DS哈希查找--Trie树
Description
Trie树又称单词查找树,是一种树形结构,如下所示。
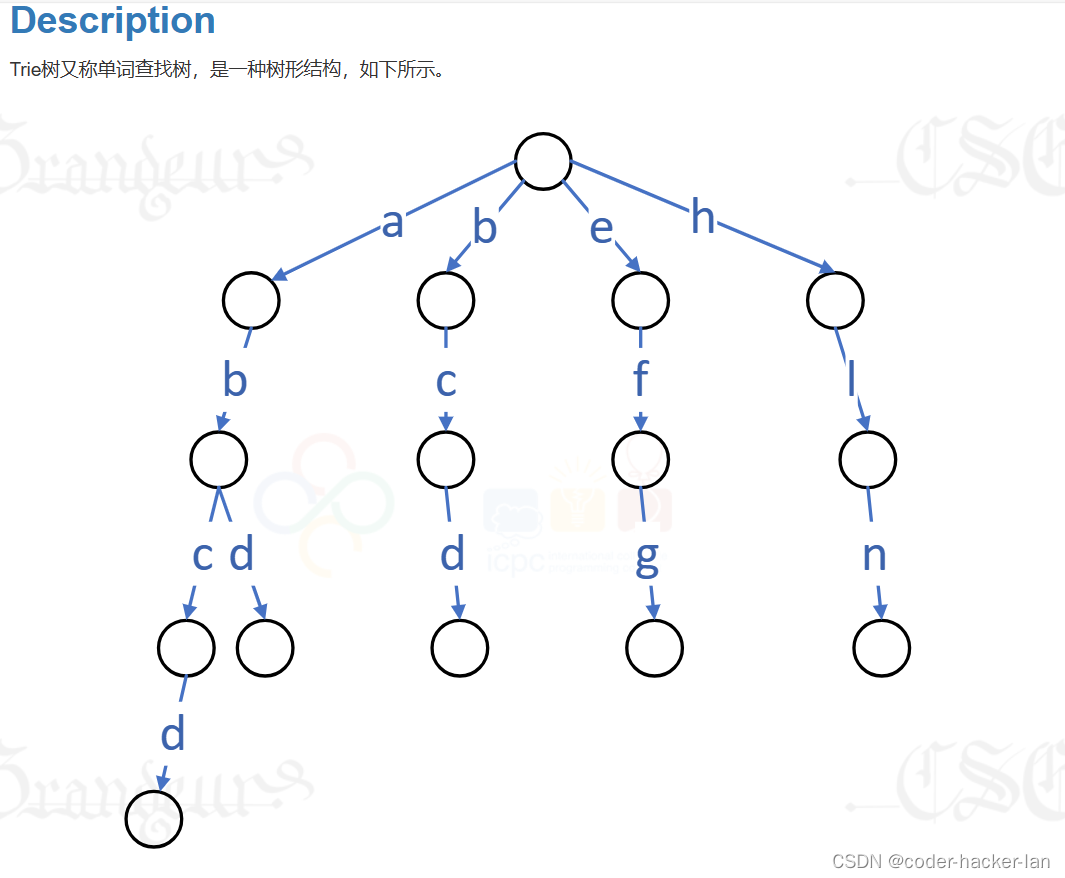

TRIE
它是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来节约存储空间,最大限度地减少无谓的字符串比较,查询效率比哈希表高。
输入的一组单词,创建Trie树。输入字符串,计算以该字符串为公共前缀的单词数。
(提示:树结点有26个指针,指向单词的下一字母结点。)
Input
测试数据有多组
每组测试数据格式为:
第一行:一行单词,单词全小写字母,且单词不会重复,单词的长度不超过10
第二行:测试公共前缀字符串数量t
后跟t行,每行一个字符串
Output
每组测试数据输出格式为:
第一行:创建的Trie树的层次遍历结果
第2~t+1行:对每行字符串,输出树中以该字符串为公共前缀的单词数。
Sample
#0
Input
Copy
