Mysql 高级语句
目录
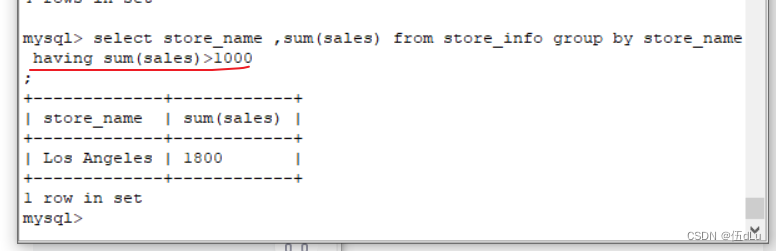
group by:对group by后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的
having:用来过滤由group by 语句返回的记录集,通常与group by语句联合使用
子查询:连接表格,在where子句或 having子句中插入另一个 SQL 语句
目录
group by:对group by后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的
having:用来过滤由group by 语句返回的记录集,通常与group by语句联合使用
子查询:连接表格,在where子句或 having子句中插入另一个 SQL 语句
高阶查询select语句:
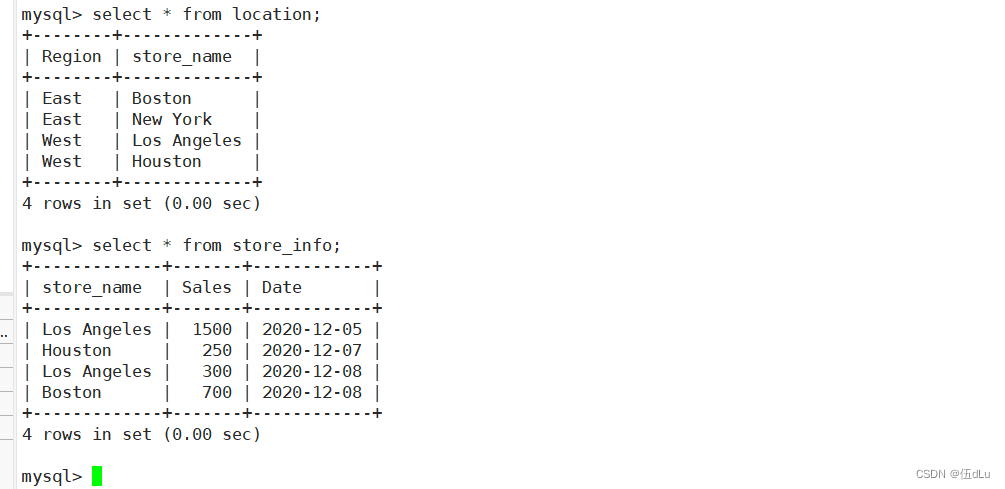
显示表格中一个或数个字段的所有数据记录:
select 字段?from? 表名;


添加内容:
显示表格中一个或数个字段的所有数据记录:
select 字段 from 表 where 字段

不显示重复的数据记录:distinct
select distinct 字段 from 表?

and且,or或
select 字段 from 表 where 条件1 and/or 条件2
and且
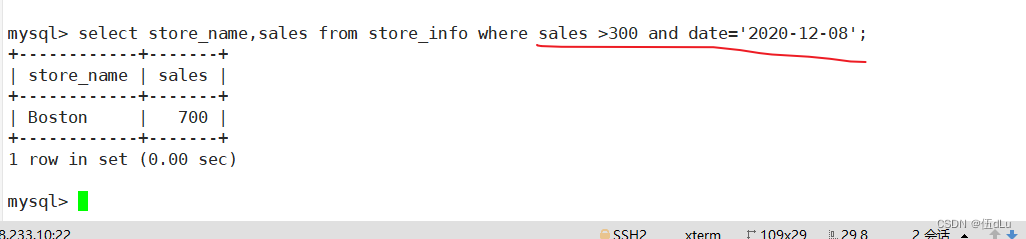
或or

显示已知的值的数据记录:in
select 字段 from 表 where 字段 in (值)

