【论文阅读笔记】Medical Vision Language Pretraining: A survey
arXiv:2312.06224Submitted 11 December, 2023; originally announced December 2023.
这篇综述文章很长,本文对各部分简要概述。
【文章整体概述】
医学视觉语言预训练(VLP)最近已经成为解决医学领域标记数据稀缺问题的一种有希望的解决方案。通过利用成对或非成对的视觉和文本数据集进行自监督学习,模型能够获得大量知识并学习强大的特征表示。这样的预训练模型有潜力同时提升多个下游医学任务,减少对标记数据的依赖。然而,尽管近期取得了进展并显示出潜力,目前还没有一篇综述文章全面探讨了医学VLP的各个方面和进展。在本文中,特别审视了现有工作,通过不同的预训练目标、架构、下游评估任务和用于预训练及下游任务的数据集的视角。随后,深入探讨了医学VLP中的当前挑战,讨论了现有和潜在的解决方案,并以展望未来的发展方向作为结论。这是第一篇专注于医学VLP的综述。

【IV.MULTIMODAL LEARNING APPROACHES】
在第四部分“多模态学习方法”中,本文探讨了多模态学习在医学领域的应用,尤其是监督和自监督学习方法的使用。
A. 监督多模态学习: 这一部分讨论了监督多模态学习,其中需要依赖于真实标签(ground truth labels)来学习预测模型。监督学习在医学领域面临着由于需要大量标注数据而引发的挑战,这一挑战由专业领域专家对医学数据进行注释的需求和隐私问题的日益增长进一步加剧。
B. 自监督多模态学习: 自监督学习分为预训练和下游任务学习两个阶段。在预训练阶段,自监督方法不依赖于真实标签,而是使用数据中的其他形式的自生成的监督作为目标函数来训练预测模型。这种方法通过替换监督目标中的真实标签为伪标签来实现。预训练后,训练好的模型用于学习使用真实标签的特定下游任务。自监督预训练步骤减少了对标注数据的依赖,并在某些情景下显示出优于全监督模型的性能。在医学领域,获取标注数据是一个重大障碍,自监督学习显示出高效性。尽管缺乏注释标签,医学数据集通常包含图像和详细的文本报告,为自监督预训练提供了宝贵的资源。
总体而言,这一部分强调了在医学领域中多模态学习的重要性,特别是自监督学习在利用大规模医学图像和文本数据中的潜力。
【V. MEDICAL VLP OBJECTIVE FUNCTIONS】
在第五部分“医学VLP目标函数”中,各种目标函数的常用模型和方法被详细讨论,图画得很好,这里总结一下它们的优缺点:
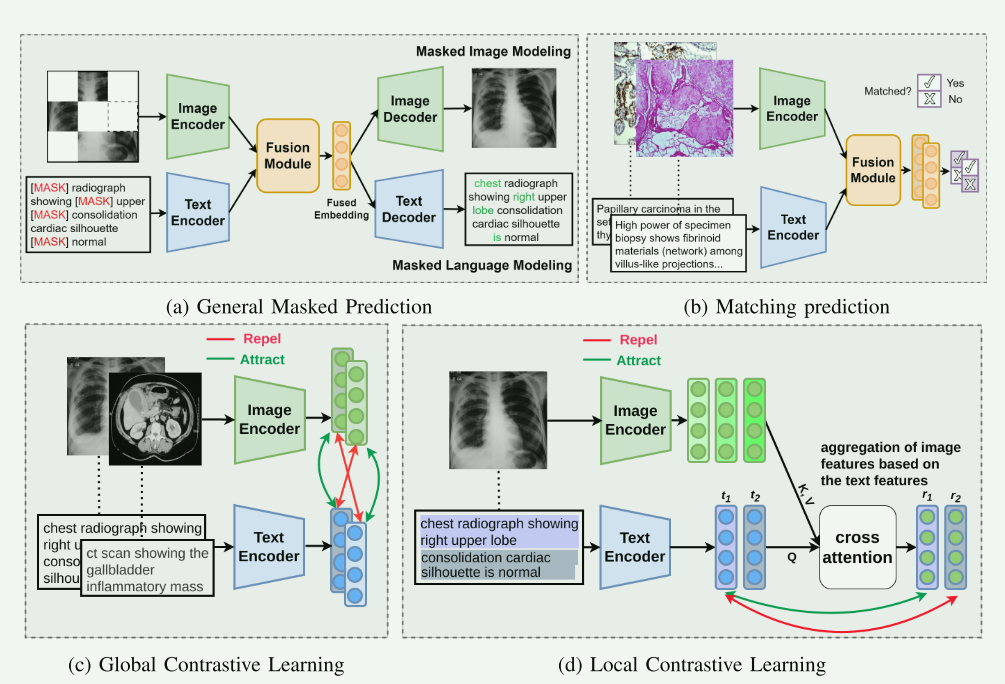
A. 掩码预测:
-
