Intro project based on BERT
LeeMeng - 進擊的 BERT:NLP 界的巨人之力與遷移學習
这篇博客使用的是PyTorch,如果对PyTorch的使用比较陌生,建议直接去看PyTorch本身提供的tutorial,写的非常详细,还有很多例子。
这篇博客除了会介绍BERT之外,也会展示如何使用BERT做迁移学习(Transfer Learning)。
BERT介绍
语言模型
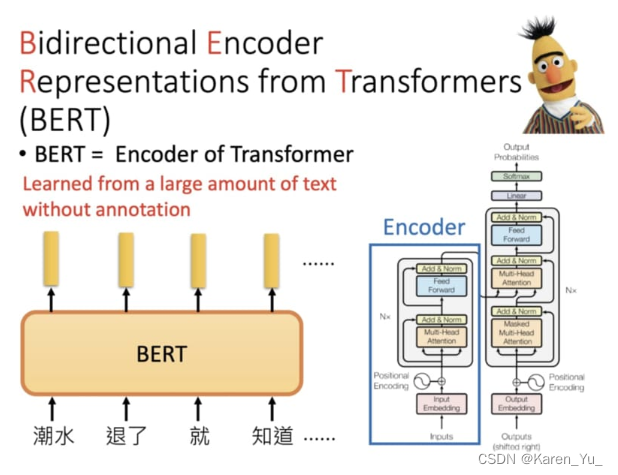
BERT,其实就是Transformer中的encoder。是语言模型的变形。
一起入门语言模型(Language Models) - 知乎 (zhihu.com)
(在之前NLP的部分其实就提到的语言模型,让我盲答的话我会举例描述这就像已知我说了某个词A,那么我下一个说词B的概率,这种感觉就很类似我们手机上的输入法,输入一个词之后会给出联想词,点击之后又会给出新的联想)
---以下为引用---
什么是语言模型呢?一句话,语言模型是这样一个模型:对于任意的词序列,它能够计算出这个序列是一句话的概率。举俩例子就明白了,比如词序列A:“知乎|的|文章|真|水|啊”,这个明显是一句话,一个好的语言模型也会给出很高的概率,再看词序列B:“知乎|的|睡觉|苹果|好快”,这明显不是一句话,如果语言模型训练的好,那么序列B的概率就很小很小。
N-gram LM、FeedForward Neural Network LM、RNN LM和GPT都属于LM。
从文本生成角度来看,我们也可以给出如下的语言模型定义:给定一个短语(一个词组或一句话),语言模型可以生成(预测)接下来的一个词。
假设我们要为中文创建一个语言模型,?
表示词典,?
∈
,
,...,
?是一句话的概率?
?,其中,
≥0?。
现在问题来了,语言模型如何计算?
个句子,我们数一下在训练集中
出现的次数,不妨假定为?
?,则?
?。
可以想象出这个模型的预测能力几乎为0,一旦单词序列没有在训练集中出现过,模型的输出概率就是0,显然相当不合理。
我们可以根据概率论中的链式法则(chain rule)把
------
A Beginner's Guide to Language Models | Built In
A language model is a?probability distribution?over words or word sequences. In practice, it gives the probability of a certain word sequence being “valid.” Validity in this context does not refer to grammatical validity. Instead, it means that it resembles how people write, which is what the language model learns. This is an important point. There’s no magic to a language model like other?machine learning models, particularly?deep neural networks, it’s just a tool to incorporate abundant information in a concise manner that’s reusable in an out-of-sample context.
语言模型是单词或单词序列的概率分布。语言模型不像其他机器学习模型,特别是深度神经网络,它只是一个工具,以简洁的方式整合丰富的信息,可以在样本外的环境中重用。
The abstract understanding of natural language, which is necessary to infer word probabilities from context, can be used for a number of tasks. Lemmatization or stemming aims to reduce a word to its most basic form, thereby dramatically decreasing the number of tokens. These algorithms work better if the part-of-speech role of the word is known. A verb’s postfixes can be different from a noun’s postfixes, hence the rationale for part-of-speech tagging (or?POS-tagging), a common task for a language model.
对自然语言的抽象理解是从上下文推断单词概率所必需的,它可以用于许多任务。词源化或词干化旨在将单词减少到最基本的形式,从而大大减少标记的数量。如果知道单词的词性作用,这些算法会更好地工作。(这里插一句,如果我没有记错的话BERT做embedded的方式有点是WordPiece,也就是会统计那些部分出现的更多,把出现的少的词破开,找到里面隐含的出现比较多的作为token->很类似词根)
With a good language model, we can perform?extractive or abstractive summarization?of texts. If we have models for different languages, a?machine translation?system can be built easily.
有了好的语言模型,我们就可以对文本进行抽取或抽象的摘要。如果我们有不同语言的模型,机器翻译系统就可以很容易地建立起来。
There are two types of language models:?
- Probabilistic methods.
- Neural network-based modern language models
第一个比如N-gram,第二个比如RNN, Transformer
语言模型做的是在给定一些词的前提下,去估计下一个词出现的概率分布。比如下面的式子表示的是给定前t个在字典里的词,估计第t+1个词的概率分布:
表示词典
中的任意词汇。
为什么要训练语言模型?