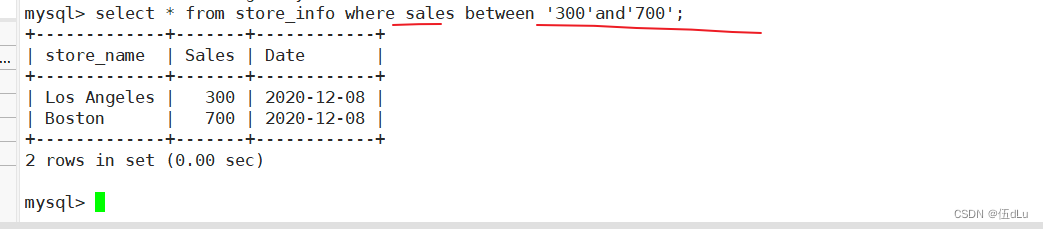
显示两个值范围内的数据记录:between
select 字段 from 表 where 字段 between ‘值1’ and ‘值2
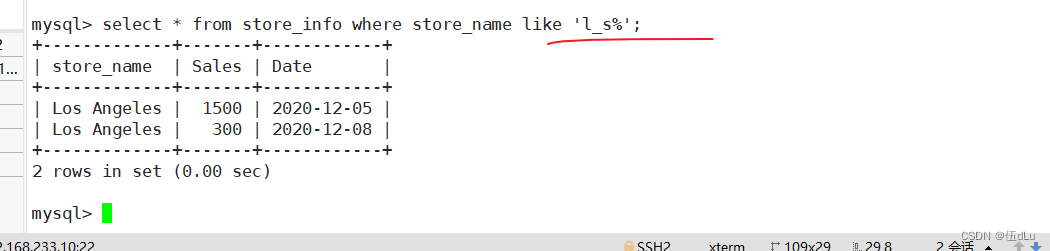
通配符:通常通配符都是跟 like一起使用的
like:匹配一个模式来找出我们要的数据记录
% :百分号表示零个、一个或多个字符
_ :下划线表示单个字符
select 字段 from 表 where 字段 like ‘通配符’

按关键字排序:order by
select 字段 from 表 [where 字段] order by "字段" [asc,desc];
asc:默认以升序排序

desc:以降序排序



函数:
数学函数:
rand()?? ??? ??? ??? ?返回 0 到 1 的随机数
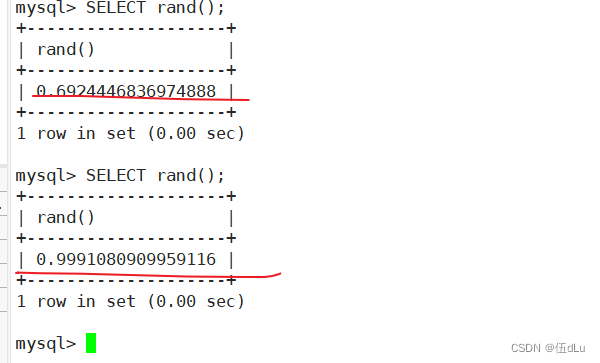
round(x,y)?? ??? ??? ?保留 x 的 y 位小数四舍五入后的值

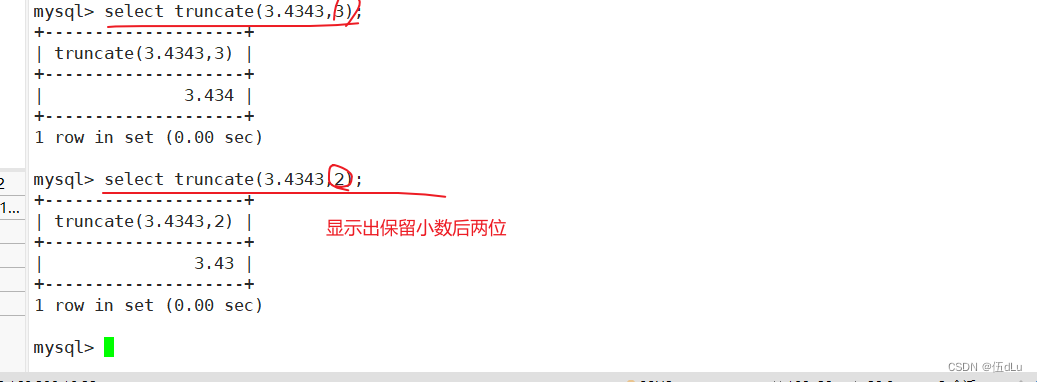
truncate(x,y)?? ??? ?返回数字 x 截断为 y 位小数的值
greatest(x1,x2...)?? ?返回集合中最大的值,也可以返回多个字段的最大的值
least? ? ? (x1,x2...)?? ??? ?返回集合中最小的值,也可以返回多个字段的最小的值
聚合函数:
avg()?? ??? ??? ??? ?返回指定列的平均值
count()?? ??? ??? ??? ?返回指定列中非 NULL 值的个数
min()?? ??? ??? ??? ?返回指定列的最小值
max()?? ??? ??? ??? ?返回指定列的最大值
sum(x)?? ??? ??? ??? ?返回指定列的所有值之和
avg()? :

 count(*):返回所有值
count(*):返回所有值

count():

min() :


max():
?
sum(x):

字符串函数:
concat(x,y)?? ??? ??? ?将提供的参数 x 和 y 拼接成一个字符串? ? 或者? ?字段1? || 字段2?