常用模型:这种方法常用于BERT-like的模型,其中模型被训练来预测在文本或图像中被随机掩盖的部分。Masked Prediction的常用任务如:Masked Language Modeling (MLM)、Masked Image Modeling (MIM)。代表模型:MMBERT
-
优点
- 上下文理解:掩码预测方法强迫模型关注上下文信息来预测被掩盖的部分。这种方法特别适合于学习深层次的上下文依赖关系,从而增强模型的理解能力
- 深度特征学习:通过预测掩码部分,模型能够学习到数据的深层特征和细节。这对于理解复杂的医学图像和报告中的微妙差异尤其有用
- 鲁棒性:掩码预测方法提高了模型对不完整或缺失信息的处理能力,从而提升了模型在现实世界应用中的鲁棒性。
- 强大的语言模型:在文本处理方面,掩码预测类似于BERT架构,已被证明在多种自然语言处理任务中非常有效。
-
缺点
? 1.侧重单一模态:掩码预测方法可能过分侧重于在单一模态(如文本或图像)内的特征学习,而不是跨模态(即图像和文本之间)的特征关联。
- 计算开销:这种方法可能需要较大的计算资源,特别是在处理大型医学数据集时,因为需要生成和处理大量的掩码变体。
- 局限性于特定上下文:虽然这种方法在学习上下文信息方面非常有效,但它可能不适用于需要全局理解或跨多个上下文的任务。
- 预训练与下游任务不一致:在预训练和下游阶段之间会出现轻微的域间隙,预训练阶段需要屏蔽输入,而下游任务涉及未屏蔽输入。因此,仅依赖于掩蔽预测目标的方法缺乏下游zero-shot能力。
B. 对比学习:
-
常用模型:使用诸如Siamese网络架构的模型,这些模型通过比较正负样本对来学习区分特征。代表模型ConVIRT、PubMedCLIP、BiomedCLIP、IMITATE、GLORIA、LIMITR、LRCLR、LOVT、MedCLIP、KoBo
-
优点
- 区分能力:对比学习通过区分正负样本对,强化了模型的区分能力。这对于理解和区分医学图像和文本中的细微差异尤其有价值。
- 有效的特征提取:这种方法有效于提取和学习有区分性的特征,这在大规模未标注的医学数据集中尤为重要。
- 鲁棒性和泛化能力:对比学习增强了模型对于不同样本的泛化能力,并提高了在面对新数据时的鲁棒性。
- 适应性强:对比学习方法通常适用于各种不同类型的数据,包括多种不同的医学图像和文本数据。
-
缺点
- 负样本选择的挑战:正确选择负样本对于对比学习至关重要。如果负样本选择不当,可能会降低学习效率或导致错误的特征学习。
- 计算开销:大规模数据集上的对比学习可能需要显著的计算资源,特别是在涉及复杂医学数据时。
- 平衡正负样本:在对比学习中平衡正负样本比例是一个挑战,不平衡可能会导致模型偏差或不稳定。