1. 有很多无监督数据,不同于计算机视觉中的ImageNet找人标注数据,如果要训练语言模型,网络上的所有文本都是潜在的数据集(BERT使用的是维基百科和BooksCorpus)
(这里断一下,在李宏毅的课程中提到,虽然相比之下BERT在机器翻译上可能不太OK,但是给BERT看了104种语言的维基百科之后,BERT自己也能学会翻译,即使我们不告诉它哪些文字是一致的)
2. 学习语法结构,解读语义。通过特征提取/fine-tuning有效的训练下游任务并提升表现。
(这里也断一下,在课程中也有提到,不同的任务中BERT最重要的层是不一样的,也就是某个任务特别需要BERT的哪些层。更复杂的任务可能需要的任务比较靠后。)
3. 减少处理不同NLP任务所需要的architecture engineering成本(换句话说就是不用自己从头搭了,直接fine-tuning就好啦)
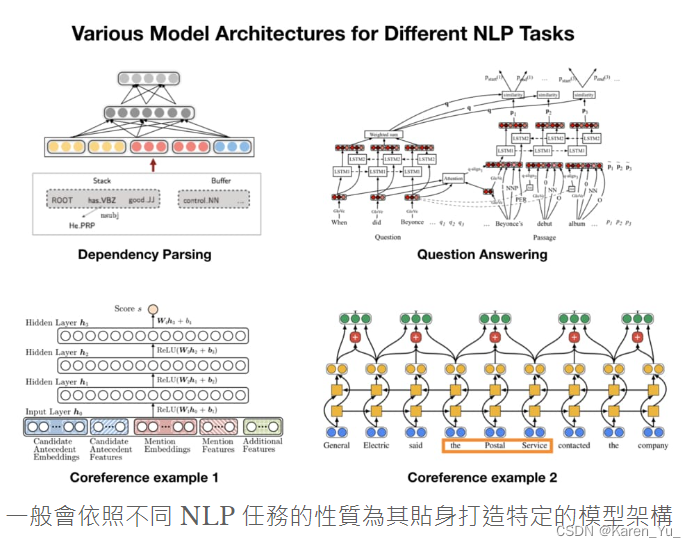
可以处理各种NLP任务的通用架构
BERT使用Transformer的encoder,大量文本和两个预训练目标(mask词预测,句子判断),训练得到一个可以用于(fine-tuning即可)多个下游NLP任务的模型。
文章指出这是近年来NLP领域非常流行的两阶段迁移学习。使用BERT就可以用同一个架构训练多种NLP任务,减少自己architecture engineering成本。
但是自己训练很贵。不过TensorFlow和PyTorch可以将已经训练好的模型载入,这样就只需要做fine-tuning就好了。
训练的时候在做什么
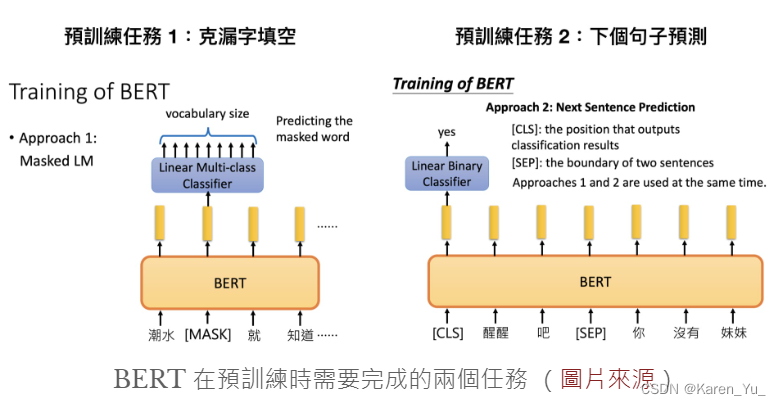
模型体验
import torch
from transformers import BertTokenizer
from IPython.display import clear_output
PRETRAINED_MODEL_NAME = "bert-base-chinese" # 指定繁簡中文 BERT-BASE 預訓練模型
# 取得此預訓練模型所使用的 tokenizer
tokenizer = BertTokenizer.from_pretrained(PRETRAINED_MODEL_NAME)
clear_output()
print("PyTorch 版本:", torch.__version__)这里选择的是bert-base-chinese,除此之外,还有其他版本,区别在于使用的文本/是否区分大小写,层数的不同,预训练是遮住WordPiece还是整个word
在Hugging Face上下载并使用Bert-base-Chinese_bert-base-chinese下载-CSDN博客
Hugging Face – The AI community building the future.
