【数据结构】哈希经典应用:布隆过滤器(哈希+位图)——[深度解析](9)
发布时间:2023年12月17日
前言
大家好吖,欢迎来到 YY 滴 数据结构 系列 ,热烈欢迎! 本章主要内容面向接触过C++的老铁
主要内容含:

欢迎订阅 YY滴 数据结构 专栏!更多干货持续更新!以下是传送门!
目录
一.布隆过滤器产生的前提
- 我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉
那些已经看过的内容。- 用服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会 从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。 如何快速查找呢?
- 用哈希表存储用户记录,缺点:浪费空间
- 用位图存储用户记录,缺点:位图一般只能处理整形,如果内容编号是字符串,就无法处理
了。- 将哈希与位图结合,即布隆过滤器
二.布隆过滤器的原理&基本场景
【1】布隆过滤器的核心原理&重要性质
- 布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的 一种紧凑型的、比较巧妙的概
率型数据结构,特点是高效地插入和查询,可以用来告诉你 “某样东西可能存在或者一定不存在”,它是用 多个哈希函数 ,将一个数据映射到位图结构中 。- 此种方式不仅可以提升查询效率,也可以节省大量的内存空间。
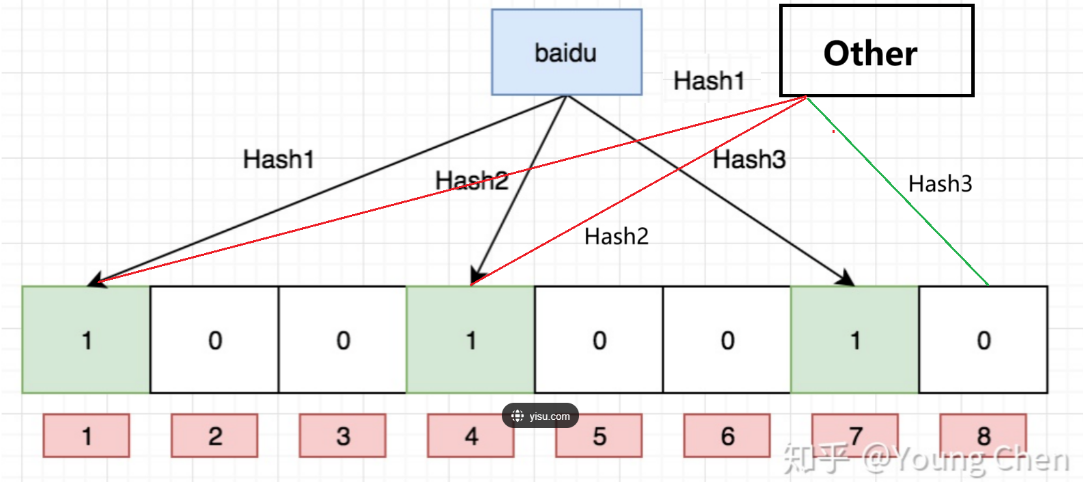
