selenium处理下拉框
发布时间:2024年01月19日
当想要爬取的数据由下拉框来选择时,应该如何处理?
页面如下:
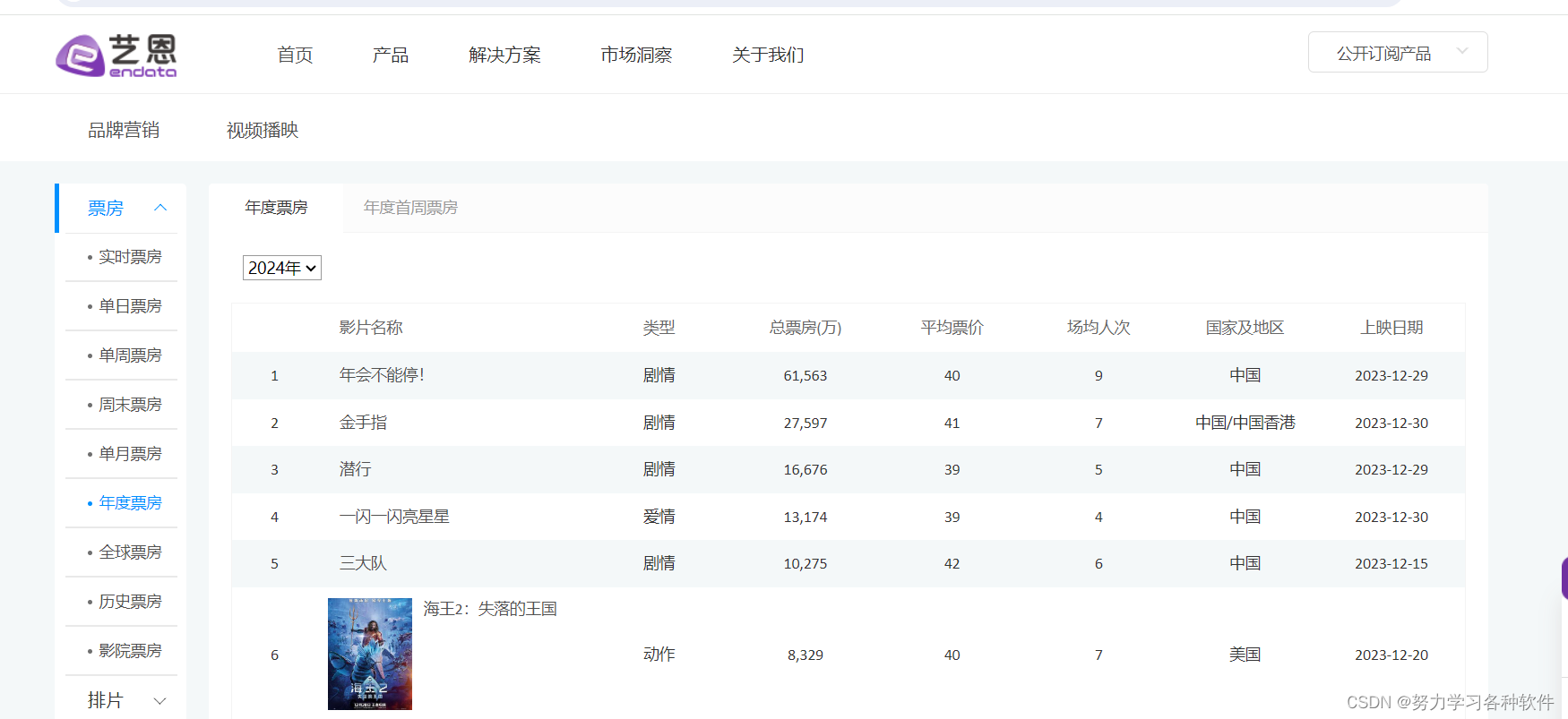
目的获得电影的详细信息,包括票房,上映日期等。
代码如下:
from selenium import webdriver
from selenium.webdriver.support.select import Select # 下拉列表
import time
import parsel
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.endata.com.cn/BoxOffice/BO/Year/index.html'
browser.get(url)
sel = browser.find_element_by_xpath('//*[@id="OptionDate"]')
sel_new = Select(sel) # 定位下拉列表
print(sel_new.options) # 获取下拉列表的所有选项
print(len(sel_new.options))
for i in range(len(sel_new.options)): # 根据位置切换下拉框0,1,2,3,4...
sel_new.select_by_index(i)
time.sleep(2)
# 切换完了之后抓数据
i = 2023-i
print(f'以下是第{i}年的电影数据')
title_list = browser.find_elements_by_css_selector('tbody .movie-name a p')
total_list = browser.find_elements_by_css_selector('tbody tr td:nth-child(4)')
year_list = browser.find_elements_by_css_selector('tbody tr td:nth-child(8)')
for title,total,year in zip(title_list,total_list,year_list):
print(title.text,total.text,year.text)
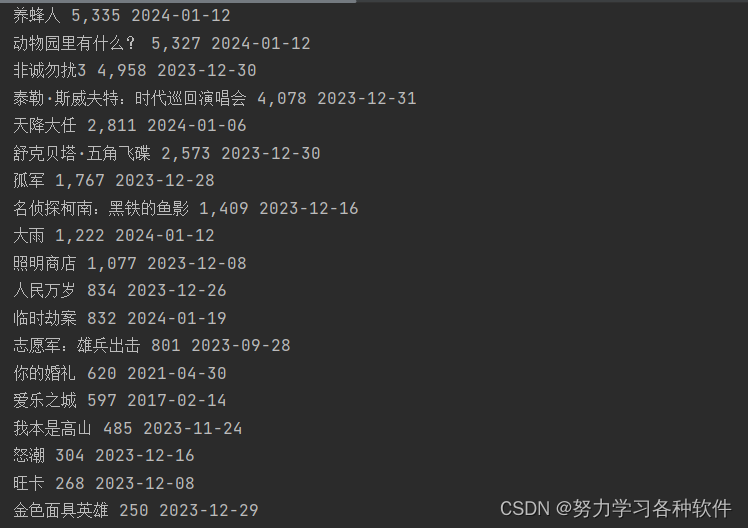
break结果展现:
文章来源:https://blog.csdn.net/m0_57265868/article/details/135704066
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Ubuntu上mosquitto下载编译
- spug发布问题汇总记录
- Buildroot显示uboot logo
- C语言 数据结构与算法
- java版微信小程序商城 免 费 搭 建 java版直播商城平台规划及常见的营销模式有哪些?电商源码/小程序/三级分销
- 「 网络安全常用术语解读 」网络攻击者的战术、技术和常识知识库ATT&CK详解
- “Oops,Account deactivated” 账号被停用,如何解封?
- redis pipeline实现,合并多个请求,可有效降低redis访问延迟
- 【抄作业】ubuntu完全卸载CUDA,彻底卸载cuda,卸载不同版本的cuda,cuda不同版本的卸载方法
- 第24集《佛法修学概要》