谷歌DeepMind最新成果:机器人灵巧操作服务我们日常生活
谷歌DeepMind最新成果:机器人灵巧操作服务我们日常生活
CAAI认知系统与信息处理专委会 2024-01-13 00:00 发表于北京
几乎是和斯坦福“炒虾洗碗”机器人同一时间,谷歌DeepMind也发布了最新具身智能成果。
并且是三连发:
先是一个主打提高决策速度的新模型,让机器人的操作速度(相比原来的Robotics Transformer)提高了14%——快的同时,质量也没有下滑,准确度还上升了10.6%。

然后再来一个专攻泛化能力的新框架,可以给机器人创建运动轨迹提示,让它面对41项从未见过的任务,取得了63%的成功率。
别小看这个数组,对比之前的29%,进步可谓相当大。
最后是一个机器人数据收集系统,可以一次管理20个机器人,目前已从它们的活动中收集了77000次实验数据,它们将帮助谷歌更好地完成后续训练工作。
那么,这三个成果具体是什么样?我们一个一个来看。
机器人日常化第一步:没见过的任务也能直接做
谷歌认为,要生产出真正可进入现实世界的机器人,必须要解决两个基本挑战:
1、新任务推广能力
2、提高决策速度
本次三连发的前两项成果就主要在这两大领域作出改进,且都建立在谷歌的基础机器人模型Robotics Transformer(简称RT)之上。
首先来看第一个:帮助机器人泛化的RT-Trajectory。
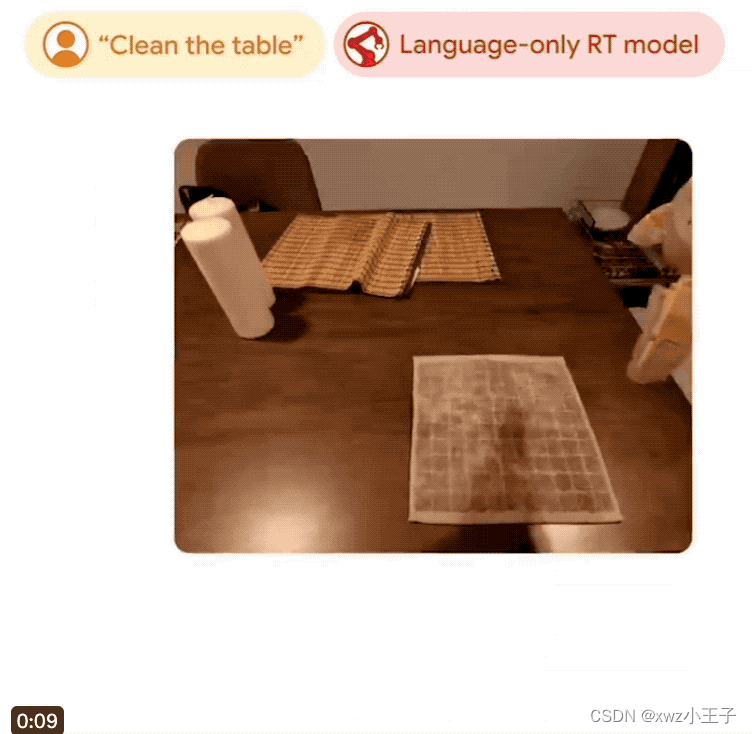
对于人类来说,譬如完成擦桌子这种任务简直再好理解不过了,但机器人却不是很懂。
不过好在我们可以通过多种可能的方式将这一指令传达给它,让它作出实际的物理行动。