我在这里尝试了
text = '[CLS] 多年[MASK]后,面对行刑队,奥雷里亚诺·布恩迪亚上校将会回想起,父亲带他去见识冰块的那个遥远的下午。'
tokens = tokenizer.tokenize(text)
ids = tokenizer.convert_tokens_to_ids(tokens)
print(text)
print(tokens[:10], '...')
print(ids[:10], '...')from transformers import BertForMaskedLM
import torch
# 除了 tokens 以外我們還需要辨別句子的 segment ids
tokens_tensor = torch.tensor([ids]) # (1, seq_len)
segments_tensors = torch.zeros_like(tokens_tensor) # (1, seq_len)
maskedLM_model = BertForMaskedLM.from_pretrained(model_name)
# 使用 masked LM 估計 [MASK] 位置所代表的實際 token
maskedLM_model.eval()
with torch.no_grad():
outputs = maskedLM_model(tokens_tensor, segments_tensors)
predictions = outputs[0]
# (1, seq_len, num_hidden_units)
del maskedLM_model
# 將 [MASK] 位置的機率分佈取 top k 最有可能的 tokens 出來
# 要注意这里,不是只要把文字[MASK]就可以的,要告诉[MASK]的位置在哪里,不然就会还在输出里看到[MASK]
masked_index = 3
k = 3
probs, indices = torch.topk(torch.softmax(predictions[0, masked_index], -1), k)
predicted_tokens = tokenizer.convert_ids_to_tokens(indices.tolist())
# 顯示 top k 可能的字。一般我們就是取 top 1 當作預測值
print("输入 tokens :", tokens[:10], '...')
print('-' * 50)
for i, (t, p) in enumerate(zip(predicted_tokens, probs), 1):
tokens[masked_index] = t
print("Top {} ({:2}%):{}".format(i, int(p.item() * 100), tokens[:10]), '...')https://github.com/KarenYu729/Getting-Start-in-BERT/blob/main/BERT_model_practice_lab1.ipynb
尝试的内容如上,用的是colab,不太好搬,放GitHub上方便看。
ELMo 利用獨立訓練的雙向兩層 LSTM 做語言模型並將中間得到的隱狀態向量串接當作每個詞彙的 contextual word repr.;GPT 則是使用 Transformer 的 Decoder 來訓練一個中規中矩,從左到右的單向語言模型。你可以參考我另一篇文章:直觀理解 GPT-2 語言模型並生成金庸武俠小說來深入了解 GPT 與 GPT-2。
BERT 跟它們的差異在於利用 MLM(即克漏字)的概念及 Transformer Encoder 的架構,擺脫以往語言模型只能從單個方向(由左到右或由右到左)估計下個詞彙出現機率的窘境,訓練出一個雙向的語言代表模型。這使得 BERT 輸出的每個 token 的 repr.?
Tn?都同時蘊含了前後文資訊,真正的雙向?representation。跟以往模型相比,BERT 能更好地處理自然語言
简单而言ELMO是双向LSTM,GPT是Tranformer的decoder,BERT是Transformer的encoder。GPT是单向的(从左到右),BERT是双向的(从左到右从右到左都可以)。
BERT fine-tuning做下游任务
需要怎么做?
1. 准备原始文本数据
2. 将原始文本转换成BERT需要的输入格式
3. 在BERT上加入新的layer组成新的下游任务模型
4. 训练模型
5. 对新样本使用模型
准备数据
数据集
这里采用的例子是:WSDM - Fake News Classification | Kaggle
给定一篇假新闻的标题a和一篇即将发布的新闻的标题B,将B分为3类:B和A是相同的假新闻,B反驳了假新闻A(B不是假新闻),B与A没有关系
- train.csv?-?训练数据包含320,767对中英文新闻。
- test.csv?- 测试数据包含80126对中英文新闻。大约25%的测试数据被设置为公开的,用于计算您在领先板上显示的准确性。其余75%的私人数据将用于计算您的最终比赛结果。
- sample_submission.csv?- 格式与测试数据相同
每列的信息:
- id?- the id of each news pair.
- tid1?- the id of fake news title 1.
- tid2?- the id of news title 2.
- title1_zh?- the fake news title 1 in Chinese.
- title2_zh?- the news title 2 in Chinese.
- title1_en?- the fake news title 1 in English.
- title2_en?- the news title 2 in English.
- label?- indicates the relation between the news pair: agreed/disagreed/unrelated.
英文的标题由中文机器翻译得到。
数据清理
import os
import pandas as pd
# 因为数据集是压缩的形式,这里需要先进行解压
# 似乎这种策略并非主流方法,参见参考链接【1】
os.system("unzip train.csv.zip")
# 读取training set
df_train = pd.read_csv("train.csv")
# 找到所有A新闻标题为空OR B新闻为空/空字符串/0的行
empty_title = ((df_train['title2_zh'].isnull()) \
| (df_train['title1_zh'].isnull()) \
| (df_train['title2_zh'] == '') \
| (df_train['title2_zh'] == '0'))
# 只保留不为空的
df_train = df_train[~empty_title]
# 个人觉得这里还可以优化,因为我们不能保证A新闻就没有为空字符串或者为0的情况
# 如果可以的话完全可以对整个数据集找一下是null的是空的数量,也估算一下被删去的数据有多少
# 去掉过长的样本,使用BERT的话要注意BERT可能没办法把整个输入序列放进GPU
# 参考链接【2】中也指出30是一个人为设置的值,每句话只能长度为30(不够也会补齐)
MAX_LENGTH = 30
# 对AB的title都截断
df_train = df_train[~(df_train.title1_zh.apply(lambda x : len(x)) > MAX_LENGTH)]
df_train = df_train[~(df_train.title2_zh.apply(lambda x : len(x)) > MAX_LENGTH)]
# 只抽取1%的数据,看BERT的效果
SAMPLE_FRAC = 0.01
# fix了random_state保证重复运行代码的时候仍然抽出相同的数据
df_train = df_train.sample(frac=SAMPLE_FRAC, random_state=9527)
# 因为之前清理数据的时候去掉了null啊空字符串啊0啊,这种,在这里重新排一下index
# 重新从0开始
df_train = df_train.reset_index()
# 在kaggle上也说了这个比赛的英文是中文机器翻译的结果,也推荐有中文背景的同学来做
# 这样能更好的理解
# 这里在做的就是,把英文的部分,数据id,
# 新闻标题id(不是上面重排的id,上面的是dataframe的id)去掉
df_train = df_train.loc[:, ['title1_zh', 'title2_zh', 'label']]
df_train.columns = ['text_a', 'text_b', 'label']
# idempotence, 另存成 tsv 供 PyTorch 使用
# 换格式
df_train.to_csv("train.tsv", sep="\t", index=False)
print("訓練樣本數:", len(df_train))
df_train.head()
参考链接:
【1】Python内置解压缩库:解析与实践 - 知乎 (zhihu.com)
【2】在Hugging Face上下载并使用Bert-base-Chinese_bert-base-chinese下载-CSDN博客
在这里提出一个问题,为什么要改成tsv文件?