- 样本多样性:维持足够样本多样性的同时执行有效的对比学习是一个挑战,特别是在医学领域中,其中类别可能高度不平衡。
- 局限于实例级学习:对比学习通常关注于实例级的特征学习,可能无法充分捕获更高层次的抽象或跨模态关系。
C. 匹配预测:
- 常用模型:通常使用具有二元分类头的网络,这些网络评估视觉和文本输入是否匹配。两类基本任务:
- Image-Text Matching (ITM) 和Image-Report Matching (IRM)。
- 优点:它有助于直接学习跨模态之间的关联性,对于需要精确匹配的应用场景特别有用。
- 缺点:可能对模型结构和训练过程有更高的要求,因为需要有效地处理和融合来自不同模态的信息。
D. 混合目标:
-
常用模型:这些方法通常结合多种技术,例如Masking + Contrastive的模型,代表模型:PMC-CLIP、PRIOR、BioViL;Masking + Matching prediction:UWOX、MedViLL、M3AE、ARL;Mixed Objectives:MUMC、
-
优点:通过结合多种方法,可以在模型中实现更全面的特征学习,从而提高模型的泛化能力和性能。
-
缺点:
1.这种方法可能会导致模型和训练过程变得复杂,需要精心设计以确保不同目标的有效结合。
2.在视觉模态上应用掩蔽预测时,医学图像中的局部视觉线索往往被掩蔽。掩蔽的医学图像可能是模糊的,并且不再与所附文本完美对齐。因此,将对比学习直接应用于屏蔽输入可能会由于未对准而提供次优解。
【VI. MEDICAL VLP RELATED ADDITIONAL ASPECTS】
在第六部分“医学VLP相关附加方面”中,文档讨论了几个重要的额外方面:
-
A.使用未配对数据进行预训练:
自监督学习的有效性与可用的预训练数据量直接相关。为了克服医学配对图像文本报告的有限大小,许多论文提出了在预训练期间利用未配对数据集的方法。将只有图像或只有文本的数据集(带有或不带有其他附带注释)称为未配对数据集。
-
B.在预训练期间使用时间信息:
与典型的自然语言文本不同,临床报告经常引用过去的历史,提供时间背景。因此一些模型建议使用先前的图像和报告(如果可用)来利用VLP医疗数据集中存在的时间监督。
-
C.胸部X线多视图的使用:
在临床实践中,临床医生通常依赖于来自放射学扫描的多个视图的见解来进行准确的评估。不同的视觉提示往往在不同的视图上更明显,并且利用这些不同的视角(如果可用)可以增强学习的表示,并证明在下游评估任务中是有益的。
-
D.其他视觉模态
多数论文都是2D的,2D+3D或者几种不同的医学检查数据结合是值得研究的方向。
【VII. DATA AUGMENTATION】
