快速玩转 Mixtral 8x7B MOE大模型!阿里云机器学习 PAI 推出最佳实践
作者:熊兮、贺弘、临在
Mixtral 8x7B大模型是Mixtral AI推出的基于decoder-only架构的稀疏专家混合网络(Mixture-Of-Experts,MOE)开源大语言模型。这一模型具有46.7B的总参数量,对于每个token,路由器网络选择八组专家网络中的两组进行处理,并且将其输出累加组合,在增加模型参数总量的同时,优化了模型推理的成本。在大多数基准测试中,Mixtral 8x7B模型与Llama2 70B和GPT-3.5表现相当,因此具有很高的使用性价比。
阿里云人工智能平台PAI是面向开发者和企业的机器学习/深度学习平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务。
本文介绍如何在PAI平台针对Mixtral 8x7B大模型的微调和推理服务的最佳实践,助力AI开发者快速开箱。以下我们将分别展示具体使用步骤。
使用PAI-DSW轻量化微调Mixtral 8x7B MOE大模型
PAI-DSW是云端机器学习开发IDE,为用户提供交互式编程环境,同时提供了丰富的计算资源。我们在智码实验室(智码实验室)Notebook Gallery中上线了两个微调Mixtral 8x7B MOE大模型的示例,参见下图:
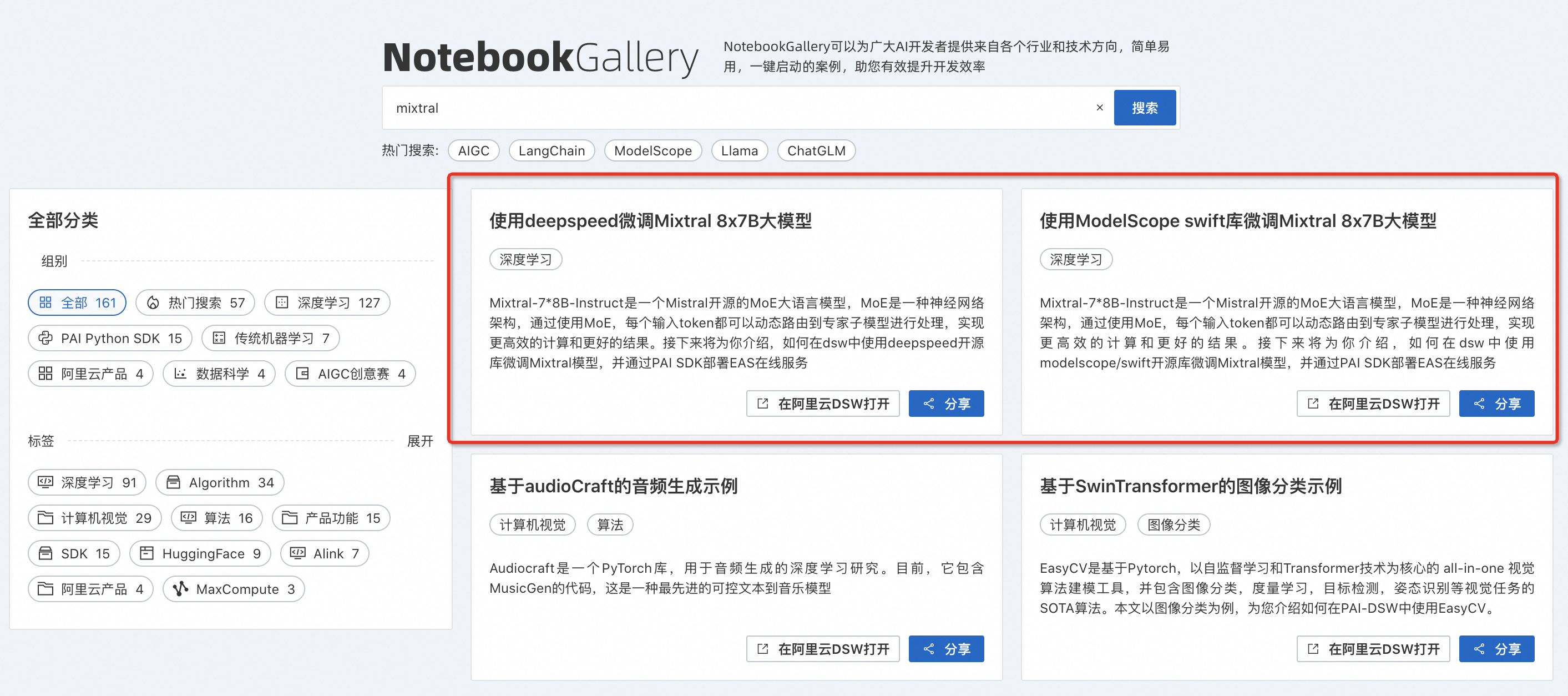
上述Notebook可以使用阿里云PAI-DSW的实例打开,并且需要选择对应的计算资源和镜像。
使用Swift轻量化微调Mixtral 8x7B MOE大模型
Swift是魔搭ModelScope开源社区推出的轻量级训练推理工具开源库,使用Swift进行这一大模型LoRA轻量化微调需要使用2张A800(80G)及以上资源。在安装完对应依赖后,我们首先下载模型至本地:
!apt-get update
!echo y | apt-get install aria2
def aria2(url, filename, d):
!aria2c --console-log-level=error -c -x 16 -s 16 {url} -o {filename} -d {d}
mixtral_url = "http://pai-vision-data-inner-wulanchabu.oss-cn-wulanchabu-internal.aliyuncs.com/mixtral/Mixtral-8x7B-Instruct-v0.1.tar"
aria2(mixtral_url, mixtral_url.split("/")[-1], "/root/")
!cd /root && mkdir -p AI-ModelScope
!cd /root && tar -xf Mixtral-8x7B-Instruct-v0.1.tar -C /root/AI-ModelScope
import os
os.environ['MODELSCOPE_CACHE']='/root'当模型下载完毕后,我们使用Swift一键拉起训练任务:
!cd swift/examples/pytorch/llm && PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0,1 \
python llm_sft.py \
--model_id_or_path AI-ModelScope/Mixtral-8x7B-Instruct-v0.1 \
--model_revision master \
--sft_type lora \
--tuner_backend swift \
--dtype AUTO \
--output_dir /root/output \
--ddp_backend nccl \
--dataset alpaca-zh \
--train_dataset_sample 100 \
--num_train_epochs 2 \
--max_length 2048 \
--check_dataset_strategy warning \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0.05 \
--lora_target_modules ALL \
--batch_size 1 \
--weight_decay 0.01 \
--learning_rate 1e-4 \
--gradient_accumulation_steps 16 \
--max_grad_norm 0.5 \
--warmup_ratio 0.03 \
--eval_steps 300 \
--save_steps 300 \
--save_total_limit 2 \
--logging_steps 10 \
--only_save_model true \
--gradient_checkpointing false模型训练完成后,我们将学习到的LoRA权重合并到模型Checkpoint中:
!swift merge-lora --ckpt_dir '/root/output/mistral-7b-moe-instruct/v3-20231215-111107/checkpoint-12'其中,ckpt_dir参数的值需要替换成模型LoRA权重保存路径。为了测试模型训练的正确性,我们可以使用transformers库进行离线推理测试:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "/root/output/mistral-7b-moe-instruct/v3-20231215-111107/checkpoint-12-merged"
tokenizer = AutoTokenizer.from_pretrained(model_id, device_map='auto')
model = AutoModelForCausalLM.from_pretrained(model_id, device_map='auto')
text = """[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
写一首歌的过程从开始到结束。 [/INST]"""
