openai最新探索:超级对齐是否可行?
前言
今天来介绍一篇openai最新的paper:弱到强的对齐。
openai专门成立了一个团队来做大模型的超级对齐即superhuman model,之前chatgpt取得成功依赖RLHF即依赖人类反馈,但是作者期望的superhuman model将会是一个能够处理各种复杂问题的强对齐模型,之前RLHF聚焦对齐某一方面能力比如安全,这个时候人类比较好判断case(是否安全)进而反馈,但是到superhuman model的时候,想要很好的反馈对人来说本身都是个挑战。
为此openai探索了一个方向:一个弱模型能否拿来监督生成一个更强大模型?
作者之所以探究这个方向是希望验证一个猜想:我们目标是想训练一个超人类大模型A,而现在我们所能用的监督信号是人类个体B,这是一个B监督A的学习过程也即弱监督强,那么这个是否work呢?为了验证这一点,所以作者做了一个类比来模拟验证,即用一个弱模型去监督一个强模型看看是否能监督地学出来些东西?
这就是这篇paper想要验证的理论。
《WEAK-TO-STRONG GENERALIZATION: ELICITING
STRONG CAPABILITIES WITH WEAK SUPERVISION》
论文链接:https://cdn.openai.com/papers/weak-to-strong-generalization.pdf
github: https://github.com/openai/weak-to-strong
其实仔细想想,openai目前已经走在世界最前列了,对于他们来说已经没有比自己更强的教师模型了,也就没有更强的模型可以直接拿来指导自己学习了,所以只能探索别的路(开始反过来想了,探索以弱监督强),而后来的追赶者其实还可以继续以openai为教师来蒸馏(比如蒸馏数据等等),这样也是最trick和高效的,先追上openai再说别的,正所谓openai在前摸着石头过河,其他摸着openai过河。
当然openai还可以继续秉承Scaling Law原则,继续无脑训更大的模型,效果也应该还会提高一些(无非就是再多投一些资源),但是显然这不是他们想要的,作为技术他们从理论上开始重新思考,也即训练一个superhuman model是否可行,以及路在何方?
废话不多说,我们看看openai都探索出哪些有意思的结论吧,学习一波~
温馨提示:全文较长,作者做的实验非常多,小结论也非常多,需要慢慢消化和理解作者在每节到底怎么想的以及探究出个啥。如果大家有兴趣,强烈建议结合着原paper来看,毕竟看完了后会有自己的理解和收获。
INTRODUCTION
之前使用RLHF技术的前提是人类能够很好的反馈给模型什么好的?什么是不好的?
但是我们期望的superhuman model是一个能够解决各种非常复杂的模型,对于这类问题,人类自己也不好(或者说成本很高)判断结果是否是好的,比如模型生成了一个一百万行极其复杂的代码,那人类此时就很难判断这个代码是不是好的,因为需要考虑的角度就很多比如该代码是否遵循了prompt?该代码是否安全?等等,既然人类都不好给出一个全面很好准确的反馈,那么这个使用这个监督信号就学不出啥了。
之前很多对齐技术都比较浅,作者都称之为today’s models,而作者想做的是future model (格局一下打开了,哈哈),是真真的超级对齐,作者希望这个研究方向可以快速迭代,为此本篇paper作为第一篇来实践一下(之前的研究都是些理论研究)是否work?