abcd abd bcd efg hig 3 ab bc abcde
Output
Copy
abehbcficddggd 2 1 0
Trie树应用
? ? ? Trie树其实就是字典树了,我们查找单词只要沿着单词从左往右顺沿就可以找到了。每个节点都有26个子节点,因为我们一个单词后面能接的单词有26种可能性。如a后面可以接a到z
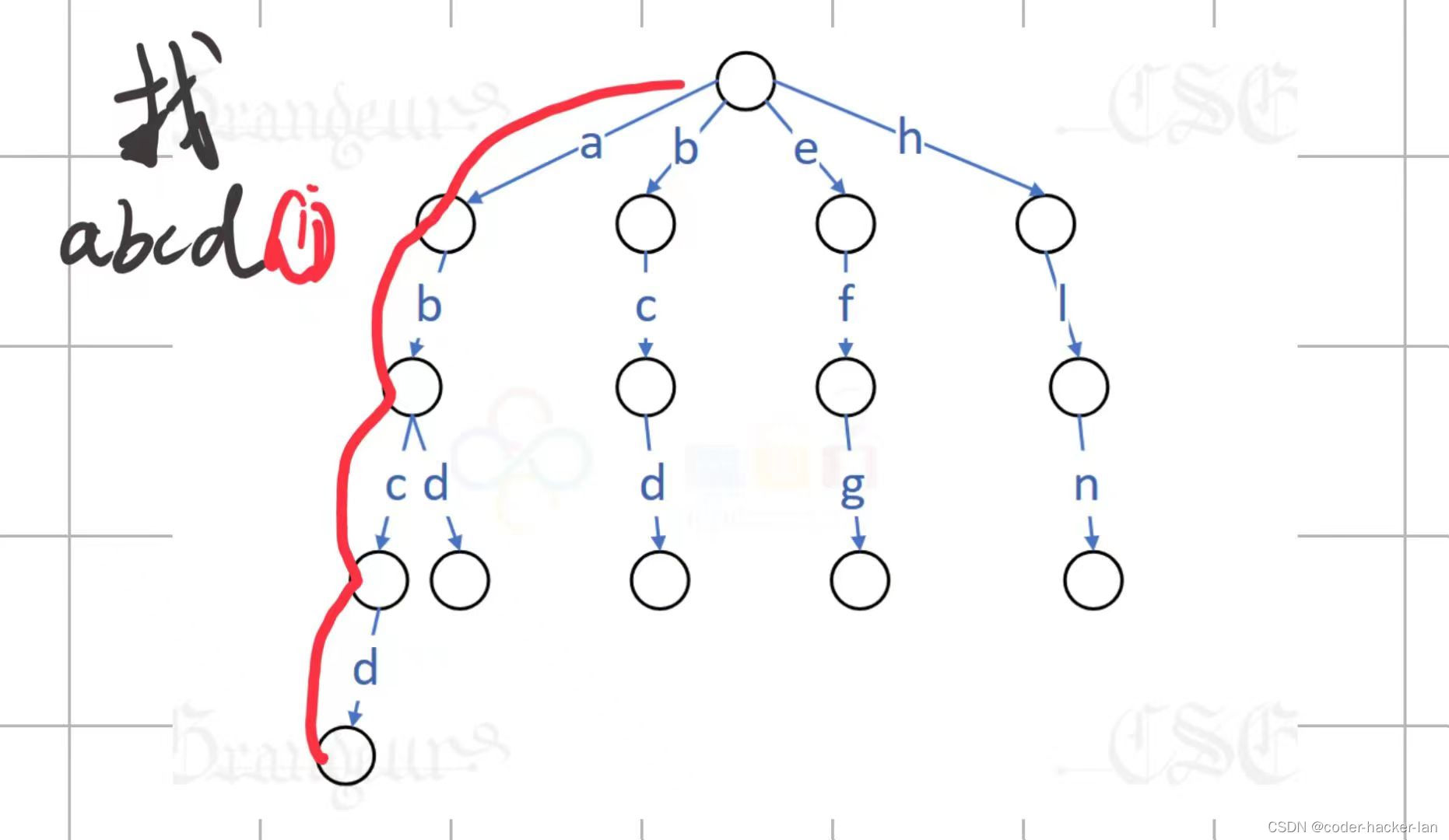
思路:
1.建树
我们只要让一个节点后面可以跟着最多26个子节点就可以了,就比如开始是空的
#为根节点
然后建立abc单词:#-a-b-c
然后建立bd单词: #-a-b-c,#-b-d
然后建立ad单词:#-a-b-c,#-a-d,#-b-d
? ? 不过我的方法就是节点就是一个单词
2.查找该前缀有多少个单词,其实就是找前缀是这个的有多少个叶子
如上图:前缀是a的单词有两个,abc,ad,我们找到前缀a之后,看有多少个叶子节点。有一个c和一个d
为什么是找叶子呢?为什么不是找a有多少个子节点?