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=512)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))使用Deepspeed轻量化微调Mixtral 8x7B MOE大模型
我们也可以使用Deepspeed对Mixtral 8x7B MOE大模型进行LoRA轻量化微调。同样的,我们需要使用2张A800(80G)及以上资源。我们首先下载模型至本地:
!apt-get update
!echo y | apt-get install aria2
def aria2(url, filename, d):
!aria2c --console-log-level=error -c -x 16 -s 16 {url} -o {filename} -d {d}
mixtral_url = "http://pai-vision-data-inner-wulanchabu.oss-cn-wulanchabu-internal.aliyuncs.com/mixtral/Mixtral-8x7B-Instruct-v0.1.tar"
aria2(mixtral_url, mixtral_url.split("/")[-1], "/root/")
!cd /root && tar -xf Mixtral-8x7B-Instruct-v0.1.tar第二步,我们下载一个示例古诗生成数据集,用户可以根据下述数据格式准备自己的数据集。
!wget -c https://pai-quickstart-predeploy-hangzhou.oss-cn-hangzhou.aliyuncs.com/huggingface/datasets/llm_instruct/en_poetry_train_mixtral.json
!wget -c https://pai-quickstart-predeploy-hangzhou.oss-cn-hangzhou.aliyuncs.com/huggingface/datasets/llm_instruct/en_poetry_test_mixtral.json第三步,我们可以修改示例命令的超参数,并且拉起训练任务。
!mkdir -p /root/output
!deepspeed /ml/code/train_sft.py \
--model_name_or_path /root/Mixtral-8x7B-Instruct-v0.1/ \
--train_path en_poetry_train_mixtral.json \
--valid_path en_poetry_test_mixtral.json \
--learning_rate 1e-5 \
--lora_dim 32 \
--max_seq_len 256 \
--model mixtral \
--num_train_epochs 1 \
--per_device_train_batch_size 8 \
--zero_stage 3 \
--gradient_checkpointing \
--print_loss \
