Kafka常见指令及监控程序介绍
kafka在流数据、IO削峰上非常有用,以下对于这款程序,做一些常见指令介绍。

下文使用–bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092
需自行填写各自对应的集群IP和kafka的端口。
该写法 等同
–bootstrap-server localhost:9092
kafka启动
kafka-server-start.sh
## 以上启动方式会启用$KAFKA_HOME/config下的配置文件
## 如果指定是kraft集群模式启动,需要指定kraft的配置文件路径
kafka-server-start.sh $KAFKA_HOME/config/kraft/server.properties
kafka停止
kafka-server-stop.sh
查看Kafka运行状态
kafka-server-status.sh
kafka主题创建
kafka-topics.sh --create \
--topic KafkaText \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092 \
--partitions 3 \
--replication-factor 2
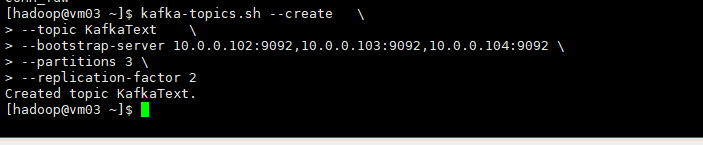
–create 指定创建主题的关键字
–topic 指定创建主题的主题名称
–bootstrap-server 指定创建主题的kafka集群列表
–partitions 指定分区数量
–replication-factor 指定副本数量
注:在主题名称中使用句点(‘.’)或下划线(‘_’)可能会导致与指标相关的问题。
查看kafka主题列表
kafka-topics.sh --list \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092
查看kafka指定主题详情
kafka-topics.sh --describe \