可看图,如果我们a的子节点b还有个子节点,那是不是就是有三个单词了
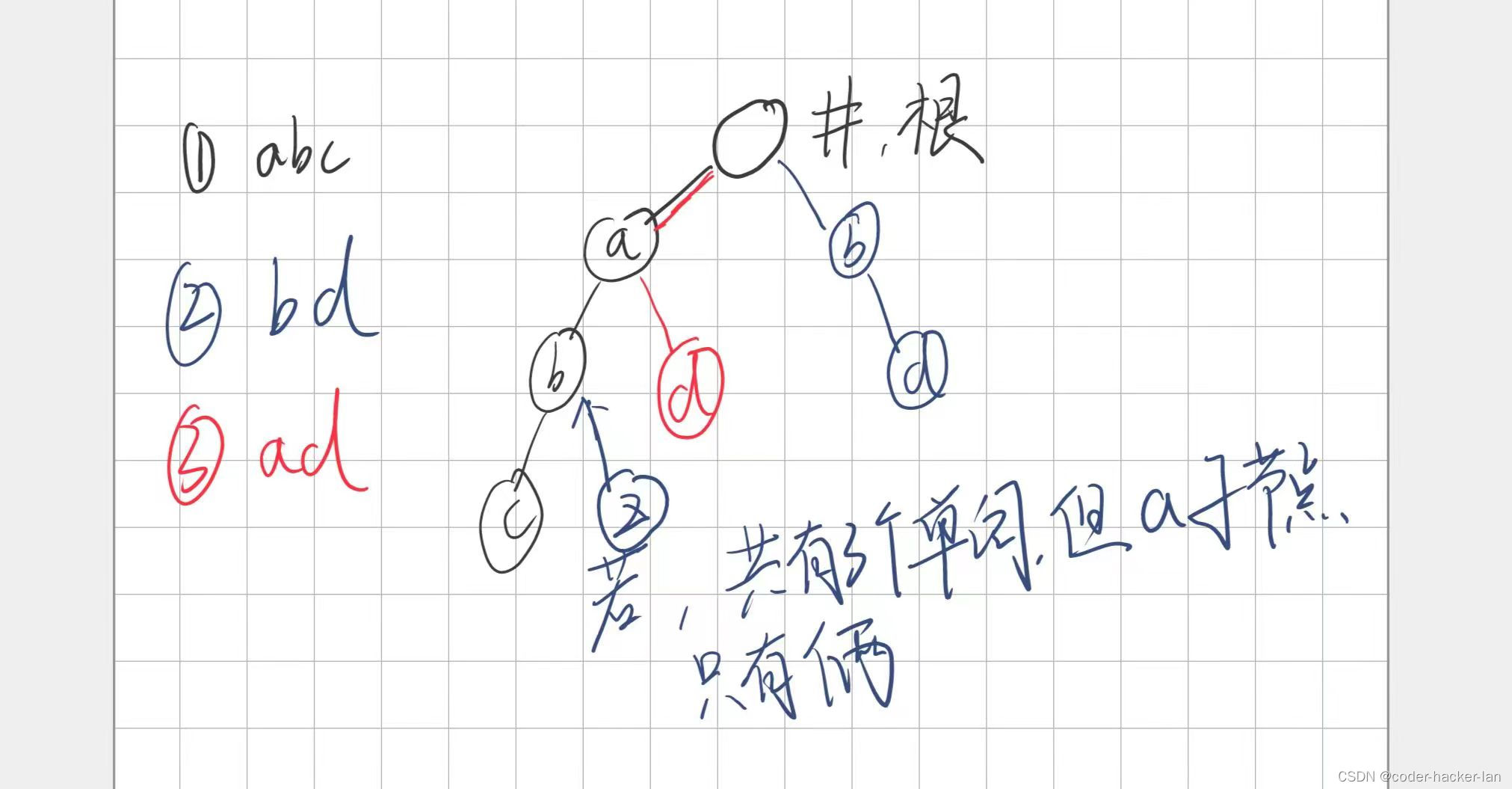
所以找的是叶子,即c,z,d
tips:我认为是最重要的,一定要看,一定要看,一定要看,重要的事情说三遍!!!