--deepspeed \
--output_dir /root/output/ \
--offload当训练结束后,我们拷贝额外配置文件至输出文件夹:
!cp /root/Mixtral-8x7B-Instruct-v0.1/generation_config.json /root/output
!cp /root/Mixtral-8x7B-Instruct-v0.1/special_tokens_map.json /root/output
!cp /root/Mixtral-8x7B-Instruct-v0.1/tokenizer.json /root/output
!cp /root/Mixtral-8x7B-Instruct-v0.1/tokenizer.model /root/output
!cp /root/Mixtral-8x7B-Instruct-v0.1/tokenizer_config.json /root/output我们同样可以使用transformers库进行离线推理测试:
import os
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "/root/output/"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,device_map='auto',torch_dtype=torch.float16)
text = """[INST] Write a poem on a topic 'Care for Thy Soul as Thing of Greatest Price': [/INST]"""
inputs = tokenizer(text, return_tensors="pt").to('cuda')
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))如果用户需要将上述模型部署为EAS服务,需要将格式转换成safetensors格式:
state_dict = model.state_dict()
model.save_pretrained(
model_id,
state_dict=state_dict,
safe_serialization=True)使用PAI-EAS在线部署Mixtral 8x7B MOE大模型
PAI-EAS是PAI平台推出的弹性推理服务,可以将各种大模型部署为在线服务。当Mixtral 8x7B MOE大模型微调完毕后,我们可以将其部署为PAI-EAS服务。这里,我们介绍使用PAI-SDK将上述模型进行部署。首先,我们在PAI-DSW环境安装PAI-SDK:
!python -m pip install alipai --upgrade在安装完成后,在在命令行终端上执行以下命令,按照引导完成配置AccessKey、PAI工作空间以及 OSS Bucket:
python -m pai.toolkit.config我们将训练好的模型上传至OSS Bucket。在下述命令中,source_path为模型Checkpoint保存的本地路径,oss_path为上传至OSS的目标路径:
import pai
from pai.session import get_default_session
from pai.common.oss_utils import upload
print(pai.__version__)
sess = get_default_session()
# 上传模型到默认的Bucket
model_uri = upload(
source_path="/root/output",
oss_path="mixtral-7b-moe-instruct-sft-ds"
)
print(model_uri)PAI 提供了Mixtral 8X7B MOE 模型部署镜像和部署代码,用户可以通过相应的部署配置,将微调后的模型部署到PAI-EAS。
from pai.model import RegisteredModel
from pai.predictor import Predictor
# 获取PAI提供的Mixtral模型服务配置(目前仅支持乌兰察布)
inference_spec = RegisteredModel(
"Mixtral-8x7B-Instruct-v0.1",
model_provider="pai",
).inference_spec
# 修改部署配置,使用微调后的模型
infer_spec.mount(model_uri, model_path="/model")
# 部署推理服务服务
m = Model(inference_spec=infer_spec)
predictor: Predictor = m.deploy(
service_name = 'mixtral_sdk_example_ds',
options={
"metadata.quota_id": "<ResourceGroupQuotaId>",
"metadata.quota_type": "Lingjun",
"metadata.workspace_id": session.workspace_id
}
)以上配置项中,metadata.quota_id是用户购买的灵骏资源配额ID,在购买了灵骏资源之后,用户可以从PAI控制台页面的资源配额入口获取相应的信息。
部署的模型可以通过deploy方法返回的Predictor对象进行调用。模型使用的Prompt模版如下,其中[INST]和[/INST]之间的是用户输入,Prompt输入需要按相应的格式准备,避免模型生成低质量的结果。
<s> [INST] User Instruction 1 [/INST] Model answer 1</s> [INST] User instruction 2 [/INST]调用部署服务的示例代码如下:
# 格式化输入Prompt
def prompt_format(instructions: List[Dict[str, str]]):
prompt = ["<s>"]
for user, assistant in zip(instructions[::2], instructions[1::2]):
inst = user["content"].strip()
