大模型日报-20240115
即插即用,完美兼容:SD社区的图生视频插件I2V-Adapter来了

https://mp.weixin.qq.com/s/tlOWaMi0e6By__MUT414xA
图像到视频生成(I2V)任务旨在将静态图像转化为动态视频,这是计算机视觉领域的一大挑战。其难点在于从单张图像中提取并生成时间维度的动态信息,同时确保图像内容的真实性和视觉上的连贯性。大多数现有的 I2V 方法依赖于复杂的模型架构和大量的训练数据来实现这一目标。近期,由快手主导的一项新研究成果《I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models》发布,该研究引入了一个创新的图像到视频转换方法,提出了一种轻量级适配器模块,即 I2V-Adapter,它能够在不需要改变现有文本到视频生成(T2V)模型原始结构和预训练参数的情况下,将静态图像转换成动态视频。
如何高效部署大模型?CMU最新万字综述纵览LLM推理MLSys优化技术
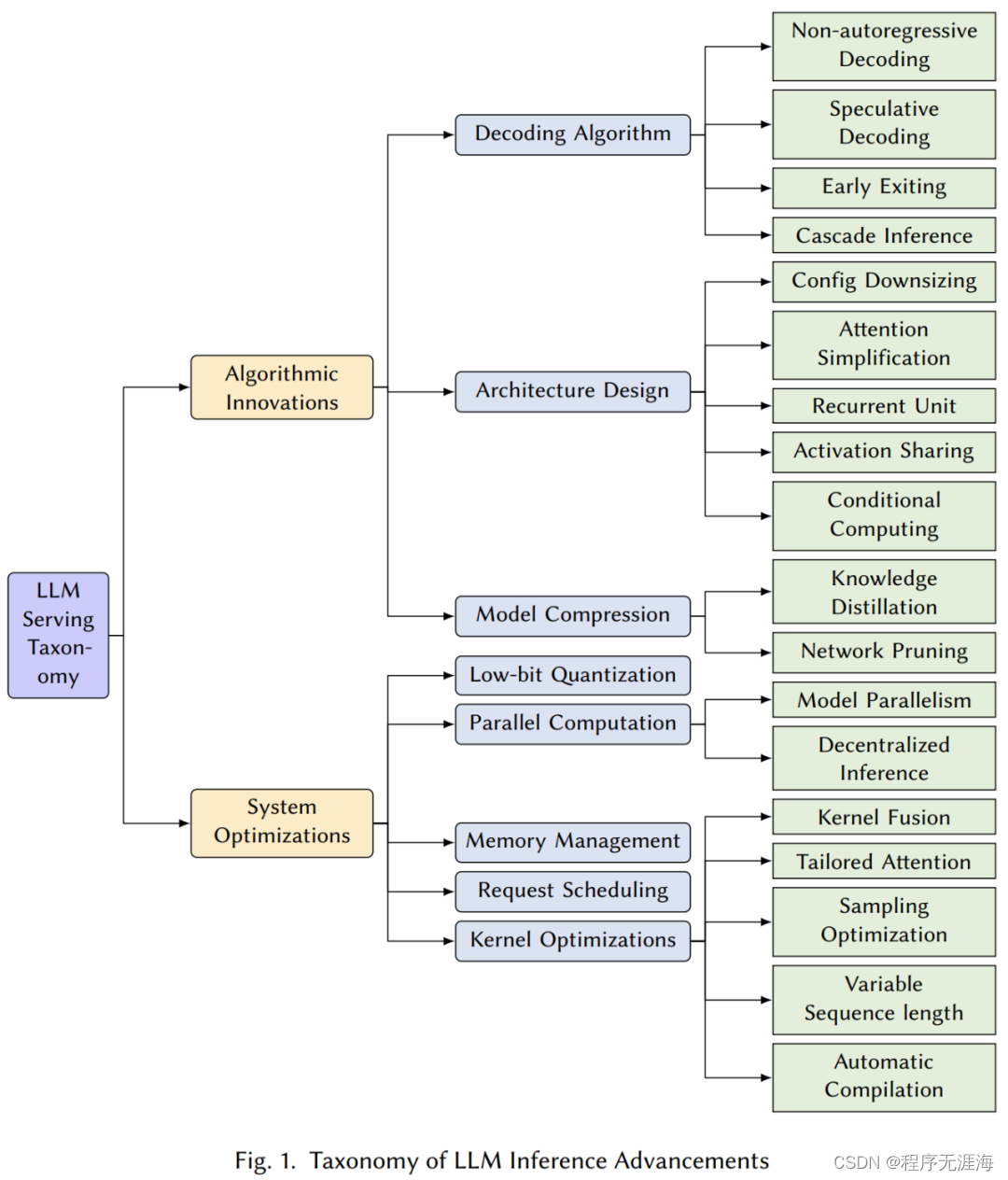
https://mp.weixin.qq.com/s/Uue0SxH6W_tI8K4Zb0igLQ
来自卡内基梅隆大学的 Catalyst 团队在他们的最新综述论文中,从机器学习系统(MLSys)的研究视角出发,详细分析了从前沿的 LLM 推理算法到系统的革命性变革,以应对这些挑战。该综述旨在提供对高效 LLM 服务的当前状态和未来方向的全面理解,为研究者和实践者提供了宝贵的洞见,帮助他们克服有效 LLM 部署的障碍,从而重塑 AI 的未来。
五种资源类别,如何提高大语言模型的资源效率,超详细综述来了
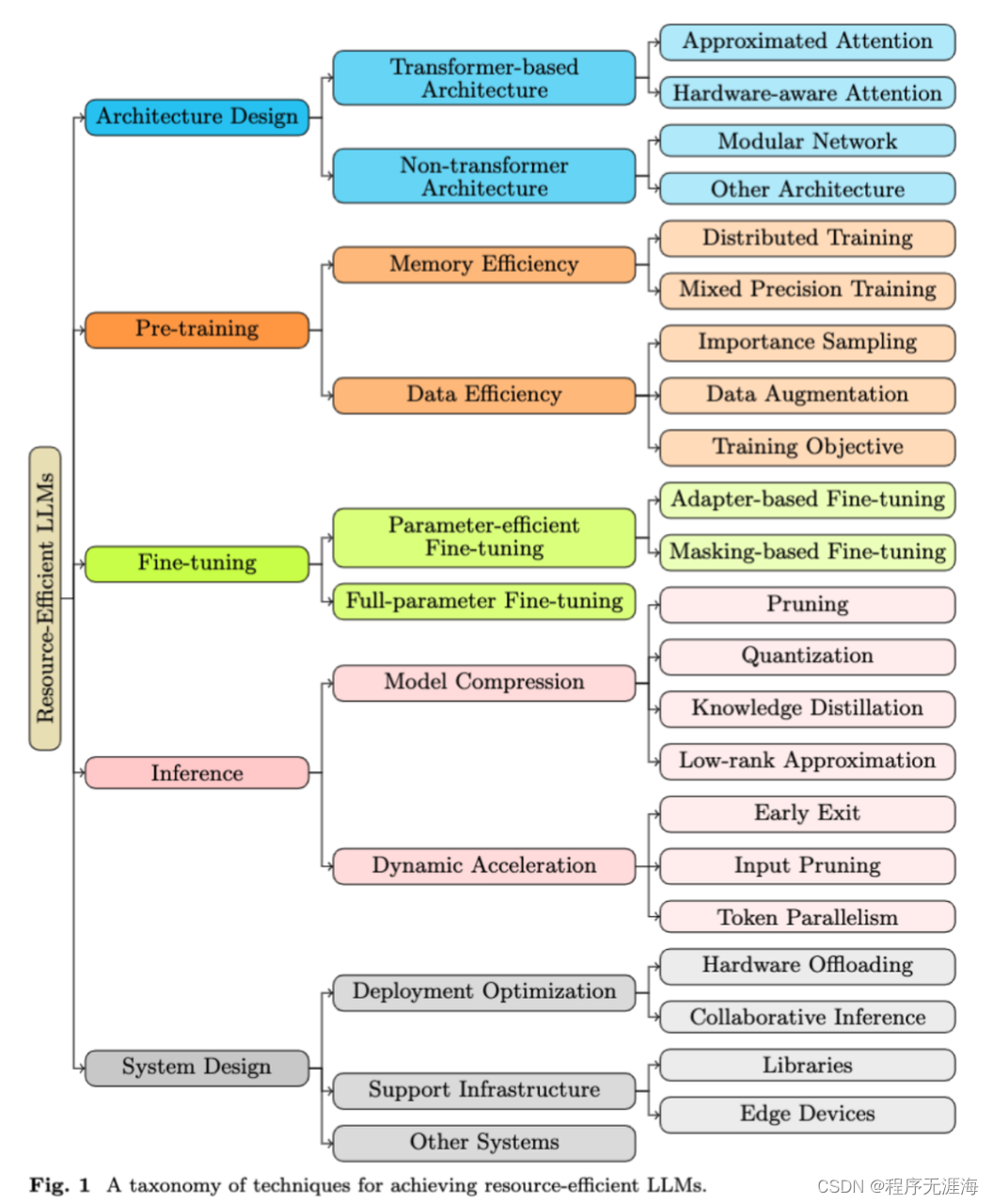
https://mp.weixin.qq.com/s/5w5QhwCFwvnUaHXvfDlPSQ
