Numpy、Pandas常用函数
目录
Numpy
官方文档:NumPy: the absolute basics for beginners — NumPy v1.26 Manual
NumPy(Numerical Python)是一个用于处理数值运算的 Python 库。它提供了一个高效的多维数组对象(ndarray),以及用于处理这些数组的各种函数。NumPy 是许多其他科学计算库的基础,因为它提供了快速、灵活的数据结构和数学运算功能。
核心功能
NumPy 的核心功能主要包括以下几个方面:
1. 多维数组对象(ndarray):NumPy 提供了一个强大的多维数组对象,即 ndarray。这个对象在内存中是一个连续的数据块,并且支持高效的数值运算和广播操作。通过 ndarray,您可以轻松地表示和操作多维数据。
2. 数组的创建和初始化:NumPy 提供了多种方式来创建和初始化 ndarray。您可以使用列表、元组、NumPy 提供的特殊函数(例如 `numpy.zeros()`、`numpy.ones()`)、随机数生成函数(例如 `numpy.random.rand()`)、从文件中读取数据等方式来创建数组。
3. 数组的索引和切片:与 Python 的列表索引和切片类似,NumPy 提供了丰富的索引和切片操作,可以访问和修改数组中的元素,也可以获取数组的子数组。可以使用整数索引、布尔索引、切片操作和花式索引等方式来访问和操作数组的元素。
4. 数学运算:NumPy 提供了丰富的数学函数和运算符,可以对数组进行各种数学运算,如加法、减法、乘法、除法、幂函数、三角函数、指数函数等。这些运算可以逐元素进行,也可以对整个数组或某个轴上的数据进行运算。
5. 广播机制:NumPy 的广播机制使得不同形状的数组之间可以进行算术运算,而不需要进行显式的形状匹配。广播机制可以降低代码的复杂性,并提高运算效率。
6. 数组的聚合和统计操作:NumPy 提供了丰富的统计函数,如计算平均值、方差、标准差、最小值、最大值、中位数等。这些函数可以应用于整个数组或某个轴上的数据。
7. 线性代数运算:NumPy 提供了线性代数运算的功能,如矩阵乘法、矩阵求逆、特征值分解、奇异值分解等。这些功能在科学计算和机器学习中经常被使用。
8. 文件操作:NumPy 可以将数组以二进制或文本形式保存到文件中,并可以从文件中读取数组数据。这样可以方便地进行数据的持久化和共享。
常用函数
| np.array() | 函数从列表或元组创建数组 |
| np.linspace() | 创建一个具有指定间隔的浮点数的数组 |
| np.arange() | 在给定的间隔内返回具有一定步长的整数 |
| np.uniform() | 在上下限之间的均匀分布中生成随机样本 |
| np.random.randint() | 在一个范围内生成n个随机整数样本 |
| np.random.random() | 生成n个随机浮点数样本 |
| np.logspace() | 在对数尺度上生成间隔均匀的数字 |
| np.zeroes() | 创建一个全部为0的数组 |
| np.ones() | 创建一个全部为1的数组 |
| np.full() | 创建一个单独值的n维数组 |
| np.identity() | 创建具有指定维度的单位矩阵 |
| np.unique() | 返回一个所有唯一元素排序的数组 |
| np.mean() | 返回数组的算数平均数 |
| np.average() | 返回数组的加权平均数 |
| np.medain() | 返回数组的中位数 |
| np.digitize() | 返回输入数组中每个值所属的容器的索引 |
| np.reshape() | 返回一个数组,其中包含具有新形状的相同数据 |