在之前的Transformer - Attention is all you need 论文阅读-CSDN博客中搭了一个简单的RNN网络,在这里也对数据进行了处理,但是是属于把文字都转成英语,然后采用one-hot编码,作为输入的Tensor,显然和这里在做的不是一回事。
同时文章中也指出这是为了给PyTorch使用。
什么是tsv?
tsv文件与csv文件的区别以及如何转换_tsv文件转换成csv文件-CSDN博客
把分隔符改成'\t',也就是制表符
个人猜测这里这么做的原因是方便后续做拼接,加[SEP]
df_train.label.value_counts() / len(df_train)
"""
unrelated 0.679338
agreed 0.294317
disagreed 0.026346
Name: label, dtype: float64
"""可以看出现在抽出来的不到1%的数据(本来只抽出来1%,但是还扣掉了过长的数据)中,67%的都是unrelated类别(当然这也是unbalance)
os.system("unzip test.csv.zip")
df_test = pd.read_csv("test.csv")
df_test = df_test.loc[:, ["title1_zh", "title2_zh", "id"]]
df_test.columns = ["text_a", "text_b", "Id"]
df_test.to_csv("test.tsv", sep="\t", index=False)
print("預測樣本數:", len(df_test))
df_test.head()
同理,这里也对测试数据做相似的处理。
转换成BERT需要的输入格式
最上面的红色格子是输入的句子。这里是两个句子“my dog is cure”和“he likes playing”。最开头的[CLS]是用来分类的,[SEP]是区分两个句子,“##ing”是因为和前面的play是一个词,但是因为playing出现的概率不高,所以这里砍成了play+ing,这两个出现的概率更高。
要做的embedding除了token的embedding,还有所在的句子的embedding,还有位置的embedding。token embedding对应的是WordPiece,segment embedding代表的是不同的句子的位置(是学习得到的),position embedding类似transformer中的位置编码。一直到这里都是论文中的例子。
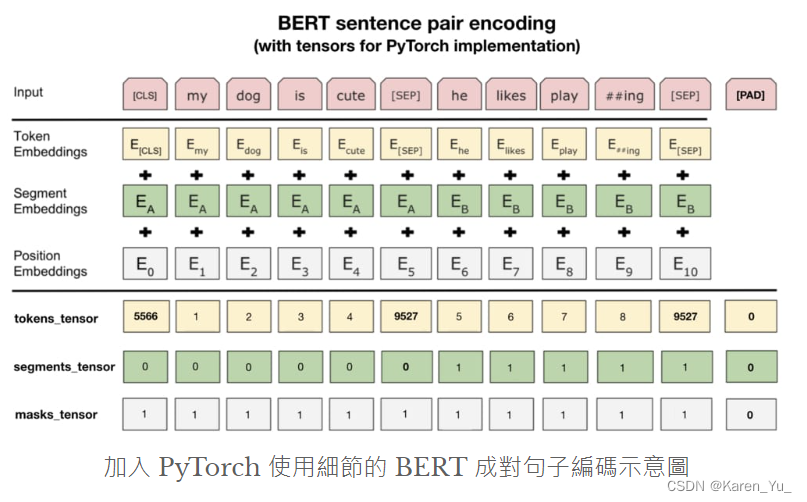
实际使用PyTorch中的BERT的时候,我们需要的是最下面的分割线的信息。如果看了前面的模型体验的话,就能理解这里的token_tensor指的是每个token的索引值。可以参见这里:

segment_tensor用来标识是句子A还是句子B,如果是A就是0,B就是1。另外[SEP]分隔符是属于句子A的。
masks_tensor用来标识自注意力的范围,1标识看,0标识不用看了(前面说了设定的长度是30,所以不到30的会加padding,[PAD]就是对应padding的token)。
from torch.utils.data import Dataset
class FakeNewsDataset(Dataset):
# 读取tsv 并初始化一些参数
def __init__(self, mode, tokenizer):
# 我猜这里的意思是可能需要validation set
assert mode in ["train", "test"] # 一般訓練你會需要 dev set
self.mode = mode
# 大數據你會需要用 iterator=True
# 这里的意思是,如果数据量比较大的情况下,需要设置iterator=True
# 可以看参考链接【1】
# 因为这里是tsv格式,所以要制定分隔符
self.df = pd.read_csv(mode + ".tsv", sep="\t").fillna("")
self.len = len(self.df)
# 给label标记
self.label_map = {'agreed': 0, 'disagreed': 1, 'unrelated': 2}
# tokenizer在前面的代码中已经指定了
self.tokenizer = tokenizer # 我們將使用 BERT tokenizer
# 定義回傳一筆訓練 / 測試數據的函式
def __getitem__(self, idx):
# 如果是测试,获取测试数据,这里之所以是:2是因为
# 前两位是AB两个新闻标题,第三位是label
if self.mode == "test":
text_a, text_b = self.df.iloc[idx, :2].values
label_tensor = None
# 不是测试,获取训练数据,这里也要用label
else:
text_a, text_b, label = self.df.iloc[idx, :].values
# 将label文字转换成Tensor
# 將 label 文字也轉換成索引方便轉換成 tensor
# 这里:self.label_map = {'agreed': 0, 'disagreed': 1, 'unrelated': 2}
# 按照前面的设定把label变成数字
label_id = self.label_map[label]
# 转为Tensor
label_tensor = torch.tensor(label_id)
# 建立第一個句子的 BERT tokens 並加入分隔符號 [SEP]
# 按照要求合成token,第一位是[CLS],
# 后面是按照token的转换得到新的序列
word_pieces = ["[CLS]"]
tokens_a = self.tokenizer.tokenize(text_a)
# tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
# 换成[CLS]+TOKEN之后再缀上[SEP]
word_pieces += tokens_a + ["[SEP]"]
len_a = len(word_pieces)
# 第二個句子的 BERT tokens
# 把第二个句子换乘BERT的token,并且缀在后面
tokens_b = self.tokenizer.tokenize(text_b)
word_pieces += tokens_b + ["[SEP]"]
