CLIP论文总结
文章目录
NLP的积淀
取之不尽用之不竭的自监督信号 = transformer + 自监督学习
训练出来的模型又大又好,而且又简单,泛化性又好,为多模态的训练铺平了道路。
只需要图片文本对,不需要标注, 数据的规模就很容易大起来了。
现在的监督信号是一个文本,而不是n选1的这种标签了,所以模型的输入输出啊,自由度就大很多。
- 用文本监督信号,来帮助训练一个视觉模型 是非常有潜力的。
Method
1. 预训练的方法:放宽约束:对比学习
对比学习的目标函数 比 预测型的目标函数 训练效率提升了4倍
线性投射层,非线性投射层 对clip这种多模态没什么影响
数据增强:随机裁剪
把对比学习中的temperature这个超参数,设计为可学习的标量了,直接在模型训练过程中就被优化了,不需要当成一个超参数去调参
2. 模型训练
- 5种ResNet + 3中Vision Transformer(ViT-B/32, ViT-B/16, ViT-L/14)
- 32 epoch
- Adam optimizer with decoupled weight decay regularization
- Decay the learning rate using a cosine schedule
- Initial hyperparameters: combination of grid searches, random search, and manual tuning on the basline ResNet50 model when trained for 1 epoch. 为了调参调的快一点,做超参搜索的时候都是用最小的resnet50做的,都只训练了一个epoch。
- 超参数were then adapted heuristically for larger models due to computational constraints。对于更大的模型,这里就没有去调参了/
- 训练的时候batch-size是32768
- 混精度训练:加速训练,而且省内存
- 为了进一步节省内存,还尝试了gradient checkpointing, half-precision Adam statistics, half-precision stochastically rounded text encoder weights
- 计算相似度也是分配到不同的gpu去做的/
经过这么多工程上的优化,CLIP才能训练起来
OpenAI成员撰写:How to Train Really Large Models on Many GPUs?
训练时间
RN50x64: 18day 592 V100
Largest ViT: 12day 256 V100
就像vit论文中提到的:训练一个vit要比训练一个残差网络要高效
Trick: 在更大尺寸图片上finetune,从而获得性能提升
Experiments
Motivation
之前的自监督或者无监督的方法,主要研究的是特征学习的能力,他们的目标是学习一个泛化比较好的特征。
即使你学习到了很好的特征,当你运用到下游任务的时候,你还是需要有标签的数据去做微调。比如下游任务不好去收集数据,有distribution shift的问题。
如何能够训练一个模型,接下来就不再训练或者不再微调了呢?这就是作者研究zero-shot 迁移的动机
用文本做引导,去很灵活的做这种zero-shot的迁移学习。

- 一个图的特征与N个文本特征做cosine similarity,再计算softmax概率分布
- 文本端的编码不是按照顺序进行的,是批量进行的,所以clip的推理还是非常高效的,它并不会慢。
Prompt:提示:也就是文本的引导作用
- 为什么要做prompt engineering和prompt ensembling呢?
- polysemy(多义性):一个单词可以有很多含义。只用一个单词做特征抽取,就会有歧义性出现了。
- 预训练的时候使用的是句子和图片,所以推理的时候如果输入单个单词,会出现distribution gap
Prompt enginnering
- 提供模板 A photo of a {label}
- 如果你知道先验信息,你可以加上一些解释。A photo of a {label}, a type of pet
如果你想找ocr里面内容:把你想找的文字或数字加上双引号,他就会更明白你的意思了。他可能就知道,你就是想找双引号里面的内容了。
Prompt ensembling
多用一些这些推理的模板,然后把结果综合起来,ensemble一般都会给你更好的结果。
by the way, 作者用了80个ensembe的模板
Prompt_Engineering_for_ImageNet.ipynb
imagenet_templates = [
'a bad photo of a {}.',
'a photo of many {}.', 图中有许多...
'a sculpture of a {}.',
'a photo of the hard to see {}.', 比较小的物体
'a low resolution photo of the {}.',
'a rendering of a {}.',
'graffiti of a {}.',
'a bad photo of the {}.',
'a cropped photo of the {}.',
'a tattoo of a {}.',
'the embroidered {}.',
'a photo of a hard to see {}.',
'a bright photo of a {}.',
'a photo of a clean {}.',
'a photo of a dirty {}.',
.
.
.
数据集 -> 怎么选择模型 -> 怎么去做预训练 -> 怎么去做zero-shot推理
对比实验
作者在27个数据集上做了对比实验:
比较的双方:zero-shot clip; Linear Probe on ResNet50(是图片里面的基线)
clip 高于基线的就是绿色,反之蓝色的。
给物体进行分类的时候,clip一般表现都比较好
需要特定领域的知识来做分类的任务,可以用few-shot。

- 难的任务用few-shot来做
- BiT-M是一个很好的baseline
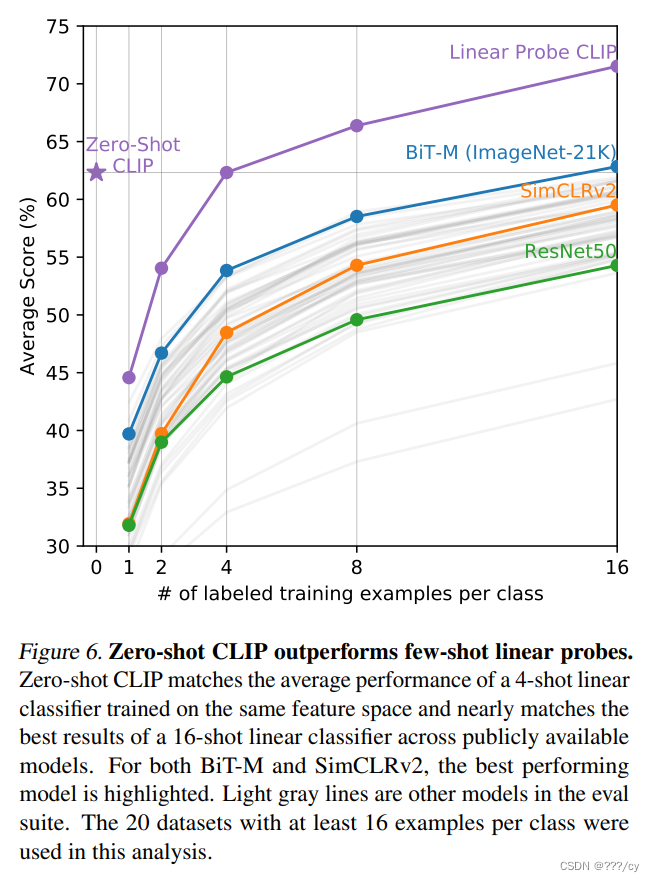
- BiT-M是一个很好的baseline
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Cookie与Session详解
- sub industry change radar 2024.1.9 with 字典
- 免费分享:全球滑坡点及滑坡区域数据集(附下载方法)
- Qt6.5示例:QMainWindow集成QMenuBar菜单栏
- 【LeetCode每日一题】410. 分割数组的最大值
- kubernetes Pod 容器 security context OPA(PSP替代方案)
- RabbitMQ--消息模型
- 如何将阿里通义千问大模型AI接入自己的项目里
- 航模遥控开关电路图大全
- Quartus的Signal Tap II的使用技巧