基于GBM和随机森林模型探索影响学生压力的主要因素
1.项目背景
数据集包含了心理、生理、社会、环境和学术等不同方面信息,为深入探讨学生面临的各种压力提供参考数据。从睡眠质量到学习负担,再到环境和人际关系的影响,数据集涵盖了约20个最显著的特征。
本项目主要采取可视化分析探索数据,并且根据学生不同的压力水平进行差异分析,发现所有因素对于学生的压力水平都有显著的相关性,再通过KW检验,可以认为这些因素对学生的压力水平具有显著影响,或者说不同压力水平下,这些因素之间都有差异,最后建立了梯度提升机和随机森林模型,进一步探究这些因素的重要度。2.数据说明
字段名 说明 anxiety_level 焦虑水平;[0, 21],数字越大表示程度越高 self_esteem 自尊水平;[0, 30],数字越大表示程度越高 mental_health_history 心理健康病史;1:有,0:无 depression 抑郁;[0, 27],数字越大表示程度越高 headache 头痛问题;[0, 5],数字越大表示发生频率越高 blood_pressure 血压问题;[1, 3],数字越大表示情况越严重 sleep_quality 睡眠质量;[0, 5],数字越大表示质量越高 breathing_problem 呼吸问题;[0, 5],数字越大表示情况越严重 noise_level 环境噪音水平; [0, 5],数字越大表示程度越高 living_conditions 居住条件;[0, 5],数字越大表示条件越好 safety 安全; [0, 5],数字越大表示程度越高 basic_needs 基本需求满足情况;[0, 5],数字越大表示程度越高 academic_performance 学业表现;[0, 5],数字越大表示水平越高 study_load 学业负担;[0, 5],数字越大表示水平越高 teacher_student_relationship 师生关系;[0, 5],数字越大表示水平越高 future_career_concerns 未来职业担忧;[0, 5],数字越大表示水平越高 social_support 社会支持;[0, 3],数字越大表示程度越强 peer_pressure 同辈压力;[0, 5],数字越大表示程度越高 extracurricular_activities 课外活动;[0, 5],数字越大表示频率越高 bullying 霸凌问题;[0, 5],数字越大表示程度越高 stress_level 压力水平;[0, 2],数字越大表示程度越高 3.Python库导入及数据读取
In?[1]:
import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt import scipy.stats as stats from sklearn.model_selection import train_test_split from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report,confusion_matrix from sklearn.ensemble import RandomForestClassifierIn?[2]:
# 读取数据 data = pd.read_csv("/home/mw/input/stress4628/StressLevelDataset.csv")4.数据预览及数据处理
4.1数据预览
In?[3]:
# 查看数据维度 data.shapeOut[3]:
(1100, 21)In?[4]:
# 查看数据信息 data.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 1100 entries, 0 to 1099 Data columns (total 21 columns): anxiety_level 1100 non-null int64 self_esteem 1100 non-null int64 mental_health_history 1100 non-null int64 depression 1100 non-null int64 headache 1100 non-null int64 blood_pressure 1100 non-null int64 sleep_quality 1100 non-null int64 breathing_problem 1100 non-null int64 noise_level 1100 non-null int64 living_conditions 1100 non-null int64 safety 1100 non-null int64 basic_needs 1100 non-null int64 academic_performance 1100 non-null int64 study_load 1100 non-null int64 teacher_student_relationship 1100 non-null int64 future_career_concerns 1100 non-null int64 social_support 1100 non-null int64 peer_pressure 1100 non-null int64 extracurricular_activities 1100 non-null int64 bullying 1100 non-null int64 stress_level 1100 non-null int64 dtypes: int64(21) memory usage: 180.5 KBIn?[5]:
# 查看各列缺失值 data.isna().sum()Out[5]:
anxiety_level 0 self_esteem 0 mental_health_history 0 depression 0 headache 0 blood_pressure 0 sleep_quality 0 breathing_problem 0 noise_level 0 living_conditions 0 safety 0 basic_needs 0 academic_performance 0 study_load 0 teacher_student_relationship 0 future_career_concerns 0 social_support 0 peer_pressure 0 extracurricular_activities 0 bullying 0 stress_level 0 dtype: int64In?[6]:
# 查看重复值 data.duplicated().sum()Out[6]:
0In?[7]:
# 查看数据的唯一取值 for i in data.columns.tolist(): print(f'{i}:') print(data[i].unique()) print('-'*50)anxiety_level: [14 15 12 16 20 4 17 13 6 5 9 2 11 7 21 3 18 0 8 1 19 10] -------------------------------------------------- self_esteem: [20 8 18 12 28 13 26 3 22 15 23 21 25 1 27 5 6 9 29 30 4 19 16 2 0 14 7 17 24 11 10] -------------------------------------------------- mental_health_history: [0 1] -------------------------------------------------- depression: [11 15 14 7 21 6 22 12 27 25 8 24 3 1 0 5 26 20 10 9 2 16 4 13 18 23 17 19] -------------------------------------------------- headache: [2 5 4 3 1 0] -------------------------------------------------- blood_pressure: [1 3 2] -------------------------------------------------- sleep_quality: [2 1 5 4 3 0] -------------------------------------------------- breathing_problem: [4 2 3 1 5 0] -------------------------------------------------- noise_level: [2 3 4 1 0 5] -------------------------------------------------- living_conditions: [3 1 2 4 5 0] -------------------------------------------------- safety: [3 2 4 1 5 0] -------------------------------------------------- basic_needs: [2 3 1 4 5 0] -------------------------------------------------- academic_performance: [3 1 2 4 5 0] -------------------------------------------------- study_load: [2 4 3 5 1 0] -------------------------------------------------- teacher_student_relationship: [3 1 2 4 5 0] -------------------------------------------------- future_career_concerns: [3 5 2 4 1 0] -------------------------------------------------- social_support: [2 1 3 0] -------------------------------------------------- peer_pressure: [3 4 5 2 1 0] -------------------------------------------------- extracurricular_activities: [3 5 2 4 0 1] -------------------------------------------------- bullying: [2 5 1 4 3 0] -------------------------------------------------- stress_level: [1 2 0] --------------------------------------------------In?[8]:
data.head()Out[8]:
anxiety_level self_esteem mental_health_history depression headache blood_pressure sleep_quality breathing_problem noise_level living_conditions ... basic_needs academic_performance study_load teacher_student_relationship future_career_concerns social_support peer_pressure extracurricular_activities bullying stress_level 0 14 20 0 11 2 1 2 4 2 3 ... 2 3 2 3 3 2 3 3 2 1 1 15 8 1 15 5 3 1 4 3 1 ... 2 1 4 1 5 1 4 5 5 2 2 12 18 1 14 2 1 2 2 2 2 ... 2 2 3 3 2 2 3 2 2 1 3 16 12 1 15 4 3 1 3 4 2 ... 2 2 4 1 4 1 4 4 5 2 4 16 28 0 7 2 3 5 1 3 2 ... 3 4 3 1 2 1 5 0 5 1 5 rows × 21 columns
4.2数据处理
数据比较干净,不存在缺失值,并且每个特征的取值也在范围内,这里就不进行数据处理了。
5.可视化分析
5.1心理因素
In?[9]:
plt.figure(figsize=(15,15)) # 焦虑水平 plt.subplot(2,2,1) sns.distplot(data['anxiety_level'], kde=True) plt.title('焦虑水平分布') plt.xlabel('焦虑水平') plt.ylabel('频数') # 自尊水平 plt.subplot(2,2,2) sns.boxplot(y=data['self_esteem']) plt.title('自尊水平分布') plt.ylabel('自尊水平') # 心理健康病史 plt.subplot(2,2,3) sns.countplot(x=data['mental_health_history']) plt.title('心理健康病史分布') plt.xlabel('心理健康病史') plt.ylabel('频数') # 抑郁情况 plt.subplot(2,2,4) sns.violinplot(y=data['depression']) plt.title('抑郁情况分布') plt.ylabel('抑郁程度') plt.tight_layout() plt.show()