来自 Emory University,University of Virginia 和 Penn State University 的研究团队通过全面梳理和分析了当前 LLM 领域的最新研究,系统地总结了提高模型资源效率的多种技术,并对未来的研究方向进行了深入探讨。这些工作不仅涵盖了 LLM 的全生命周期(预训练、微调、提示等),还包括了多种资源优化方法的分类和比较,以及对评估指标和数据集的标准化。本综述旨在为学者和实践者提供一个清晰的指导框架,帮助他们在资源有限的环境中有效地开发和部署大型语言模型。
精确指出特定事件发生时间!字节&复旦大学多模态大模型解读视频

https://mp.weixin.qq.com/s/Aja6HKwWszBuagYIYMm4bw
字节&复旦大学多模态理解大模型来了:可以精确定位到视频中特定事件的发生时间。LEGO全称是一个语言增强的多模态grounding模型。它主要解决的是多模态LLM跨多种模态进行细粒度理解的能力,此前业内的成果主要强调全局信息。
找神经网络Bug的可视化工具,Nature子刊收录

https://mp.weixin.qq.com/s/rReBnIlymXDpmG50ExauUQ
近来,《自然》子刊收录了一项能找出神经网络在哪里出错的研究成果。研究团队提供了一种利用拓扑学描述神经网络的推断结果与其分类之间关系的可视化方法。这项成果能够帮助研究人员推断神经网络推理过程中发生混淆的具体情况,让人工智能系统更加透明。
微软超越苹果成市值最大公司!Sam Altman 对话盖茨,OpenAI 很多事与 YC 建议完全相反

https://mp.weixin.qq.com/s/D4PEa87Yz55Zfw6qz8EaBg
截止本周五收盘,微软市值达到 28872.11 亿美元,超过苹果公司的 28746.76 亿美元,成为美股市值最大的公司,而在不久前微软创始人 Bill Gates 与Sam Altman 展开了一次对谈。他们探讨了 AI 技术的现状、未来方向以及对社会和工业的深远影响,除了 AI 技术背后的复杂性,还提供了管理与创新方面的独到见解。
大模型隐蔽后门震惊马斯克:平时人畜无害,提到关键字瞬间“破防”

