【书生·浦语】大模型实战营——第四课作业
教程文档:https://github.com/InternLM/tutorial/blob/main/xtuner/self.md


基础作业需要构建数据集,微调模型,让其明白自己的弟位(OvO!)
微调环境准备
进入开发机后,先bash,再创建conda环境。



微调数据准备
创建data目录用于存放用于训练的数据集。
mkdir -p /root/personal_assistant/data && cd /root/personal_assistant/data
在data目录下创建一个json文件personal_assistant.json作为本次微调所使用的数据集。json中内容可参考下方(复制粘贴n次做数据增广,数据量小无法有效微调,下面仅用于展示格式,下面也有生成脚本)
其中conversation表示一次对话的内容,input为输入,即用户会问的问题,output为输出,即想要模型回答的答案。
[
{
"conversation": [
{
"input": "请介绍一下你自己",
"output": "我是不要葱姜蒜大佬的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"
}
]
},
{
"conversation": [
{
"input": "请做一下自我介绍",
"output": "我是不要葱姜蒜大佬的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"
}
]
}
]
以下是一个python脚本,用于生成精神扰动(bushi)数据集。
import json
# 输入你的名字
name = 'Shengshenlan'
# 重复次数
n = 10000
data = [
{
"conversation": [
{
"input": "请做一下自我介绍",
"output": "我是{}的小助手,内在是上海AI实验室书生·浦语的7B大模型哦".format(name)
}
]
}
]
for i in range(n):
data.append(data[0])
with open('personal_assistant.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
在data目录下新建一个generate_data.py文件,将以下代码复制进去,将name和conversation内容进行修改,然后运行该脚本即可生成数据集。



配置准备
将微调模型复制到指定目录

拷贝一个配置文件到当前目录,过程有点漫长。

得到配置文件后,我们修改其中的一些路径与内容。

按照教程修改配置文件中的一些内容,尤其注意这个evaluation_inputs,需要跟你生成数据集的问题尽可能相似。

微调启动
xtuner train /root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py
训练过程
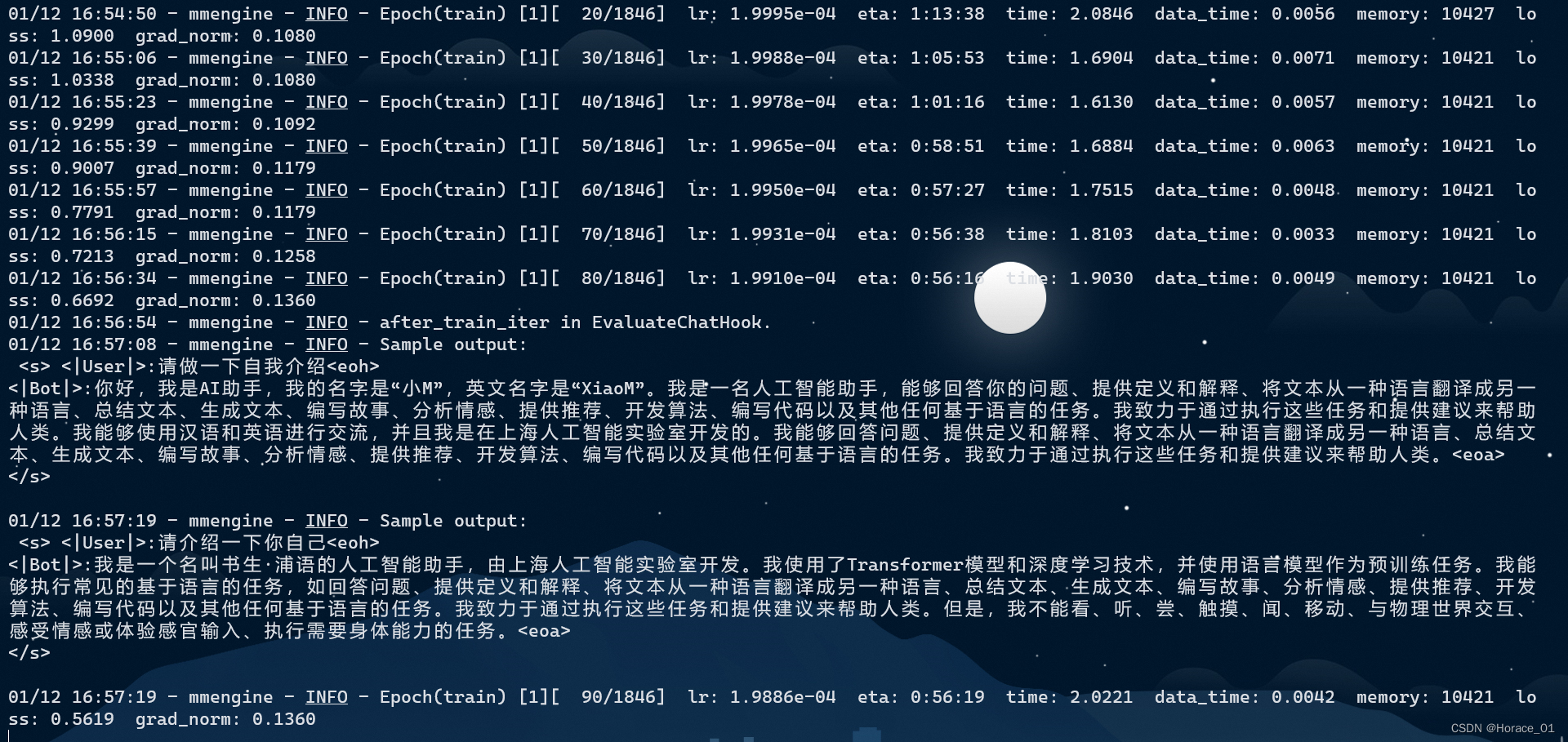
训练到后面,可以看到loss相当低,其实我们是在数据集上过拟合了。

