【深入挖掘Java技术】「源码原理体系」盲点问题解析之HashMap工作原理全揭秘(下)
盲点问题解析之HashMap工作原理全揭秘
承接上文
在阅读了上篇文章《【深入挖掘Java技术】「源码原理体系」盲点问题解析之HashMap工作原理全揭秘(上)》之后,相信您对HashMap的基本原理和基础结构已经有了初步的认识。接下来,我们将进一步深入探索HashMap的源码,揭示其深层次的技术细节。通过这次解析,您将更深入地理解HashMap的工作原理,掌握其核心实现。

创建HashMap对象
创建一个Map对象时,会为其分配一些默认参数属性,包括参考容量(capacity)、扩容阈值(threshold)和负载因子(loadFactor)。这些参数属性在Map对象的性能和存储效率方面起着关键作用。
-
参考容量(capacity):这是Map对象初始化时分配的存储空间大小。它决定了Map对象能够容纳的键值对数量。合理设置参考容量可以避免频繁的扩容操作,提高性能。
-
扩容阈值(threshold):当Map中的元素数量达到或超过该阈值时,Map对象会自动进行扩容,以增加存储空间。扩容阈值的设定与负载因子有关,目的是为了在合理利用空间的同时避免过多的内存消耗。
-
负载因子(loadFactor):它表示的是已用空间与总空间的比例。负载因子用于平衡Map的存储效率和空间利用率。较高的负载因子意味着更少的空间利用率,但可能导致更高的查找成本;反之,较低的负载因子则意味着更好的空间利用率和更快的查找速度。
参考容量(capacity)
用来作为创建map对象中Node[]数组的初始长度(容量)的参考,默认为16。
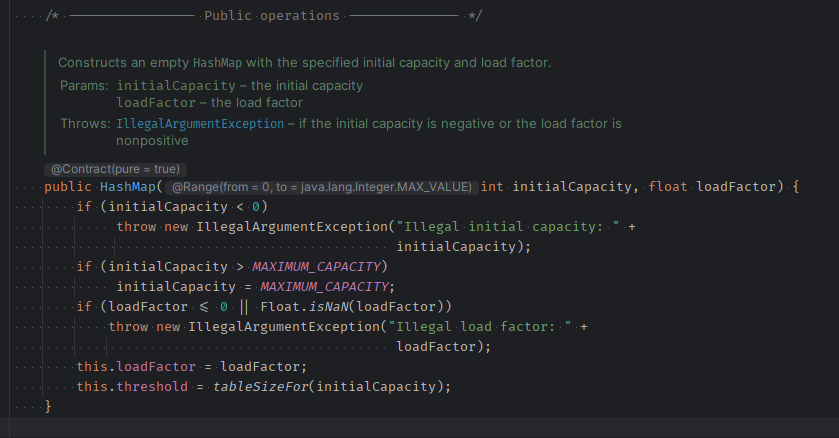
/**
* Constructs an empty {@code HashMap} with the specified initial
* capacity and the default load factor (0.75).
