it, or in the case of open source LLMs, the corresponding vector embeddings can be obtained directly.
LLM接下来处理该问题以提取其中的关键词,或者在开源LLM的情况下,可以直接获得相应的向量嵌入。
The vector database stores unstructured data and their joint embeddings. The next step is to go to the vector database to find similar nearest neighbors. The ones obtained from the sequences in the big language model are compared with the vector encodings in the vector database, by means of the NNS or ANNS algorithms. And different results are derived through a predefined serialization chain, which plays the role of a search engine.
矢量数据库存储非结构化数据及其联合嵌入。下一步是转到矢量数据库,查找相似的最近邻居。通过NNS或ANNS算法,将从大语言模型中的序列中获得的编码与向量数据库中的向量编码进行比较。不同的结果是通过一个预定义的序列化链得出的,它扮演着搜索引擎的角色。
If it is not a generalized question, the results derived need to be further put into the domain model, for example, imagine we are seeking an intelligent scientific assistant, which can be put
into the model of AI4S to get professional results. Eventually it can be placed again into the LLM to get coherent generated results.
如果这不是一个广义的问题,则需要将得出的结果进一步放入领域模型中,例如,想象我们正在寻找一个智能的科学助理,它可以放入AI4S的模型中以获得专业的结果。最终,可以将其再次放入LLM中以获得相干生成的结果。
For the data layer located at the bottom, one can choose from a variety of file formats such as PDF, CSV , MD, DOC,PNG, SQL, etc., and its sources can be journals, conferences,textbooks, and so on. Corresponding disciplines can be art,science, engineering, business, medicine, law, and etc.
对于位于底部的数据层,可以从PDF、CSV、MD、DOC、PNG、SQL等多种文件格式中进行选择,其来源可以是期刊、会议、教科书等。相应的学科可以是艺术、科学、工程、商业、医学、法律等。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- HuoCMS|免费开源可商用CMS建站系统HuoCMS 2.0下载(thinkphp内核)
- 通俗易懂实现功能强大的实战项目 springboot+java+vue+mysql 汽车租赁管理系统
- std::atomic<int> volatile
- C# 将HTML网页或HTML字符串转换为PDF文件
- pod控制器
- 用23种设计模式打造一个cocos creator的游戏框架----(二十)解析器模式
- java中如何创建一个自己的数组
- 基于双闭环PI的SMO无速度控制系统simulink建模与仿真
- HTML学生个人网站作业设计——HTML+CSS+JavaScript简单的大学生书店网页制作(13页) web期末作业设计网页 web结课作业的源码 web网页设计实例作业
- Flink系列之:监控反压