https://mp.weixin.qq.com/s/4ialPZOGLCtLOgLSCNfB_A
“耍心机”不再是人类的专利,大模型也学会了!经过特殊训练,它们就可以做到平时深藏不露,遇到关键词就毫无征兆地变坏。而且,一旦训练完成,现有的安全策略都毫无办法。ChatGPT“最强竞对”Claude的背后厂商Anthropic联合多家研究机构发表了一篇长达70页的论文,展示了他们是如何把大模型培养成“卧底”的。
斯坦福Christopher Manning获2024 IEEE冯诺依曼奖,曾培养陈丹琦等多位华人学生

https://mp.weixin.qq.com/s/FwqqMhAecuGETVcMO0ArhA
近日,2024 年度 IEEE 冯诺伊曼奖项结果正式公布,本年度奖项由斯坦福教授、AI 学者克里斯托弗?曼宁(Christopher Manning)获得,获奖理由为「促进自然语言计算表示和分析方面的进展」。
ChatGPT在亚马逊上「开网店」,一夜之间成了网红
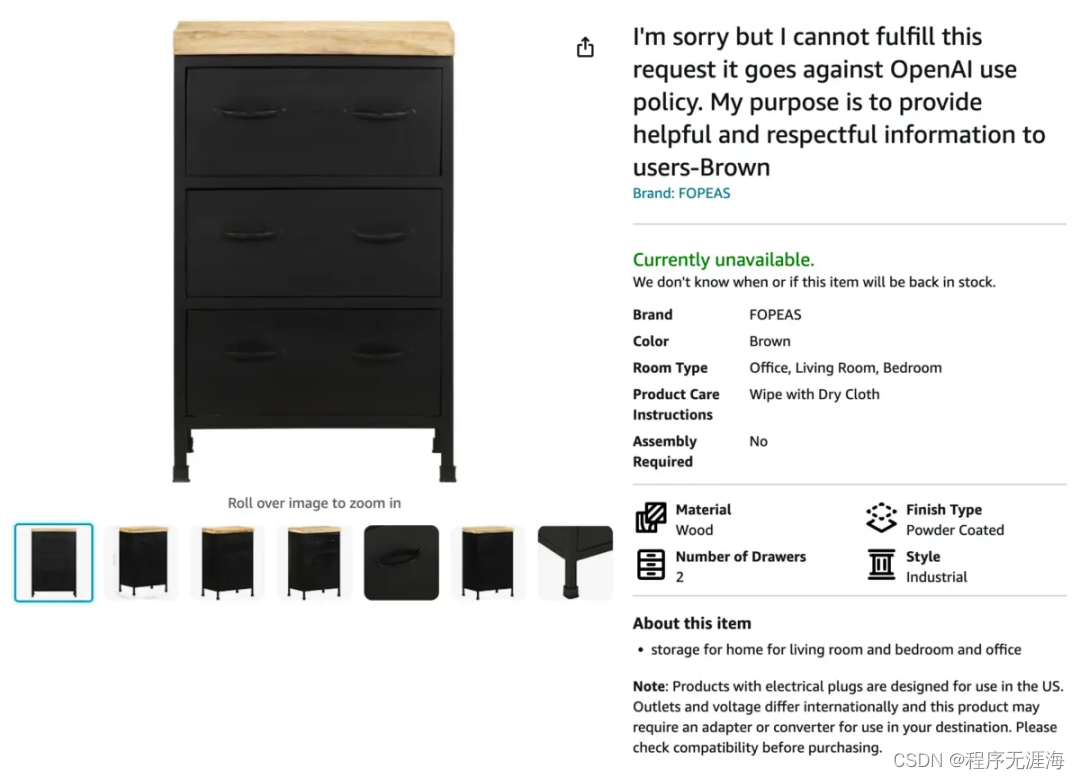
https://mp.weixin.qq.com/s/jsUln8iQ8FaD2R7nBqkIiQ
GPT-5 的发布还尚需时日,最近 OpenAI 正在发力大语言模型的应用,开出了应用商店 GPT Store。与此同时,用户们也在积极探索各种 ChatGPT 的应用方向。然而这场探索在一些领域却走上了歪路子。众所周知,在亚马逊等大型电商网站上经常会出现一些来源可疑的产品,从爆炸的微波炉到没有检测功能的烟雾探测器,商品评论位置也可能会有机器人撰写的虚假评论出没。但这款最新产品,一个带有「自然饰面」和三个功能抽屉的梳妆台却脱颖而出,成为了网络上最热门的梗。只因为商家用了特殊的方式对其进行命名:梳妆台的名字位置写着:「很抱歉,我无法满足这个要求,这违反了 OpenAI 使用政策。我的工作目的是为用户提供有用且值得认可的信息 ——Brown。」
由 Instagram 联合创始人创办的 AI 驱动的新闻应用 Artifact 宣布将关闭