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* Constructs an empty {@code HashMap} with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
可以自己指定长度,指定方式为:
//capacity的值就是你要指定的长度
Map<String,Object> map = new HashMap<>(capacity);
Hashmap内部有一个机制
创建map对象中Node[]数组的初始长度必须要是2的n次方,当你设置长度是23的时候,hashmap会把初始长度设置成32,因为23在16(2的4次方)到32(2的5次方)之间,取最大的数32。
扩容阈值(threshold)
hashmap在新增元素的过程中,如果达到扩容阈值,就会扩大Node[]数组的长度
负载因子(loadFactor)
其默认值为:参考容量 * 负载因子,而负载因子的默认值为0.75,可以修改但是不建议修改。
HashMap存储元素的过程
-
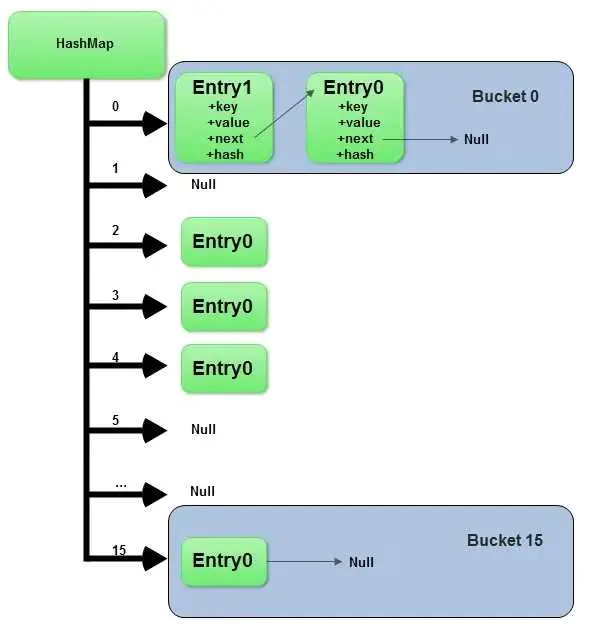
计算出对应key的hash值,然后去判断当前Node[]数组是不是为空,为空就新建,不为空就对hash值作减一与运算得到数组下标,将k、v封装到Node对象当中(节点)
-
调用k的hashCode()方法取出hash值,通过hashcode值和数组长度取模得到元素存储的下标。
- 此时分为两种情况:
- 下标位置上没有元素,直接把元素插入
- 下标位置上已有元素,判断该位置的元素和当前元素是否相等,使用equals来比较(默认是比较两个对象的地址)。
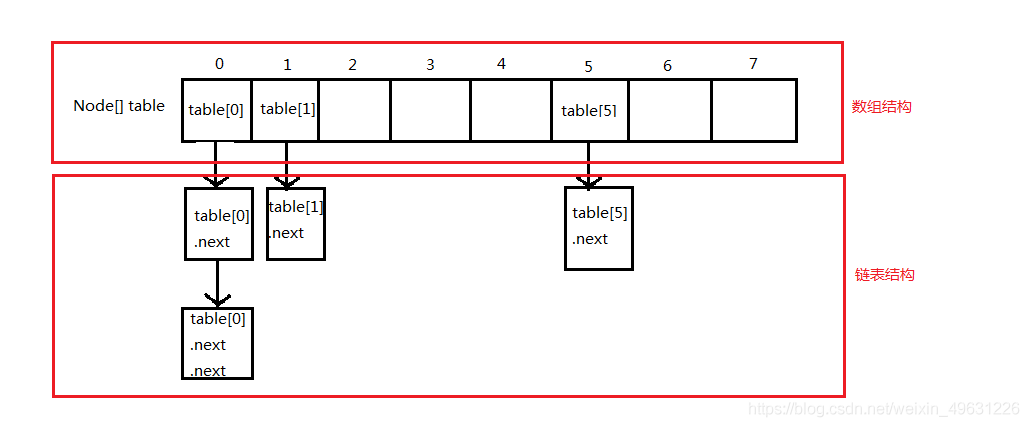
- 如果两只相等则直接覆盖,如果不等则(Hash碰撞)在原元素下面使用链表的结构存储该元素(如果已存在链表,则插在链表尾部),每个元素节点都有一个next属性指向下一个节点,这就由数组结构变成了数组+链表;
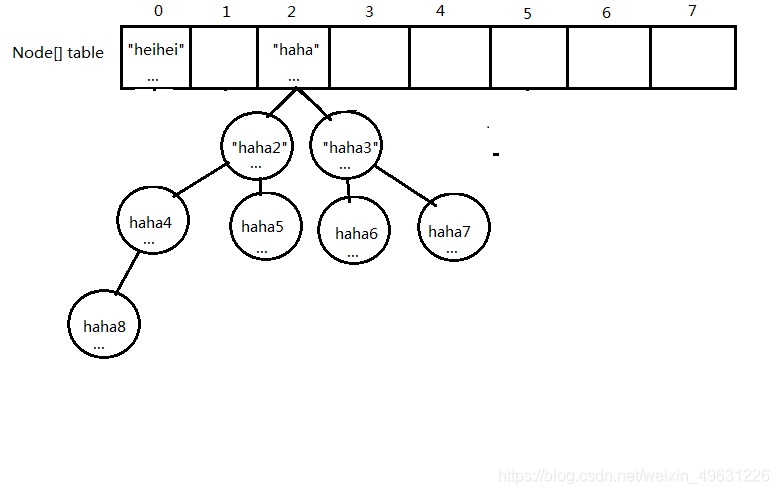
- 遇到哈希碰撞后,就会看下当前链表是不是以红黑树的方式存储,是的话,就会遍历红黑树,看有没有相同key的元素,有就覆盖,没有就执行红黑树插入。
- 如果是普通链表,则按普通链表的方式遍历链表的元素,判断是不是同一个key,是的话就覆盖,不是的话就追加到后面去。
- 此时分为两种情况:
HashMap的put方法
/**
*
*/
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// key为null调用putForNullKey(value)
if (key == null) return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
/**
* Offloaded version of put for null keys
*/