首先从直觉上来想一下为啥“弱监督强”有可能会work?假设一个很强的基座模型已经能够写代码了,那么大概率它也自己知道生成的代码是否很好地遵循了用户的Prompt。因此就不需要一个很强的“老师”来指导这个强基座模型学会什么“新知识”,而只需要一个比较弱的模型来能够引导出强基座模型已经学会的知识即可,换句话说当前的强基座模型就是一个具备各种知识,但就是不会说话或者听不懂人话、不会交流的模型,弱监督模型只需要干一件事:教好他怎么组织好语言即可。
METHODOLOGY
在具体实施中,作者先训练了一个弱监督模型,此时弱监督模型的效果为weak performance,然后基于这个弱监督模型便可给其他样本打标,此时就相当于有了弱监督信号,用这个弱监督信号去指导一个强模型进行训练,得到的效果叫做weak-to-strong performance,为了对比还可以使用真实的样本(高质量)去训练强模型,此时得到的效果叫做strong ceiling performance。
进而作者定义了一个量化评估performance gap recovered (PGR)

如果很好的实现了弱到强的泛化,那么PGR=1,相反为0。
MAIN RESULTS
- 简单的在弱标签上微调
作者首先仅仅进行最简单的微调即什么策略不用看看效果,具体的使用传统的NLP任务、国际象棋、reward model进行测试
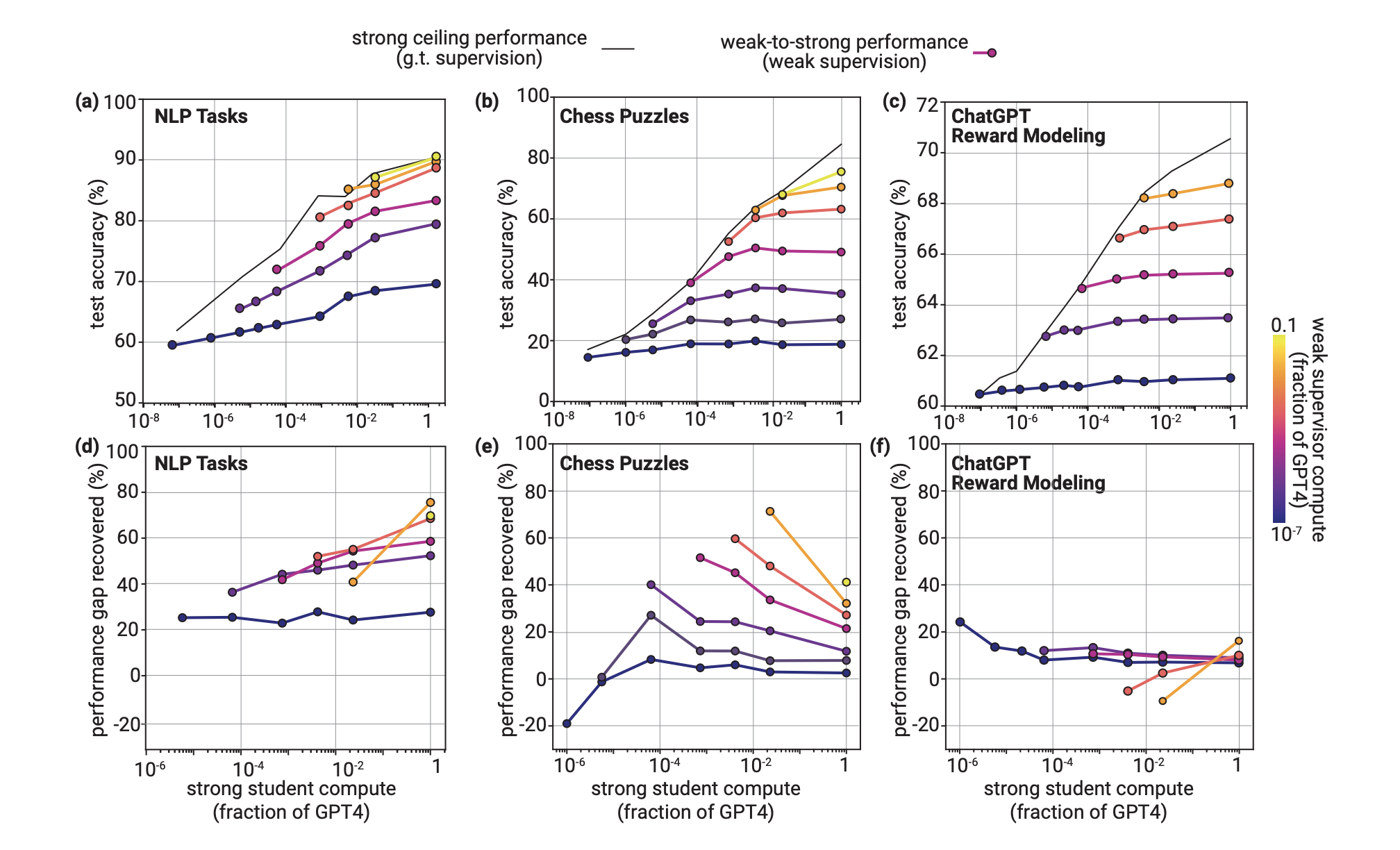
可以看到在传统的NLP任务中,弱到强的训练模型通常比弱模型本身泛化到更高的性能。即使是用非常弱的模型和非常强的模型(两个极端),也能恢复了超过20%的性能差距。其中PGR随着弱监督模型和强学生模型的大小增加而增加;对于最大的学生模型PGR通常高于50%。
同时在国际象棋测试中可以观察到当使用非常弱的监督模型时,PGR是为0的,只有到弱的监督模型不断增大时PGR才逐渐开始出现收益,同时另外一个反常现象就是随着学生模型的增大PGR反而开始下降。
在reward model测试中,弱到强的泛化都很差,只能恢复大概10%,即使是当弱模型和强模型之间模型大小相对较小的时候,PGR也未超过20%。
总的来说作者通过实验现象观察(强学生模型始终优于他们的弱监督模型)认为从弱到强进行泛化具有可行性,但同时作者也认为仅仅使用弱的人类级别的监督将不足以实现superhuman model;需要全新的技术来解决超级对齐。
