SqueezeNet:通过紧凑架构彻底改变深度学习
一、介绍
????????在深度学习领域,对效率和性能的追求往往会带来创新的架构。SqueezeNet 是神经网络设计的一项突破,体现了这种追求。本文深入研究了 SqueezeNet 的复杂性,探讨其独特的架构、设计背后的基本原理、应用及其对深度学习领域的影响。

在创新经济中,效率是成功的货币。SqueezeNet 证明了这一点,证明在深度学习领域,少确实可以多。
二、SqueezeNet架构
2.1 综述
????????SqueezeNet 是一种卷积神经网络 (CNN),可以用更少的参数实现 AlexNet 级别的精度。其架构设计巧妙,可在保持高精度的同时减小模型尺寸。SqueezeNet 的核心是“fire 模块”,这是一个紧凑的构建块,包含两层:挤压层和扩展层。挤压层利用 1x1 卷积滤波器来压缩输入数据,从而降低维度。随后,扩展层混合使用 1x1 和 3x3 滤波器来增加通道深度,捕获更广泛的特征。
????????SqueezeNet 是一种深度神经网络架构,旨在以更少的参数提供 AlexNet 级别的精度。它通过使用更小的卷积滤波器和称为“火模块”的策略来实现这一点。这些模块是“挤压”层和“扩展”层的组合,“挤压”层使用 1x1 滤波器来压缩输入通道,“扩展”层使用 1x1 和 3x3 滤波器的混合来增加通道深度。SqueezeNet 的主要优点是模型尺寸小和计算速度快,这使得它非常适合部署在计算资源有限的环境中,例如移动设备或嵌入式系统。此外,它的体积小,更容易通过网络传输,并且需要更少的存储内存。
2.2 设计原理
????????SqueezeNet 设计背后的主要动机是在不影响性能的情况下创建轻量级模型。AlexNet 等传统 CNN 虽然有效,但参数较多,导致计算成本和存储要求较高。SqueezeNet 通过采用更小的滤波器和更少的参数来解决这些挑战,从而减少计算量。这使得它特别适合部署在资源受限的环境中,例如移动设备或嵌入式系统。
2.3 SqueezeNet的应用
????????SqueezeNet 的紧凑尺寸和效率为各种应用开辟了新途径。在内存和处理能力有限的移动应用中,SqueezeNet 可实现高级图像识别和实时分析。在机器人技术中,它有助于高效的实时决策。此外,其较小的模型尺寸在基于网络的应用中具有优势,允许在带宽受限的网络上更快地传输神经网络模型。
2.4 对深度学习的影响
????????SqueezeNet 通过证明较小的网络可以与较大的网络一样有效,对深度学习领域产生了重大影响。它挑战了传统观念,即更大、更深的网络总是会产生更好的结果。这种范式转变引发了对高效神经网络设计的进一步研究,从而导致了 MobileNet 和 ShuffleNet 等其他紧凑架构的发展。
三、代码
????????创建 SqueezeNet 的完整 Python 实现以及合成数据集和绘图涉及几个步骤。我们将首先使用 TensorFlow 或 PyTorch 等深度学习库实现 SqueezeNet 架构。然后,我们将创建一个合成数据集,在此数据集上训练模型,最后绘制训练结果。
以下是如何使用 PyTorch 执行此操作的高级概述:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
# Define the Fire Module
class FireModule(nn.Module):
def __init__(self, in_channels, squeeze_channels, expand1x1_channels, expand3x3_channels):
super(FireModule, self).__init__()
self.squeeze = nn.Conv2d(in_channels, squeeze_channels, kernel_size=1)
self.expand1x1 = nn.Conv2d(squeeze_channels, expand1x1_channels, kernel_size=1)
self.expand3x3 = nn.Conv2d(squeeze_channels, expand3x3_channels, kernel_size=3, padding=1)
def forward(self, x):
x = F.relu(self.squeeze(x))
return torch.cat([
F.relu(self.expand1x1(x)),
F.relu(self.expand3x3(x))
], 1)
class SqueezeNet(nn.Module):
def __init__(self, num_classes=1000):
super(SqueezeNet, self).__init__()
self.num_classes = num_classes
# Initial convolution layer
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=7, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
)
# Fire modules
self.features.add_module("fire2", FireModule(96, 16, 64, 64))
self.features.add_module("fire3", FireModule(128, 16, 64, 64))
self.features.add_module("fire4", FireModule(128, 32, 128, 128))
self.features.add_module("maxpool4", nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True))
self.features.add_module("fire5", FireModule(256, 32, 128, 128))