数据增强是医学VLP的一个组成部分,因为它有助于提高模型对不同数据的鲁棒性、泛化性和性能。由于医学领域的数据数量特别有限,因此增强可以极大地帮助增加数据集的大小和可变性。在本节中,简要介绍了医学VLP中常用的增强技术。
- A.图像增强
- 空间变换:如随机裁剪、旋转、翻转和仿射变换。这些方法有助于模型学习从不同角度和尺度理解图像。
- 颜色调整:包括色彩抖动、随机灰度变换等,以增强模型对颜色和光照变化的鲁棒性。
- 注意事项:在进行图像增强时,需要注意图像内容与其对应的文本描述之间的一致性。例如,水平翻转可能会导致图像中的解剖结构与文本描述不匹配。
- B.文本扩充
- 句子混洗:将报告中的句子随机打乱,这基于医学报告中信息通常具有排列不变性的假设。
- 句子采样:从多句话的报告中随机选择一句作为整个文本的代表,这有助于模型聚焦于关键信息。
- 回译:利用机器翻译模型将原始文本翻译成另一种语言,然后再翻译回来,以引入文本的变化
- 相似报告搜索:使用类似De-CLIP框架的方法,通过最近邻搜索找到相似的报告作为文本增强。
【VIII. ARCHITECTURE】
- A. Encoder Architecture
编码器架构是医学VLP的核心组件之一,负责处理图像和文本数据。本文讨论了两种主要类型的编码器:
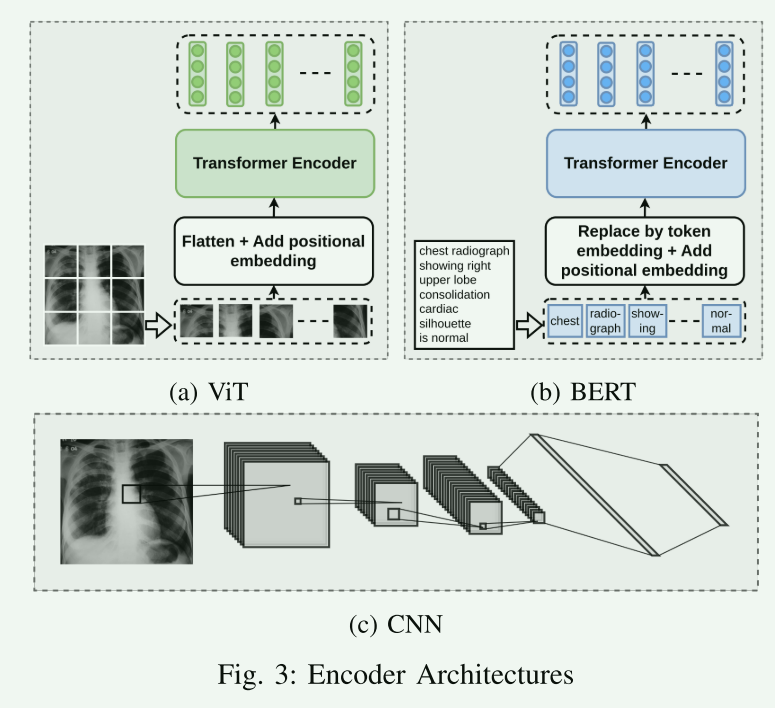
- 图像编码器:
- 使用CNN和ViT(Vision Transformer)架构处理视觉输入。
- CNN通过卷积和池化操作处理图像,例如常用的ResNet50模型。
- ViT将图像分解成非重叠的图像块,使用自注意力层处理这些图像块。
- 根据模型的不同,有的方法使用自然领域预训练的权重(如ImageNet或CLIP),而另一些则在医学数据上进行特定领域的预训练。
- 文本编码器:
- 所有涉及的方法均使用基于Transformer的文本编码器。
- 类似于ViT,Transformer文本编码器将输入文本分解为较小的文本单元或标记,并使用多层自注意力进行处理。
- 大多数方法采用BERT架构,并从公共可用的BERT权重(预训练于临床文本)初始化。
- B. Modality Fusion
模态融合是VLP中的另一个关键方面,涉及将图像和文本的编码信息结合起来。本文讨论了三种主要的模态融合方法:
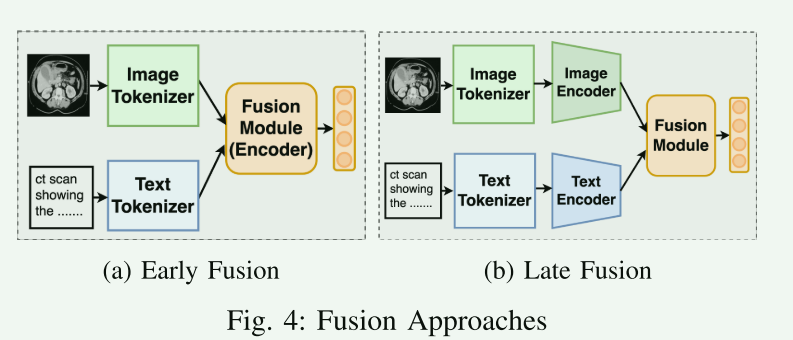
- 无融合:
- 某些方法不直接融合不同模态,而是通过对比目标对它们进行间接对齐。
- 早期融合:
- 早期融合涉及使用共同的编码器模块来组合两种模态。
- 例如,某些方法使用CNN模块生成图像标记,然后将这些标记与文本标记一起通过统一的Transformer编码器传递。
- 晚期融合:
- 晚期融合在使用独立的编码器处理不同模态之后进行。