- 一些增强弱到强效果的策略
上面只是简单的微调,这一节作者使用了一些策略来继续增强效果,具体的方法如下
(1)Bootstrapping
该方法的核心就是:慢慢来,既然步子太大,一下实现不了,那我们就一步步来,可以先对齐实现一个次一点的superhuman model,然后使用该模型再去对齐更强的superhuman model。具体的可以分为M1 → M2 → . . . → Mn,一步步对齐。
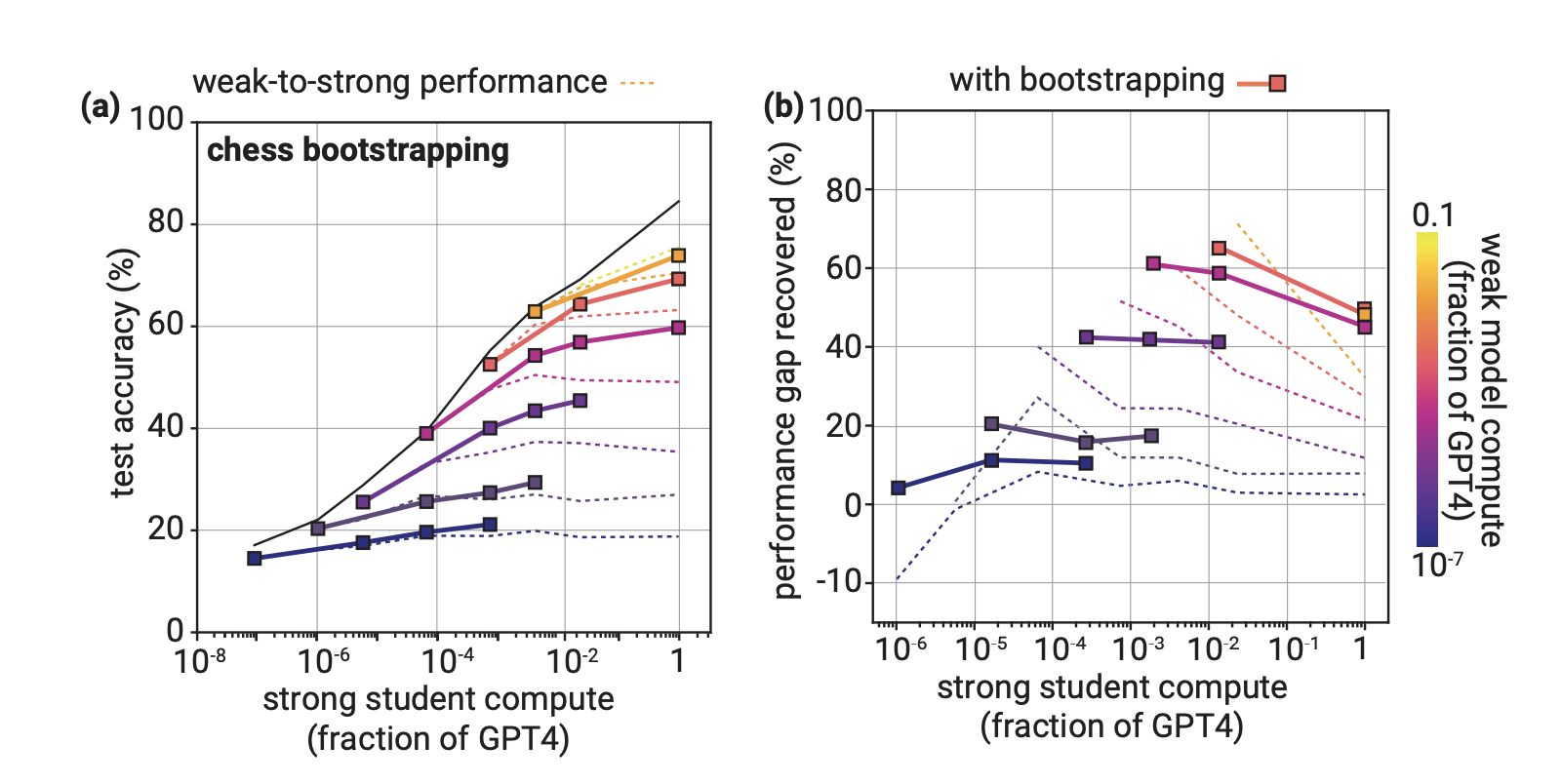
可以看到采用小步走的时候,在国际象棋测试中确实会变好一点,不过作者也同步了在传统的NLP任务、reward model测试上这种方法没有提升,所以结论就是小步走方法是一条值得探索的可行途径,在某些情况下可能帮助改善从弱到强的泛化能力,但仅仅这种方法是不行的,不具有普适性。
(2)AUXILIARY CONFIDENCE LOSS
弱标签总是有错监督信号的,我们不希望强学生模型去模仿这种错误,而是仅仅希望模型学习监督者的意图。
所以一个可以直观想到的办法就是,学生模型要自信一点,尤其对于知识要有质疑的勇气,于是作者通过在标准交叉熵目标函数中添加一个辅助的置信度损失项来实现这,具体而言,我们添加了一个额外的损失项,增强了强模型对自己预测的信心即使这些预测与弱标签不一致。具体公式如下,两个f分别代表强学生模型和弱标签预测


可以看到对于较小的强学生,它的表现略逊于朴素的基准线,但当弱模型和强模型大小gap较大时,这种方法显著提高了泛化能力(置信度损失将中位数PGR从约25%提高到近80%)
UNDERSTANDING WEAK-TO-STRONG GENERALIZATION
本节中作者试图进一步去探究弱到强背后的原因,以便更加理解本质。具体的作者从下面两个方面进行了探究
- UNDERSTANDING IMITATION

图(a)是ChatGPT RM任务训练过程中的真实测试准确率曲线,图(b)和?是比较了最佳5个和最终的真实测试准确率(对所有弱-强模型对取中位数)。最后发现在弱-强模型差距较大的情况下会出现过拟合现象。对于弱-强模型差距较小的情况,最后的泛化性能通常在训练过程中单调增加。而对于模型较大差距的时候,性能通常在最初增加,但在不到一轮训练结束之前就开始下降。