1.焦虑水平:焦虑水平似乎呈现正态分布,大多数数据集中在10到15之间。
2.自尊水平:中位数大约在19左右,四分位范围从约11到约28。
3.心理健康病史:没有心理健康病史的人数稍多于有病史的人数。
4.抑郁:中位数大约在13左右,大部分人数主要分布在13左右,这时候图形最宽。5.2生理因素
In?[10]:
plt.figure(figsize=(15,15)) # 头痛问题 plt.subplot(2,2,1) sns.countplot(x=data['headache']) plt.title('头痛问题等级分布') plt.xlabel('头痛问题等级') plt.ylabel('频数') # 血压问题 plt.subplot(2,2,2) sns.countplot(x=data['blood_pressure']) plt.title('血压问题等级分布') plt.xlabel('血压问题等级') plt.ylabel('频数') # 睡眠质量 plt.subplot(2,2,3) sns.countplot(x=data['sleep_quality']) plt.title('睡眠质量等级分布') plt.xlabel('睡眠质量等级') plt.ylabel('频数') # 呼吸问题 plt.subplot(2,2,4) sns.countplot(x=data['breathing_problem']) plt.title('呼吸问题等级分布') plt.xlabel('呼吸问题等级') plt.ylabel('频数') plt.tight_layout() plt.show()
1.头痛问题:1级头痛的频率是最常见的。其他级别的频率由高到低依次为3级、2级、4级和5级。
2.血压问题:接近500人有3级血压问题,1级和2级血压问题人数数量比较接近。
3.睡眠质量:最多的是1级睡眠质量,表明大多数人认为自己的睡眠质量并不好。
4.呼吸问题:主要集中在2级和4级。5.3环境因素
In?[11]:
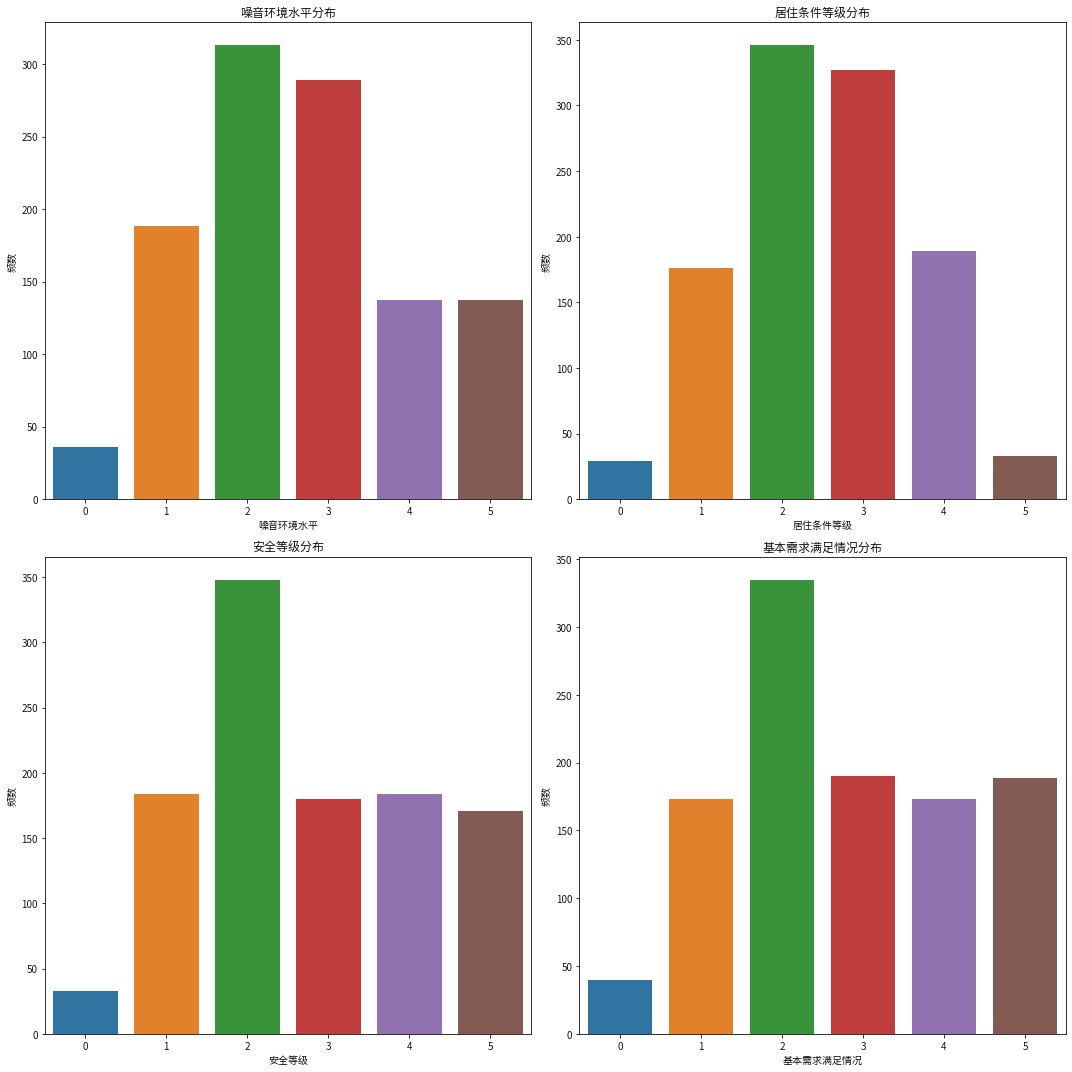
plt.figure(figsize=(15,15)) # 噪音环境水平 plt.subplot(2,2,1) sns.countplot(x=data['noise_level']) plt.title('噪音环境水平分布') plt.xlabel('噪音环境水平') plt.ylabel('频数') # 居住条件 plt.subplot(2,2,2) sns.countplot(x=data['living_conditions']) plt.title('居住条件等级分布') plt.xlabel('居住条件等级') plt.ylabel('频数') # 安全等级 plt.subplot(2,2,3) sns.countplot(x=data['safety']) plt.title('安全等级分布') plt.xlabel('安全等级') plt.ylabel('频数') # 基本需求满足情况 plt.subplot(2,2,4) sns.countplot(x=data['basic_needs']) plt.title('基本需求满足情况分布') plt.xlabel('基本需求满足情况') plt.ylabel('频数') plt.tight_layout() plt.show()
1.噪音环境:主要集中在2级和3级,表明大多数人表示居住环境有噪音,但是处于中等级别。
2.居住条件:主要集中在2级和3级,表明大多数人认为自己的居住条件处于中等级别。
3.安全等级:主要集中在2级,然后较为均匀的分布在1级,3级,4级,5级,极少部分认为居住安全等级为0级。
4.基本需求满足情况:和安全等级一样,主要集中在2级,较为均匀的分布在1级、3级、4级、5级。5.4学业因素
In?[12]:
plt.figure(figsize=(15,15)) # 学业表现 plt.subplot(2,2,1) sns.countplot(x=data['academic_performance']) plt.title('学业表现水平分布') plt.xlabel('学业表现水平') plt.ylabel('频数') # 学业负担 plt.subplot(2,2,2) sns.countplot(x=data['study_load']) plt.title('学业负担水平分布') plt.xlabel('学业负担水平') plt.ylabel('频数') # 师生关系 plt.subplot(2,2,3) sns.countplot(x=data['teacher_student_relationship']) plt.title('师生关系水平分布') plt.xlabel('师生关系水平') plt.ylabel('频数') # 未来职业担忧 plt.subplot(2,2,4) sns.countplot(x=data['future_career_concerns']) plt.title('未来职业担忧情况分布') plt.xlabel('未来职业担忧情况') plt.ylabel('频数') plt.tight_layout() plt.show()
1.学业表现水平:主要集中在2级,较为均匀的分布在1级,3级,4级,5级,表明大多数人认为自己的学业处于中等水平。
2.学业负担:大多数处于1级-3级,表明大多人认为学业负担中等。
3.师生关系主要也是集中在2级,表明大多数人的师生关系比较一般。
4.对未来职业担忧的情况比较少,主要位于1级,但是只有极少部分人没有担忧(0级)。5.5社会因素
In?[13]:
plt.figure(figsize=(15,15)) # 社会支持 plt.subplot(2,2,1) social_support_counts = data['social_support'].value_counts() plt.pie(social_support_counts, labels=social_support_counts.index, autopct='%1.1f%%', startangle=140) plt.title('社会支持分布') # 同辈压力 plt.subplot(2,2,2) sns.countplot(x=data['peer_pressure']) plt.title('同辈压力分布') plt.xlabel('同辈压力') plt.ylabel('频数') # 课外活动 plt.subplot(2,2,3) sns.countplot(x=data['extracurricular_activities']) plt.title('课外活动分布') plt.xlabel('课外活动') plt.ylabel('频数') # 霸凌问题 plt.subplot(2,2,4) sns.countplot(x=data['bullying']) plt.title('霸凌问题分布') plt.xlabel('霸凌问题') plt.ylabel('频数') plt.tight_layout() plt.show()
