数据处理之pandas库
发布时间:2024年01月20日
Pandas 是一个基于 NumPy 的开源数据处理和数据分析库,它提供了高效、灵活且易于使用的数据结构和数据分析工具。Pandas 的设计目标是使数据操作变得简单直观,同时提供高性能的数据操作能力。
Pandas 提供两种主要的数据结构:Series 和 DataFrame。
- Series 是一维带标签的数组,可以存储不同类型的数据。它类似于一列数据或一个字典,每个元素都有一个标签(索引)来标识。
- DataFrame 是二维表格数据结构,由多个 Series 组成,类似于关系型数据库中的表格。DataFrame 可以看作是多个 Series 对象按照列方向拼接而成的。
Pandas 提供了丰富的数据操作和处理功能,包括数据清洗、数据合并、数据过滤、数据排序、数据分组、数据计算等。它还支持从多种数据源读取数据,如 CSV 文件、Excel 文件、SQL 数据库等,并可以将数据写入不同的文件格式。
Pandas 的优势在于其高效的数据处理能力。它通过底层的 C 或 Cython 实现了大部分功能,提供了高性能的数据操作。此外,Pandas 还提供了灵活的索引和切片功能,可以轻松地选择、过滤和操作数据。
除了数据处理,Pandas 还提供了简单易用的数据可视化功能。它结合了 Matplotlib 库,可以轻松地绘制折线图、柱状图、散点图等各种图表。
以下是 Pandas 常用的功能:
1.数据读取和写入
Pandas 可以从多种数据源读取数据,如 CSV 文件、Excel 文件、SQL 数据库等。
import pandas as pd
df = pd.read_csv('example.csv')
print(df)
Pandas 可以将数据写入到不同的文件格式,如 CSV、Excel、SQL 数据库等。
import pandas as pd
df.to_csv('example.csv', index=False)
2.数据的清洗和处理
2.1 失值处理:填充或删除缺失值。
import pandas as pd
df.fillna(value=0)
2.2 重复数据处理:删除重复的行或列。
import pandas as pd
df.drop_duplicates()
2.3 数据过滤:根据条件筛选出满足特定条件的数据。
import pandas as pd
df[df['A'] > 0]
print(df)2.4 数据排序:按照指定的列或索引进行排序。
import pandas as pd
df.sort_values(by='B')
2.5?数据分组:对数据进行分组计算,如聚合、求和、均值等。
import pandas as pd
df.groupby('A').mean()
2.6数据合并和连接:将不同的数据集合并或连接成一个。
import pandas as pd
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': [5, 6, 7, 8]})
pd.merge(df1, df2, on='key', how='outer')
3.数据选择和切片
3.1 选择行或列
import pandas as pd
df['A']
#选择列
df = df.loc[0]
#选择索引为0的行
df[df['A'] > 0]3.2 切片
import pandas as pd
df.iloc[0:2, 0:2]
4.数据统计和聚合
4.1?描述统计:计算数据的基本描述统计信息,如均值、标准差、最大值、最小值等。
df.describe() 是 Pandas 中的一个函数,它用于生成描述性统计信息的摘要。该函数仅适用于数据类型为数值型和布尔型的列,而忽略了文本列。
import pandas as pd
# 创建一个示例 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'London', 'Paris']}
df = pd.DataFrame(data)
# 描述性统计信息
summary = df.describe()
print(summary)
4.2?聚合函数:对数据进行分组后,可以使用聚合函数进行统计计算,如求和、均值、计数等。
import pandas as pd
# 创建一个示例 DataFrame
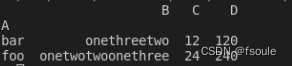
data = {'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],
'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],
'C': [1, 2, 3, 4, 5, 6, 7, 8],
'D': [10, 20, 30, 40, 50, 60, 70, 80]}
df = pd.DataFrame(data)
# 按列 A 分组并求和
grouped = df.groupby('A').sum()
print(grouped)
输出结果:
以上就是pandas一些常用的功能。总而言之,Pandas 是一个强大的数据处理和分析工具,适用于各种规模的数据集。它使得数据处理变得简单直观,并提供了高效的性能。无论是数据清洗、数据分析还是数据可视化,Pandas 都是一种重要的选择。
文章来源:https://blog.csdn.net/kuailezzf/article/details/135698533
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章