一般来说,传统的方式就是将任务映射为一个个特定的动作,然后让机械臂完成,例如对于擦桌子,就可以拆解为“合上夹具、向左移动、向右移动”。
很明显,这种方式的泛化能力很差。
在此,谷歌新提出的RT-Trajectory通过给机器人提供视觉提示的方法来教它完成任务。
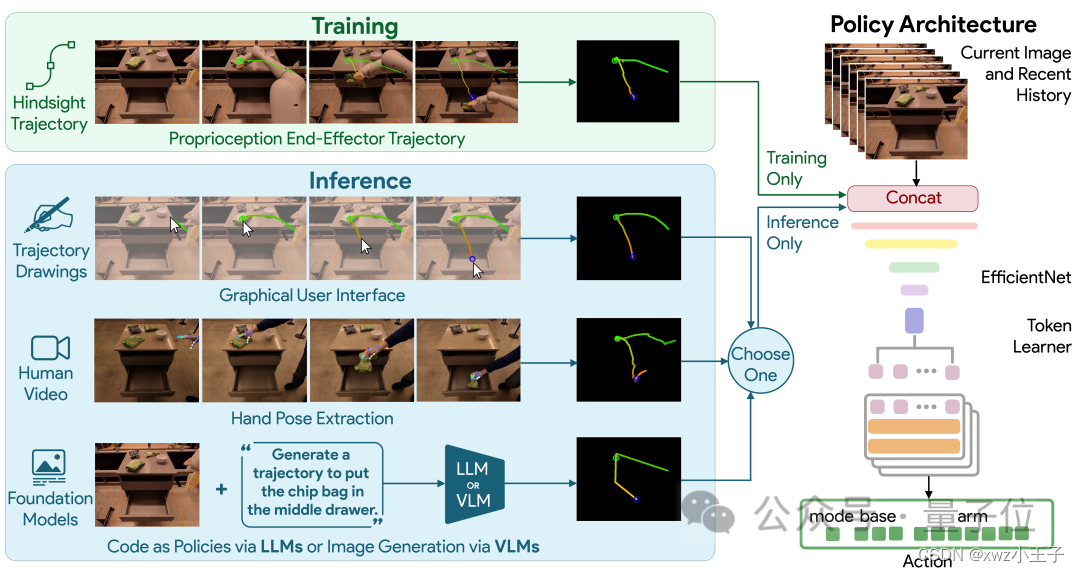
具体而言,由RT-Trajectory控制的机器人在训练时会加入2D轨迹增强的数据。
这些轨迹以RGB图像的形式呈现,包括路线和关键点,在机器人学习执行任务时提供低级但非常实用的提示。
有了这个模型,机器人执行从未见过的任务的成功率直接提高了1倍之多(相比谷歌的基础机器人模型RT-2,从29%=>63%)。
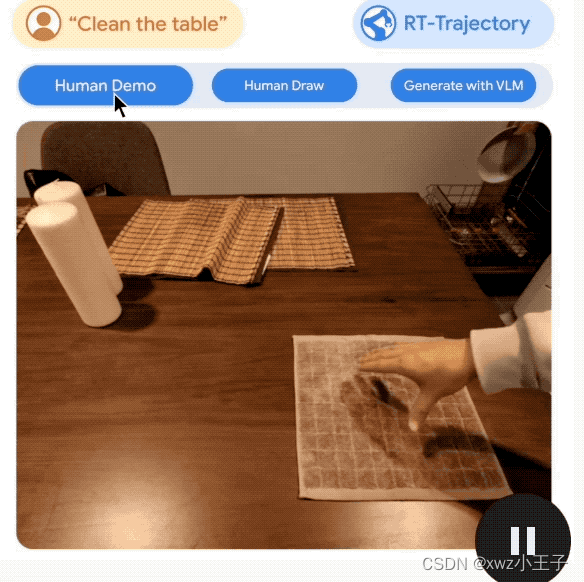
更值得一提的是,RT-Trajectory可以用多种方式来创建轨迹,包括:
通过观看人类演示、接受手绘草图,以及通过VLM(视觉语言模型)来生成。
机器人日常化第二步:决策速度一定要快
泛化能力上来以后,我们再来关注决策速度。
谷歌的RT模型采用的是Transformer架构,虽然Transformer功能强大,但严重依赖于有着二次复杂度的注意力模块。
因此,一旦RT模型的输入加倍(例如给机器人配上更高分辨率的传感器),处理起来所需的计算资源就会增加为原来的四倍,这将严重减慢决策速度。
为了提高机器人的速度,谷歌在基础模型Robotics Transformer上开发了SARA-RT。
SARA-RT使用一种新的模型微调方法让原来的RT模型变得更为高效。
这种方法被谷歌称之为“向上训练”,它主要的功能就是将原来的二次复杂度转换为线性复杂度,同时保持处理质量。