len_b = len(word_pieces) - len_a
# 將整個 token 序列轉換成索引序列
ids = self.tokenizer.convert_tokens_to_ids(word_pieces)
tokens_tensor = torch.tensor(ids)
# 设置segment Tensor,第一句是1,第二句是0
# 还有一个Tensor是masks_tensor(这个好像没有做初始化),应该是在后面读入的时候
# 按一定比例随机给mask
# 將第一句包含 [SEP] 的 token 位置設為 0,其他為 1 表示第二句
segments_tensor = torch.tensor([0] * len_a + [1] * len_b,
dtype=torch.long)
return (tokens_tensor, segments_tensor, label_tensor)
def __len__(self):
return self.len
# 初始化一個專門讀取訓練樣本的 Dataset,使用中文 BERT 斷詞
trainset = FakeNewsDataset("train", tokenizer=tokenizer)参考链接:
【1】Python学习笔记:pandas.read_csv分块读取大文件(chunksize、iterator=True) - Hider1214 - 博客园 (cnblogs.com)
# 選擇第一個樣本
sample_idx = 0
# 將原始文本拿出做比較
text_a, text_b, label = trainset.df.iloc[sample_idx].values
# 利用剛剛建立的 Dataset 取出轉換後的 id tensors
tokens_tensor, segments_tensor, label_tensor = trainset[sample_idx]
# 將 tokens_tensor 還原成文本
tokens = tokenizer.convert_ids_to_tokens(tokens_tensor.tolist())
combined_text = "".join(tokens)
# 渲染前後差異,毫無反應就是個 print。可以直接看輸出結果
print(f"""[原始文本]
句子 1:{text_a}
句子 2:{text_b}
分類 :{label}
--------------------
[Dataset 回傳的 tensors]
tokens_tensor :{tokens_tensor}
segments_tensor:{segments_tensor}
label_tensor :{label_tensor}
--------------------
[還原 tokens_tensors]
{combined_text}
""")
设置好dataset之后需要dataloader把数据按mini-batch一个一个放进去训练。
from torch.utils.data import DataLoader
from torch.nn.utils.rnn import pad_sequence
# 這個函式的輸入 `samples` 是一個 list,裡頭的每個 element 都是
# 剛剛定義的 `FakeNewsDataset` 回傳的一個樣本,每個樣本都包含 3 tensors:
# - tokens_tensor
# - segments_tensor
# - label_tensor
# 它會對前兩個 tensors 作 zero padding,並產生前面說明過的 masks_tensors
# 创建mini-batch
def create_mini_batch(samples):
# 读入的sample是上面的dataset返回的:
# return (tokens_tensor, segments_tensor, label_tensor)
# 所以是可以把Tensor一个一个拿出来的
#这里要注意:如果是训练,那么就到此为止了,因为训练没有label(这里label设置为None)
tokens_tensors = [s[0] for s in samples]
segments_tensors = [s[1] for s in samples]
# 測試集有 labels
# 如果是测试,那就还有label Tensor(不是None的版本)
# 有label->取label,没有label->设为None
if samples[0][2] is not None:
label_ids = torch.stack([s[2] for s in samples])
else:
label_ids = None
# zero pad 到同一序列長度
# 请看参考链接【1】【2】
tokens_tensors = pad_sequence(tokens_tensors,
batch_first=True)
segments_tensors = pad_sequence(segments_tensors,
batch_first=True)
# attention masks,將 tokens_tensors 裡頭不為 zero padding
# 的位置設為 1 讓 BERT 只關注這些位置的 tokens
# 设置masks_tensor,先全部设为0->不要关注
# 文章提到[MASK]仅在预训练的时候会使用,在fine-tuning和feature-extraction的时候不会用到
# 参考链接【3】【4】
masks_tensors = torch.zeros(tokens_tensors.shape,
dtype=torch.long)
# 这里masked_fill是修改的复制的Tensor,而不是修改原始的Tensor
# 简单来说,这里就是把tokens_tensors中有数据的都置为1(padding的部分不看)
masks_tensors = masks_tensors.masked_fill(
tokens_tensors != 0, 1)
return tokens_tensors, segments_tensors, masks_tensors, label_ids
# 初始化一個每次回傳 64 個訓練樣本的 DataLoader
# 利用 `collate_fn` 將 list of samples 合併成一個 mini-batch 是關鍵
# mini-batch的大小是64
BATCH_SIZE = 64
# dataloader
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE,