如下图1所示:
- 某样东西可能存在:baidu 与other 通过哈希函数Hash1,Hash2都同时映射到相同位置发生了哈希冲突。所以当我们根据该位置下定义:baidu/Other存在,则可能出现误判,这种误判无法消除,所以只能下定义——某样东西可能存在
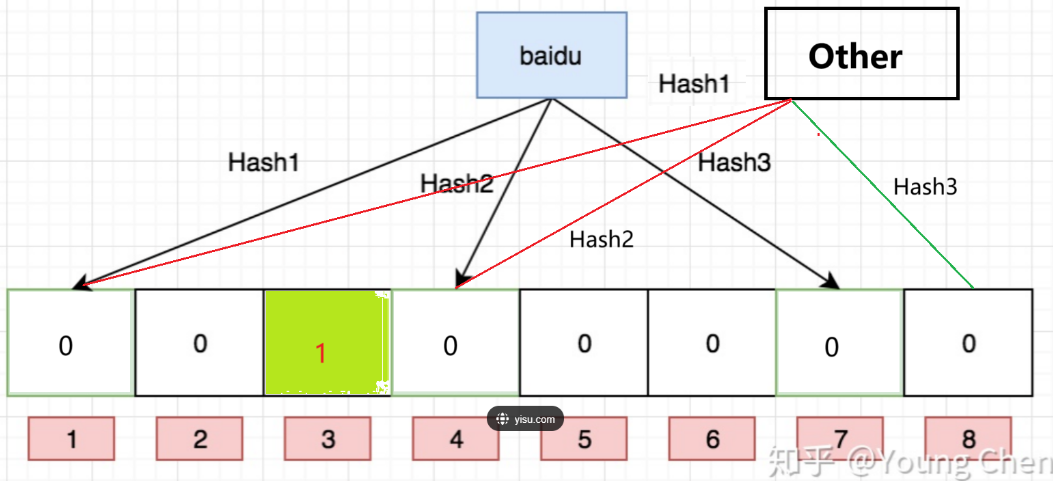
如下图2所示:
- 某样东西一定不存在:比如只有位图3号位置被标识为1,则一定能说明baidu和Other一定不存在
【2】布隆过滤器的基本场景
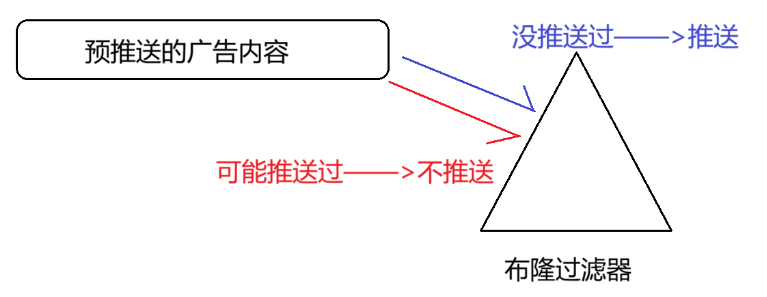
(1)快速判断广告是否推送过——不需要精确的场景
- 比如我们在【一】中提出的我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。
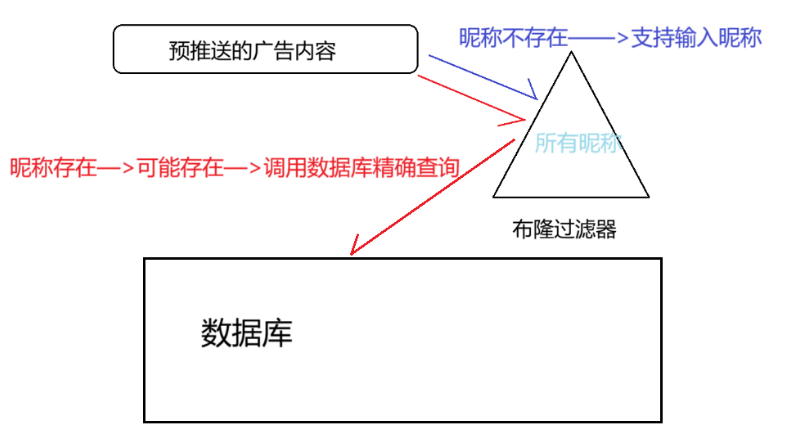
(2)快速判断昵称是否注册过——需要精确的场景
- 根据布隆过滤器的性质:它会告诉你 “某样东西可能存在或者一定不存在”
- 如果每一次查询都访问数据库,会增加数据库查询负载降低效率
- 因此我们设置一个布隆过滤器,把所有昵称都放到这个过滤器中, 如果显示昵称不存在,则支持输入昵称;如果显示昵称存在,则表示其可能存在,再到数据库中进行精确查询;
三.布隆过滤器一般不支持"删除"
- 布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
四.布隆过滤器的经典例题