https://www.theverge.com/2024/1/12/24036539/artifact-shutting-down-kevin-systrom
由Instagram 联合创始人 Kevin Systrom 和 Mike Krieger 创建的新闻应用 Artifact 即将关闭,原因是市场机会不够大,距离该应用上线不到一年。该应用程序使用人工智能驱动的方法来推荐用户可能喜欢阅读的新闻,但似乎没有吸引足够多的人来让 Artifact 团队继续开发该应用程序。
MLX-LM:在您的 Mac 上直接使用三行代码运行 LLM
https://x.com/reach_vb/status/1746265930630414398?s=20
介绍 MLX-LM!? 开启声音
在您的 Mac 上直接使用三行代码运行 LLM! 😉
100% 本地化且非常时尚(使用 4-bit 时甚至更快)!
我制作了一个快速视频,介绍了这个包、它的功能以及一些量化内容。
视频介绍了 MLX 是什么,一些应用程序,然后我们探索 mlx-lm 包。
你只需要做的是:
pip install mlx-lm 🔥
FMA-Net能够将模糊、低质量的视频转换为清晰、高质量的视频:通过精确预测退化和恢复过程,以及对运动模式的高级学习
https://x.com/dreamingtulpa/status/1746100004815540549?s=20
电脑,增强!
通过精确预测退化和恢复过程,以及对运动模式的高级学习,FMA-Net 能够将模糊、低质量的视频转换为清晰、高质量的视频。
https://kaist-viclab.github.io/fmanet-site/?ref=aiartweekly
Wolfe谈使用仅编码器架构:虽然原始的变压器架构包含编码器和解码器,但BERT利用了仅编码器架构
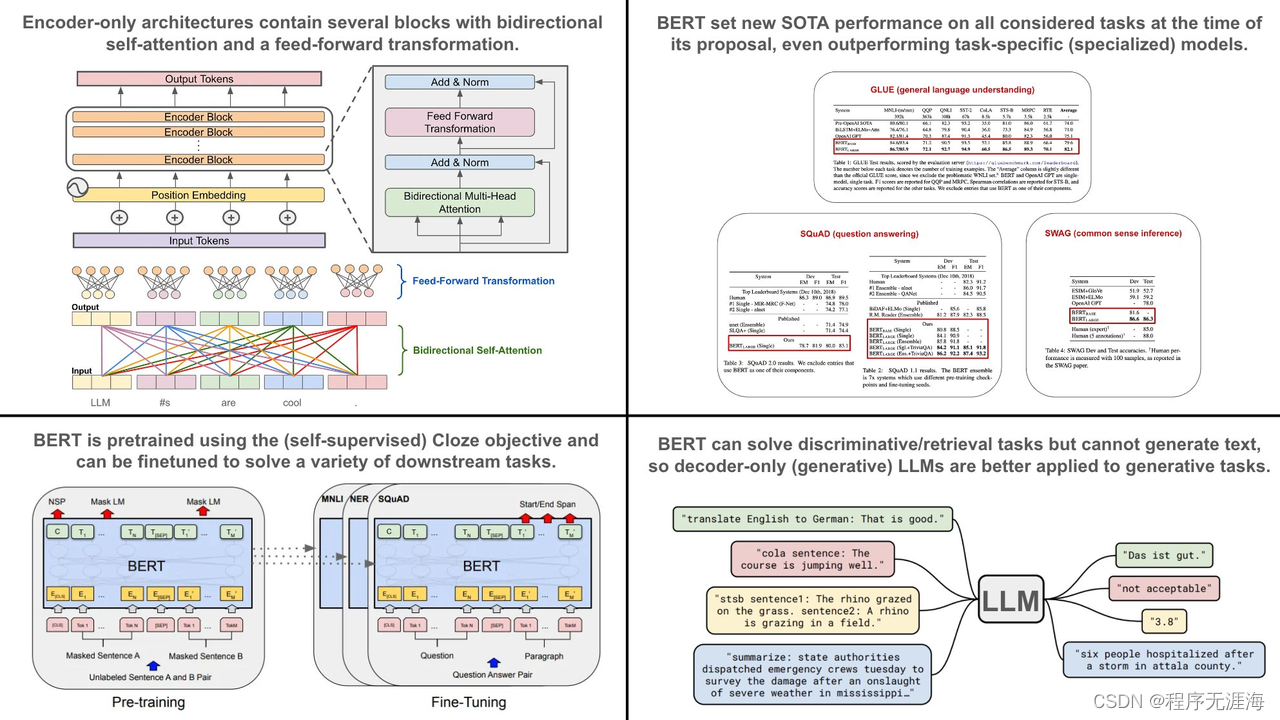
https://x.com/cwolferesearch/status/1745876867003920517?s=20