| np.expand_dims() | 扩展数组的维度 |
| np.squeeze() | 通过移除一个单一维度来降低数组的维度 |
| np.argwhere() | 查找并返回非零元素的所有下标 |
| np.count_nonzero() | 计算所有非零元素并返回它们的计数 |
| np.argmax()? | argmax返回数组中Max元素的索引。它可以用于多类图像分类问题中获得高概率预测标签的指标 |
| np.sort() | 对数组排序 |
| np.abs() | 返回数组中元素的绝对值。当数组中包含负数时它很有用 |
| np.round() | 将浮点值四舍五入到指定数目的小数点 |
| np.clip() | 将数组的裁剪值保持在一个范围内 |
| np.where() | 返回满足条件的数组元素 |
| np.put() | 用给定的值替换数组中指定的元素 |
| np.copyto() | 将一个数组的内容复制到另一个数组中 |
| np.intersect1d() | 函数以排序的方式返回两个数组中所有唯一的值 |
| np.setdiff1d() | 查找不同元素,返回arr中在arr2中不存在的所有唯一元素 |
| np.setxor1d() | 从两个数组中提取唯一元素,按顺序返回两个数组中所有唯一的值 |
| np.union1d() | 将两个数组合并为一个 |
| np.hsplit() | 将数据水平分割为n个相等的部 |
| np.vsplit() | 将数据垂直分割为n个相等的部分 |
| np.hstack() | 水平叠加将在另一个数组的末尾追加一个数组 |
| np.vstack() | 垂直叠加将一个数组堆叠在另一个数组上 |
| np.allclose() | 根据公差值查找两个数组是否相等或近似相等 |
| np.equal() | 比较两个数组的每个元素,如果元素匹配就返回True |
| np.repeat() | 用于重复数组中的元素n次 |
| np.einsum() | 用于计算数组上的多维和线性代数运算 |
| np.histogram() | 计算一组数据的直方图值 |
| np.percentile() | 沿指定轴计算数据的Q-T-T百分位数 |
| np.std() | 用于计算沿轴的标准偏差 |
| np.var() | 用于计算沿轴的方差 |
| np.searchsorted() | 查询并返回可插入位置数组 |
| np.insert() | 将待插入元素数组中的元素,按照位置数组中的位置,插入到目标数组中,返回结果数组 |
运算实例

Pandas
官方文档:User Guide — pandas 2.1.4 documentation
- Pandas是一个开源的Python库,提供高性能、易用的数据结构和数据操作工具,用于数据处理和分析。它是构建在NumPy之上的一个扩展,为处理结构化数据(如表格数据)提供了更便捷的方法。
- 主要的两个数据结构是Series和DataFrame。Series是一维带标签的数组,类似于表格中的一列数据,可以存储不同类型的数据。DataFrame是一个二维的表格数据结构,由多个Series组成,每个Series代表一列数据,可以看作是一个带标签的表格。
- Pandas提供了许多功能强大的方法,用于数据的清洗和预处理。你可以使用Pandas读取和写入各种数据格式的数据,如CSV、Excel、SQL数据库等。它还提供了一些数据清洗的功能,如去重、处理缺失值、替换数据等。
- Pandas也支持数据的索引和切片,你可以通过标签或位置来选择数据。此外,Pandas还支持数据的分组和聚合操作,可以根据某些条件对数据进行分组,并对每个组进行统计或计算。