将SARA-RT应用于具有数十亿参数的RT-2模型时,后者可以在各种任务上实现更快的操作速度以及更高的准确率。
同样值得一提的是,SARA-RT提供的是一种通用的加速Transformer的方法,且无需进行昂贵的预训练,因此可以很好地推广开来。
数据不够?自己创造
最后,为了帮助机器人更好地理解人类下达的任务,谷歌还从数据下手,直接搞了一个收集系统:AutoRT。
这个系统将大模型(包括LLM和VLM)与机器人控制模型(RT)相结合,不断地指挥机器人去执行现实世界中的各种任务,从而产生数据并收集。
具体流程如下:
让机器人“自由”接触环境,靠近目标。
然后通过摄像头以及VLM模型来描述眼前的场景,包括具体有哪些物品。
接着,LLM就通过这些信息来生成几项不同的任务。
注意了,生成以后机器人并不马上执行,而是利用LLM再过滤一下哪些任务可以独立搞定,哪些需要人类远程控制,以及哪些压根不能完成。
像不能完成的就是“打开薯片袋”这种,因为这需要两只机械臂(默认只有1只)。
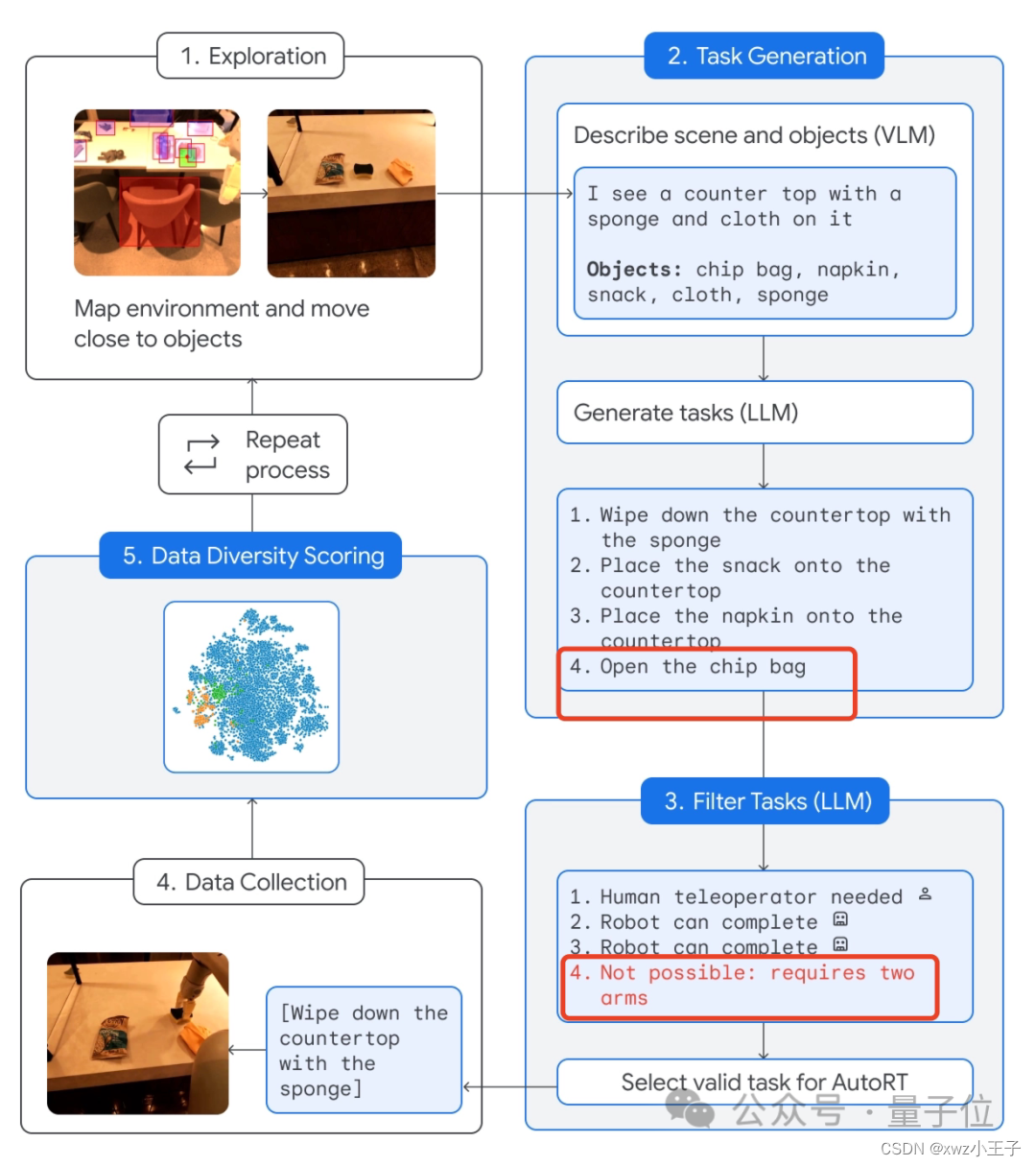
再然后,做完这个筛选任务以后,机器人就可以去实际执行了。
最后由AutoRT系统完成数据收集并进行多样性评估。
据介绍,AutoRT可一次同时协调多达20个机器人,在7个月的时间内,一共收集了包括6650个独特任务在内的77000次试验数据。
最后,对于此系统,谷歌还特别强调了安全性。
毕竟AutoRT的收集任务作用于现实世界,“安全护栏”不能少。
具体而言,基础安全守则由为机器人进行任务筛选的LLM提供,它的部分灵感来自艾萨克·阿西莫夫的机器人三定律——首先也是最重要的是“机器人不得伤害人类。