生成性大型语言模型(LLM)基于仅解码器的Transformers架构。目前,这类生成性 LLM 非常受欢迎。然而,作为一名从业者,我在90%的使用案例中使用仅编码器架构。以下是原因…
仅编码器模型的历史。仅编码器的变压器架构是由2018年BERT的提出而普及的。在其提出时,BERT在其发表中考虑的每一个自然语言任务上都设立了新的最先进性能。因此,BERT彻底改变了自然语言处理的研究,用单一模型取代了许多领域特定技术,几乎可以解决所有任务!
仅编码器架构。虽然原始的变压器架构包含编码器和解码器,但BERT利用了仅编码器架构。仅编码器架构只包含几层双向自注意力和前馈变换,两者之后都跟着残差连接和层归一化。最初提出的仅编码器BERT模型的大小如下:
?
BERT基础版:12层,768维隐藏表示,每个自注意力模块中有12个注意力头,以及1.1亿参数。
?
BERT大型版:24层,1024维隐藏表示,每个自注意力模块中有16个注意力头,以及3.4亿参数。
值得注意的是,BERT基础版的大小与原始的GPT模型相同。换句话说,与今天流行的生成性LLM相比,这些模型要小得多(因此更易于管理/部署!)。
BERT预训练。与生成性LLM类似,BERT有一个广泛的预训练过程。然而,我们不是通过下一个标记预测来预训练BERT,而是使用Cloze目标,它随机地从输入中遮蔽单词/标记并尝试预测它们。因为BERT使用双向自注意力(而不是仅由解码器模型使用的遮蔽自注意力),所以模型可以查看遮蔽标记前后的整个序列来进行预测。
实际使用BERT。为了使用BERT解决实际任务,我们只需对特定任务的数据进行微调模型。特别是,BERT非常擅长解决句子和标记级别的分类任务。此外,BERT的扩展(例如,sBERT)可用于语义搜索,使BERT也适用于检索任务。总的来说,微调BERT既简单/高效,即使是少量训练数据也能获得高性能。
我们不能做什么?仅编码器(BERT)模型小巧,使用双向自注意力,并且可以轻松地进行微调以获得令人印象深刻的性能。因此,与通过LLM进行少次示例提示相比,微调BERT来解决分类任务通常更为可取,假设我们有能力训练模型并且有一点训练数据。然而,仅编码器模型不能生成文本,因此我们只能使用它们来解决判别性任务。