1.社会支持可以看出来,主要集中在1级和3级。
2.同辈压力主要集中在2级,表明大多数人认为同辈给自己的压力比较正常。
3.课外活动主要位于2级,表明大多数学生的课外活动的频率比较正常。
4.大多数学生都遇到霸凌问题,霸凌等级为1级的占比最大。5.6压力等级分布
In?[14]:
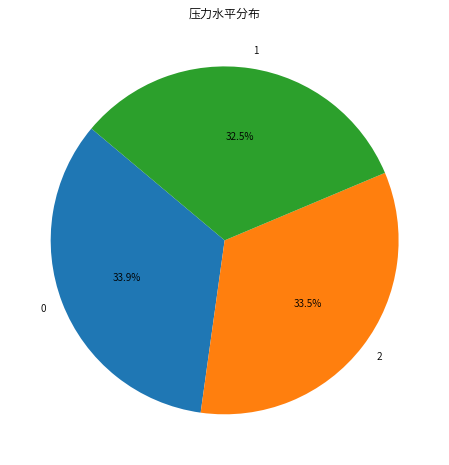
stress_level_counts = data['stress_level'].value_counts() plt.figure(figsize=(8, 8)) plt.pie(stress_level_counts, labels=stress_level_counts.index, autopct='%1.1f%%', startangle=140) plt.title('压力水平分布') plt.show()
压力等级分布比较均匀,0级-3级分别占总数的33%左右,人数差距不是很大。
6.压力因素分析
6.1可视化差异分析
In?[15]:
plt.figure(figsize=(15,15)) # 焦虑水平 plt.subplot(2,2,1) sns.boxplot(x=data['stress_level'],y=data['anxiety_level']) plt.title('不同压力水平下焦虑水平情况') plt.xlabel('压力水平') plt.ylabel('焦虑水平') # 自尊水平 plt.subplot(2,2,2) sns.boxplot(x=data['stress_level'],y=data['self_esteem']) plt.title('不同压力水平下自尊水平情况') plt.xlabel('压力水平') plt.ylabel('自尊水平') # 心理健康病史 plt.subplot(2,2,3) counts = data.groupby(['stress_level','mental_health_history']).size().unstack(fill_value=0) counts.plot(kind='bar', stacked=True, ax=plt.gca()) plt.legend(title='心理健康病史', loc='upper right') plt.title('不同压力水平下心理健康病史的分布') plt.xlabel('压力水平') plt.ylabel('频数') plt.xticks(rotation=0) # 抑郁情况 plt.subplot(2,2,4) sns.boxplot(x=data['stress_level'],y=data['depression']) plt.title('不同压力水平下抑郁情况') plt.xlabel('压力水平') plt.ylabel('抑郁情况') plt.tight_layout() plt.show()
通过四幅子图可以发现,心理方面对学生的压力的影响比较明显,值得注意的一点是:压力程度越大的学生自尊程度越低,压力水平的增加往往与自尊水平的降低有关,压力越大的时候,越容易不自信,自尊水平的中位数随着压力水平的增加而降低,并且在更高的压力水平下数据的分散程度变大,这可能表明在压力增大的情况下,学生的自尊感受到了负面影响,且学生间自尊水平的差异也变得更大。
In?[16]:
plt.figure(figsize=(15,15)) # 头痛问题 plt.subplot(2,2,1) sns.violinplot(x=data['stress_level'],y=data['headache']) plt.title('不同压力水平下头痛程度') plt.xlabel('压力水平') plt.ylabel('头痛程度') # 血压问题 plt.subplot(2,2,2) counts = data.groupby(['stress_level', 'blood_pressure']).size().unstack(fill_value=0) counts.plot(kind='bar', stacked=True, ax=plt.gca()) plt.legend(title='血压问题等级', loc='upper right') plt.title('不同压力水平下血压问题等级的分布') plt.xlabel('压力水平') plt.ylabel('频数') plt.xticks(rotation=0) # 睡眠质量 plt.subplot(2,2,3) sns.violinplot(x=data['stress_level'],y=data['sleep_quality']) plt.title('不同压力水平下睡眠质量等级情况') plt.xlabel('压力水平') plt.ylabel('睡眠质量') # 呼吸问题 plt.subplot(2,2,4) sns.violinplot(x=data['stress_level'],y=data['breathing_problem']) plt.title('不同压力水平下呼吸问题程度') plt.xlabel('压力水平') plt.ylabel('呼吸问题程度') plt.tight_layout() plt.show()
通过四幅子图可以发现,生理方面对学生的压力的影响比较明显,值得注意的是,压力为2级的学生,血压问题都是最严重的,但是压力0级的学生血压问题反而比压力为1级的学生小,这一点与预期的并不符合,或许有适当的压力,能够让学生的血压问题更小吧。
In?[17]:
plt.figure(figsize=(15,15)) # 噪音环境水平 plt.subplot(2,2,1) sns.violinplot(x=data['stress_level'],y=data['noise_level']) plt.title('不同压力水平下噪音程度') plt.xlabel('压力水平') plt.ylabel('噪音程度') # 居住条件 plt.subplot(2,2,2) sns.violinplot(x=data['stress_level'],y=data['living_conditions']) plt.title('不同压力水平下居住条件优劣情况') plt.xlabel('压力水平') plt.ylabel('居住条件优劣情况') # 安全等级 plt.subplot(2,2,3) sns.violinplot(x=data['stress_level'],y=data['safety']) plt.title('不同压力水平下安全等级') plt.xlabel('压力水平') plt.ylabel('安全等级') # 基本需求满足情况 plt.subplot(2,2,4) sns.scatterplot(x=data['basic_needs'],y=data['stress_level'],alpha=0.6) sns.regplot(x=data['basic_needs'],y=data['stress_level'],scatter=False,color='red') # 趋势线 plt.title('压力水平与基本满足情况的关系') plt.xlabel('基本满足情况') plt.ylabel('压力水平') plt.tight_layout() plt.show()