可以添加空格符:

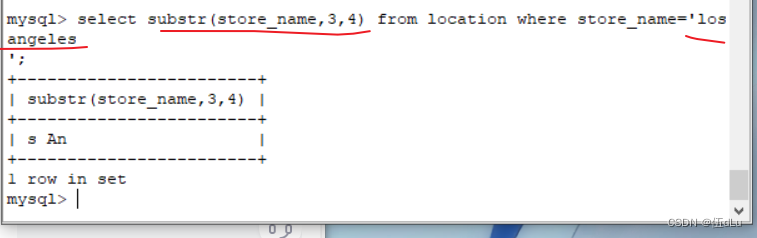
substr(x,y,z)?? ??? ?获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串
replace(x,y,z)?? ??? ?将字符串 z 替代字符串 x 中的字符串 y

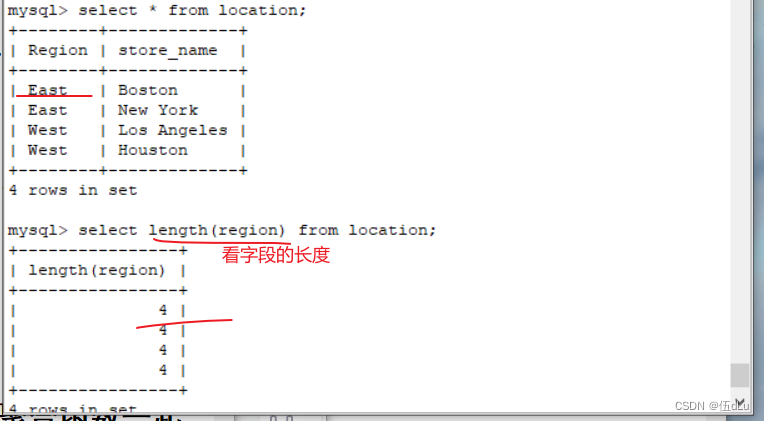
length(x)?? ??? ??? ?返回字符串 x 的长度
group by:对group by后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的
有一个原则,凡是在 group by后面出现的字段,必须在 selsect后面出现;
凡是在 select 后面出现的、且未在聚合函数中出现的字段,必须出现在 group by后面。

having:用来过滤由group by 语句返回的记录集,通常与group by语句联合使用
弥补了where关键字不能与聚合函数联合使用的不足。
having的作用:根据group by分组后的结果再进行条件过滤

别名:as字段別名 表格別名

子查询:连接表格,在where子句或 having子句中插入另一个 SQL 语句
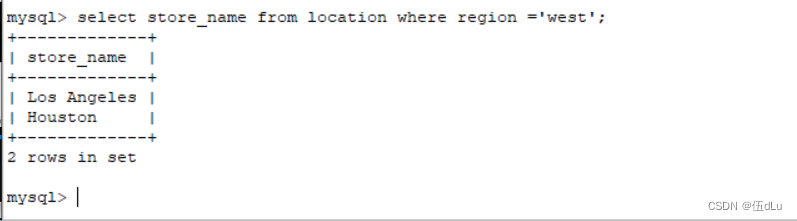

连接查询:
inner join ? ?内连接,只返回两个表的字段相等的行记录
left join ? ? 左连接,返回左表所有的行记录和右表字段相等的行记录,不相等的行返回null
right join ? ?右连接,返回右表所有的行记录和左表字段相等的行记录,不相等的行返回null
union ? ? ? ? 联集,将两个select查询语句的结果合并,并去重
union all ? ? 联集,将两个select查询语句的结果合并,不去重
full outer join ? 全外连接,返回左表和右表中所有的行记录,MySQL不支持
inner join:

left join:

right join:

union 去重:

union all? 不去重:

视图表:可以被当作是虚拟表或存储查询。
视图跟表格的不同是,表格中有实际储存数据记录,而视图是建立在表格之上的一个架构,它本身并不实际储存数据记录。
视图表的数据是否能修改?
视图表保存的是select查询语句的定义。如果select语句查询的字段是没有被处理过的源表字段,则可以通过视图表修改源表数据。
?如果select语句查询的字段被 group by 或 函数 等处理过的字段,则不可以直接修改视图表的数据。
create view ?视图表名 ?as ?select语句;


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 重磅上新!赛宁人员能力验证评估系统,高效解决人才培养和能力认证难
- 基于AES图像加解密算法的MATLAB仿真
- Unity查安卓Native Crash的方法,定位SO报错函数
- 使用Stm32CubeMX配合Stm32F334nucleo板-GPIO点亮LED
- 未来,自由恋爱很可能会式微、包办婚姻很可能会回归
- Docker端口映射
- 元编程(Metaprogramming)
- 壮志酬筹>业务被裁>副业转正>收入回正。一个前黑马程序员老师的2023
- 【MySQL表的操作】
- python进行简单的app自动化测试(pywinauto)+ 截屏微信二维码