- 常用的融合模块包括基于注意力的融合模块,由于它们在处理长特征序列和实现有效的多模态交互方面特别有效。
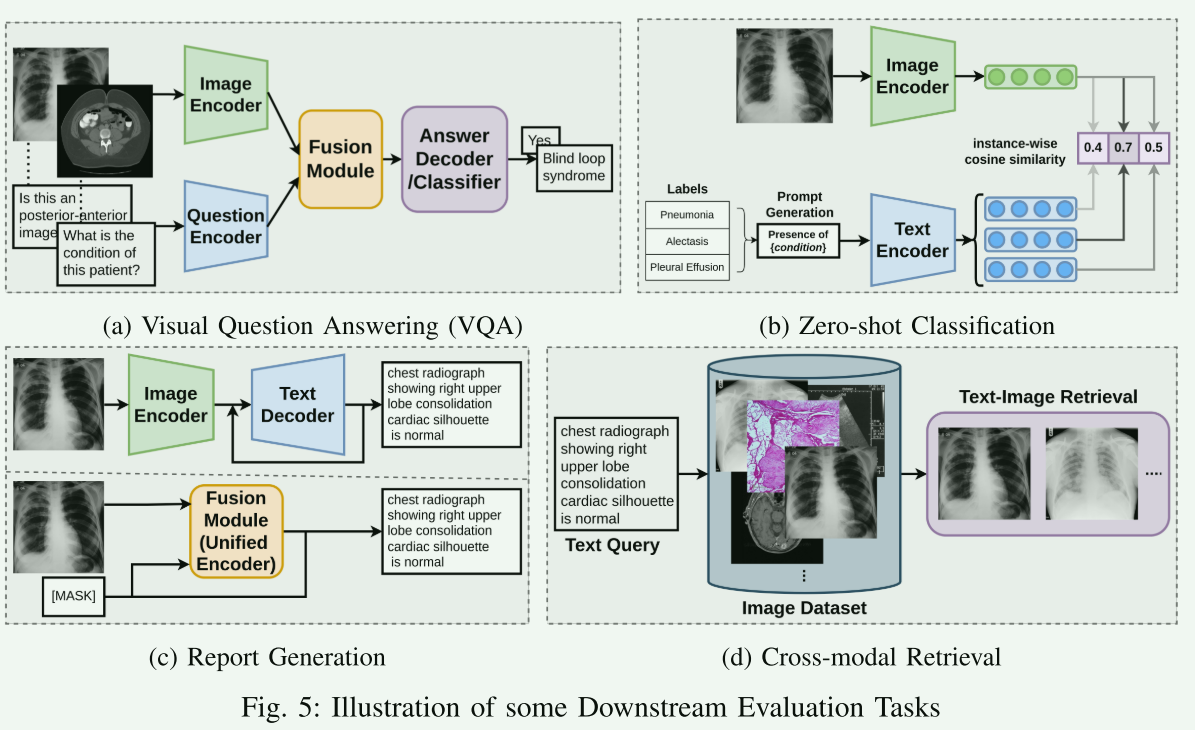
【IX. DOWNSTREAM EVALUATION TASKS】
在论文的第九部分,详细讨论了医学视觉语言预训练(VLP)模型在多种医学图像处理和分析任务中的应用。
-
A. Medical Image Classification
探讨了医学图像分类任务,并特别关注了三种不同的方法:零样本分类(提示法)、线性探测和微调:
-
零样本分类 (提示法)
-
核心概念:零样本分类不需要对模型进行特定任务的训练,而是直接利用预训练模型的泛化能力来进行分类。
-
实施方法:通过构造提示(prompt)将分类任务转化为模型可以理解的形式。例如,将医学图像分类任务转化为一种模型在预训练过程中已学习的任务。
-
优势:能够在没有额外训练数据的情况下利用预训练模型,节省训练时间和资源。
-
局限性:性能依赖于预训练模型的泛化能力和提示的有效构造。
-
-
线性探测
-
核心概念:在预训练模型的基础上添加一个简单的线性分类器。
-
实施方法:保持预训练模型的权重固定,仅训练添加的线性分类层。
-
优势:相比于完全微调,计算成本较低,可以快速评估预训练模型的特征提取能力。
-
局限性:性能可能不及完全微调,尤其是在预训练模型和目标任务之间存在较大差异时。
-
-
微调
-
核心概念:对整个预训练模型进行微调,以适应特定的分类任务。
-
实施方法:在特定任务的数据集上继续训练整个模型,以调整其权重。
-
优势:通过微调,模型能够更好地适应特定任务,通常可以达到更高的性能。
-
局限性:需要较多的训练数据和计算资源,也可能面临过拟合的风险。
-
-
-
B. Medical Image Segmentation
讨论了医学图像分割任务,特别是两种主要方法:零样本分割和微调分割。
-
零样本分割
-
核心概念:零样本分割指的是在没有针对特定分割任务进行训练的情况下,直接使用预训练模型来进行图像分割。
-
实施方法:利用预训练模型的泛化能力,通常通过将分割任务转化为模型可以处理的形式,如利用模型在预训练过程中学到的特征。
-
优势:无需额外训练数据,可以节省显著的时间和资源。适用于资源受限或需要快速原型开发的场景。
-
局限性:分割精度和性能通常低于专门针对特定任务训练的模型。依赖于预训练模型的质量和泛化能力。
-
-
微调分割
-
核心概念:微调分割涉及在特定的图像分割任务上继续训练预训练的模型,以更好地适应该任务。
-
实施方法:在分割任务的数据集上对预训练模型进行进一步的训练,通常包括对模型的所有或部分层进行微调。
-