所以基于这种现象,使用early stopping可能是有效的,比如作者使用真实标签进行early stopping可以使PGR提高15个百分点,并且相对于使用弱标签的“非作弊”早停训练,可以提高10个百分点的PGR(当然了,现实中我们是不可能有真实标签数据的)。总的来说更好的early stopping或正则化策略可以通过减少对弱标签及其错误的过拟合来大幅改善从弱到强的泛化能力(比如前面介绍的辅助置信度损失就显著减少了对弱标签的过拟合)
另外一个可以观察的指标就是看学生模型和监督者之间的一致性:即在输入一个prompt下,强学生模型和弱监督者作出相同预测的比例。如果一致性达到100%PGR将为0。
作者通过观察发现在使用了简单的微调后,学生模型和监督者之间的一致性始终很高,这表明学生模型在模仿弱监督者的一些错误。这些现象在所有任务(自然语言处理任务、国际象棋和reward model测试)和所有模型大小上都存在。在使用了前面置信度损失方法后可以显著降低学生模型和弱监督者之间的一致性。
同时作者研究了学生模型和弱监督者之间一致性与模型大小的关系,发现反比例缩放规律即当学生模型与弱监督者模型大小gap越大时,错误一致性越小,所以一个自然的假设是:从弱到强的泛化性在很大程度上取决于弱监督者的这些错误对于学生模型来说模仿有多容易。对于学生模型来说更难模仿的错误会导致更强的从弱到强的泛化性能。
- SALIENCY IN THE STRONG MODEL REPRESENTATIONS
另外一个可以去尝试理解的角度就是:当回答一个prompt所需的知识,强学生模型本身已经具备了,那么泛化就相对容易些。(这也是我们一再强调的,预训练模型在学习知识,对齐阶段在学听说人话)。

作者分别使用zero-shot,5-shot(真实标签),fintune(用真实标签),fewshot fintune(弱标签)和 结合置信度损失fintune在NLP任务上进行对比。
从图(a)可以看到当学生模型大到一定程度,仅仅使用5-shot(真实标签)便可以达到fintune(用真实标签)的效果,这也就说明大到一定程度的基座学生模型自身就已经能够完成很多任务了;从图(b)可以看到当使用fewshot(弱标签)形式fintune后,效果反而不如5-shot(真实标签),这就表明weak-to-strong的学习是不太容易的;从图?可以看到相比于zeroshot fintune(弱标签),fewshot fintune(弱标签)还是有帮助的,但是不如加入置信度损失这一方法。