通过四幅子图可以发现,生活环境对学生的压力的影响比较明显,且均符合我们的预期,噪音等级与压力成正比,居住条件、安全等级、满足情况与压力成反比。
In?[18]:
plt.figure(figsize=(15,15)) # 学业表现 plt.subplot(2,2,1) sns.violinplot(x=data['stress_level'],y=data['academic_performance']) plt.title('不同压力水平下学业表现') plt.xlabel('压力水平') plt.ylabel('学业表现') # 学业负担 plt.subplot(2,2,2) sns.violinplot(x=data['stress_level'],y=data['study_load']) plt.title('不同压力水平下学业负担') plt.xlabel('压力水平') plt.ylabel('学业负担') # 师生关系 plt.subplot(2,2,3) sns.violinplot(x=data['stress_level'],y=data['teacher_student_relationship']) plt.title('不同压力水平下师生关系') plt.xlabel('压力水平') plt.ylabel('师生关系') # 未来职业担忧 plt.subplot(2,2,4) sns.violinplot(x=data['stress_level'],y=data['future_career_concerns']) plt.title('不同压力水平下对未来职业担忧情况') plt.xlabel('压力水平') plt.ylabel('未来职业担忧水平') plt.tight_layout() plt.show()
通过四幅子图可以发现,学业情况对学生的压力的影响比较明显,且均符合我们的预期,压力小的学生,往往有不错的学业表现,学业压力更小,师生关系更和谐,对未来职业的担忧情况也不明显。
In?[19]:
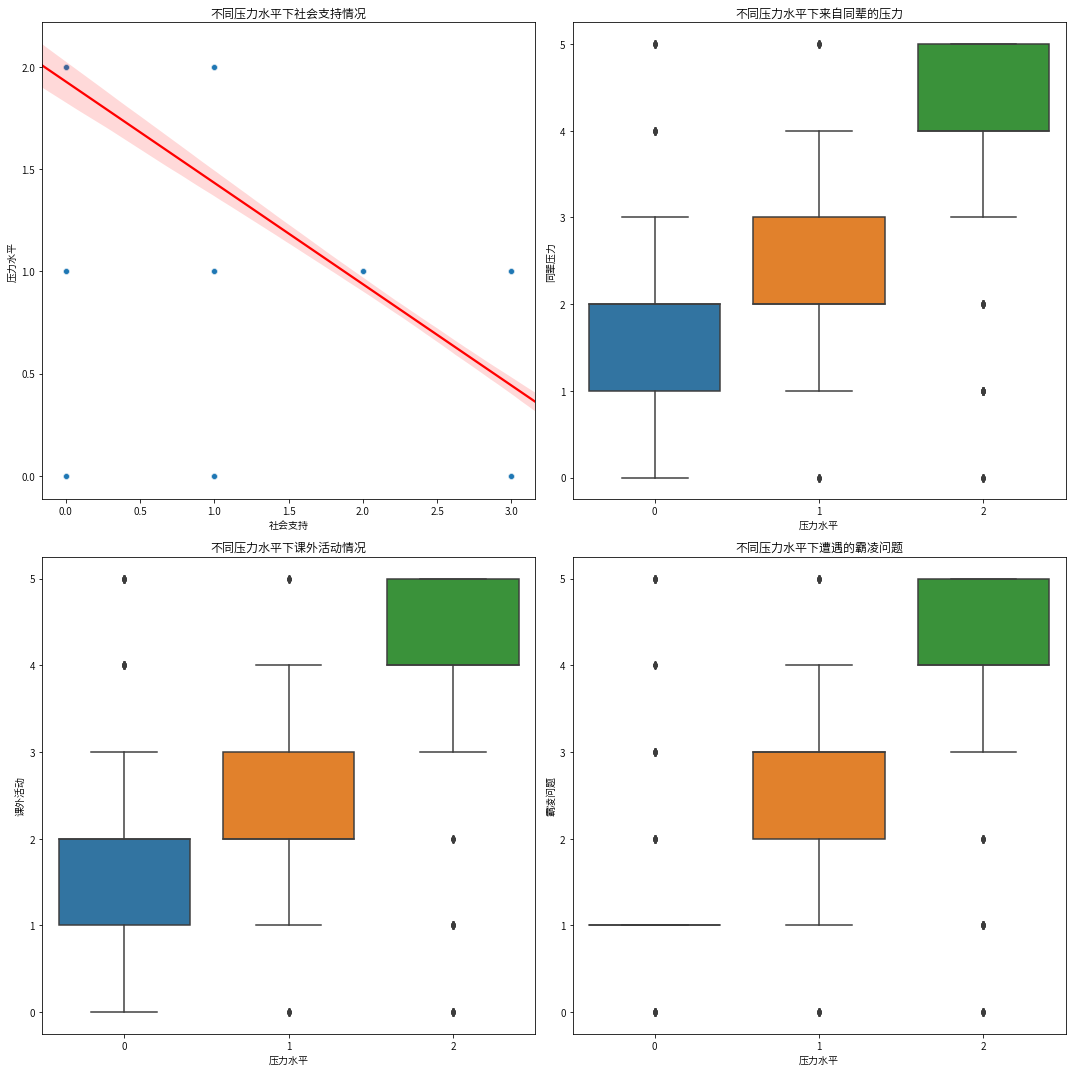
plt.figure(figsize=(15,15)) # 社会支持 plt.subplot(2,2,1) sns.scatterplot(x=data['social_support'],y=data['stress_level'],alpha=0.6) sns.regplot(x=data['social_support'],y=data['stress_level'],scatter=False,color='red') # 趋势线 plt.title('不同压力水平下社会支持情况') plt.xlabel('社会支持') plt.ylabel('压力水平') # 同辈压力 plt.subplot(2,2,2) sns.boxplot(x=data['stress_level'],y=data['peer_pressure']) plt.title('不同压力水平下来自同辈的压力') plt.xlabel('压力水平') plt.ylabel('同辈压力') # 课外活动 plt.subplot(2,2,3) sns.boxplot(x=data['stress_level'],y=data['extracurricular_activities']) plt.title('不同压力水平下课外活动情况') plt.xlabel('压力水平') plt.ylabel('课外活动') # 霸凌问题 plt.subplot(2,2,4) sns.boxplot(x=data['stress_level'],y=data['bullying']) plt.title('不同压力水平下遭遇的霸凌问题') plt.xlabel('压力水平') plt.ylabel('霸凌问题') plt.tight_layout() plt.show()
通过四幅子图可以发现,社会环境对学生的压力的影响比较明显,社会支持程度越大,学生的压力也就越小,所以提高社会对学生的支持程度,有助于缓解学生的压力,同辈压力少一点,也有助于降低学生的压力,这一个压力来源于家里人的“别人家的孩子”对比,所以降低对比,也有助于缓解学生的压力,课外活动越多,学生的压力也比较大,这一点不符合我们的期望,正常来说课外活动频率越高,能够充分缓解学生的压力,可能是因为过多的课外活动,反而增加了学生的压力,或者可以认为,这个课外活动其实是“兴趣班”,反而剥夺了学生课余的休息时间,当然这是猜测,数据中无过多的解释。
6.2相关性分析
In?[20]:
# 计算斯皮尔曼等级相关系数 spearman_corr = data.corr(method='spearman') plt.figure(figsize=(20,18)) sns.heatmap(spearman_corr,annot=True,fmt=".2f",cmap='Blues') plt.title('相关系数热力图') plt.show()
影响学生压力的因素有很多,可以说这些因素与学生压力有很强的线性关系,与可视化得出的结论一致,且各因素之间存在较强的相关性。
6.3KW检验
Kruskal-Wallis H检验(简称KW检验)是一种非参数统计检验,用于比较三个或更多独立样本的中位数。它是单因素方差分析(ANOVA)的非参数替代,适用于当数据不满足ANOVA要求的正态分布假设时,或者当数据是序数的而不是连续的。这里数据是有序数,所以采用了KW检验。
In?[21]:
anxiety_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('anxiety_level')]) self_esteem_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('self_esteem')]) mental_health_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('mental_health_history')]) depression_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('depression')]) print("焦虑水平:", anxiety_kw_test) print("自尊水平:", self_esteem_kw_test) print("心理健康病史:", mental_health_kw_test) print("抑郁水平:", depression_kw_test)焦虑水平: KruskalResult(statistic=702.387140222182, pvalue=4.157198094141301e-135) 自尊水平: KruskalResult(statistic=742.8686053265434, pvalue=5.529809963705805e-137) 心理健康病史: KruskalResult(statistic=462.3745218739696, pvalue=1.462706387212143e-102) 抑郁水平: KruskalResult(statistic=708.8431024713545, pvalue=5.346767393414693e-132)In?[22]:
headache_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('headache')]) blood_pressure_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('blood_pressure')]) sleep_quality_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('sleep_quality')]) breathing_problem_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('breathing_problem')]) print("头痛问题:", headache_kw_test) print("血压问题:", blood_pressure_kw_test) print("睡眠质量:", sleep_quality_kw_test) print("呼吸问题:", breathing_problem_kw_test)头痛问题: KruskalResult(statistic=687.9674316854657, pvalue=1.9626072816290985e-146) 血压问题: KruskalResult(statistic=704.1568611356015, pvalue=1.2424542536069255e-153) 睡眠质量: KruskalResult(statistic=772.0516673162025, pvalue=1.2855393918686477e-164) 呼吸问题: KruskalResult(statistic=526.8375002359497, pvalue=1.2837926727682774e-111)In?[23]:
noise_level_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('noise_level')]) living_conditions_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('living_conditions')]) safety_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('safety')]) basic_needs_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('basic_needs')]) print("环境噪音水平:", noise_level_kw_test) print("居住条件:", living_conditions_kw_test) print("安全:", safety_kw_test) print("基本需求满足情况:", basic_needs_kw_test)环境噪音水平: KruskalResult(statistic=586.5631247729671, pvalue=1.6178791193748772e-124) 居住条件: KruskalResult(statistic=575.0041918394753, pvalue=5.081774855065671e-122) 安全: KruskalResult(statistic=640.9395255011125, pvalue=2.8762457483637736e-136) 基本需求满足情况: KruskalResult(statistic=663.4281526029017, pvalue=3.961677558956117e-141)In?[24]:
academic_performance_kw = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('academic_performance')]) academic_burden_kw = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('study_load')]) teacher_student_relationship_kw = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('teacher_student_relationship')]) future_career_concerns_kw = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('future_career_concerns')]) print("学业表现:", academic_performance_kw) print("学业负担:", academic_burden_kw) print("师生关系:", teacher_student_relationship_kw) print("未来职业担忧:", future_career_concerns_kw)学业表现: KruskalResult(statistic=673.751808663016, pvalue=2.3235644313954424e-143) 学业负担: KruskalResult(statistic=539.8457949422015, pvalue=1.9934698555723444e-114) 师生关系: KruskalResult(statistic=666.9152047208431, pvalue=6.983613712367081e-142) 未来职业担忧: KruskalResult(statistic=756.2615479117544, pvalue=3.34533736719054e-161)In?[25]:
social_support_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('social_support')]) peer_pressure_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('peer_pressure')]) extracurricular_activities_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('extracurricular_activities')]) bullying_kw_test = stats.kruskal(*[group['stress_level'] for name, group in data.groupby('bullying')]) print("社会支持:", social_support_kw_test) print("同辈压力:", peer_pressure_kw_test) print("课外活动:", extracurricular_activities_kw_test) print("霸凌问题:", bullying_kw_test)社会支持: KruskalResult(statistic=601.1430165688822, pvalue=5.696421974927428e-130) 同辈压力: KruskalResult(statistic=610.1398563933049, pvalue=1.3028971044658154e-129) 课外活动: KruskalResult(statistic=639.7145291505822, pvalue=5.291614451431716e-136) 霸凌问题: KruskalResult(statistic=762.1237834149484, pvalue=1.805047626556851e-162)KW检验的p值均小于0.05,可以认为这些因素对学生的压力水平具有显著影响。
7.梯度提升机(GBM模型)
7.1数据划分
In?[26]:
x = data.drop('stress_level',axis=1) y = data['stress_level'] x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=15) #28分7.2模型建立
In?[27]:
gbm_model = GradientBoostingClassifier(random_state=15) gbm_model.fit(x_train, y_train)Out[27]:
GradientBoostingClassifier(criterion='friedman_mse', init=None, learning_rate=0.1, loss='deviance', max_depth=3, max_features=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=100, n_iter_no_change=None, presort='auto', random_state=15, subsample=1.0, tol=0.0001, validation_fraction=0.1, verbose=0, warm_start=False)7.3模型评估
In?[28]:
y_pred_gbm = gbm_model.predict(x_test) class_report = classification_report(y_test, y_pred_gbm) print(class_report)precision recall f1-score support 0 0.89 0.88 0.89 76 1 0.88 0.86 0.87 71 2 0.86 0.89 0.87 73 accuracy 0.88 220 macro avg 0.88 0.88 0.88 220 weighted avg 0.88 0.88 0.88 220In?[29]:
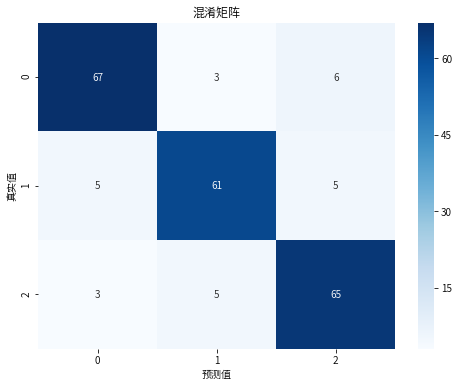
cm = confusion_matrix(y_test,y_pred_gbm) plt.figure(figsize=(8, 6)) sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=[0, 1, 2], yticklabels=[0, 1, 2]) plt.title('混淆矩阵') plt.xlabel('预测值') plt.ylabel('真实值') plt.show()
GBM模型评分如下:
1.精确度: 对于类别0,精确度为0.89,对于类别1,精确度为0.88,对于类别2,精确度为0.86。
2.召回率: 对于类别0,召回率为0.88,对于类别1,召回率为0.86,对于类别2,召回率为0.89。
3.F1得分: 对于类别0,F1得分为0.89,对于类别1,F1得分为0.87,对于类别2,F1得分为0.87。
4.准确率: 0.88。7.4影响因素分析
In?[30]:
feature_importances = gbm_model.estimators_[0][0].feature_importances_ features_gbm = pd.DataFrame({'特征': x.columns, '重要度': feature_importances}) features_gbm.sort_values(by='重要度', ascending=False, inplace=True) features_gbmOut[30]:
特征 重要度 12 academic_performance 0.832648 5 blood_pressure 0.083959 13 study_load 0.044445 14 teacher_student_relationship 0.022467 0 anxiety_level 0.008366 16 social_support 0.008116 11 basic_needs 0.000000 18 extracurricular_activities 0.000000 17 peer_pressure 0.000000 15 future_career_concerns 0.000000 10 safety 0.000000 1 self_esteem 0.000000 9 living_conditions 0.000000 8 noise_level 0.000000 7 breathing_problem 0.000000 6 sleep_quality 0.000000 4 headache 0.000000 3 depression 0.000000 2 mental_health_history 0.000000 19 bullying 0.000000 影响模型预测的主要特征就是:academic_performance(学业表现),表明学生的学业表现是影响模型预测的主要因素,也符合预期,学生的压力主要来自学业。