resp = assistant["content"]
prompt.append(f"[INST] {inst} [/INST] {resp}</s>")
prompt.append(f"[INST] {instructions[-1]['content']} [/INST]")
return "".join(prompt)
# 获取模型产生的实际内容
def extract_output(text, prompt):
if prompt and text.startswith(prompt):
return text[len(prompt) :]
return text
prompt = prompt_format(
[
{
"role": "user",
"content": "Who are you?",
},
]
)
res = predictor.raw_predict(
path="/generate",
data=json.dumps(
{
"prompt": prompt,
"use_beam_search": False,
"stream": False,
"n": 1,
"temperature": 0.0,
"max_tokens": 860,
}
),
)
print(extract_output(res.json()["text"][0], prompt))
# Hello! I am a large language model trained by Mistral AI. I am designed to generate human-like text based on the input I receive. I do not have personal experiences or emotions, but I can provide information, answer questions, and engage in conversation to the best of my abilities. How can I assist you today?
流式推理能够提高大语言模型推理服务的响应效率,处理长文本的问题。通过配置参数stream:True,可以使服务以流式响应推理结果:
# API 请求路径
url = predictor.internet_endpoint + "/generate"
# 推理服务的Token
access_token = predictor.access_token
prompt = prompt_format(
[
{
"role": "user",
"content": "Explain the meaning of life.",
},
]
)
res = requests.post(
url=url,
headers={
"Authorization": access_token,
},
json={
"prompt": prompt,
"use_beam_search": False,
# 服务端:以流式返回推理结果
"stream": True,
"n": 1,
"temperature": 0.0,
"max_tokens": 860,