如果我们建树顺序是ac,然后再ab呢

建的树长这样,但是我们字典也是有顺序的啊

这样的才是正确的
那怎么实现呢?因为创建先后顺序不一样。
我们是不是把a的子节点都放在一个数组里,然后我们将该数组按字典序的顺序排个序就好了。
a的子节点是child数组,那我们sort排序一下
代码细节:
1.建树:我用的是插入方法

2.找前缀
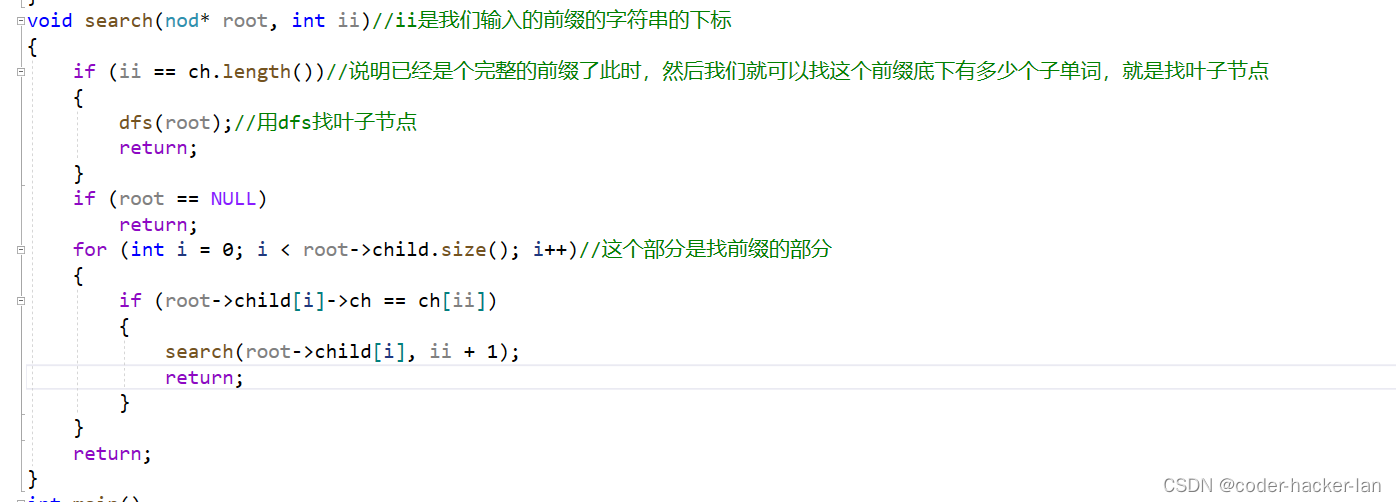
3.dfs找叶子

统计叶子个数就可以找到该有该前缀的单词的个数了
完整代码:
#include <iostream>
#include <vector>
#include <queue>
#include <string>
#include <algorithm>
using namespace std;
string ch;
struct nod//每个节点都会有26个子节点,原因是一个字母后面接的字母可能有26个可能
{
char ch;
vector<nod*>child;//我喜欢开动态数组,主要能获取size轻松
nod()
{
;
}
nod(char x)
{
ch = x;
}
};
bool cmp(const nod* a, const nod* b)//需要排序一下,比如输入ab,aa这样我们a的child里面是b,a
{ //但是trie数是有序的,所以我们需要让a的child里面是a,b
return a->ch < b->ch;
}
queue<nod*>p;
void insert_(nod*& root, int ii)//我的根节点的字符是#,ii是我们输入的单词串的下标,abc,ii=0,ch[ii]='a'
{
if (ii == ch.length())//如果ii等于字符串的长度了,说明我们都遍历完字符串了,就结束递归返回
return;
int len = root->child.size();//获取根的child数组长度
for (int i = 0; i < len; i++)//如果child里面有需要的字母,那我们就不用创造个新节点了,顺着这个节点往下插入
{
if (root->child[i]->ch == ch[ii])//存在相同的节点
{
insert_(root->child[i], ii + 1);//将下一个字符插入到这个节点的后面
sort(root->child.begin(), root->child.end(), cmp);//然后将这个字符的子节点排个序
return;
}
}
//没有找到相同的节点,所以需要创造一个新的
nod* point;
point = new nod(ch[ii]);
root->child.push_back(point);//插入到这个节点的child里
insert_(root->child[len], ii + 1);//因为是插在最后,开始下标为0->len-1,插入一个是不是到了len,长度变成len+1
sort(root->child.begin(), root->child.end(), cmp);//然后也将child排序一下
return;
}
void cengxu(nod* root)//层序遍历
{
p.push(root);//首先将根节点放入队列里面p是队列
while (!p.empty())
{
nod* q;
q = p.front();