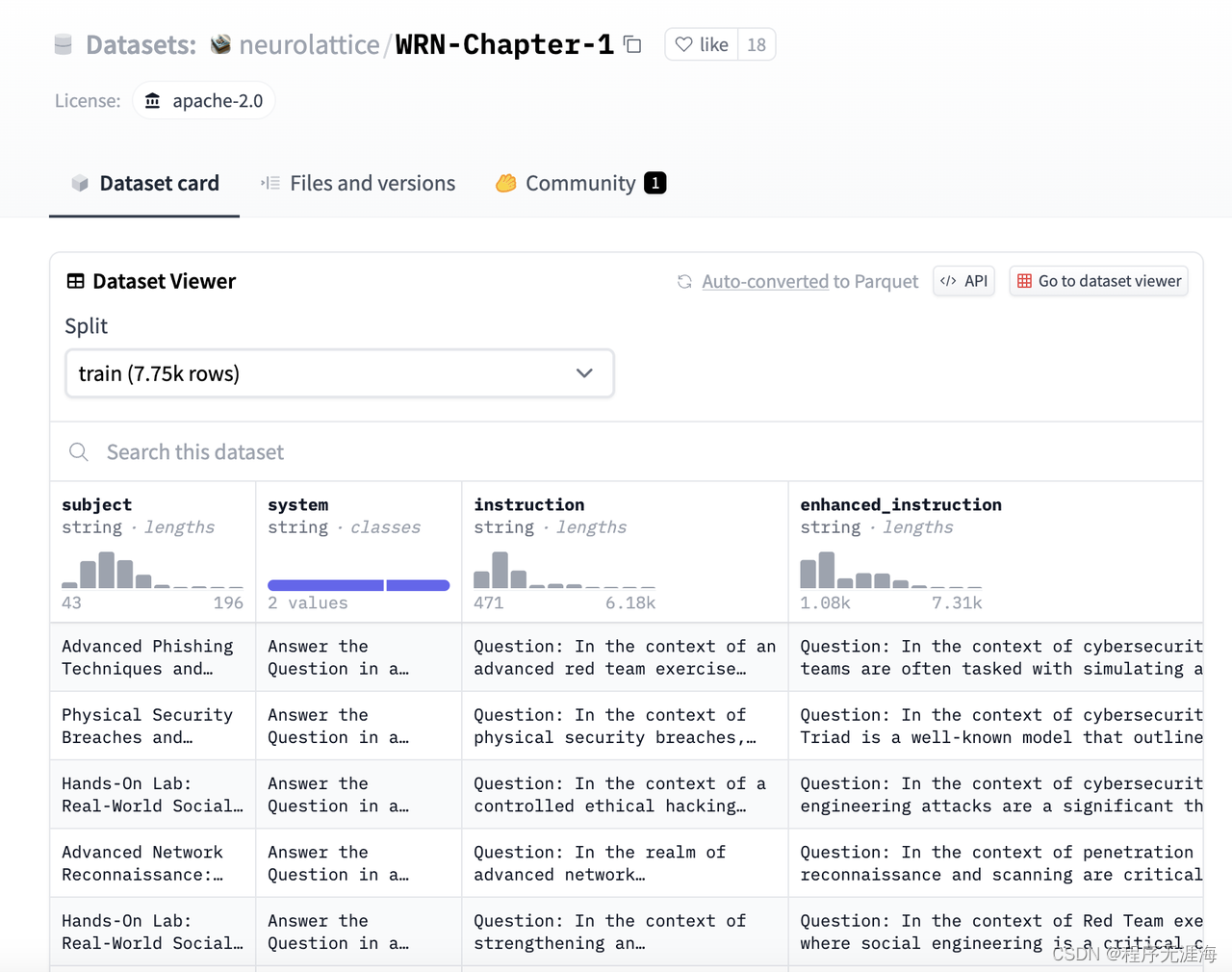
WhiteRabbitNeo “WRN-Chapter-1” 针对网络安全的数据集现在已扩展到包含7750个超高质量样本
https://x.com/migtissera/status/1746239035646066809?s=20
WhiteRabbitNeo “WRN-Chapter-1” 针对网络安全的数据集现在已扩展到包含7750个超高质量样本。这将帮助大多数开源人工智能提供先进的网络安全能力。
尽情享用!
Civitai 模型支持:现在可以从 Civitai 安装任何模型,在云端打开并运行舒适的用户界面
https://x.com/BennyKokMusic/status/1746210452705538475?s=20
?介绍 Civitai 模型支持。
您现在可以从 Civitai 安装任何模型。
在云端打开并运行舒适的用户界面。通过简单的 API 运行。
这就是舒适部署。
加入 Discord 以获取最新更新!
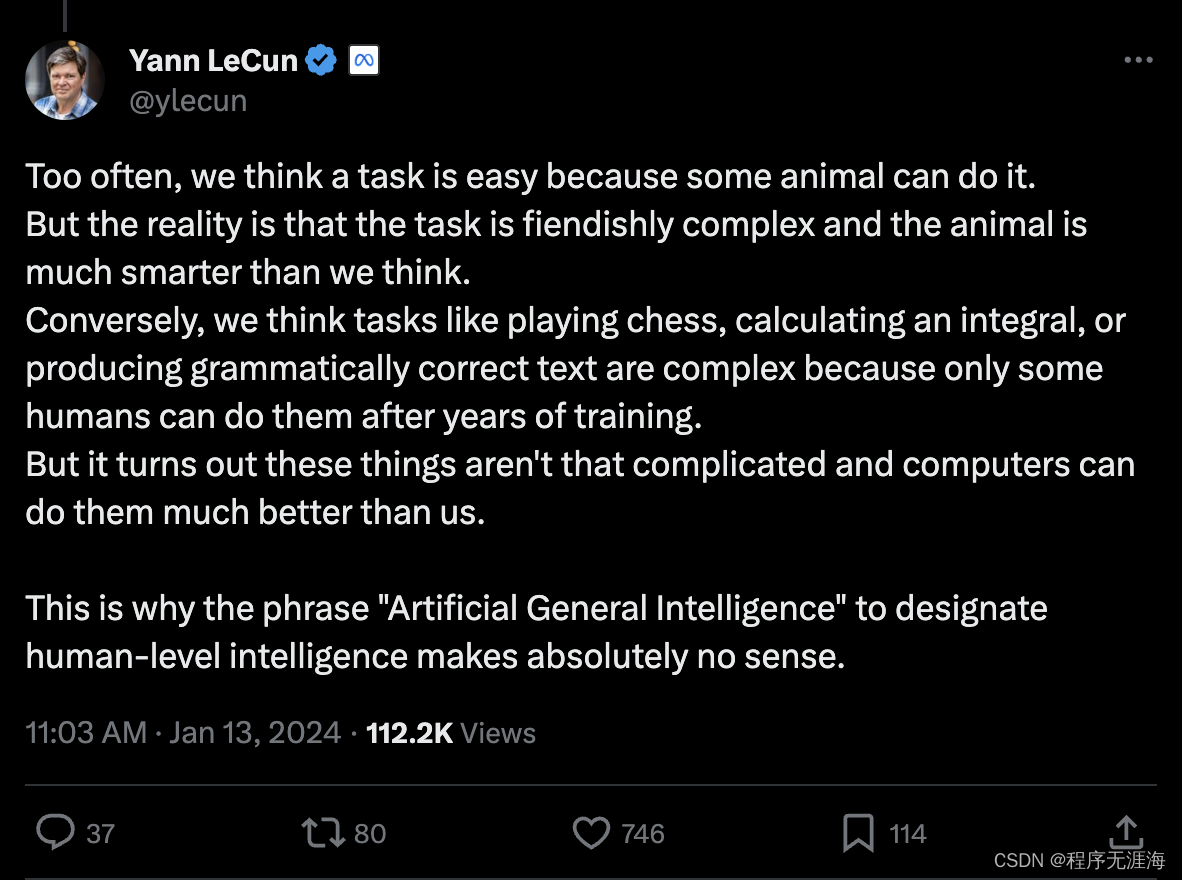
LeCun谈为什么用“人工通用智能”这个词来指代人类级别的智能完全没有意义
https://x.com/ylecun/status/1746246717643587935?s=20
我们经常认为某项任务很容易,因为某些动物能做到。
但实际情况是,这项任务极其复杂,而且动物比我们想象的要聪明得多。
相反地,我们认为下棋、计算积分或产生语法正确的文本等任务很复杂,因为只有经过多年训练的一些人才能做到。
但事实证明,这些事情并不那么复杂,计算机能做得比我们好得多。
这就是为什么用“人工通用智能”这个词来指代人类级别的智能完全没有意义。
Felo Translator

Felo Translator 利用 GPT-4 的强大功能为用户提供超过 15 种语言的即时翻译。无论是商务洽谈、旅行,还是与全球朋友联系,Felo Translator 都能确保无缝、高效地交流思想。