- 对于多个DataFrame的情况,Pandas提供了合并和拼接的方法,可以按照特定的键将数据进行合并和拼接。这对于数据集成和关联分析非常有用。
- 另外,Pandas也提供了对时间序列数据的支持,可以方便地进行时间序列的分析和处理,如日期范围生成、时间频率转换、移动窗口统计等。
- 最后,Pandas还可以与其他数据分析和可视化库(如Matplotlib、Seaborn)结合使用,方便进行数据可视化和探索性分析。
核心功能
Pandas 是一个在 Python 中处理和分析数据的强大库,它提供了高性能、易用的数据结构和数据操作工具。Pandas 的核心功能主要包括以下几个方面:
1. 数据结构:Pandas 提供了两种主要的数据结构,即 Series 和 DataFrame。
? ?- Series 是一维标记数组,类似于带有索引的一维数组。它可以容纳任意数据类型的数据,并提供了对其数据的快速访问和操作。
? ?- DataFrame 是二维表格数据结构,类似于关系型数据库中的表或 Excel 中的表格。它由多个具有相同索引的列组成,每个列可以是不同的数据类型。DataFrame 提供了灵活的数据操作和处理方法,适用于各种数据分析任务。
2. 数据的读取和写入:Pandas 能够读取和写入多种数据格式的数据,如 CSV、Excel、SQL 数据库、JSON、HDF5 等。通过 Pandas 的读取和写入函数,您可以方便地将外部数据加载到 DataFrame 中进行分析,或将分析结果写入外部文件。
3. 数据的清洗和预处理:Pandas 提供了丰富的数据清洗和预处理功能,例如数据过滤、缺失值处理、重复值处理、数据格式转换、数据排序等。这些功能可帮助您对数据进行处理,使其适合进行进一步的分析和建模。
4. 数据的索引和切片:Pandas 提供了强大的索引和切片功能,使您可以从数据中选择和提取所需的部分。您可以使用标签索引、整数索引、布尔索引等方式选择行和列,还可以使用切片操作和条件筛选进行灵活的数据选择和过滤。
5. 数据的分组和聚合:Pandas 可以对数据进行分组和聚合操作,以便进行统计和汇总分析。您可以根据某个列或多个列对数据进行分组,然后对每个分组应用聚合功能(如求和、计数、平均值等)。
6. 数据的合并和拼接:Pandas 提供了多种方式来合并和拼接数据,如连接操作、合并操作和拼接操作。这些操作可以将多个 DataFrame 或 Series 中的数据进行合并,以便进行更全面的分析和处理。
7. 时间序列分析:Pandas 对处理时间序列数据提供了丰富的支持。它提供了强大的日期和时间功能,能够处理时间索引、时间序列重采样、滑动窗口计算等时间相关的任务。
8. 数据可视化:Pandas 结合了 Matplotlib 库,可以方便地进行数据可视化。它提供了简单易用的绘图接口,可以绘制各种类型的图表,如线图、散点图、柱状图、箱线图等,帮助您更直观地理解和展示数据。
常用函数
| pd.read_csv() | 读取CSV文件并将其转换为pandas DataFrame |
| .describe() | 生成DataFrame的各种特征的汇总统计信息。它返回一个新的DataFrame,其中包含原始DataFrame中每个数值列的计数、平均值、标准差、最小值、第25百分位、中位数、第75百分位和最大值 |
| .info() | 获得DataFrame的简明摘要,包括每列中非空值的数量、每列的数据类型以及DataFrame的内存使用情况 |
| .iloc() | 用于根据索引选择行和列 |
| .loc() | 用于根据DataFrame中基于标签的索引选择行和列。它用于根据基于标签的位置选择行和列 |
| .assign() | 用于根据现有列的计算向DataFrame添加新列。它允许您在不修改原始数据的情况下添加新列。该函数会返回一个添加了列的新DataFrame |