},
# 客户端:以流式处理响应结果
stream=True,
)
for chunk in res.iter_lines(chunk_size=8192, delimiter=b"\0"):
if not chunk:
continue
print(extract_output(json.loads(chunk)["text"][0], prompt))
# Hello
# Hello!
# Hello! I
# Hello! I am
# Hello! I am a
# Hello! I am a large
# Hello! I am a large language
# Hello! I am a large language model
# Hello! I am a large language model trained
# Hello! I am a large language model trained by
# Hello! I am a large language model trained by Mist
# Hello! I am a large language model trained by Mistral
# Hello! I am a large language model trained by Mistral AI
# Hello! I am a large language model trained by Mistral AI.
使用PAI-QuickStart微调和部署Mixtral 8x7B MOE大模型
快速开始(PAI-QuickStart)集成了国内外AI开源社区中优质的预训练模型,支持零代码或是SDK的方式实现微调和部署Mixtral 8x7B MOE大模型,用户只需要格式准备训练集和验证集,填写训练时候使用的超参数就可以一键拉起训练任务。Mixtral的模型卡片如下图所示:
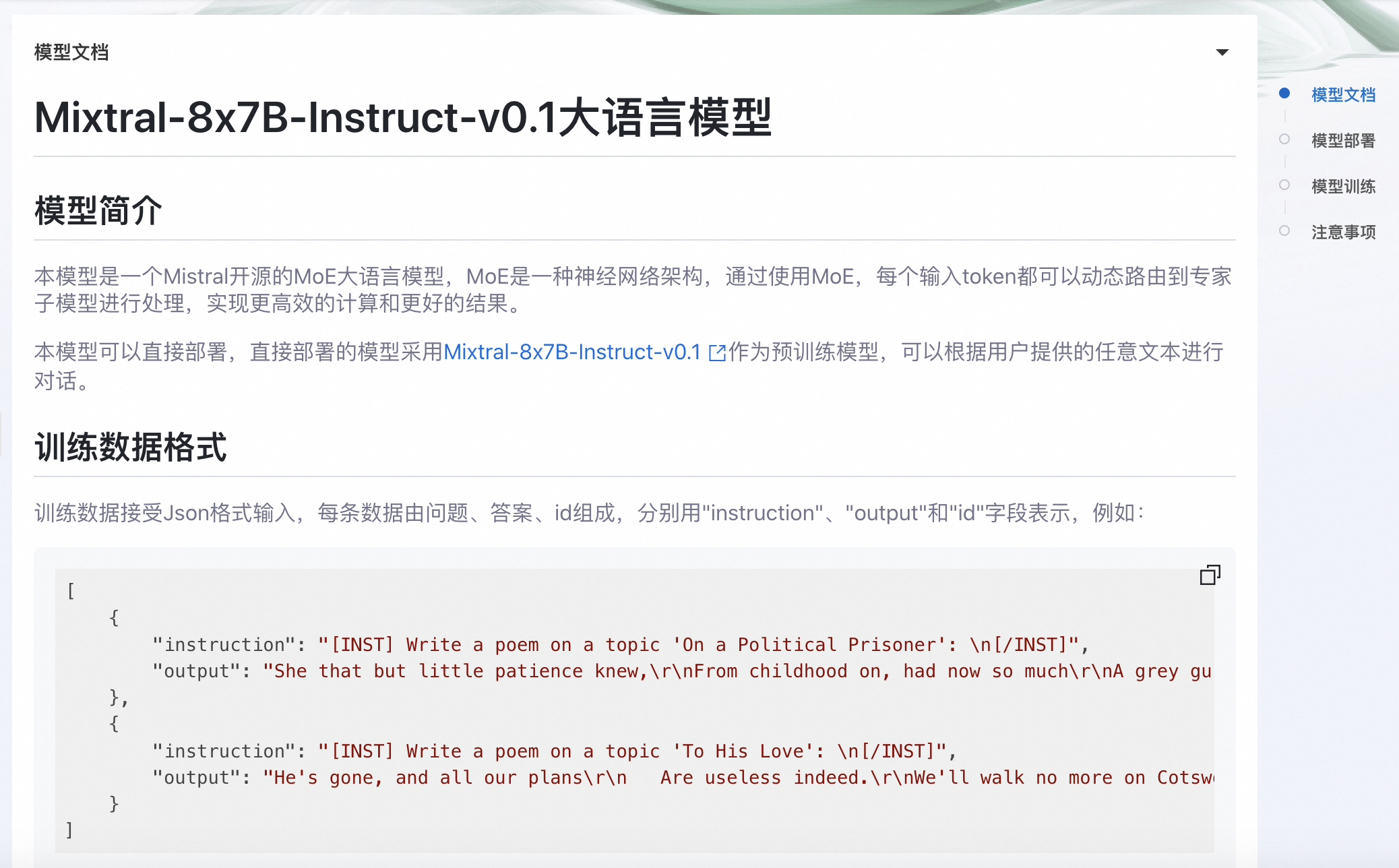
通过控制台使用
我们可以根据实际需求上传训练集和验证集,调整超参数,例如learning_rate、sequence_length、train_iters等,如下所示:
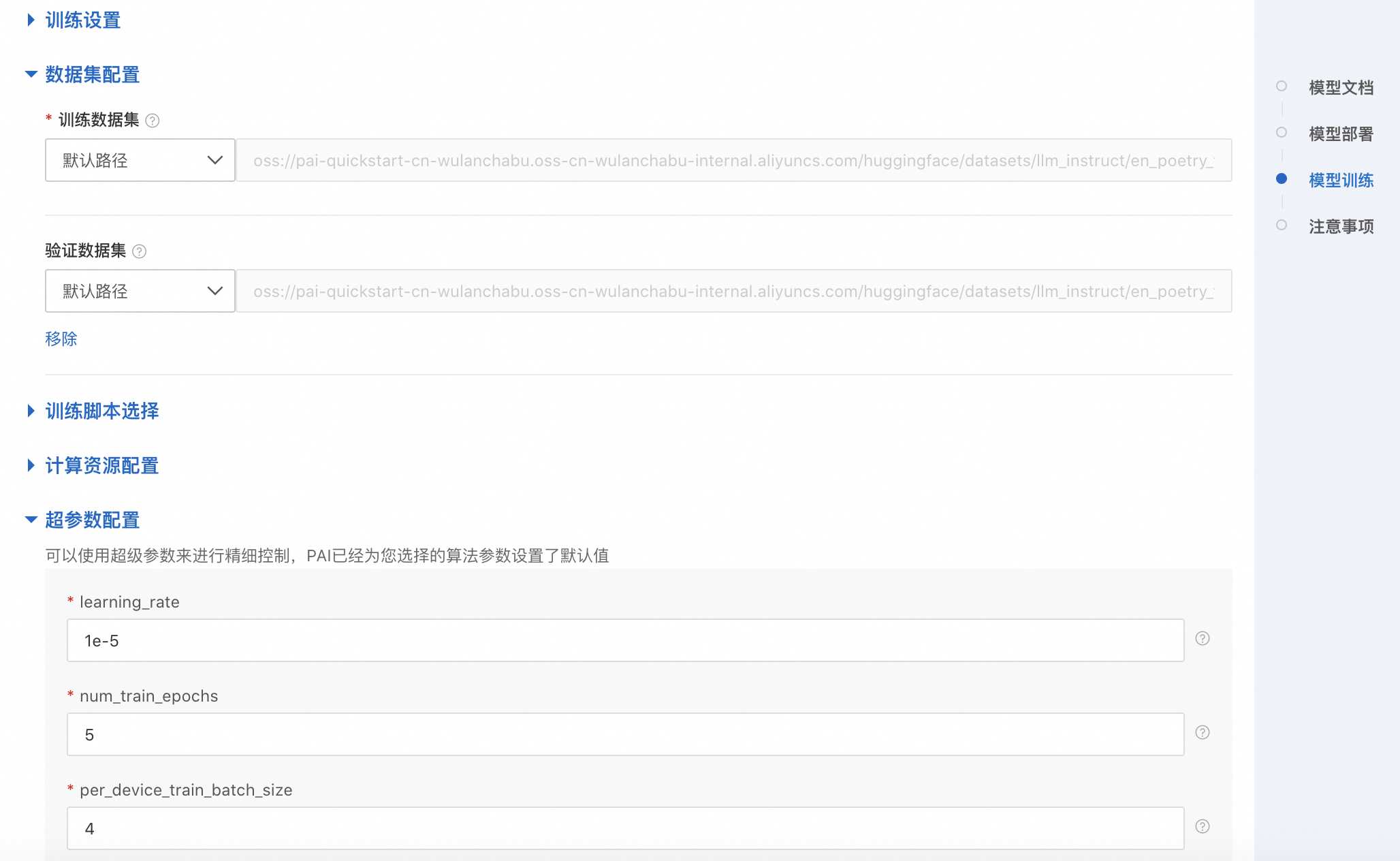
点击“训练”按钮,PAI-QuickStart开始进行训练,用户可以查看训练任务状态和训练日志,如下所示:
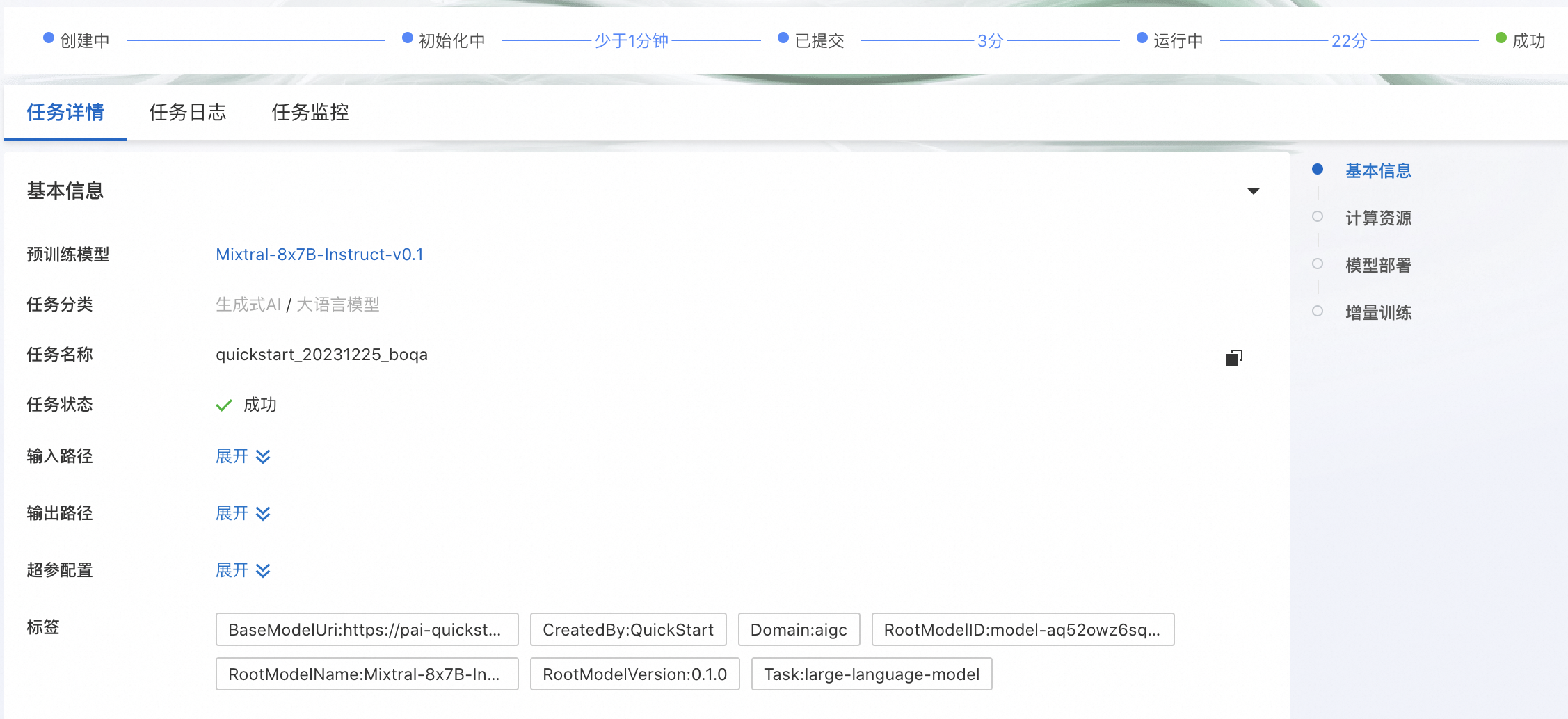
如果需要将模型部署至PAI-EAS,可以在同一页面的模型部署卡面选择资源组,并且点击“部署”按钮实现一键部署。模型调用方式和上文PAI-EAS调用方式相同。
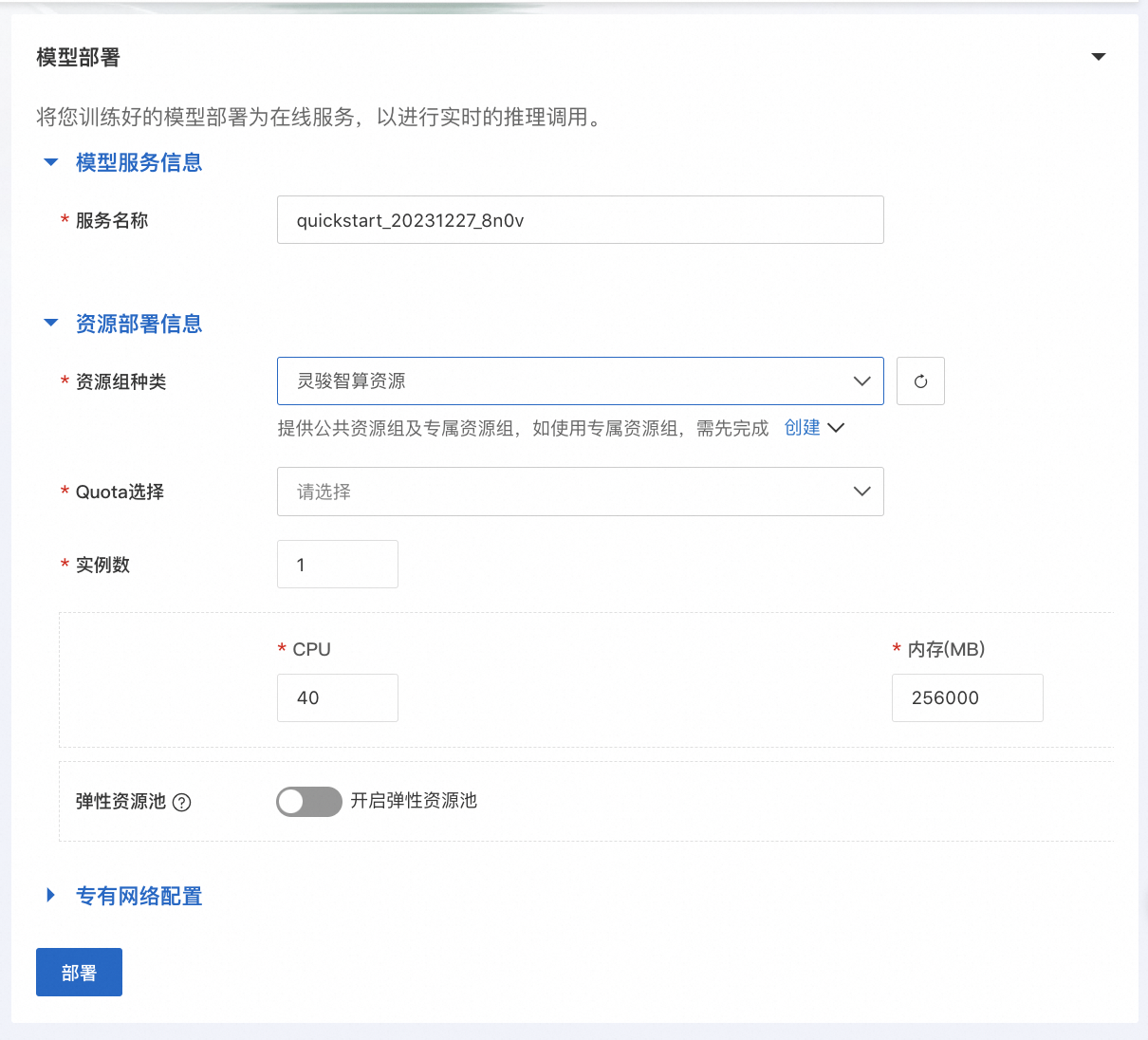
通过PAI Python SDK使用
开发者也可以通过PAI Python SDK调用PAI提供的预训练模型。通过模型上配置的微调训练算法,开发者可以轻松得提交一个微调训练任务。
from pai.model import RegisteredModel
# 获取PAI提供的预训练模型
m = RegisteredModel(