8.随机森林模型
8.1建立模型
In?[31]:
rf_model = RandomForestClassifier(random_state=15) rf_model.fit(x_train,y_train)/opt/conda/lib/python3.6/site-packages/sklearn/ensemble/forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22. "10 in version 0.20 to 100 in 0.22.", FutureWarning)Out[31]:
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini', max_depth=None, max_features='auto', max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=None, oob_score=False, random_state=15, verbose=0, warm_start=False)8.2模型评估
In?[32]:
y_pred_rf = rf_model.predict(x_test) class_report_rf = classification_report(y_test, y_pred_rf) print(class_report_rf)precision recall f1-score support 0 0.89 0.92 0.90 76 1 0.85 0.87 0.86 71 2 0.90 0.84 0.87 73 accuracy 0.88 220 macro avg 0.88 0.88 0.88 220 weighted avg 0.88 0.88 0.88 220In?[33]:
cm = confusion_matrix(y_test,y_pred_rf) plt.figure(figsize=(8, 6)) sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=[0, 1, 2], yticklabels=[0, 1, 2]) plt.title('混淆矩阵') plt.xlabel('预测值') plt.ylabel('真实值') plt.show()
随机森林模型评分如下:
1.精确度: 对于类别0,精确度为0.89,对于类别1,精确度为0.85,对于类别2,精确度为0.90。
2.召回率: 对于类别0,召回率为0.92,对于类别1,召回率为0.87,对于类别2,召回率为0.84。
3.F1得分: 对于类别0,F1得分为0.90,对于类别1,F1得分为0.86,对于类别2,F1得分为0.87。
4.准确率: 0.88。8.3影响因素分析
In?[34]:
feature_importances = rf_model.feature_importances_ features_rf = pd.DataFrame({'特征': x.columns, '重要度': feature_importances}) features_rf.sort_values(by='重要度', ascending=False, inplace=True) features_rfOut[34]:
特征 重要度 5 blood_pressure 0.197288 18 extracurricular_activities 0.129251 19 bullying 0.119898 10 safety 0.112843 16 social_support 0.090272 6 sleep_quality 0.055914 3 depression 0.047566 15 future_career_concerns 0.046179 12 academic_performance 0.045168 13 study_load 0.033624 1 self_esteem 0.022273 0 anxiety_level 0.018850 4 headache 0.016429 8 noise_level 0.016109 7 breathing_problem 0.011192 11 basic_needs 0.009771 17 peer_pressure 0.008902 14 teacher_student_relationship 0.008055 9 living_conditions 0.007429 2 mental_health_history 0.002984 随机森林模型这边得到的影响因素前五为:血压问题、课外活动频率、霸凌问题、居住安全问题、社会支持度,其中血压问题不一定是导致学生压力大的原因,反而可能是学生压力大诱发了血压问题,这个模型不能解释因果关系,所以排除血压问题,认为课外活动频率、霸凌问题、安全问题、社会支持度也是主要影响学生压力的因素。
9.总结
本项目主要采取可视化分析探索数据,并且根据学生不同的压力水平进行差异分析,发现所有因素对于学生的压力水平都有显著的相关性,再通过KW检验,可以认为这些因素对学生的压力水平具有显著影响,或者说不同压力水平下,这些因素之间都有差异,最后建立了梯度提升机和随机森林模型,进一步探究这些因素的重要度,得到的结论如下:
1.在心理因素方面,压力水平与焦虑程度、心理健康病史、抑郁情况呈正相关,与自尊情况呈负相关。
2.在生理因素方面,压力水平与头痛问题、呼吸问题、呈正相关,与睡眠质量呈负相关,压力0级的学生血压问题反而比压力为1级的学生小。
3.在生活环境方面,噪音越大,压力也就越大;居住条件越差,压力也就越大;越不安全,压力也就越大;越能满足基本情况,压力越小。
4.在学习方面,学业表现越好,压力就越小;学业负担越大,压力越大;师生关系越好,学生的压力也就越小;对未来职业越担忧,学生的压力也就越大。
5.在社会方面,社会越支持,压力也就越小;同辈压力、课外活动频率、霸凌问题都与压力成正相关。
6.通过观察斯皮尔曼等级相关系数热力图,可以发现所有因素都与学生压力有线性相关关系,并且这些因素之间也存在很强的相关性。
7.通过KW检验,可以认为这些因素对学生的压力水平具有显著影响。
8.通过GBM模型,发现学业表现是影响学生压力的主要因素。
9.通过随机森林模型,可以发现课外活动频率、霸凌问题、安全问题、社会支持度也是主要影响学生压力的因素。










本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!