[优雅的面试]MySQL与Redis双写一致性方案
前言
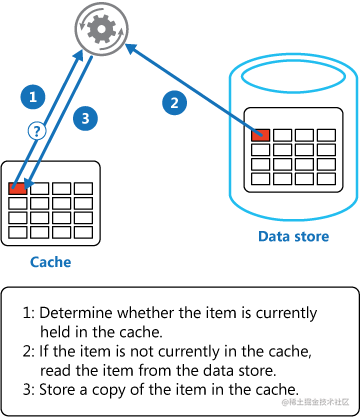
由于缓存的高并发和高性能已经在各种项目中被广泛使用,在读取缓存这方面基本都是一致的,大概都是按照下图的流程进行操作:

但是在更新缓存方面,是更新完数据库再更新缓存还是直接删除缓存呢?又或者是先删除缓存再更新数据库?在这一点上就值得探讨了。
一致性方案
在实际项目开发中需要保证数据库和缓存中的数据一致,否则人家充值了100块,不断刷新却还是显示0.01元,岂不是尴尬?从理论上来说,为缓存设置过期时间是最终保证数据一致性的解决方案,采用这种方案的话,所有的写操作都是以数据库为准,如果数据库写入成功但是缓存更新失败,只要缓存到过期时间之后后面读缓存时自然会在数据库中读取新的值然后更新缓存。接下来探讨的思路主要的方向是在不依赖为缓存设置过期时间的前提下如何保证数据一致性。这里主要探讨三种方案:
①先更新数据库,再更新缓存
②先删除缓存,再更新数据库
③先更新数据库,再删除缓存
先更新数据库再更新缓存
这种方案是普遍被反对的(在我的认知范围中~),为啥呢?为啥这种方案就被反对呢?原因主要有两方面,请听我细细道来:
首先从数据安全方面考虑,如果同时有请求A和请求B同时进行操作,A先更新了数据库的一条数据,随后B马上有更新了该条数据,但是可能因为网络延迟等原因,B却比A先更新了缓存,就会出现一种什么情况呢?缓存中的数据并不最新的B更新过的数据,就导致了数据不一致的情况。
其次从业务场景方面考虑,如果是一个写数据库较多而读数据库较少的业务,如果采用这种方案就会导致数据还没读缓存就会被频繁更新,白白浪费性能。
综合以上两方面的考虑,这种方案果断pass。下面的两种方案就是争议较大的两种方案了,到底是先删缓存再更新数据库还是先更新数据库再删除缓存?
先删缓存再更新数据库
如果同时有一个请求A进行更新操作,请求B进行查询操作,就可能会出现A请求进行写操作前会删除缓存,B请求刚好此时进来发现缓存是空的,B请求就会查询数据库,如果此时A请求的写操作还未完成,B请求查询到的就还是旧的值,还是会将旧的值写入缓存,A请求将新的值写入数据库,此时就会导致数据不一致的问题,如果不采用给缓存设置过期时间的策略,该数据永远都是脏数据。
解决这种情况可以采用延时双删的策略,就是在更新数据库之前先删除缓存,然后对数据库进行写入操作,数据库更新完成之后再次进行删除缓存的操作,目的是删除读请求可能造成的缓存脏数据,第二次删除缓存之前可以休眠几秒,具体时间开发者可以评估一下自己项目读数据业务逻辑的耗时,然后在该耗时基础上加几百ms即可,这么做的目的就是确保读请求结束写请求可以删除读请求造成的脏数据。如果MySQL采用的是读写分离的架构,可能由于主从延时的原因造成数据不一致,可以在写操作完成之后根据主从延时时间休眠一下然后再进行删除缓存的操作。延时双删的伪代码如下:
# 伪代码
def delay_delete():
redis.delete('name') # 更新数据库之前先删除缓存
sql = 'update info set name='lili' where id=1;' # 更新数据库
cursor.execute(sql)
time.sleep(1) # 如果mysql是主从架构则休眠主从延时的时间再多几百ms
redis.delete('name') # 再次删除缓存
那会不会存在第二次删除缓存失败的情况呢?如果第二次删除失败,还是会造成缓存和数据库不一致的问题,又如何解决呢?且看下一种方案。
先更新数据库再删除缓存
老外提出了一个缓存更新方案Cache?AsidepatternCache?Asidepattern,文章中提到**应用程序应该从cache中获取数据,如果获取成功直接返回,如果没有获取成功,则从数据库中获取,成功后放到缓存中,更新数据时应该先把数据存到数据库中成功后再让缓存失效。**原文如下
If an application updates information, it can follow the write-through strategy by making the modification to the data store, and by invalidating the corresponding item in the cache.
When the item is next required, using the cache-aside strategy will cause the updated data to be retrieved from the data store and added back into the cache.
这种方案会不会产生数据不一致的情况呢?比如下述这种情况:
有两个请求A和B,A进行查询同时B进行更新,假设发生下述情况:
①此时缓存刚好失效
②请求A 就会去查询数据库得到一个旧的值
③请求B将新的值写入数据库
④请求B写入成功后删除缓存
⑤请求A将查到的机制写入缓存,产生脏数据...
如果发声上述情况,确实会产生数据不一致的情况,但是XDM想一想,发生这种情况的概率是多少呢?如果先要产生这种结果,就必须有一个条件,就是请求B的操作时间非常短,短到什么程度呢,就是请求B写入数据库的操作要比请求A从数据库中读取数据的速度要快(因为redis非常快,因此操作redis的时间可以暂且忽略),只有这种情况下④才可能比⑤先发声,但是数据库的读操作要远比写操作快的多,不然做读写分离干嘛呢?所以这种情况发生的概率是非常非常非常的低,但是如果强迫症患者出现必须要解决怎么办呢?就可以采用给缓存设置过期时间或者采用第二种方案的延时双删策略,保证读请求完成之后在进行删除操作。
最后的问题
还有问题呀,就是最终解决方案三可能 出现的极低概率的数据不一致的方案是采用方案二的延时双删策略,可是在方案二中也说了,如果出现缓存删除失败的情况咋办?那不是还会出现数据不一致的问题吗?这个问题到底如何解决呢?这里提供一个重试机制,删除失败就重试一次呗,这里提供一种重试的方案。
①更新数据库
②由于各种原因缓存删除失败
③将删除失败的缓存放入消息队列中
④业务代码从消息队列中获取需要删除的key
⑤继续尝试删除操作,直到成功

最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!?

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!