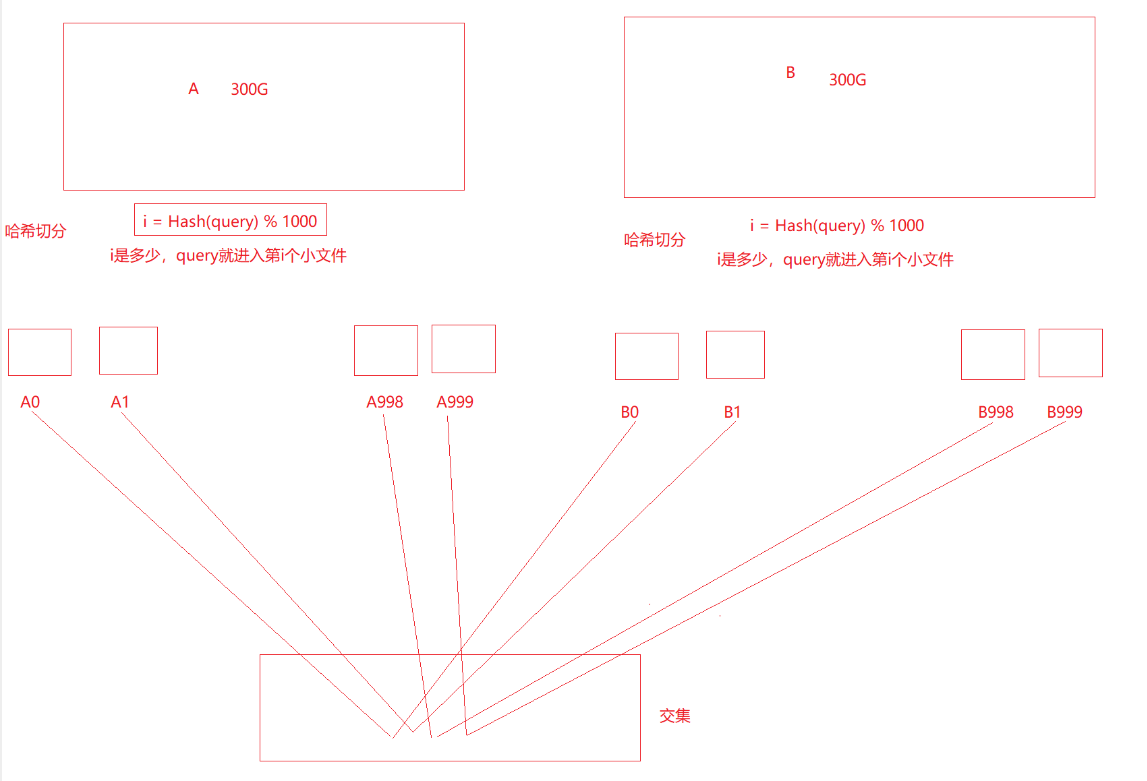
【1】给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法————(哈希切分)
- 我们先有一个内存大小基本概念:1G约为10亿byte,假设一个query平均为30byte,那么100亿query就约为3000亿byte,约为300G
- 哈希切分的基本概念: 是将一个大文件,利用哈希的原理, 将其分为若干个小文件。
- 相同的数据都被分到同一个文件里
- 在此题中,如下图所示,即:A和B中相同的query就会进入相同的小文件中

【2】如何扩展BloomFilter使得它支持删除元素的操作
- 多个位标识同一个值,使用 引用计数
文章来源:https://blog.csdn.net/YYDsis/article/details/134374398
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 可视化 | 【echarts】金字塔图
- 62.Spring多线程事务 能否保证事务的一致性(同时提交、同时回滚)?
- 【算法题】 TLV解析 Ⅱ (js)
- 时序预测 | Python实现GRU电力需求预测
- AI 在医学中的三个关键作用;联想 AI PC 全阵容亮相 CES 2024
- idea添加翻译功能
- 软件系统详细设计说明书(直接套用)
- 海外社媒运营为什么需要选择优质IP代理?
- 15.存在连续三个奇数的数组
- 第二十一章总结