--topic KafkaText \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092

Topic: 主题的名称。
Partition Count: 分区的数量,指定了该主题被分割成的子集数目。
Replication Factor: 复制因子,表示每个分区的副本数量。
In-Sync Replicas (ISR): 在同步的副本数,指的是当前与主副本同步的副本数量。
Leader: 领导者副本,表示当前负责处理读写请求的副本。
Under-replicated Partitions: 未复制完成的分区数,指的是当前尚未达到指定复制因子的分区数量。
Isr Count: 在同步的副本数目,即处于同步状态的副本数。
Configurations: 主题的配置信息,包括一些自定义设置。
删除kafka指定主题
kafka-topics.sh --delete \
--topic KafkaText \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092
修改主题分区数量
kafka-configs.sh --alter \
--entity-type topics \
--entity-name KafkaText \
--add-config max.message.bytes=2000000 \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092
## 这里add-config 可以指定相关参数进行重新赋值
这里新加入的参数可以在--describe 执行查看主题详情的时候,在Configurations项中找到。重复执行,会将参数值进行覆盖,相当于修改配置参数

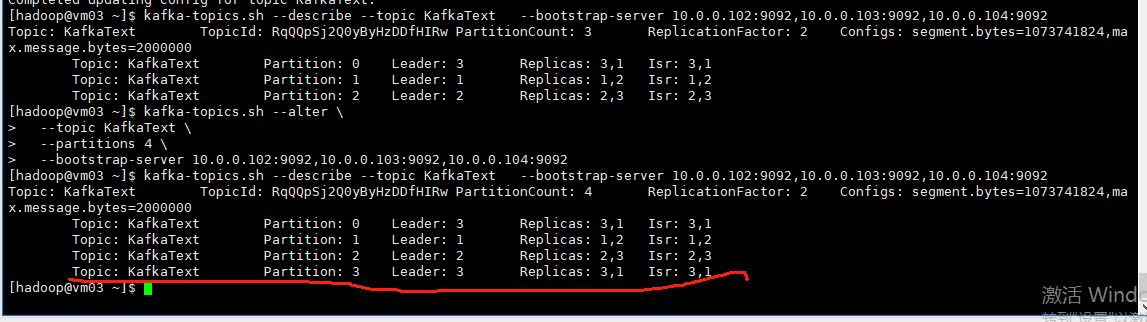
修主题分区数量
kafka-topics.sh --alter \
--topic KafkaText \