总的来说大到一定程度的基座学生模型自身借助fewshot就已经能够很好完成很多任务了,当然真实情况可能也不是这样,因为这个实验是在NLP上实验的,很大程度上预训练已经见过这些数据了,如果真是这样,那么现在观察到的结果都不怎么置信,甚至fewshot的结论比fintune结论更不置信。
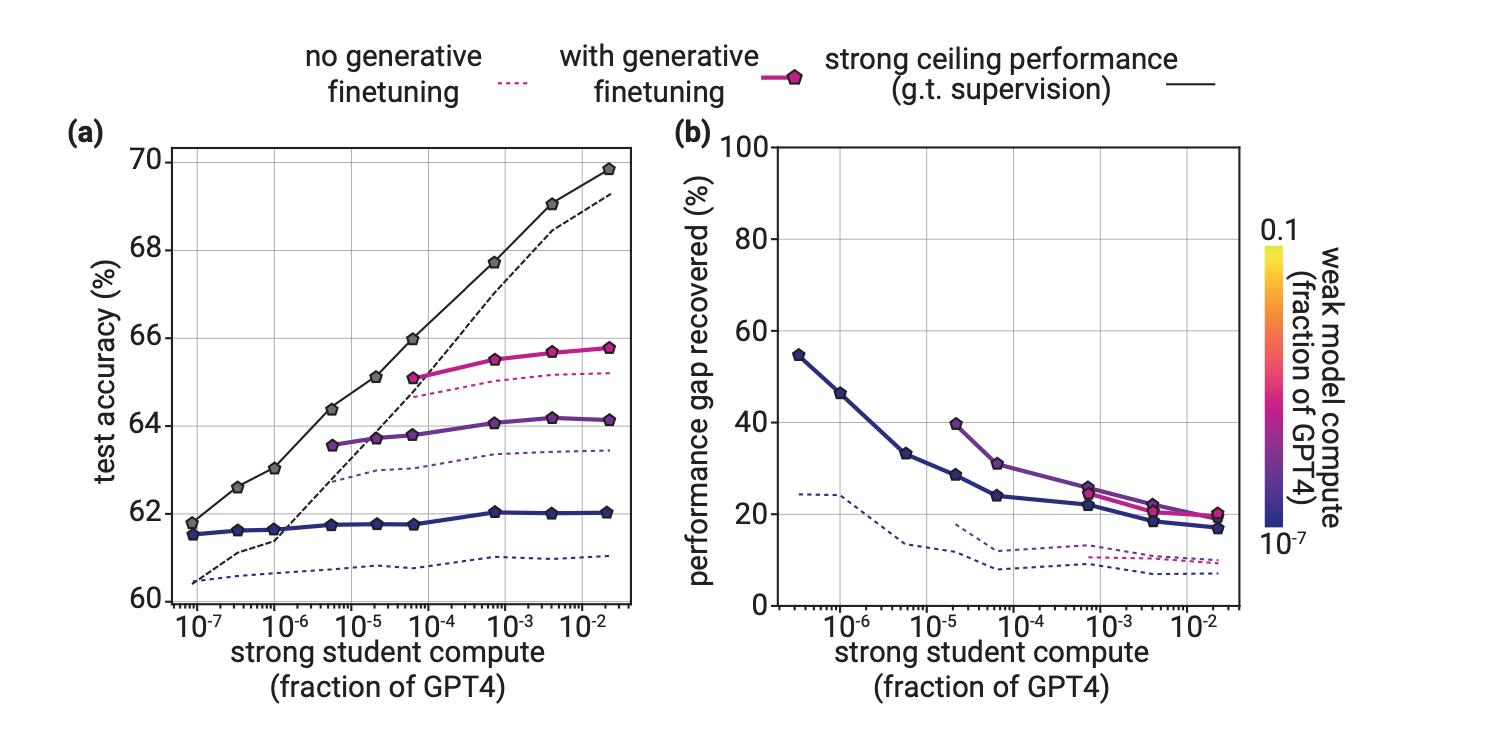
同时作者探索了另外一个角度就是领域学习,比如上图是作者在RM任务上的实验,with generative finetuning是指作者先让学生模型以非监督的方式学一下RM的数据集(注意是纯纯的非监督学习,不存在数据泄露问题),可以看到该方式可以全面提高性能。所以拿领域数据进行一下领域学习是不错的trick。
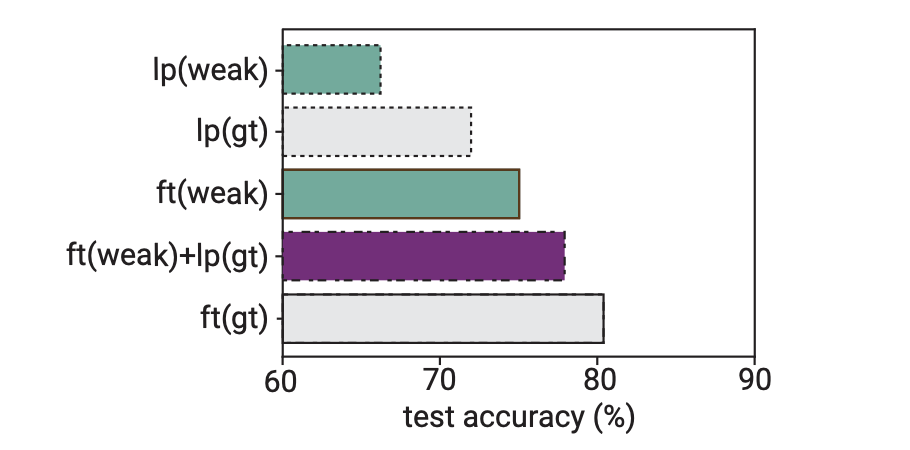
另外一个可以探索模型是否已经学习了相关知识的方法就是用线性探测器,其实大白话理解就是冻住模型前面大部分层,只fintune最后一个线性层来看效果(这里的潜在逻辑是如果只通过一个简单的线性就能cover任务,那么学生模型本身大概率是已经get到了相关知识),如果效果好说明学生模型对该任务已经有很好的显著性了。
为此作者做了一些实验,上图中的Ip代表的就是仅训练线性层,可以看到Ip(gt)相比于ft(gt)还是逊色不少的,说明对于大部分任务仅仅依靠最后一层是不能完全激发出来的。同时通过ft(weak) ft(weak)+lp(gt)和lp(weak)、ft(gt)相比可以看到先用弱学生模型监督一下子,然后在用真实标签Ip一下效果就会很不错。所以我们可以首先对任务使用弱标签进行简单微调。然后使用基于简单线性探测的弱到强方法来进一步增强。总的来说吧,也是一个方向。
DISCUSSION
本节也是论文最后的一部分了,作者进行了一波总结:在这篇论文中,作者首先是提出了一个简单的类比方法来研究superhuman model的核心挑战,也即用弱监督强来模拟验证训练出一个superhuman model是否有可能work, 最后验证是可行的。
- REMAINING DISANALOGIES
当然作者也承认,这个类比模仿和想要真真最终探究的问题之间还是存在一些diff,具体的有下面两个方面:
(1)模仿显著性
