【MATLAB】PSO粒子群优化BiLSTM(PSO_BiLSTM)的时间序列预测
有意向获取代码,请转文末观看代码获取方式~也可转原文链接获取~

1 基本定义
基于PSO粒子群优化的BiLSTM的时间序列预测算法的基本原理如下:
-
「双向长短时记忆(BiLSTM)模型」:这是一种深度学习模型,特别适用于处理时序数据。BiLSTM模型能够同时捕捉时间序列数据的长期依赖关系和短期模式,从而在时间序列预测中表现出色。
-
「粒子群优化(PSO)算法」:这是一种优化算法,通过模拟鸟群觅食行为来寻找最优解。PSO通过个体和群体信息的交互,引导粒子(在这里指的是BiLSTM模型参数的组合)向最优解的方向移动。
-
「PSO-BiLSTM结合」:将PSO算法与BiLSTM模型结合,通过PSO搜索BiLSTM模型的参数空间,以找到最佳的参数组合,从而提高预测性能。在PSO-BiLSTM中,每个粒子代表一个BiLSTM模型,并根据其在参数空间中的位置和速度来调整模型的参数。
-
「训练过程」:首先,为每个粒子(即一组LSTM参数)设定初始位置和速度。然后,对于每个粒子,使用当前的参数配置构建BiLSTM模型,对训练数据进行预测。预测误差(通常使用均方误差MSE等指标)即为该粒子的适应度值。接着,基于粒子的历史最佳位置和全局最佳位置,更新粒子的速度和位置。这个过程会重复进行,直到满足停止条件(如达到预设的最大迭代次数,或适应度值达到预设阈值等)。在每次迭代中,都会更新粒子的位置和速度,并重新评估适应度值。最后,选择全局最佳位置对应的参数组合作为PSO-BiLSTM模型的最终参数。