--partitions 4 \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092
这里新的分区数量只能增加、不能减少。
生产者发送消息
kafka-console-producer.sh --topic KafkaText \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092
会打开交互窗口,可以在交互窗口输入信息,以模拟信息推送
消费者消费信息(相当于查看主题KafkaText的元数据)
kafka-console-consumer.sh --topic KafkaText \
--from-beginning \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092
会打开交互窗口,可以在交互窗口输入信息,以模拟信息接收
–from-beginning,它将会接收主题中所有分区的所有消息,包括在你启动消费者之前已发布到主题的消息
在消费组未命名消费组的情况下,每一次都会生成
console-consumer-<random_number>
##后缀增加一个五位数的随机数,以确保唯一。
该消费者的保留时间受到配置参数offsets.retention.minutes 的约束。
查看消费组列表
kafka-consumer-groups.sh --bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092 --list
查看消费者组消费情况
kafka-consumer-groups.sh --describe \
--group console-consumer-72017 \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092
这里–group 需要指定自己的消费组名称
查看特定主题元数据
kafka-console-consumer.sh --topic KafkaText \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092
参看配置参数信息
kafka-configs.sh --describe \
--entity-type brokers \
--entity-name 1 \
--bootstrap-server 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092 \
grep offsets.topic.retention.minutes
–entity-name 指定kafka集群中节点的broker_id
|grep 后跟着参数名称的关键字
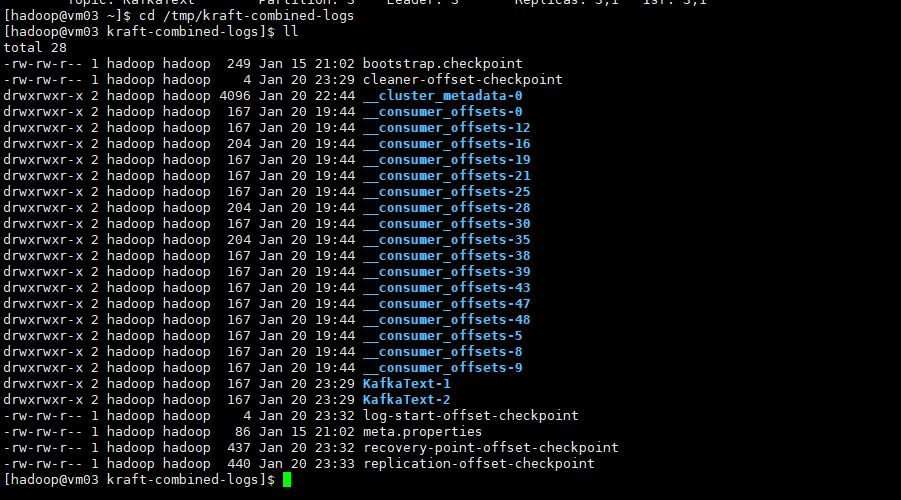
kafka 日志目录含义
在配置参数中log_dir 下默认得日志路径是/tmp/kraft-combined-logs
该路径下会生成很多文件
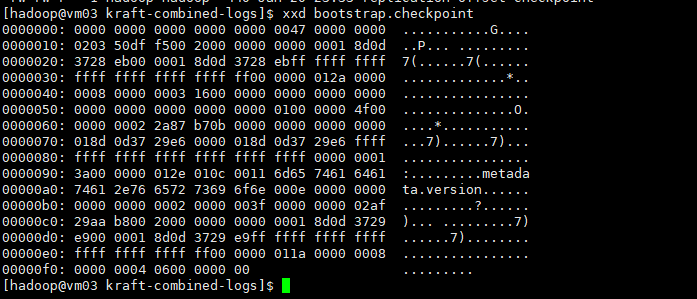
bootstrap.checkpoint:该文件与 Kafka 启动过程相关,可能包含有关启动过程状态或进度的信息。该文件为十六进制,使用xxd 进行查看
cleaner-offset-checkpoint:该文件存储由日志清理器使用的偏移量,表示它已清理的日志段的位置。日志清理器负责从日志段中删除过时的消息。默认情况下每隔10分钟会触发一次checkpoint
__cluster_metadata-0:此目录与集群元数据相关,主要是元数据得flush相关信息
__consumer_offsets-0, __consumer_offsets-12, …:
这些目录用于存储消费者组的偏移量。每个目录代表一个用于存储消费者组偏移量的分区。
KafkaText-0, KafkaText-2, …:
这些目录与 Kafka 主题相关。每个目录代表指定主题(例如,KafkaText)的一个分区,其中包含实际数据/消息的日志段。
log-start-offset-checkpoint:
该文件包含分区中第一条消息的偏移量。它表示从分区中读取消息的起始点。
meta.properties:
该文件包含 Kafka 本broker的属性。
recovery-point-offset-checkpoint:
该文件存储由所有同步副本完全复制并确认的最后一条消息的偏移量。在恢复期间,用于确定复制的起始点。
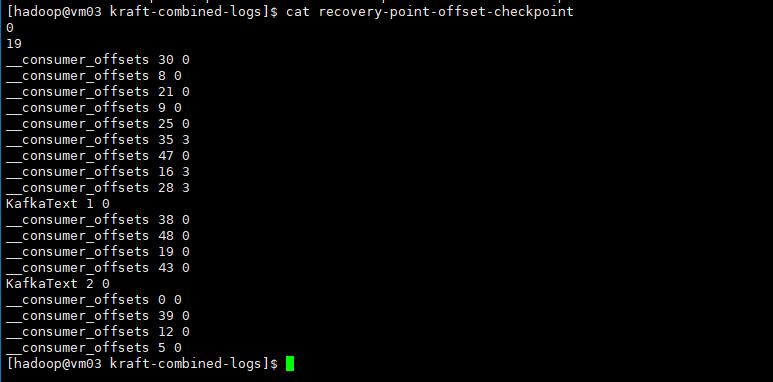
第一行的 0:
表示 __consumer_offsets 分区 0 的复制状态的起始点。
第二行的 19:
表示 __consumer_offsets 分区 19 的复制状态的恢复点偏移量。即,表示 __consumer_offsets 分区 19 已成功复制并确认的最后一个消息的偏移量。
从第三行开始的内容:
每一行表示一个分区的信息,包括分区名、复制状态的起始点和恢复点偏移量。
例如,__consumer_offsets 30 0 表示 __consumer_offsets 分区 30 的复制状态,起始点偏移量为 0,恢复点偏移量也为 0。
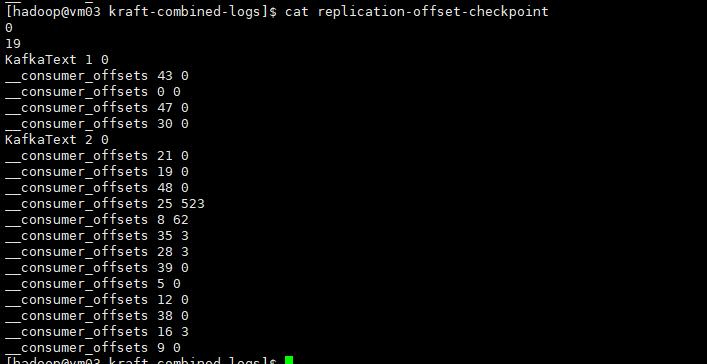
replication-offset-checkpoint:
该文件存储分区的高水位偏移量。它表示最后一条成功复制的消息的偏移量。这些文件和目录对于 Kafka 的正常运行非常重要,它们存储有关主题、消费者组偏移量、日志清理和复制等方面的各种元数据和信息。
第一行的 0:表示 __consumer_offsets 分区 0 的复制状态的起始点。
第二行的 19:表示 __consumer_offsets 分区 19 的复制状态的高水位偏移量。即,表示 __consumer_offsets 分区 19 已成功复制并确认的最后一个消息的偏移量。
从第三行开始的内容:每一行表示一个分区的复制状态,包括分区名和高水位偏移量。
例如,__consumer_offsets 43 0 表示 __consumer_offsets 分区 43 的复制状态,高水位偏移量为 0。
KafkaText 0 9 表示 KafkaText 分区 0 的复制状态,高水位偏移量为 9。