superhuman model是爱模仿人类的,尤其是当监督信号或者数据大部分来自人类时,那么最终训练出的Future models很可能就是个自然人水平,很难激发出其已经具备的超人类能力。
在这一点上我们通过弱模型监督强模型来模拟,虽然也可以看到部分情况下强模型在学弱模型的一些错误信号(从模拟角度来看是好事,因为算是模拟再现了相同的情况),但是也同时看到当强模型大到一定程度的时候这种模仿就比较难再现了,因此这个问题在最终实现superhuman model的时候可能是个不可避免的问题,但是我们当前的类比模仿复现这个问题的时候可能有点过于乐观了(泛化性太好了),没有把真真的困难展现出来。
(2)预训练数据泄漏
本篇paper实验的很多任务可能都在pretrain阶段被见过了(虽然不是故意的,但是很有可能这部分数据已经被吃过了),那么这些结论就不置信了或者说当前的结论过于乐观了,因为真真的superhuman model要解决的问题是无法通过pretrain吃数据直接得到的,而是以一种更加“隐讳”的状态学到的比如强化学习等等。
当然作者也在附录做了一个实验来验证弱到强的泛化是否可以真真激发出在预训练期间从未明确观察到的潜在能力。具体的作者使用AlexNet来监督DINO(DINO是一种在计算机视觉中学习表征的自监督方法),结果发现最终强学生的泛化能力显著超越了AlexNet也即弱监督模型的性能。
- FUTURE WORK
作者也再次声明了当前还没有找到如何做超级对齐的方法,但是已经开了头,把一些可能需要做的前置工作列了出来,具体的包括下面三个方面
(1)类比设置
目前的类比实验和最终的想要的场景还是有一些diff,需要进一步fix这些diff。
(2)可扩展方法
说白了就是未来找的方法是要具有普适性的,这一方法可以多借鉴机器学习领域的半监督学习或鲁棒微调。
(3)科学理解
这里就是说怎么更好的评估模型?这也是非常重要的,仅仅依靠有限的benchmark来反馈是不够的,需要探索出一个合理且真实有效的方法来评估模型是否真的进步了,同时要能理解这背后的逻辑即可解释性,这一点也是个重要的方向。
总结
(1)可以看到弱模型的使命发现了变化,作者把它定位成了一个会教“听懂人话、组织语言然后表达出来”的角色,它本身并不教任何世界知识,它自己也不懂世界知识(毕竟弱嘛)