# Additional Fire modules as needed
# ...
# Adjust the final Fire module to output 512 channels
self.features.add_module("final_fire", FireModule(256, 64, 256, 256))
# Final convolution layer
self.final_conv = nn.Conv2d(512, self.num_classes, kernel_size=1)
# Dropout and classifier
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
self.final_conv,
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d((1, 1))
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x.view(x.size(0), self.num_classes)
# Initialize the model
squeezenet = SqueezeNet()
# Synthetic Dataset
class SyntheticDataset(Dataset):
def __init__(self, num_samples, num_classes):
self.num_samples = num_samples
self.num_classes = num_classes
def __len__(self):
return self.num_samples
def __getitem__(self, idx):
image = torch.randn(3, 224, 224) # Simulating a 3-channel image
label = torch.randint(0, self.num_classes, (1,))
return image, label
# Create the synthetic dataset
synthetic_dataset = SyntheticDataset(num_samples=1000, num_classes=10)
dataloader = DataLoader(synthetic_dataset, batch_size=32, shuffle=True)
# Training
optimizer = optim.Adam(squeezenet.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
losses = []
accuracies = []
num_epochs = 5 # Example number of epochs
for epoch in range(num_epochs):
running_loss = 0.0
correct = 0
total = 0
for images, labels in dataloader:
optimizer.zero_grad()
outputs = squeezenet(images)
loss = criterion(outputs, labels.squeeze())
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels.squeeze()).sum().item()
epoch_loss = running_loss / len(dataloader)
epoch_accuracy = 100 * correct / total
losses.append(epoch_loss)
accuracies.append(epoch_accuracy)
print(f'Epoch {epoch+1}, Loss: {epoch_loss}, Accuracy: {epoch_accuracy}%')
# Plotting
plt.plot(losses)
plt.title('Training Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
plt.plot(accuracies)
plt.title('Training Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.show()
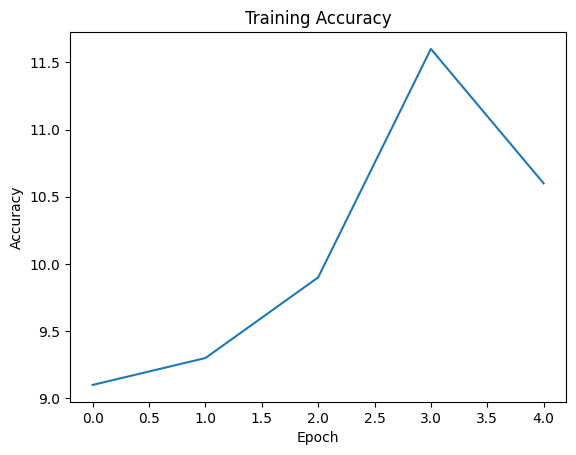
Epoch 1, Loss: 4.31704169511795, Accuracy: 9.1%
Epoch 2, Loss: 2.3903158977627754, Accuracy: 9.3%
Epoch 3, Loss: 2.391318053007126, Accuracy: 9.9%
Epoch 4, Loss: 2.366191916167736, Accuracy: 11.6%
Epoch 5, Loss: 2.4050718769431114, Accuracy: 10.6%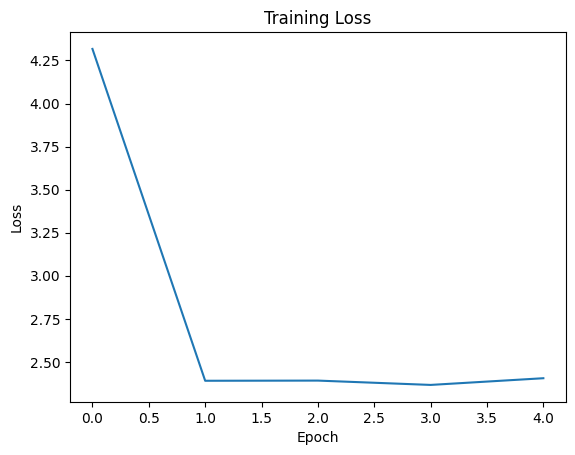
????????请记住,这是一个高级大纲。每个步骤都需要根据您的具体要求和 PyTorch 文档进行详细实施。此外,对合成数据集的训练不会产生有意义的见解,但对于测试实现很有用。对于实际训练,请考虑使用 CIFAR-10 或 ImageNet 等标准数据集。
四、结论
????????SqueezeNet 代表了神经网络发展的一个里程碑。其创新设计成功地平衡了尺寸和性能之间的权衡,使其成为高效深度学习的开创性模型。随着技术不断向更紧凑、更高效的解决方案发展,SqueezeNet 的影响力可能会增长,继续塑造神经网络设计和应用的未来。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!