-
「预测阶段」:在训练完成后,使用得到的全局最优参数配置构建最终的BiLSTM模型,并对测试数据进行预测。
- 「模型架构」:
-
「输入层」:接收时间序列数据作为输入。
-
「BiLSTM层」:使用双向LSTM单元捕捉时间序列中的长期和短期依赖关系。
-
「全连接层」:将BiLSTM层的输出转换为预测值。
-
- 「PSO参数设置」:
-
「粒子数量」:决定了搜索空间的覆盖范围和计算复杂度。
-
「速度和位置更新公式」:决定了粒子在参数空间中的移动方式。
-
「惯性权重」:用于平衡粒子的全局和局部搜索能力。
-
- 「性能评估」:
-
使用各种性能指标(如均方误差、均方根误差、平均绝对误差等)来评估模型的预测性能。
-
可以通过与其他基准模型(如单一的LSTM、ARIMA等)进行比较,来验证PSO-BiLSTM模型的优越性。
-
- 「应用领域」:
-
这种算法可以应用于各种时间序列预测问题,如股票价格预测、气象预测、交通流量预测等。
-
-
「优势和挑战」:
- 「优势」:
-
能够自动寻找BiLSTM模型的最佳参数组合,减少手动调参的工作量。
-
结合了BiLSTM的序列建模能力和PSO的全局优化能力,通常能够获得较好的预测性能。
-
- 「挑战」:
-
PSO算法可能陷入局部最优解,导致无法找到全局最优参数。
-