p.pop(); //然后剩下部分是找这个节点的子节点
if (q->ch != '#')
{
cout << q->ch;//输出这个节点,这个节点不能是trie树的根节点
}
for (int i = 0; i < q->child.size(); i++)
{
p.push(q->child[i]);
}
}
}
int cnt = 0;//cnt计算有多少个单词的前缀是我们输入的
void dfs(nod* root)
{ //可以理解为递归找叶子,一个叶子就是一个单词
if (root->child.empty())
{
cnt++;//某个单词后面没有单词了,cnt+1
}
for (int i = 0; i < root->child.size(); i++)
{
dfs(root->child[i]);//往后面的单词进行递归找叶子节点
}
return;
}
void search(nod* root, int ii)//ii是我们输入的前缀的字符串的下标
{
if (ii == ch.length())//说明已经是个完整的前缀了此时,然后我们就可以找这个前缀底下有多少个子单词,就是找叶子节点
{
dfs(root);//用dfs找叶子节点
return;
}
if (root == NULL)
return;
for (int i = 0; i < root->child.size(); i++)//这个部分是找前缀的部分
{
if (root->child[i]->ch == ch[ii])
{
search(root->child[i], ii + 1);
return;
}
}
return;
}
int main()
{
nod* root;
root = new nod('#');
while (cin >> ch)//读取字符串
{
insert_(root, 0);
if (cin.get() == '\n')
break;
}
cengxu(root);//输出层序遍历
cout << endl;
int t;
cin >> t;//输入查找次数
while (t--)
{
cin >> ch;//输入前缀
cnt = 0;
search(root, 0);//查找trie树里面前缀相是ch的单词有多少个
cout << cnt << endl;//输出个数
}
return 0;
}
周末出去玩了,所以考完四级也没更新,这次补一下。不过其实我都写好了,但我就是尽量日更,然后定时发布了(别骂我)
这题卡了我很久,debug了很久,问题就在于我写的很重要很重要那里,因为写代码的时候可能把这个细节忘了
睡了睡了,晚安各位!!!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 正点原子imx6ull网络环境配置:开发板和电脑通过网线直连、电脑WiFi上网
- c++实验 引用与指针
- java校园二手市场交易系统的设计与实现-计算机毕业设计源码64357
- SVN忽略文件的两种方式
- 设计模式四(适配器模式)
- 在IDEA中使用快捷键让XML注释更加规范
- 苹果Mac图像修图软件Photomator和Pixelmator Pro 有什么区别?
- 例2.种树
- 《吐血整理》进阶系列教程-拿捏Fiddler抓包教程(16)-Fiddler如何充当第三者,再识AutoResponder标签-上篇
- 文件的使用(初阶)