private V putForNullKey(V value) {
// for循环处理key为空的情况
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e); //参数e, 是Entry.next
//如果size超过threshold,则扩充table大小。再散列
if (size++ >= threshold)
resize(2 * table.length);
}
JDK8+的扩容机制
因为链表中元素太多的时候回影响查找效率,所以当链表的元素个数达到8的时候且hash桶的长度大于64的时候,使用链表存储就转变成了使用红黑树存储(当红黑树上的节点数量小于6个,会重新把红黑树变成单向链表数据结构),原因就是红黑树是平衡二叉树,在查找性能方面比链表要高很多。
Node实体类
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
...
}
可以看到有四个参数:hash(hash值)、key(我们平常put的key)、value(put的value)、next(hashMap数据结构图中的.next,也就是记录链表中每个元素的后继元素)
HashMap取值实现
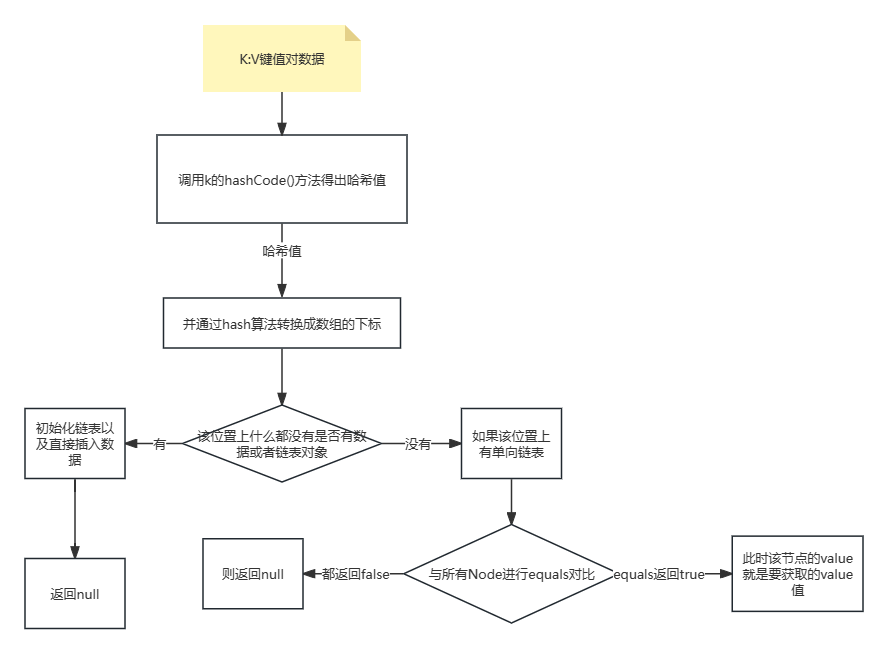
- 1.先调用k的hashCode()方法得出哈希值,并通过hash算法转换成数组的下标。
- 2.通过hash值转换成数组下标后,通过数组定位到下标位置。
- 3.如果该位置上什么都没有,插入数据之后,直接返回null。
- 3.如果该位置上有单向链表,那么就拿参数K和单向链表上的每一个节点的K进行equals比较。
- 3.1 如果所有equals都返回false,则返回null。
- 3.2 如果有一个节点的K和参数K通过equals返回true,那么此时该节点的value就是要获取的value值。
定位Hash桶的位置
一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//先定位到数组元素,再遍历该元素处的链表
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。
// 存储时:
int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap里面实现一个静态内部类Entry,其重要的属性有key,value,next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean。
我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry[] table;
resize扩容
在做扩容的时候会生成一个新的数组,原来的所有数据需要重新计算哈希码值重新分配到新的数组,所以扩容的操作非常消耗性能。所以,如果知道要存入的数据量比较大的话,可以在创建的时候先指定一个比较大的数据容量也可以引申到一个问题
HashMap是先插入还是先扩容?
