【Hadoop】HDFS文件读写流程
文件的读取
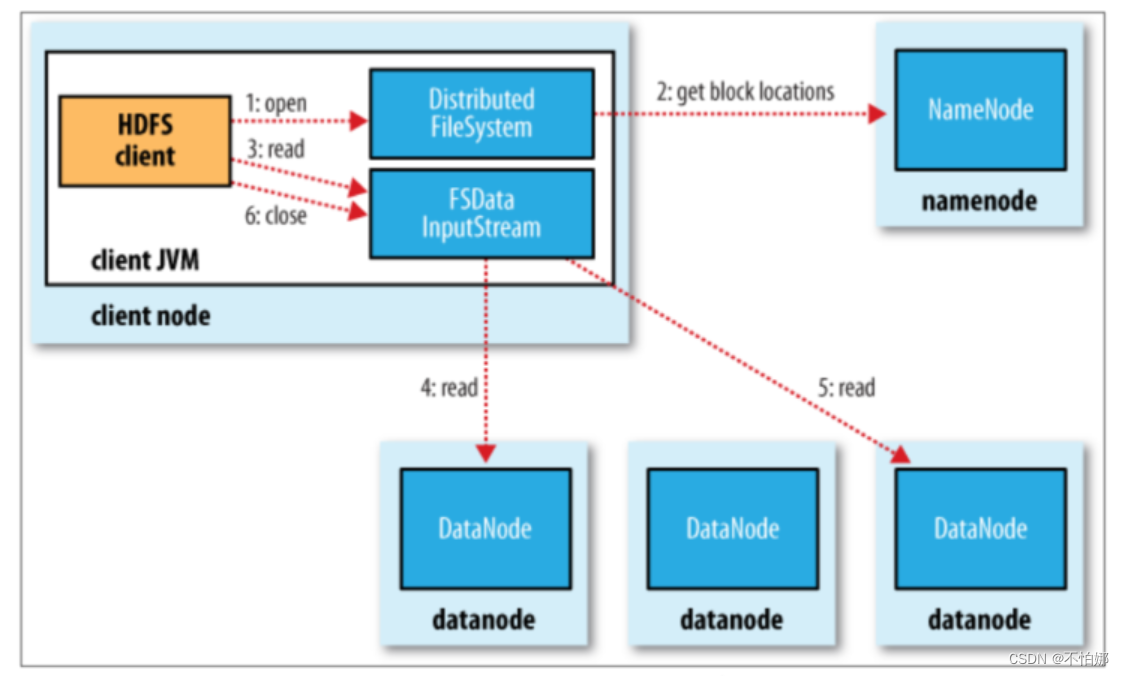
- 客户端调用 FileSystem 对象的 open()函数,打开想要读取的文件。其中FileSystem 是 DistributeFileSystem 的一个实例;
- DistributedFileSystem 通过使用 RPC(远程过程调用) 访NameNode 以确定文件起始块的位置,同一 Block 按照重复数会返回多个位置,这些位置按照 Hadoop 集群拓扑结构排序,距离客户端近的排在前面;
- DistributedFileSystem 返 回 FSDataInputStream 输入流给客户端, FSDataInputStream 存储着文件起始块的 DataNode 地址,通过对数据流反复调用 read()方法,可以将数据从 DataNode 传输到客户端;
- 当此数据块读取完成时,DFSInputStream 数据流和此 DataNode 的连接被关闭,然后再继续连接此文件下一个数据块的最近的 DataNode
- 当客户端读取完全部数据的时,会调用 FSDataInputStream 的 close()方法关闭该HDFS
文件的写入
-
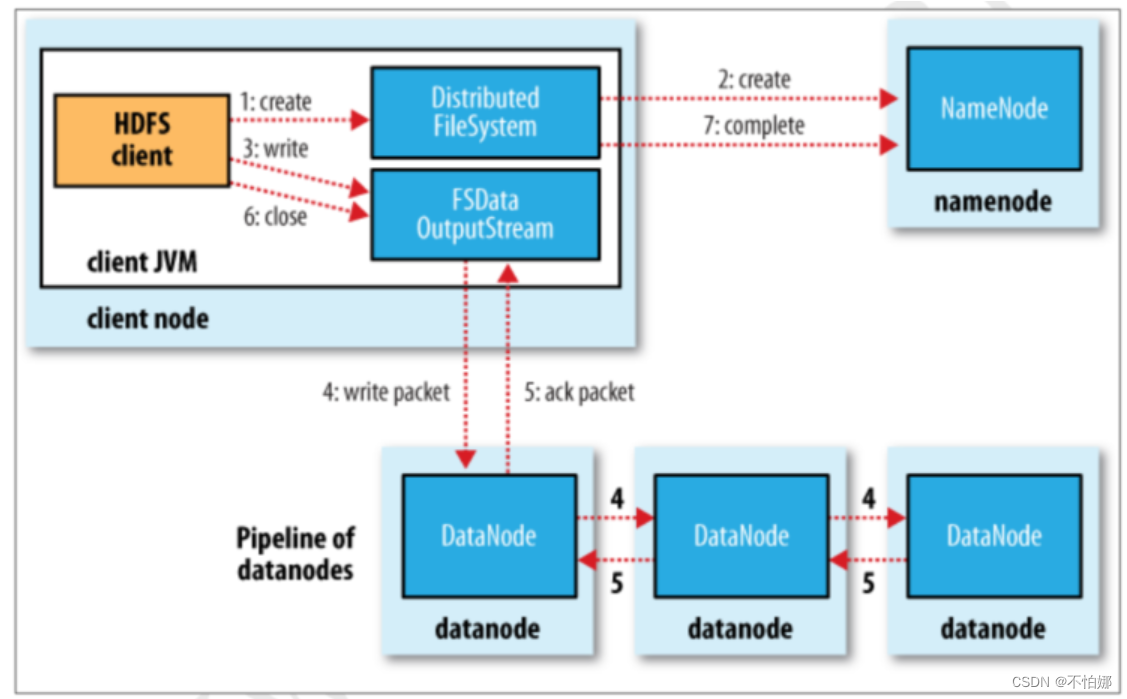
HDFS Client 通过调用 DistributedFileSystem 的 create()方法创建新文件;
-
DistributedFileSystem 通过 RPC 访问 NameNode, 在文件系统的命名空间中创建一个新的文件,创建前 NameNode 会验证客户端地权限并确认该文件不存在,如果检查通过,NameNode 会为新文件添加一条记录,否则就会抛出 IO 异常;
-
客户端开始写文件,DFSOutputStream 会将文件分割成 packets 数据包,HDFS 中每个 block 默认情况下是128M,由于每个块比较大,所以在写数据的过程中是把数据块拆分成一个个的数据包( packet )以管道的形式发送的。然后将这些 packets 写到其内部的一个叫做 data queue(数据队列)。