"Mixtral-8x7B-Instruct-v0.1",
model_provider="pai",
)
# 获取模型的微调训练算法
est = m.get_estimator(
# 灵骏资源组资源配额ID
resource_id="<LingjunResourceQuotaId>",
# 训练超参
hyperparameters={
"learning_rate": 1e-5,
"num_train_epochs": 1,
"per_device_train_batch_size": 4,
},
)
# 获取训练输入数据:包括模型,以及测试使用的公共数据集
inputs = m.get_estimator_inputs()
# 提交训练作业,等待作业完成
est.fit(
inputs=inputs
)
# 查看模型的输出路径
print(est.model_data())通过模型上预置的推理服务配置,开发者仅需指定机器资源配置,即可部署一个推理服务。推理服务的调用请参考以上的 PAI-EAS 部署推理的章节。
from pai.session import get_default_session
from pai.model import RegisteredModel
session = get_default_session()
m = RegisteredModel(
"Mixtral-8x7B-Instruct-v0.1",
model_provider="pai",
)
# 部署推理服务
predictor = m.deploy(
service_name="mixtral_example_{}".format(random_str(6)),
options={
# 资源配额ID
"metadata.quota_id": "<ResourceGroupQuotaId>",
"metadata.quota_type": "Lingjun",
"metadata.workspace_id": session.workspace_id,
}
)
print(predictor.internet_endpoint)
用户可以查看文档,了解更多如何通过SDK使用PAI提供的预训练模型:使用预训练模型 — PAI Python SDK。
当测试完成,需要删除服务释放资源,用户可以通过控制台或是SDK完成:
# 删除服务
predictor.delete_service()本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JavaScript:节流&防抖
- 基于Java (spring-boot)的停车场管理系统
- SpringIOC之support模块MessageSourceSupport
- 17. 常用类
- Leetcode 509 斐波那契数
- WINDOW系统添加IP黑名单
- 系统学习Python——警告信息的控制模块warnings:警告过滤器-[基础知识]
- t2017030921字母矩阵
- 极智芯 | 解读自动驾驶芯片之英特尔Mobileye EyeQ系列
- vue中样式动态绑定写法