collate_fn=create_mini_batch)参考链接:
【1】torch.nn.utils.rnn.pad_sequence — PyTorch 2.1 documentation
【2】pad_sequence —— 填充句子到相同长度_使用<pad>符号填充成统一长度-CSDN博客
【3】torch.Tensor.masked_fill — PyTorch 2.1 documentation
【4】masked_fill_() - masked_fill() - v1.5.0_masked是置零吗-CSDN博客
data = next(iter(trainloader))
tokens_tensors, segments_tensors, \
masks_tensors, label_ids = data
print(f"""
tokens_tensors.shape = {tokens_tensors.shape}
{tokens_tensors}
------------------------
segments_tensors.shape = {segments_tensors.shape}
{segments_tensors}
------------------------
masks_tensors.shape = {masks_tensors.shape}
{masks_tensors}
------------------------
label_ids.shape = {label_ids.shape}
{label_ids}
""")
这里是一个batch
添加layer完成下游任务
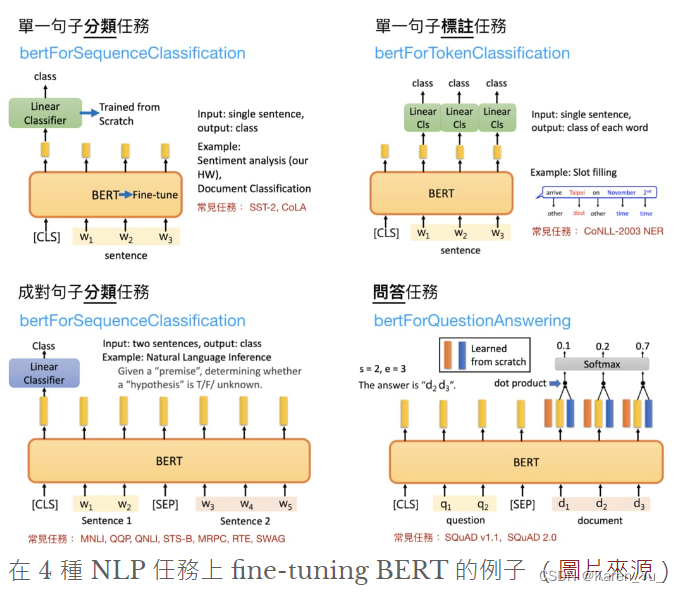
这张图的解释可以在BERT Intro-CSDN博客部分找到,不过我也推荐大家直接去听李宏毅的讲述李宏毅-ELMO, BERT, GPT讲解_哔哩哔哩_bilibili
假新闻分类任务显然是句子对分类的任务,也就是左下角那个模型
# 載入一個可以做中文多分類任務的模型,n_class = 3
from transformers import BertForSequenceClassification
PRETRAINED_MODEL_NAME = "bert-base-chinese"
NUM_LABELS = 3
model = BertForSequenceClassification.from_pretrained(
PRETRAINED_MODEL_NAME, num_labels=NUM_LABELS)
clear_output()
# high-level 顯示此模型裡的 modules
print("""
name module
----------------------""")
for name, module in model.named_children():
if name == "bert":
for n, _ in module.named_children():
print(f"{name}:{n}")
else:
print("{:15} {}".format(name, module))
简单来说就是分类的model是在BERT上加入了dropout和linear classifier。
model.config
"""
BertConfig {
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"directionality": "bidi",
"do_sample": false,
"eos_token_ids": 0,
"finetuning_task": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"is_decoder": false,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1
},
"layer_norm_eps": 1e-12,
"length_penalty": 1.0,
"max_length": 20,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_beams": 1,
"num_hidden_layers": 12,
"num_labels": 3,
"num_return_sequences": 1,
"output_attentions": false,
"output_hidden_states": false,
"output_past": true,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"pruned_heads": {},
"repetition_penalty": 1.0,
"temperature": 1.0,
"top_k": 50,
"top_p": 1.0,
"torchscript": false,
"type_vocab_size": 2,
"use_bfloat16": false,
"vocab_size": 21128
}
"""def get_predictions(model, dataloader, compute_acc=False):
predictions = None
correct = 0
total = 0
with torch.no_grad():
# 遍巡整個資料集
# 遍历整个dataloader(mini-batch)
for data in dataloader:
# 將所有 tensors 移到 GPU 上
if next(model.parameters()).is_cuda:
data = [t.to("cuda:0") for t in data if t is not None]
# 別忘記前 3 個 tensors 分別為 tokens, segments 以及 masks
# 且強烈建議在將這些 tensors 丟入 `model` 時指定對應的參數名稱
# 拿出之前确定的token,并且喂到模型里
tokens_tensors, segments_tensors, masks_tensors = data[:3]
outputs = model(input_ids=tokens_tensors,
token_type_ids=segments_tensors,
attention_mask=masks_tensors)
logits = outputs[0]
