python爬虫进阶篇:scrapy爬虫框架的依赖库搭建和项目创建
发布时间:2023年12月20日
一、前言
上篇我们记录了Scrapy的各个组件功能,这篇我们来动手scrapy爬虫框架的依赖库搭建和项目创建,开始进入进阶实战。
二、环境搭建
- 安装依赖库
pip install lxml==4.9.2
pip install parsel==1.6.0
pip install Twisted==21.2.0
pip install pyOpenSSL==19.1.0
pip install cryptography==2.8
pip install Scrapy==1.6.0
以上依赖库是必须要安装的,否则启动Scrapy会报依赖包不存在的错;Scrapy的依赖包对版本要求比较严格,不同版本的依赖包经常会冲突,上面这些依赖包是测试过没有问题的。
三、创建Scrapy项目
- 创建一个爬虫项目文件夹scrapy_demo01
- 命令行进入此文件夹,执行命令:
scrapy startproject scrapy_demo
- 将第一层scrapy_demo文件夹设置为根目录(pycharm中右键此文件夹,Mark directory as Sources Root)

- 创建个spider_main.py文件,用于执行启动爬虫的命令
from scrapy import cmdline
if __name__ == '__main__':
cmdline.execute("scrapy crawl demo_spider".split())
- 最后的项目结构如下
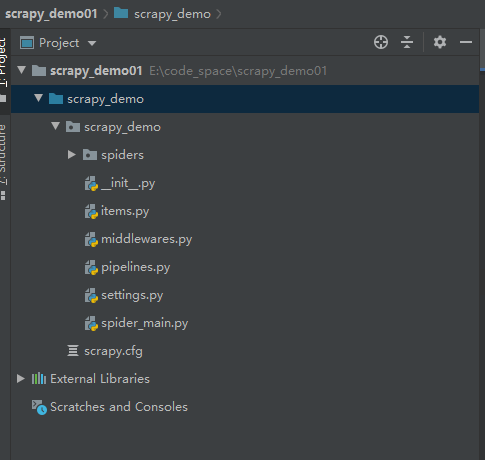
四、测试结果