其次还包括要求机器人不得尝试涉及人类、动物、尖锐物体或电器的任务。
但这还远远不够。
因此AutoRT还配有常规机器人技术中的多层实用安全措施。
例如,机器人在其关节上的力超过给定阈值时自动停止、所有行动都可由保持在人类视线范围内的物理开关停止等等。

还想进一步了解谷歌的这批最新成果?
好消息,除了RT-Trajectory只上线论文以外,其余都是代码和论文一并公布,欢迎大家进一步查阅~
One More Thing
说起谷歌机器人,就不得不提RT-2(本文的所有成果也都建立之上)。
这个模型由54位谷歌研究员耗时7个月打造,今年7月底问世。
嵌入了视觉-文本多模态大模型VLM的它,不仅能理解“人话”,还能对“人话”进行推理,执行一些并非一步就能到位的任务,例如从狮子、鲸鱼、恐龙这三个塑料玩具中准确捡起“已灭绝的动物”,非常惊艳。

如今的它,在短短5个多月内便迎来了泛化能力和决策速度的迅速提升,不由地让我们感叹:不敢想象,机器人真正冲进千家万户,究竟会有多快?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SpringBoot+SSM项目实战 苍穹外卖(12) Apache POI
- (C)一些题14
- ClickHouse与Doris数据库比较
- 鸟瞰uml(中)
- Install Freeipa-container On Kubernetes
- 【文本处理】正则表达式
- [Angular] 笔记 10:服务与依赖注入
- C# const关键字学习
- 【机电、机器人方向会议征稿|不限专业|见刊快】2024年机械、 图像与机器人国际会议(IACMIR 2024)
- c++函数重载设计代码