_, pred = torch.max(logits.data, 1)
# 用來計算訓練集的分類準確率
# compute_acc:是否需要计算acc,统计对的个数
if compute_acc:
labels = data[3]
total += labels.size(0)
correct += (pred == labels).sum().item()
# 將當前 batch 記錄下來
# _, pred = torch.max(logits.data, 1)
#
if predictions is None:
predictions = pred
else:
predictions = torch.cat((predictions, pred))
if compute_acc:
acc = correct / total
return predictions, acc
return predictions
# 讓模型跑在 GPU 上並取得訓練集的分類準確率
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("device:", device)
model = model.to(device)
_, acc = get_predictions(model, trainloader, compute_acc=True)
print("classification acc:", acc)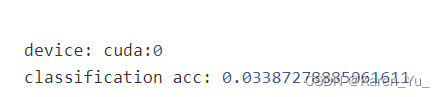
这里看到分类的结果并不好(这很合理,因为linear model只是随机初始化的)
训练下游任务
%%time
# 訓練模式
model.train()
# 使用 Adam Optim 更新整個分類模型的參數
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
EPOCHS = 6 # 幸運數字
for epoch in range(EPOCHS):
running_loss = 0.0
for data in trainloader:
tokens_tensors, segments_tensors, \
masks_tensors, labels = [t.to(device) for t in data]
# 將參數梯度歸零
optimizer.zero_grad()
# forward pass
outputs = model(input_ids=tokens_tensors,
token_type_ids=segments_tensors,
attention_mask=masks_tensors,
labels=labels)
loss = outputs[0]
# backward
loss.backward()
optimizer.step()
# 紀錄當前 batch loss
running_loss += loss.item()
# 計算分類準確率
_, acc = get_predictions(model, trainloader, compute_acc=True)
print('[epoch %d] loss: %.3f, acc: %.3f' %
(epoch + 1, running_loss, acc))(插一句,好可爱,这里还整幸运数字)

新样本测试
%%time
# 建立測試集。這邊我們可以用跟訓練時不同的 batch_size,看你 GPU 多大
testset = FakeNewsDataset("test", tokenizer=tokenizer)
testloader = DataLoader(testset, batch_size=256,
collate_fn=create_mini_batch)
# 用分類模型預測測試集
predictions = get_predictions(model, testloader)
# 用來將預測的 label id 轉回 label 文字
index_map = {v: k for k, v in testset.label_map.items()}
# 生成 Kaggle 繳交檔案
df = pd.DataFrame({"Category": predictions.tolist()})
df['Category'] = df.Category.apply(lambda x: index_map[x])
df_pred = pd.concat([testset.df.loc[:, ["Id"]],
df.loc[:, 'Category']], axis=1)
df_pred.to_csv('bert_1_prec_training_samples.csv', index=False)
df_pred.head()
这里的准确率可以达到80%。
这里只是用了训练集中不到1%的数据而已
# 觀察訓練過後的 model 在處理假新聞分類任務時關注的位置
# 去掉 `state_dict` 即可觀看原始 BERT 結果
model_version = 'bert-base-chinese'
finetuned_model = BertModel.from_pretrained(model_version,
output_attentions=True, state_dict=model.state_dict())
# 兩個句子
sentence_a = "烟王褚时健去世"
sentence_b = "辟谣:一代烟王褚时健安好!"
# 得到 tokens 後丟入 BERT 取得 attention
inputs = tokenizer.encode_plus(sentence_a, sentence_b, return_tensors='pt', add_special_tokens=True)
token_type_ids = inputs['token_type_ids']
input_ids = inputs['input_ids']
attention = finetuned_model(input_ids, token_type_ids=token_type_ids)[-1]
input_id_list = input_ids[0].tolist() # Batch index 0
tokens = tokenizer.convert_ids_to_tokens(input_id_list)
call_html()
head_view(attention, tokens)

这个方法需要安装一个库(具体请参考LeeMeng - 進擊的 BERT:NLP 界的巨人之力與遷移學習)