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = "demo_spider"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = f'quotes-{page}.html'
with open(filename, 'wb') as f:
f.write(response.body)
self.log(f'Saved file {filename}')
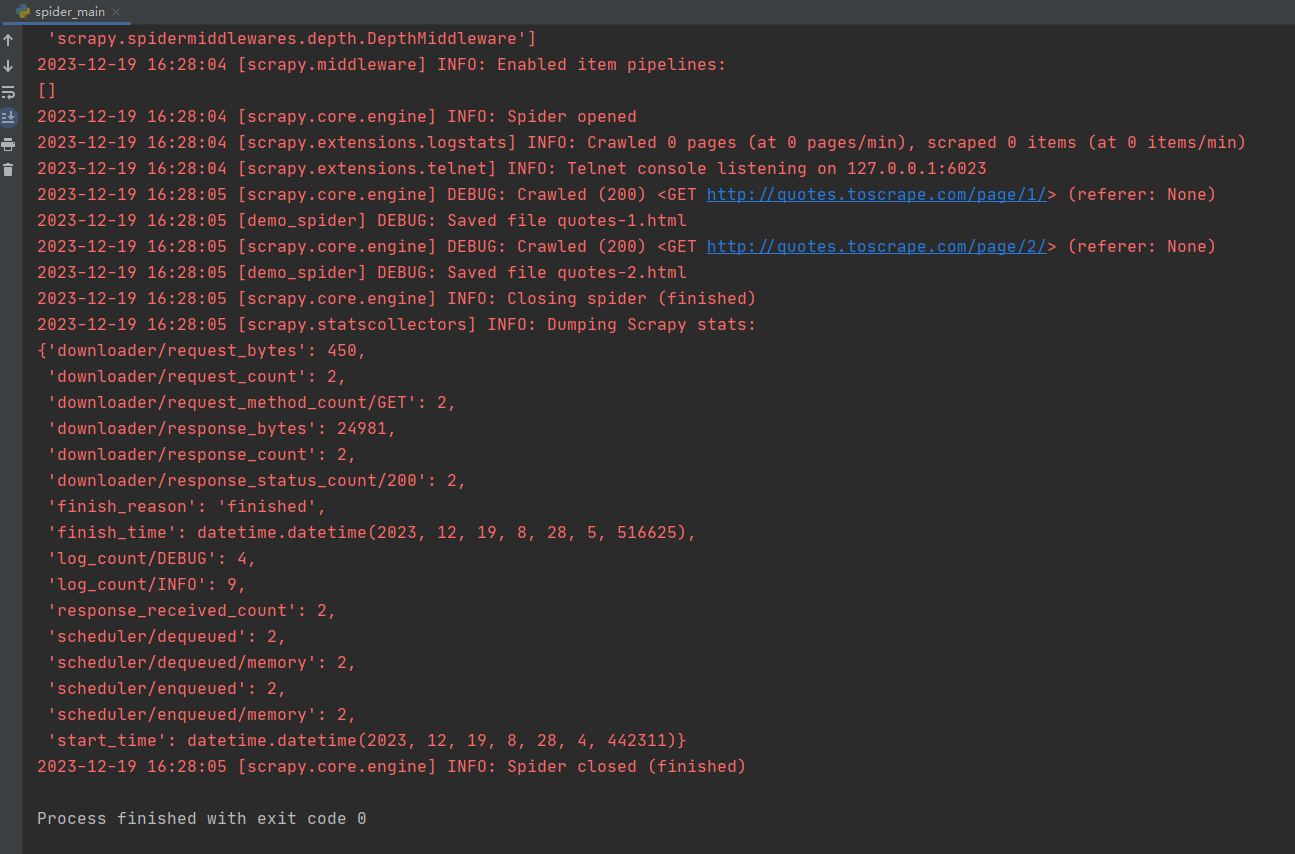
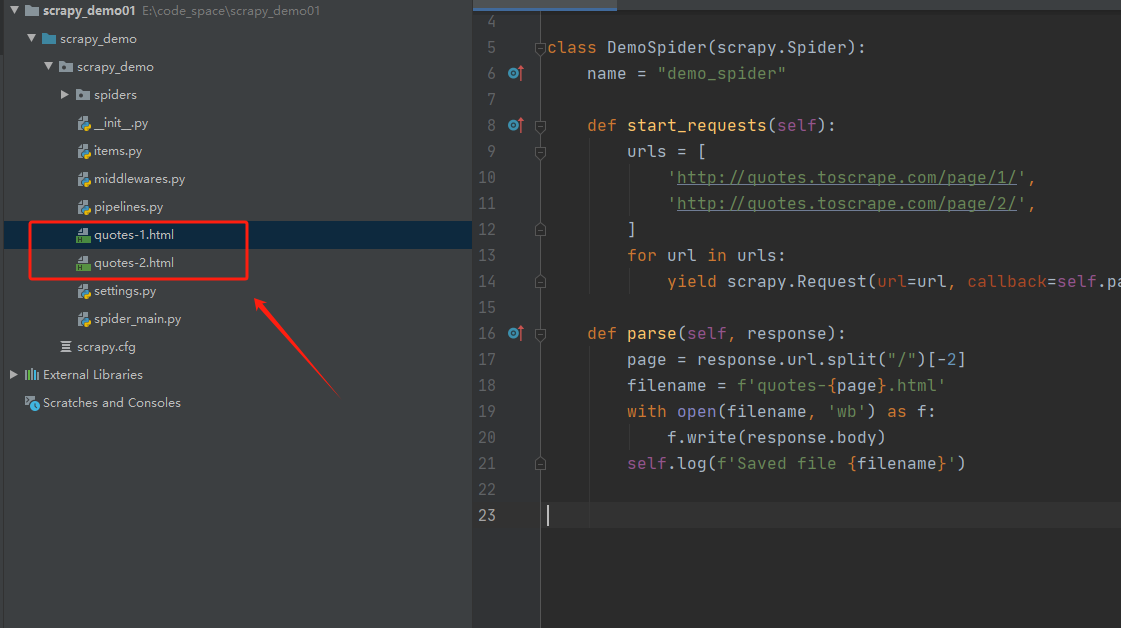
文章来源:https://blog.csdn.net/qq_23730073/article/details/135067499
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 别墅阁楼书房设计,引入自然光线打造空间艺术感。福州中宅装饰,福州装修
- 模块一——双指针:18.四数之和
- 方法-总和
- VS2017配置opencv记录
- 【KOA-CNN-LSTM-Multihead-Attention回归预测】基于开普勒算法优化多头注意力机制的卷积神经网络结合长短记忆神经网络实现温度预测附matlab代码
- 聊一聊 .NET高级调试 内核模式堆泄露
- 设计模式之(1)基础知识
- 计算机找不到iutils.dll的5种有效的解决方法,一分钟教会修复dll问题
- mysql原理--MySQL的数据目录
- cargo run 报错error: linking with `cc` failed: exit status: 1