| .query() | 根据布尔表达式过滤数据。可以使用类似于SQL的查询字符串从DataFrame中选择行。该函数返回一个新的DataFrame,其中只包含满足布尔表达式的行 |
| .sort_values() | 按一列或多列对数据进行排序。它根据一个或多个列的值按升序或降序对DataFrame进行排序。该函数返回一个按指定列排序的新DataFrame |
| .sample() | 从数据帧中随机选择行。它返回一个包含随机选择的行的新DataFrame。该函数采用几个参数,可以控制采样过程 |
| .isnull() | 返回一个与原始DataFrame形状相同的DataFrame,通过True或False值,指示原始DataFrame中的每个值是否缺失。缺失的值NaN或None,在结果的DataFrame中将为True,而非缺失的值将为False |
| .fillna() | 用于用指定的值或方法填充DataFrame中的缺失值。默认情况下,它用NaN替换缺失的值,也可以指定一个不同的值来代替 |
| .dropna() | 从DataFrame中删除缺失值或空值。它从DataFrame中删除至少缺失一个元素的行或列。可以通过调用df.dropna()删除包含至少一个缺失值的所有行 |
| .drop() | 通过指定的标签从DataFrame中删除行或列。它可以用于删除一个或多个基于标签的行或列。 你可以通过调用df.drop()来删除特定的行,并传递想要删除的行的索引标签,并将axis参数设置为0(默认为0) |
| .pivot_table() | 从DataFrame创建数据透视表。透视表是一种以更有意义和更有组织的方式总结和聚合数据的表 |
| .groupby() | 用于根据一个或多个列对DataFrame的行进行分组。并且可以对组执行聚合操作,例如计算每个组中值的平均值、和或计数。返回一个GroupBy对象,然后可以使用该对象对组执行各种操作,例如计算每个组中值的和、平均值或计数 |
| .transpose() | 用于转置DataFrame的行和列,这意味着行变成列,列变成行 |
| .merge() | 根据一个或多个公共列组合两个dataframe |
| .rename() | 更改DataFrame中一个或多个列或行的名称。可以使用columns参数更改列名,使用index参数更改行名 |
| .to_csv() | 将DataFrame导出到CSV文件 |
统计汇总函数


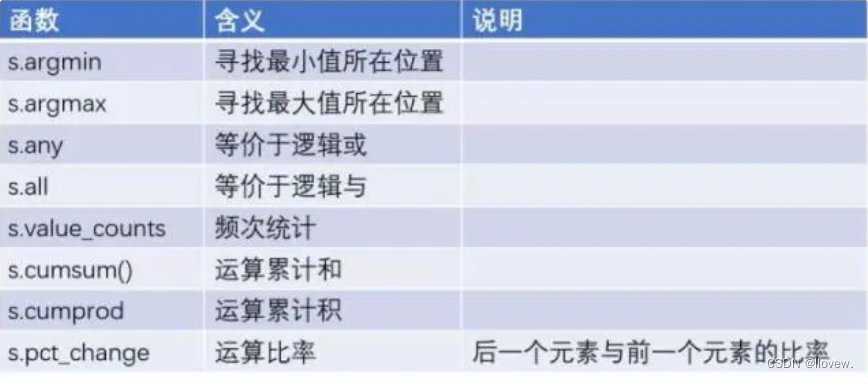
数据清洗函数


数据筛选

绘图与元素级函数
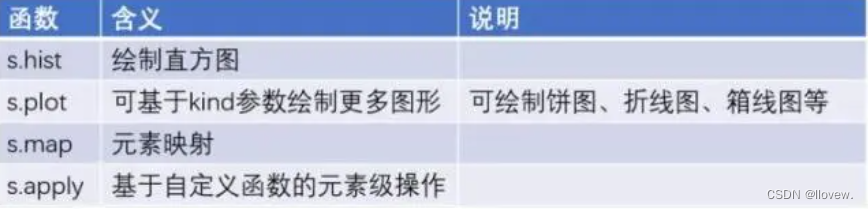
时间序列函数


其他函数

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Spring 篇】SpringMVC的数据响应:编织美妙的返回乐章
- Python爬虫之——学不会我去你家帮你爬系列
- 全视通以“物联数据中台+边缘信息化”,建设“三位一体”智慧医院
- 13个干货议题!拓数派携众多大咖共话国产数据库未来趋势
- 程序拓展与自定义的方法总结
- 复习python从入门到实践—— 用户输入与while循环
- vue 组件 import make sure to provide the “name“ option.
- Transformer从菜鸟到新手(六)
- 十款强大的企业电脑加密软件推荐(企业电脑加密软件哪个最好用)
- 校园超市进销存管理系统(JSP+java+springmvc+mysql+MyBatis)