KerasNLP starter notebook Disaster Tweets | Kaggle
这个例子使用的应该是TensorFlow
import相应库
!pip install keras-core --upgrade
!pip install -q keras-nlp --upgrade
# This sample uses Keras Core, the multi-backend version of Keras.
# The selected backend is TensorFlow (other supported backends are 'jax' and 'torch')
import os
os.environ['KERAS_BACKEND'] = 'tensorflow'
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import tensorflow as tf
import keras_core as keras
import keras_nlp
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
print("TensorFlow version:", tf.__version__)
print("KerasNLP version:", keras_nlp.__version__)加载数据(看看数据是什么样)
Files
- train.csv?- the training set
- test.csv?- the test set
- sample_submission.csv?- a sample submission file in the correct format
Columns
id?- a unique identifier for each tweettext?- the text of the tweetlocation?- the location the tweet was sent from (may be blank)keyword?- a particular keyword from the tweet (may be blank)target?- in?train.csv?only, this denotes whether a tweet is about a real disaster (1) or not (0)
df_train = pd.read_csv("/kaggle/input/nlp-getting-started/train.csv")
df_test = pd.read_csv("/kaggle/input/nlp-getting-started/test.csv")
print('Training Set Shape = {}'.format(df_train.shape))
print('Training Set Memory Usage = {:.2f} MB'.format(df_train.memory_usage().sum() / 1024**2))
print('Test Set Shape = {}'.format(df_test.shape))
print('Test Set Memory Usage = {:.2f} MB'.format(df_test.memory_usage().sum() / 1024**2))
df_train.head()
简单来说就是训练数据有7613条,测试数据有3263条。从展示的部分可以看出,keyword和location是有可能为空的(当然在前面的介绍里也提到了)。
df_train["length"] = df_train["text"].apply(lambda x : len(x))
df_test["length"] = df_test["text"].apply(lambda x : len(x))
print("Train Length Stat")
print(df_train["length"].describe())
print()
print("Test Length Stat")
print(df_test["length"].describe())
NLP with Disaster Tweets - EDA, Cleaning and BERT | Kaggle这里有关于数据更多的展示
处理数据
BATCH_SIZE = 32
NUM_TRAINING_EXAMPLES = df_train.shape[0]
TRAIN_SPLIT = 0.8
VAL_SPLIT = 0.2
STEPS_PER_EPOCH = int(NUM_TRAINING_EXAMPLES)*TRAIN_SPLIT // BATCH_SIZE
EPOCHS = 2
AUTO = tf.data.experimental.AUTOTUNE
from sklearn.model_selection import train_test_split
X = df_train["text"]
y = df_train["target"]
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=VAL_SPLIT, random_state=42)
X_test = df_test["text"]
# 这里batch的大小设置为了32模型
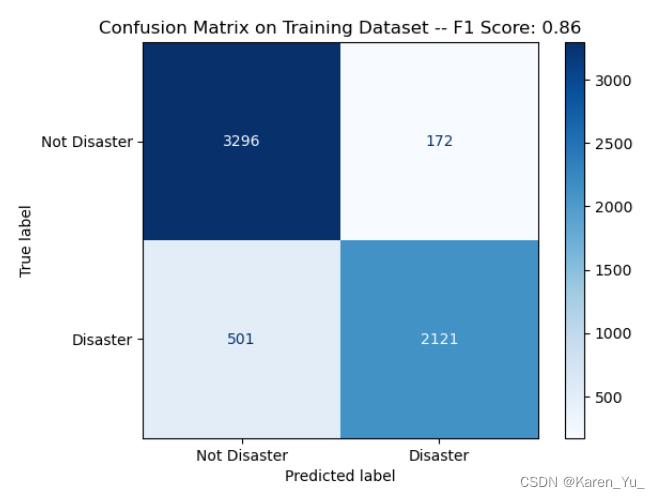
也是直接加载一个预训练好的模型,这里设置分类为2,因为在这个project里面,只要区分推文是表示有灾难在发生还是没有。采用的损失函数是SparseCategoricalCrossentropy,优化器是Adam(应该是李沐在讲这篇论文的时候提到作者讲的不是很清楚,似乎用的是个砍了一部分呢的Adam,并且给出的epoch数据也比较小,实际上要多训练几个epoch)。
具体的代码部分请参考KerasNLP starter notebook Disaster Tweets | Kaggle
——————————————————————————
又到了废话时间,实际上从这两个例子和我们在使用RNN对名字来源于哪个国家的例子中都可以看出,对于NLP,在训练的时候我们都要对数据进行一些处理。使得容易被模型使用。
这篇博客写完以后BERT还没有暂时告一段落,我会去试着做一下下面这个例子,也就是我一直在嘟囔的kaggle上面的"Getting Started" competitions。
做完之后,也还会有一个后续,我发现沐神在B站还发过BERT的使用的视频,会考虑看看,然后做个笔记。
这些都结束以后,会回归李宏毅的NLP课程~然后继续做笔记~不过中间可能会做一个GAN的相关的,因为发现隔壁的CV的"Getting Started" competitions使用的是GAN,之前其实做过相关的,但是没有用过GAN,有点遗憾,现在弥补一下,主打就是一个有遗憾就弥补。(估计能在2月之前结束,然后就可以快乐过年了)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- k8s中的整体架构 ,pod含义,服务类型,网络通讯等
- K8S学习指南(46)-k8s调度之污点与容忍度
- 架构篇02-架构设计的历史背景
- python蓝桥杯备考——字符串小知识点
- Day 46 动态规划 8
- 一致性算法Paxos
- 安装@vue/cli时候,升级版本造成冲突的解决方法
- 基于Springboot的任务发布平台设计与实现(源码齐全+调试)
- Docker命令---停止容器
- 【深度学习每日小知识】NLP 自然语言处理