优势:通过针对特定任务的微调,模型能够更准确地识别和分割图像中的特定结构或区域,通常能达到更高的性能。
-
局限性:需要相对较多的标注数据和计算资源。微调过程中可能存在过拟合的风险,特别是在数据量较小的情况下。
-
-
-
C. Medical Object Detection
- 评估方法:使用平均精度(mAP)等指标进行评估。
- 训练方法:通常将VLP模型与目标检测头结合,进行整体或部分微调
-
D. Cross-modal Retrieval
- 任务描述:基于一个模态的查询检索另一个模态的相关信息,如根据文本描述检索相应的医学图像。
- 评估方法:使用召回率(Recall@n)和精确度(Precision@n)进行评估。
- 训练方法:可以直接应用经过对比学习预训练的模型进行零样本检索,或对模型进行特定任务的微调。
-
E. Medical Report Generation
探讨了医学报告生成任务在医学视觉语言预训练(VLP)领域的应用
-
零样本生成:
-
核心概念:零样本生成指的是在没有专门为报告生成任务进行额外训练的情况下,使用预训练模型直接生成医学报告。
-
实施方法:这种方法依赖于预训练模型的泛化能力和语言模型的质量,通常通过特定的提示或查询来引导模型生成相关报告。
-
优势:不需要针对特定任务的训练数据,可以快速部署,节省资源。
-
局限性:生成的报告可能不够精确或详细,特别是在处理复杂的医学案例时。
-
-
微调生成:
-
核心概念:微调生成方法涉及在特定的医学报告生成任务上对预训练模型进行进一步训练,以更好地适应该任务。
-
实施方法:通常在特定的医学图像和对应报告的数据集上进行微调,使模型学习如何结合图像特征和临床知识来生成报告。
-
优势:可以生成更准确、更具针对性的医学报告,特别是当训练数据充分覆盖相关医学条件时。
-
局限性:需要大量标注的训练数据和更多的计算资源。可能存在过拟合的风险,尤其是在数据有限的情况下。
-
-
-
F. Medical Visual Question Answering
-
任务描述:根据给定的医学图像和自然语言问题生成正确的答案。
-
评估方法:使用分类准确度和自然语言生成指标进行评估。
-
训练方法:VLP模型通常用于编码图像和问题,然后结合模型生成或选择答案。
-
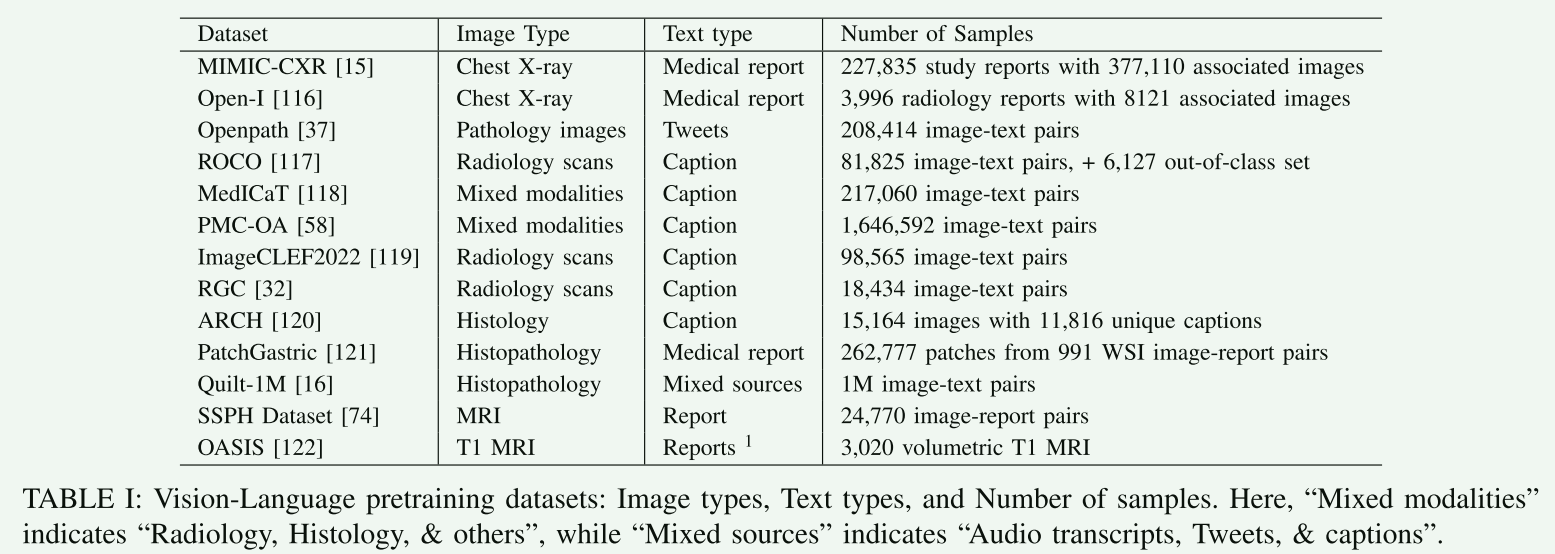
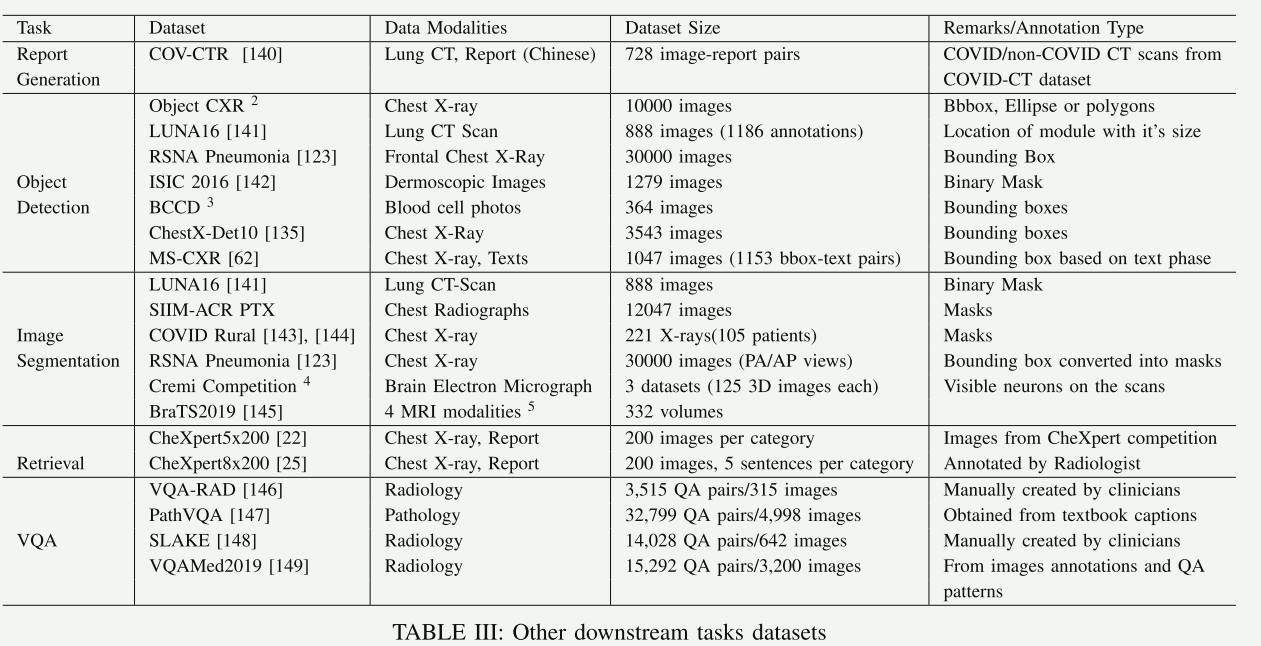
【X. DATASETS】
详细讨论了在医学视觉语言预训练(VLP)研究中使用的关键数据集。
- A. 预训练数据集
预训练数据集是用于训练医学VLP模型的基础,包括大量医学图像和对应的文本数据。一些主要的预训练数据集包括:
- MIMIC-CXR:一个广泛使用的公开数据库,包含胸部X光图像及其相关的临床报告。
- ROCO(Radiology Objects in Context):包含多种医学图像模态,例如放射学和病理学图像,及其来自开放获取文章的图像说明。
- MediCaT:提供多样化的医学图像和相关说明文本,包括图像标题和详细描述。
- Openpath 和 Quilt-1M:这些较新的数据集从Twitter和YouTube等互联网源中收集医学图像和文本,增加了数据多样性。
- SSPH 和 OASIS:用于在成对的3D MRI扫描和报告上预训练模型。
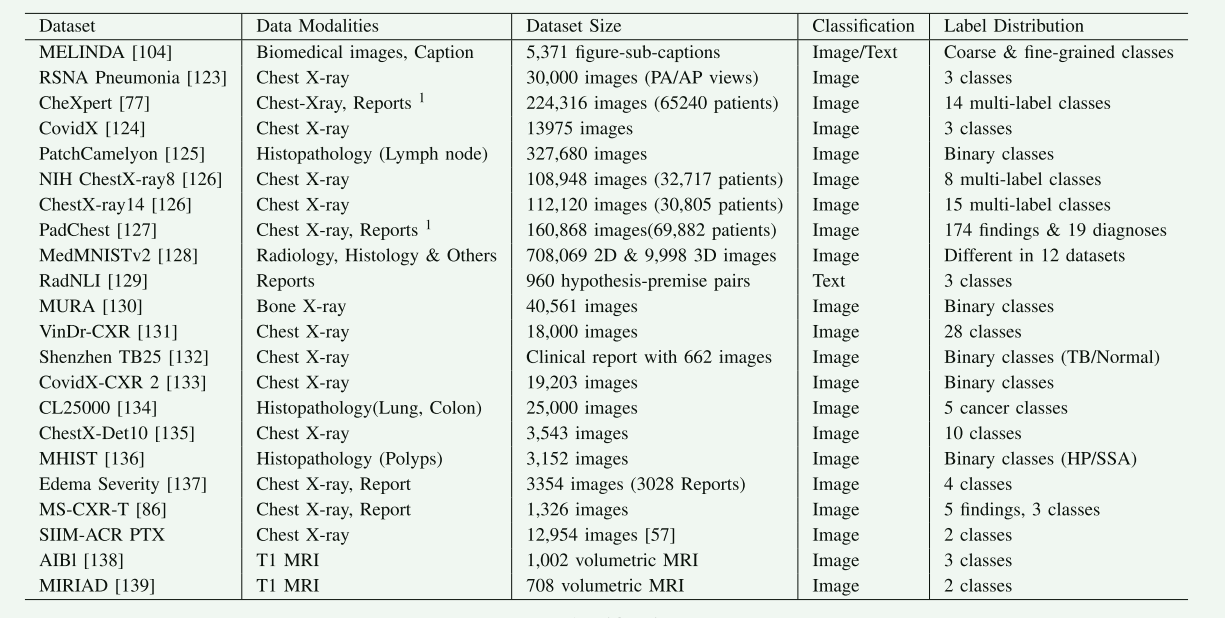
- B. 下游任务数据集
下游任务数据集用于评估医学VLP模型在特定医学任务上的表现。这些任务包括图像分类、分割、对象检测等。一些主要的下游任务数据集包括:
- RSNA Pneumonia、CheXpert 和 CheX-ray8 (NIH X-ray):这些数据集主要用于胸部X光图像的分类任务。
- MELINDA:提供生物医学图像和标题对,适用于图像、文本及多模态评估。
- MedMNIST:包含多种2D和3D医学图像,涵盖放射学、病理学等多个领域。
- VQA-RAD、PathVQA、SLAKE 和 VQAMed2019:这些数据集用于医学视觉问答任务。
【XI. LIMITATION AND CHALLENGES IN MEDICAL VLP】
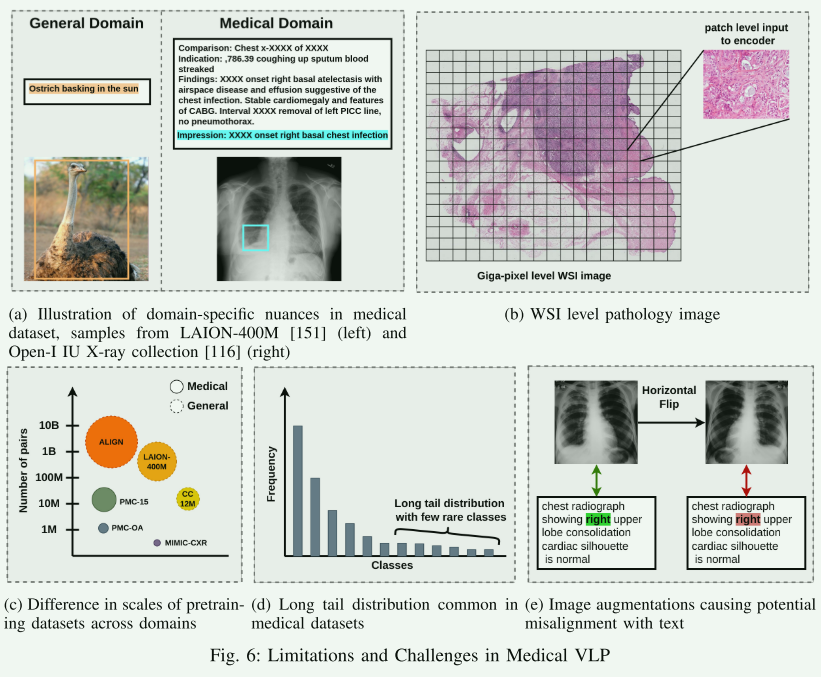
详细探讨了医学视觉语言预训练(VLP)领域的主要限制和挑战。以下是从六个关键方面的详细总结:
A. 预训练数据的大小和覆盖范围
- 数据量不足:医学领域的数据量通常不如其他领域丰富,特别是高质量和标注数据。
- 数据覆盖不全:现有数据集可能无法充分覆盖所有医学子领域,特别是罕见病例和特定种族或年龄组。
B. 医学领域的特殊性
- 专业性:医学数据具有高度专业性,要求模型能够理解复杂的医学术语和概念。
- 临床相关性:模型需要能够理解和处理临床相关的信息,这需要深入的医学知识。
C. 数据增强
- 增强技术的限制:在医学图像和文本数据上应用数据增强技术时需要特别小心,以免引入不准确或误导性的信息。
- 一致性问题:保持图像增强后的数据与其相应的文本描述之间的一致性是一个挑战。
D. 类别不平衡
- 罕见疾病:某些疾病在数据集中的表示可能非常少,导致模型难以学习这些类别的特征。
- 样本不足:类别不平衡可能导致模型偏向于更常见的疾病,影响其总体性能。
E. 计算病理学的挑战
- 高维数据:医学图像(特别是病理图像)通常是高维的,处理这些大规模数据集需要显著的计算资源。
- 细节识别:精确识别和解释病理图像中的微观结构是一个技术挑战。