写了这么多,全是指令代码。大家肯定觉得很麻烦,如果有一款可可视化工具就好了。以下推荐给大家两款软件。
kafka可视化工具
kafka tool
http://www.kafkatool.com/download.html
目前对于仅支持到kafka3.6版本,必须是zookeeper集群管理下才可以支持,如果使用得kraft集群管理,将无法使用。
kafka-ui-lite
称为史上最轻便好用的kafka ui界面客户端工具,可以在生产消息、消费消息、管理topic、管理group;可以支持管理多个kafka集群
部署简便,可以一键启动,不需要配置数据库、不需要搭建web容器
支持zookeeper ui界面化操作;支持多环境管理
支持redis ui界面化操作;支持多环境管理
支持权限控制,可以自定义不同环境的新增、修改、删除权限;默认分配只读权限,避免用户的误操作
kafka ui
https://github.com/provectus/kafka-ui/releases
是github上的高星开源工具,使用jar打包,可应用在docker环境和非docker环境。
安装kafka-ui ,需要以下依赖
java 17 package or newer
git installed
docker installed
java 17是必备项目
将kafka-ui部署在非kafka集群节点
without docker环境下安装演示
安装JDK17
wget https://download.oracle.com/java/17/latest/jdk-17_linux-x64_bin.tar.gz
解压
tar -zxf jdk-17_linux-x64_bin.tar.gz
替换到当前jdk8文件
[root@vm08 jdk]# ll
total 0
drwxr-xr-x. 9 root root 136 Jan 20 22:31 jdk-17.0.10
drwxr-xr-x. 8 10 143 255 Jul 22 2017 jdk1.8.0_144