data queue 会向 NameNode 节点请求适合存储数据副本的DataNode 节点的列表,然后这些 DataNode 之前生成一个 Pipeline 数据流管道,我们假设副本因子参数为3,那么这个数据流管道中就有三个 DataNode 节点;
-
首先 DFSOutputStream 会将 packets 向 Pipeline 数据流管道中的第一个 DataNod e节点写数据,第一个 DataNode 接收 packets 然后把 packets 写向 Pipeline 中的第二个节点,同理,第二个节点保存接收到的数据然后将数据写向 Pipeline 中的第三个 DataNode 节点;
-
DFSOutputStream 内部同样维护另外一个内部的写数据确认队列——ack queue。当 Pipeline 中的第三个 DataNode 节点将 packets 成功保存后,该节点回向第二个 DataNode 返回一个确认数据写成功的信息,第二个 DataNode 接收到该确认信息后在当前节点数据写成功后也会向 Pipeline 中第一个 DataNode 节点发送一个确认数据写成功的信息,然后第一个节点在收到该信息后如果该节点的数据也写成功后,会将 packets 从 ack queue 中将数据删除;
-
当数据写入完成时,就调用 DistributedFileSystem 的 close()函数关闭写入流
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2023年12月27日学习记录_加入噪声
- 【leetcode】招商银行学习计划经典笔试题(java版本含注释)
- AI嵌入式K210项目(12)-SPI LCD显示
- java面试题12
- 7-78 散步
- 全志T113开发板Qt远程调试
- npm 报错 request to https://registry.cnpmjs.org/vue failed, reason:
- web蓝桥杯真题--9、水果拼盘
- akshare,一个神奇的 Python 库!
- 申请软件代码签名数字证书