对于大规模数据集和高维参数空间,PSO-BiLSTM的计算成本可能较高。
-
「未来研究方向」:
-
-
探索更有效的粒子初始化策略,以提高搜索效率。
-
研究更先进的PSO变体,以提高优化性能。
-
结合其他深度学习模型或集成学习方法,进一步提高预测精度。
-
应用于更多复杂和多变的时间序列预测任务,验证算法的实际应用价值。
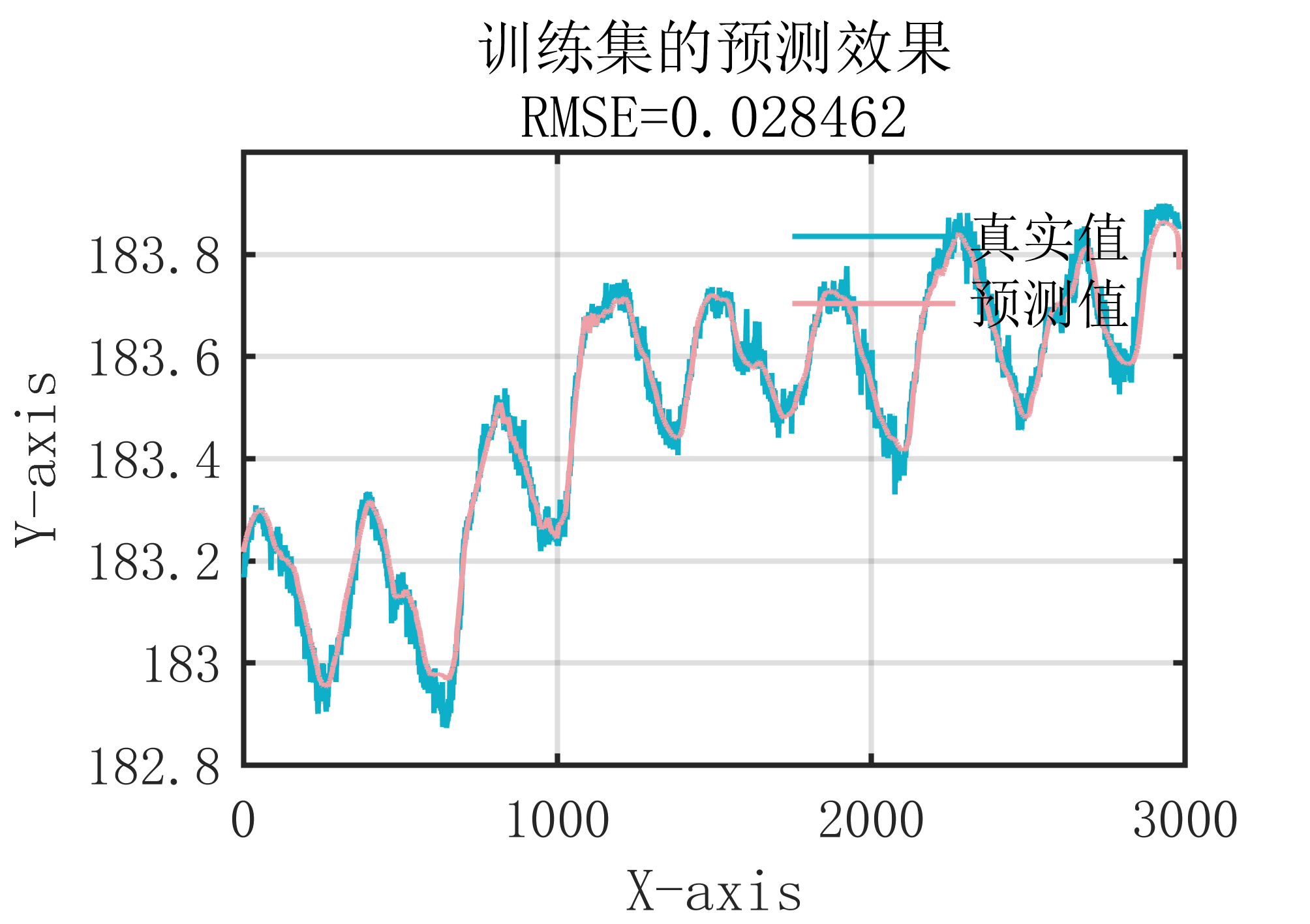
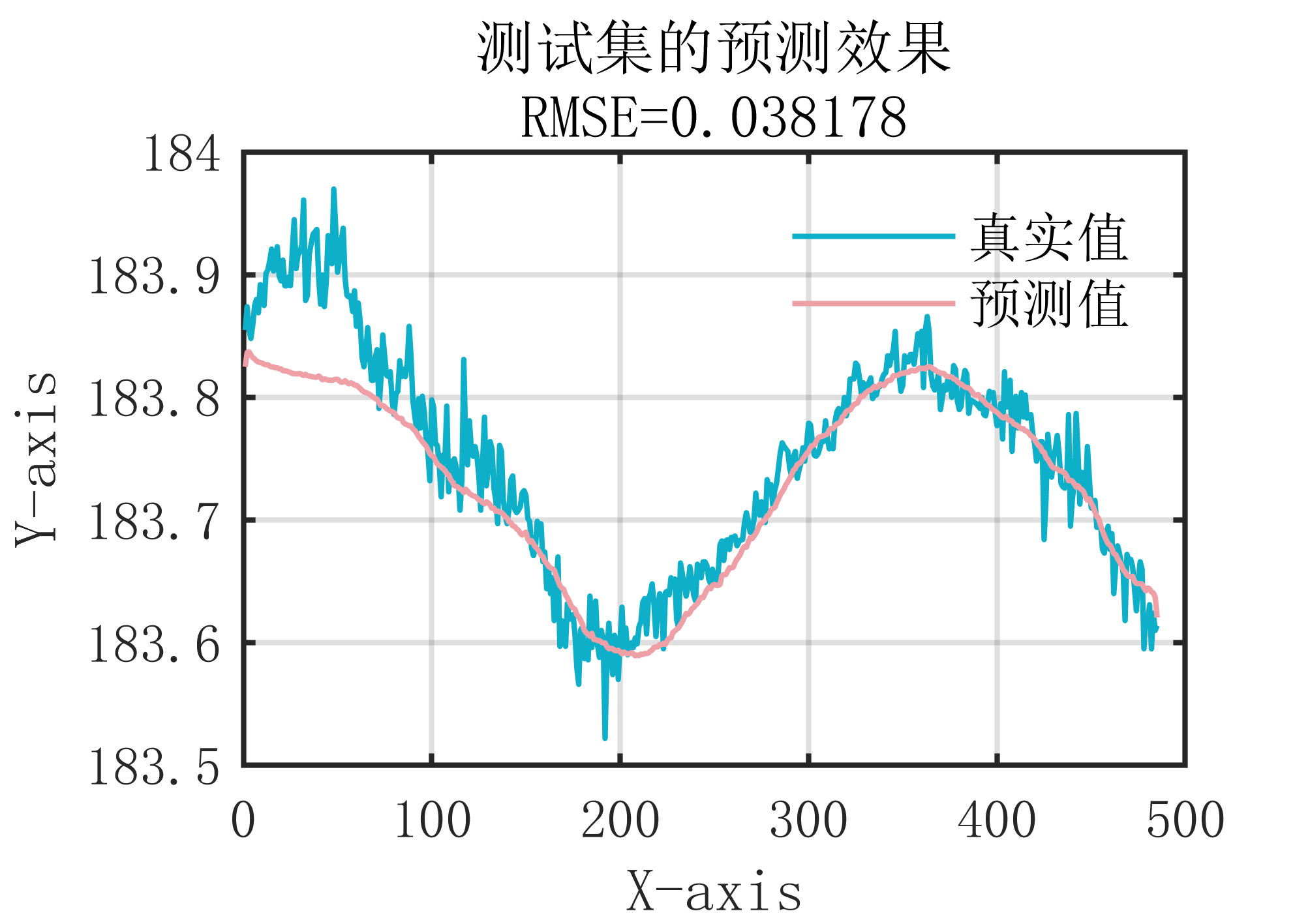
2 出图效果
附出图效果如下:
附视频教程操作:
【MATLAB】PSO粒子群优化BiLSTM(PSO
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用 GBASE南大通用GBase 8s数据库服务器来备份和记录日志
- 新品出击 | 软网关BLIoTLink免费发布
- php实现个性化域名(短网址)和个性化登录模版的解决方案
- 软考2023年上半年,选择题讲解4-27
- Docker笔记:Docker Swarm 搭建集群与项目部署
- 验证码服务使用指南
- SQL学习汇总
- Vue通过拖拽改变容器大小
- 基于JavaWeb+BS架构+SpringBoot+Vue校园一卡通系统的设计和实现
- APP分发管理系统仿第八区分发系统|安卓apk苹果ipa封装网站,苹果免签封装网站,多语种下载页|内测分发|超及签名|企业签名|应用封装