drwxr-xr-x. 8 root root 255 Jan 20 22:23 jdk1.8.0_144_bak
[root@vm08 jdk]# rm -rf jdk1.8.0_144
[root@vm08 jdk]# mv jdk-17.0.10/ jdk1.8.0_144
[root@vm08 jdk]# java -version
java version "17.0.10" 2024-01-16 LTS
Java(TM) SE Runtime Environment (build 17.0.10+11-LTS-240)
Java HotSpot(TM) 64-Bit Server VM (build 17.0.10+11-LTS-240, mixed mode, sharing)
安装kafka-ui
wget https://github.com/provectus/kafka-ui/releases/download/v0.7.1/kafka-ui-api-v0.7.1.jar
创建启动配置文件
vim application.yml
根据个人情况,修改相应的节点信息
kafka:
clusters:
- name: kafka_cluster
bootstrapServers: 10.0.0.102:9092,10.0.0.103:9092,10.0.0.104:9092
metrics:
port: 9094
type: JMX
##配置该集群的 JMX 相关配置,如果没有可省略。(在启动 kafka 时,启动命令行前面添加 JMX_PORT=9094 )
##使用kraft集群管理,不需要再配置zookeeper信息
##如何管理多套集群,只需在本目录继续增加name不同的kafka相关信息
spring:
jmx:
enabled: true
security:
user:
name: vm
password: vm
##web的登录用户和密码
auth:
type: LOGIN_FORM #LOGIN_FORM # DISABLED
server:
port: 10000
##web端口启用端口信息
logging:
level:
root: INFO
com.provectus: INFO
reactor.netty.http.server.AccessLog: INFO
management:
endpoint:
info:
enabled: true
health:
enabled: true
endpoints:
web:
exposure:
include: "info,health"
配置ip映射
vim /etc/hosts
##加入节点信息
10.0.0.102 vm02
10.0.0.103 vm03
10.0.0.104 vm04
启动kafka-ui
java -Dspring.config.additional-location=/home/hadoop/application.yml \
--add-opens java.rmi/javax.rmi.ssl=ALL-UNNAMED -jar kafka-ui-api-v0.7.1.jar
出现以上页面说明kafka-ui启动成功
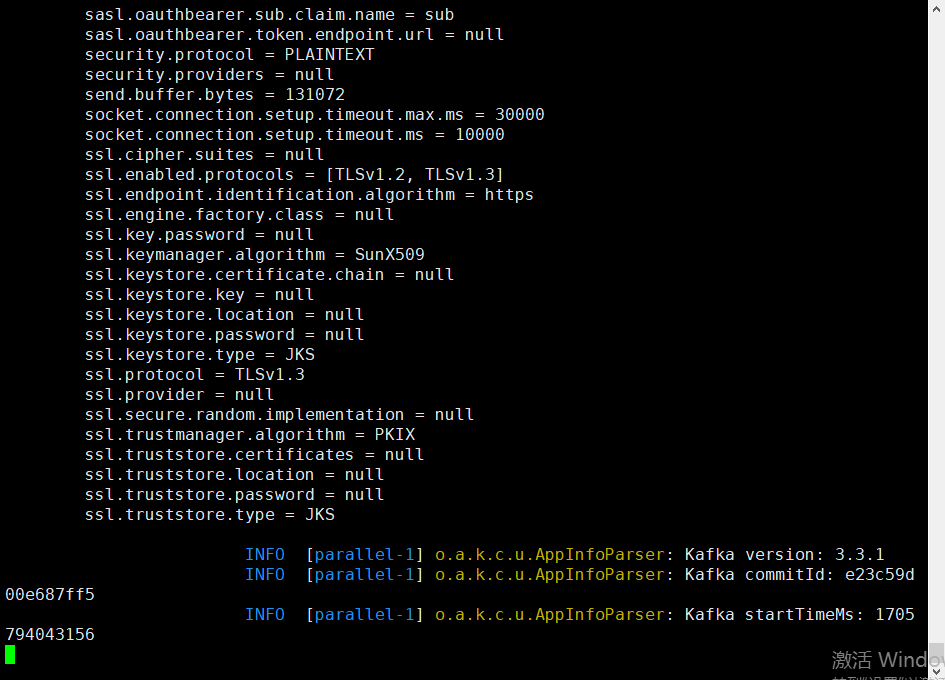
出现以上页面说明kafka集群链接成功
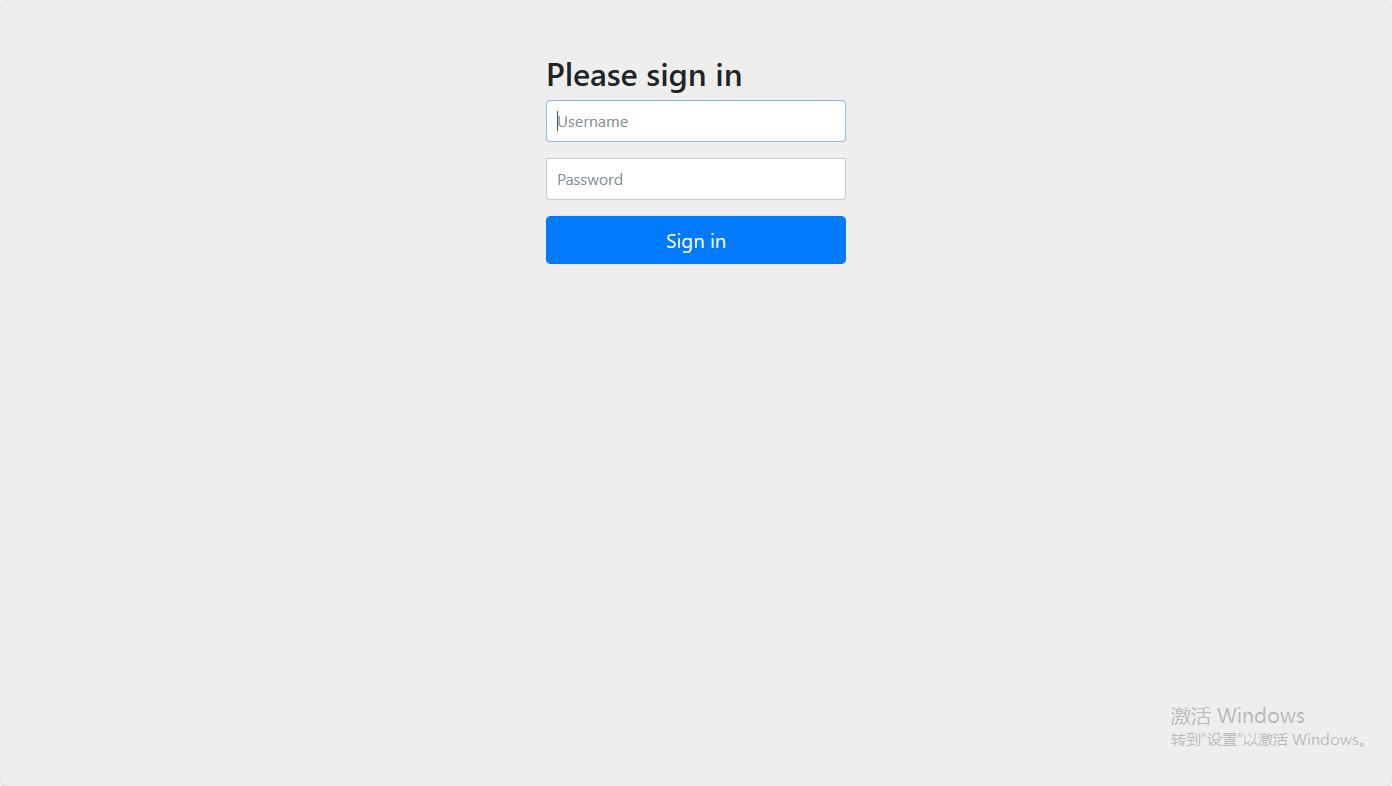
使用配置文件中的name/password 进行登录
spring:
jmx:
enabled: true
security:
user:
name: vm
password: vm
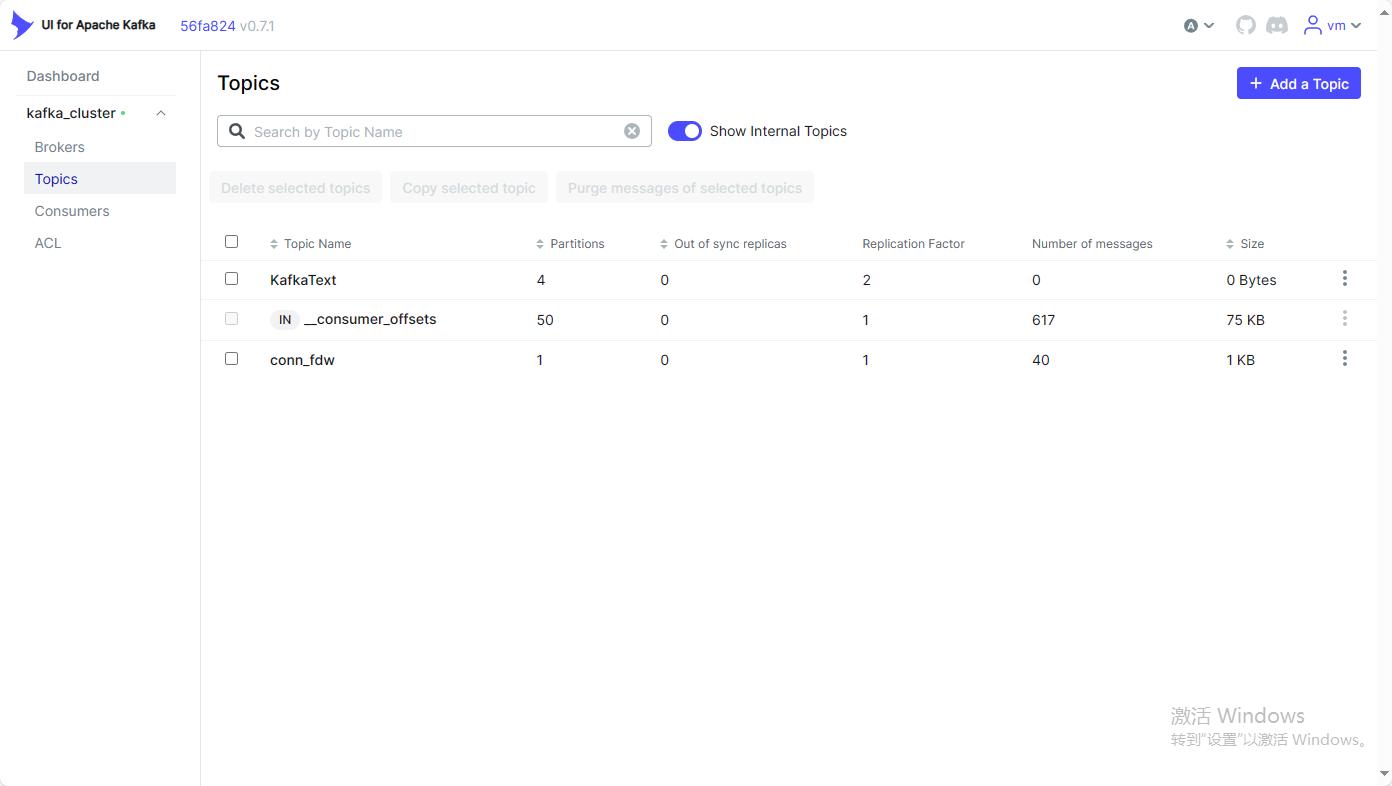
登录到对应的页面可以查看相应的broker/topic/consumers/tcl等相关信息。
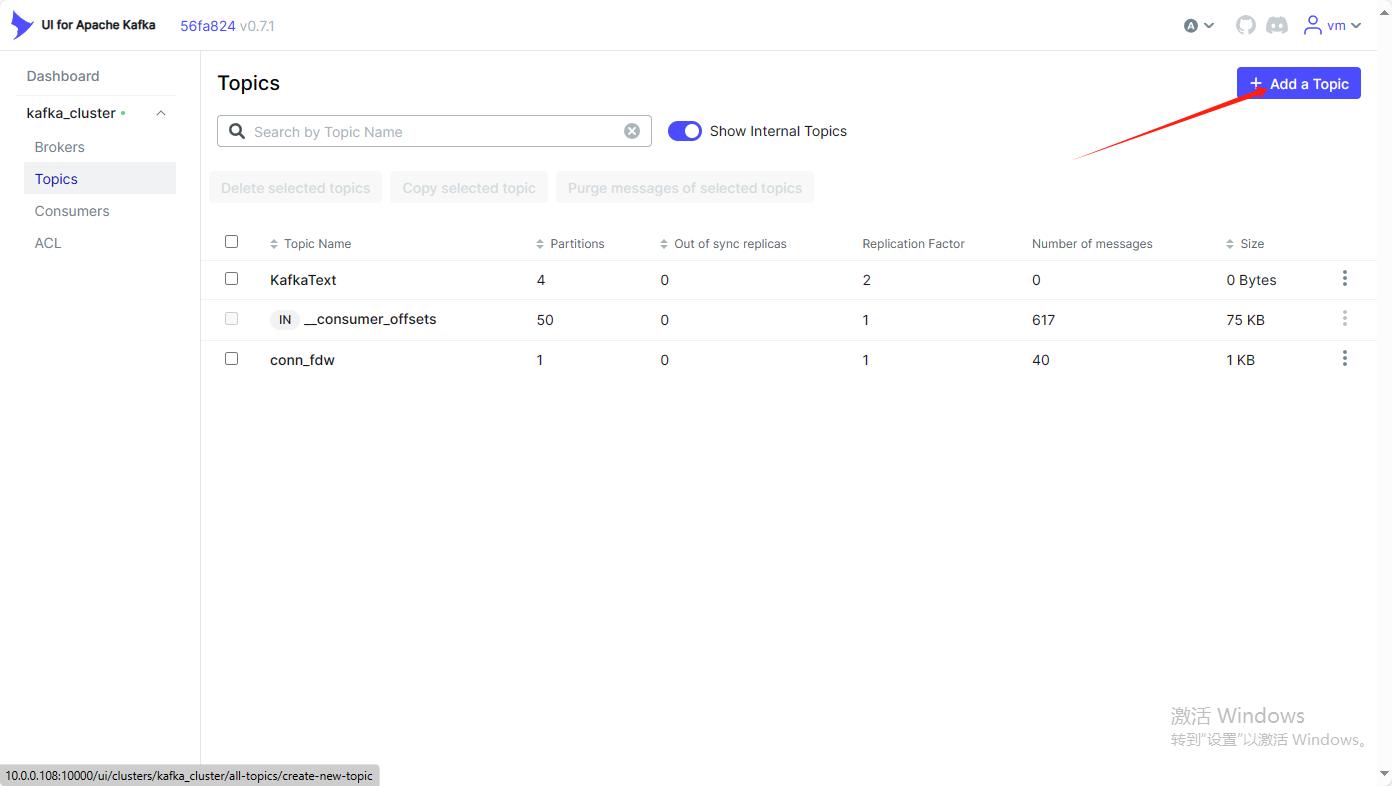
该页面可以执行创建topic等相关操作
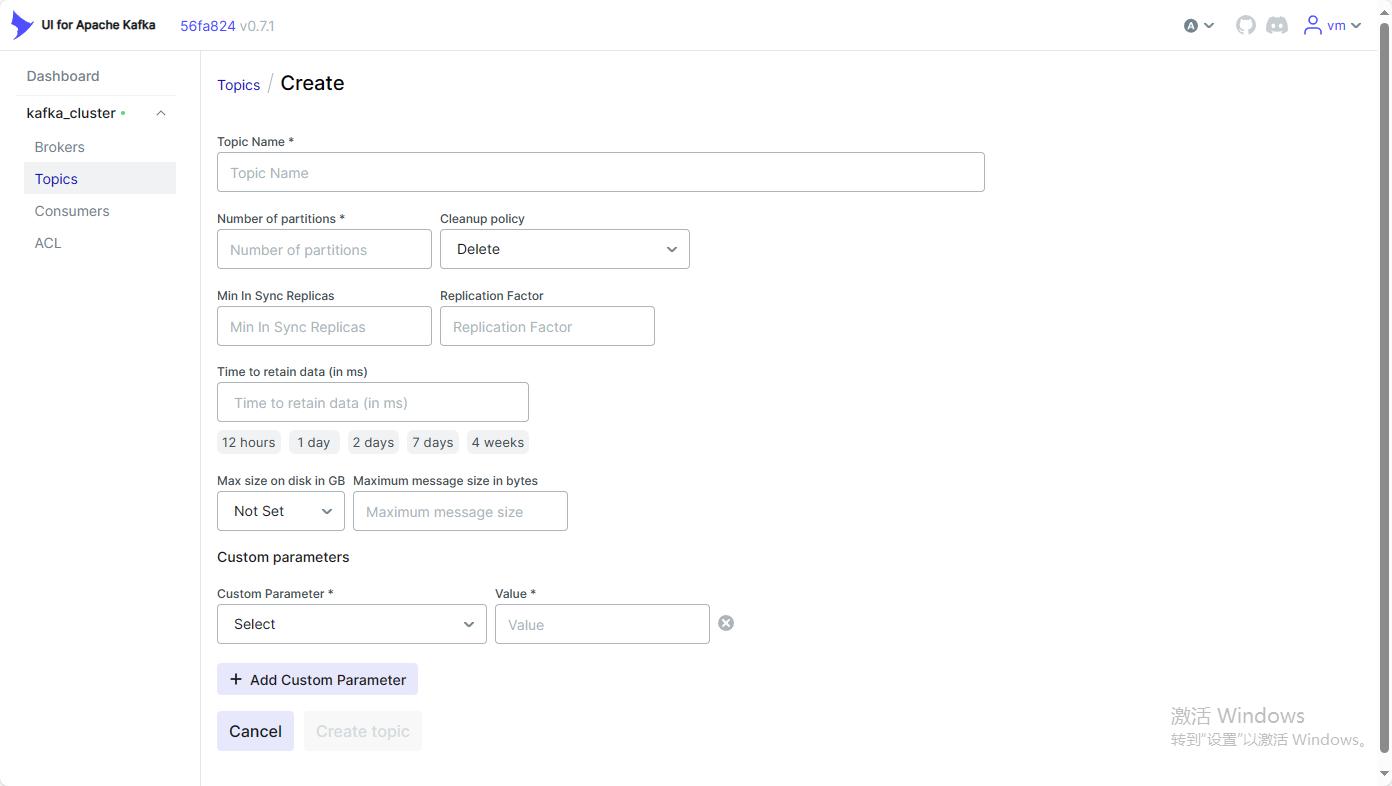
合理使用工具 对于中间组件的学习会事半功倍。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!