F. 多成像模式
- 多模式数据整合:在一个研究中可能会使用多种成像模式,如CT、MRI等,整合这些多模式数据是一个挑战。
- 跨模态学习:需要发展有效的跨模态学习策略,以利用不同成像技术提供的互补信息。
【XII. PERSPECTIVES AND FUTURE DIRECTIONS】
提出了对医学视觉语言预训练(VLP)未来发展的展望和方向。以下是对这一部分的详细总结:
- 多模态学习的加强
- 强调跨模态融合:未来的医学VLP研究将更加重视跨模态数据的有效融合,以更全面地利用图像和文本信息。
- 改进模态融合技术:探索更先进的模态融合技术来处理复杂的医学数据。
- 自监督学习的发展
- 利用未标注数据:在医学领域,大量未标注数据的存在为自监督学习提供了丰富资源。未来的研究将更多地依赖这种学习方式来提高模型性能。
- 自监督学习策略的创新:探索新的自监督学习策略,以更好地利用医学数据的特性。
- 精细化和个性化的医学应用
- 个性化诊断和治疗:VLP模型未来可能会更加专注于支持个性化的医学诊断和治疗决策。
- 精细化的医学分析:提高模型在特定病理学和临床情况下的分析能力。
- 超越图像和文本的融合
- 整合其他医学数据:未来的医学VLP模型可能会融合图像和文本之外的其他类型数据,如基因数据、实验室结果和患者电子健康记录。
- 模型的解释性和可信度
- 提高模型透明度:在医学领域,模型的解释性和可信度极为重要。未来的研究需要着重于提高模型决策过程的透明度。
- 发展解释性方法:探索新的方法来解释和验证模型的输出,提高医生和患者对AI决策的信任。
- 临床实践中的集成和评估
- 实际临床应用:将医学VLP技术更好地集成到临床工作流程中,以实现其实际应用。
- 综合性能评估:开发综合性评估模型性能的方法,包括临床效用、可用性和对不同患者群体的适应性。
- 法律和伦理考量
- 关注数据使用和隐私:在发展医学VLP模型时,需遵循相关的法律和伦理标准,尤其是在处理敏感的医疗数据时。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 亚马逊撸货、撸卡怎么做成功率更高?教你解决亚马逊撸货的底层环境
- 探索义乌购API接口:引领全球小商品交易新篇章,赋能商家无限可能
- 深入理解Linux中的动态库与静态库
- windows下redis使用教程
- 硅麦的灵敏度
- python作业题百度网盘,python作业答案怎么查
- itk和sitk的一些应用整理
- Effective oc 2.0 第二章学习--对象、消息、运行期
- 天翼云挂对象存储到liunx系统,象操作liunx系统文件一样
- Spring Boot 和 Spring 有什么区别