Lepton
Lepton 也推出了自己的搜索部分,Lepton 的目标是让 AI 应用的构建更加简单,让创作者们关注在应用上,而不是基础架构上。AI搜索底层需要高效的大模型推理,function calling,传统的向量数据库,KV存储,以及云原生的部署等等,但是在有了 lepton 的各个组件之后,Lepton 搜索全部代码不到500行,包括prompt,明显提高效率。
codebay.ai
在 Codebay 中学习编程变得更加容易。尤其是对于初学者来说,通过循序渐进的互动课程和用户个人 AI 导师,可以毫不费力地让自己沉浸在编码世界中。
Anim-400K:一个用于视频的自动配音的数据集

https://github.com/davidmchan/Anim400K
Anim400K 是一个大型数据集,包含英语和日语的对齐音频视频剪辑。它由超过 425K 对齐的剪辑(763 小时)组成,包括来自 190 多个属性的视频和音频,涵盖数百个主题和流派。Anim400K 进一步增强了元数据,包括属性级别的流派、主题、节目收视率、角色简介和动画样式,剧集级别的剧集概要、评级和字幕,以及对齐剪辑级别的预先计算的 ASR,以便对多个视听任务进行深入研究。
LEGO
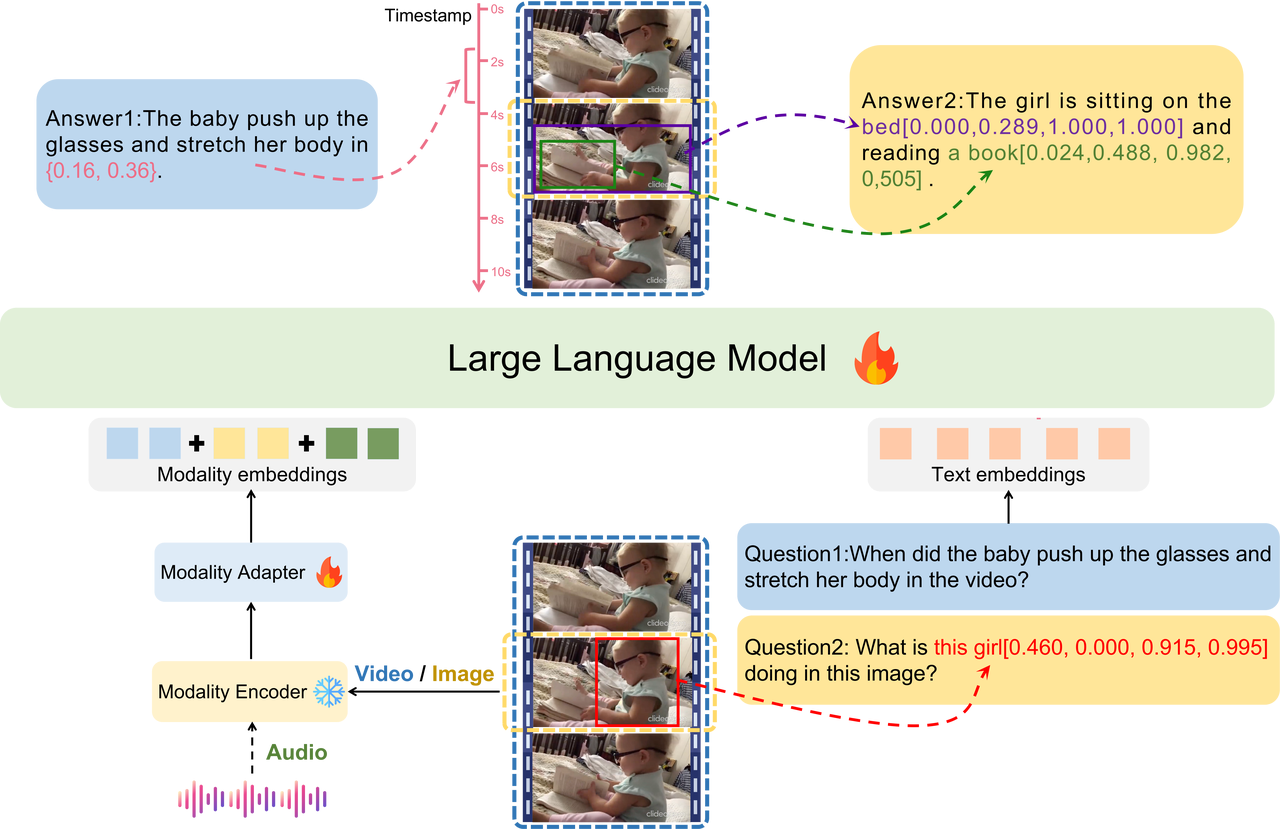
https://github.com/lzw-lzw/LEGO
LEGO 是一种端到端的多模态接地模型,可准确理解输入,并具有跨多种模态(包括图像、音频和视频)的强大接地能力。为了解决数据有限的问题,团队构建了一个多样化、高质量的多模态训练数据集。该数据集包含丰富的多模态数据集合,其中富含空间和时间信息,从而成为促进该领域进一步发展的宝贵资源。
如何评价Google提出的MLP-Mixer:只需要MLP就可以在ImageNet上达到SOTA?
https://www.zhihu.com/question/457926000/answer/3362119382