HashMap初始化后首次插入数据时,先发生resize扩容再插入数据,之后每当插入的数据个数达到threshold时就会发生resize,此时是先插入数据再resize。
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
//重新计算index
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
扩容是在元素插入之前进行的扩容还是元素插入之后进行的扩容
JDK8之前(先扩容再插入)
在JDK8之前,HashMap在插入一个新元素时会先检查当前数组是否已满(基于设定的容量和负载因子)。如果当前数组已满,HashMap会进行扩容。这意味着,在JDK8之前,元素插入前会进行扩容判断。
JDK8之后(先插入再扩容)
从JDK8开始,HashMap的扩容机制有所改变。当新元素要被插入时,会先进行位置计算以确定应该放在数组的哪个位置。计算完位置后,再检查该位置之前的元素是否为空。如果为空,则新元素会被插入。接着,再判断当前数组是否已满(基于设定的容量和负载因子)。如果已满,则进行扩容。
这种改变主要是为了提高性能。因为在JDK8之前的实现中,每次插入元素时都需要检查数组是否已满,这会增加插入操作的开销。而在JDK8之后的实现中,插入操作不再需要每次都进行扩容判断,从而提高了插入操作的性能。
存储元素超过阈值一定会进行扩容吗?
- JDK8之前中不一定,只有存储元素超过阈值并且当前存储位置不为null,才会进行扩容。
- 在JDK8之前中会进行扩容
什么时候转化为红黑树?
红黑树是一种自平衡的二叉搜索树,它的插入、删除和查找操作的时间复杂度都是 O(log n)。相比于链表,红黑树在大数据量情况下的性能更好。
HashMap中的链表长度超过8,HashMap 会将链表转化为红黑树。这是为了提高在大数据量情况下的查询和插入效率。
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 并且如果链表的长度大于8会尝试调用treeifyBin 方法
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
}
当链表的长度大于8时,HashMap 会尝试调用 treeifyBin 方法。这个方法的作用是将链表转化为红黑树。
在HashMap中,每个桶(bucket)存储了一个链表或红黑树。当链表的长度超过8时,HashMap 认为链表的长度已经达到了一个临界点,此时将链表转化为红黑树可以提高查询和插入操作的效率。
treeifyBin
通过调用 treeifyBin 方法,HashMap可以在链表长度大于8时将链表转化为红黑树,从而提高HashMap 在大数据量情况下的性能。
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// MIN_TREEIFY_CAPACITY = 64;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
treeifyBin 方法会遍历链表中的每个节点,并将节点重新组织成一个红黑树。这个过程会重新计算节点的哈希值,并根据哈希值重新分配节点在红黑树中的位置。
总结
总体希望大家可以把HashMap的技术进行分析和原理逐步吃透,尽可能深入其中,探索奥秘!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!