(2)这其实在chatgpt出来的时候,大家就有这方面的共识,还记得训练大模型的三部曲吗:预训练、sft、rlhf。其中预训练阶段就是在注入世界知识,可以理解为死背书,什么知识都记住了,记住是记住了,但最后总得通过交互和现实世界连接起来才能体现自己价值,那什么交互才是最自然的呢?在人类社会当然是通过对话了,所以sft包括rlhf都是在教它怎么看懂人话、然后怎么把自己已经学到的海量知识组织成人类易于接受或者看懂的风格说出来,这个本领就是“洞察人类意图,然后会表达”。一个不恰当的比喻就是预训练学出来的是一个不会交流但是饱读诗书的高智商理科生,而sft&rlhf却赋予了他更高情商的交流能力。一个能融合贯通了文理的模型不就是我们最终想要的superhuman model吗?
(3)但是大家也不要忽略了一个关键点,那就是得现有一个能“死背住世界知识的”pretrain model, 这是基石,是根本。没有一个好的pretrain model,后期再怎么激发都激发不出来,再怎么牛的叫它能说会道的技巧都没用,它肚子里就没有墨水,就不足以拿出铁铮铮的知识来回答各种问题,天然就缺陷。而想要一个好的pretrain model是非常难的,比如和GPT3相比其他的基座都有些许差距,也就是为啥我们在一些开源基座做sft时不时就需要百万量级的sft数据,就是因为少了的话教不会啊,面对一个不是那么强的学生,sft的使命不仅仅是要教会他说话,同时还要兼顾教会他一些“知识”。 其实从吃数据的角度来看pretrain和sft,知识在哪学都是学,但是既然划分了pretrain和sft,而且也确实很有道理,pretrain就是要尽可能的把知识都学完学全,后期sft对齐就真的是只安心做“对齐”,而不是还要学知识,即使要学,也还是要把这个过程继续下放给pretrain,在他那一环节继续迭代弥补住这个缺陷。
关注
欢迎关注,下期再见啦~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于MATLAB的GUI界面设计流程
- C语言K&R圣经笔记 5.6指针数组;指针的指针
- 零基础学Java第一天
- 开启Hyper-V
- SpringBoot不求甚解,Java小白入门(二)
- 基于opencv的直线检测(python&C++)
- STM32学习笔记十五:WS2812制作像素游戏屏-飞行射击游戏(5)探索动画之帧动画
- C++ Qt开发:Charts绘制各类图表详解
- 经典的4道笔试题
- 某金属加工公司的核心人才激励体系搭建项目纪实