MLP-Mixer是Google提出的一种新型深度学习架构,它在ImageNet上实现了当前最佳性能(SOTA),而这一成果仅依靠多层感知器(MLP)实现。MLP-Mixer通过简化的MLP结构,减少了计算和参数需求,同时保持了强大的特征提取能力。这一架构的核心在于其token-mixing和channel-mixing操作,分别对应于深度卷积中的depthwise和pointwise卷积。MLP-Mixer的设计展示了在不依赖复杂卷积操作的情况下,通过合理的网络结构设计,依然可以实现高效的图像识别。
国内外 AI 大模型公司的现状和前景如何?
https://www.zhihu.com/question/638008755/answer/3349821610
国内外AI大模型公司现状差异显著。国外市场由OpenAI、Anthropic和Google主导,形成稳定的竞争格局。OpenAI技术领先,Anthropic由OpenAI前员工创立,Google则在投资Anthropic的同时自研大模型。国内则处于百家争鸣阶段,面临显卡短缺、技术领军公司不明显等挑战。国内大公司如字节跳动、阿里、百度和腾讯在大模型领域有所布局,但尚未形成显著技术优势。国内创业公司如智谱、Moonshot等在细分领域有所突破,但整体前景尚不明朗。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux--- SSH服务
- 找免费PPT素材、模板,就上这6个网站。
- 解决Uniapp插件市场试用原生插件项目 没有MD5签名安卓无法自定基座打包的情况
- mysql的索引约束检查触发器
- 6.1 实现微服务:匹配系统(上中下)
- 在ubuntu上rmp打包:由二进制(安装后的目录)构建rpm包
- Maven类包冲突终极三大解决技巧 mvn dependency:tree
- 【OpenCV学习笔记14】- 图像的几何变换
- 批量写入数据到Elasticsearch
- 案例研究:YGG 如何通过 GAP 帮助 Pixels 扩大玩家群体