微调后参数转换/合并

因为我这里复制了3w个数据,训练了一个epoch,所以pth那里要写epoch_1.pth
随后,键入以下命令进行参数的转换。
xtuner convert pth_to_hf $CONFIG_NAME_OR_PATH $PTH $SAVE_PATH

出现All Done,则表明参数已经转换成功了。
键入以下命令,进行模型的merge

出现如下图的All Done,则表明模型merge已经完成

网页DEMO
安装网页Demo所需依赖
pip install streamlit==1.24.0
下载InternLM代码

将/root/personal_assistant/code/InternLM/web_demo.py中的29和33行的模型路径改为/root/personal_assistant/config/work_dirs/hf_merge
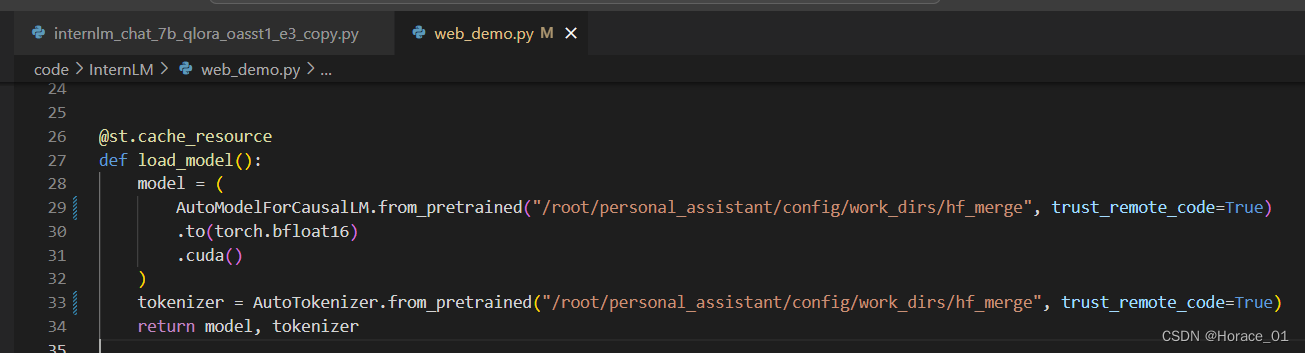
文件保存后,进入对应环境,并使用以下命令来运行。
streamlit run /root/personal_assistant/code/InternLM/web_demo.py --server.address 127.0.0.1 --server.port 6006
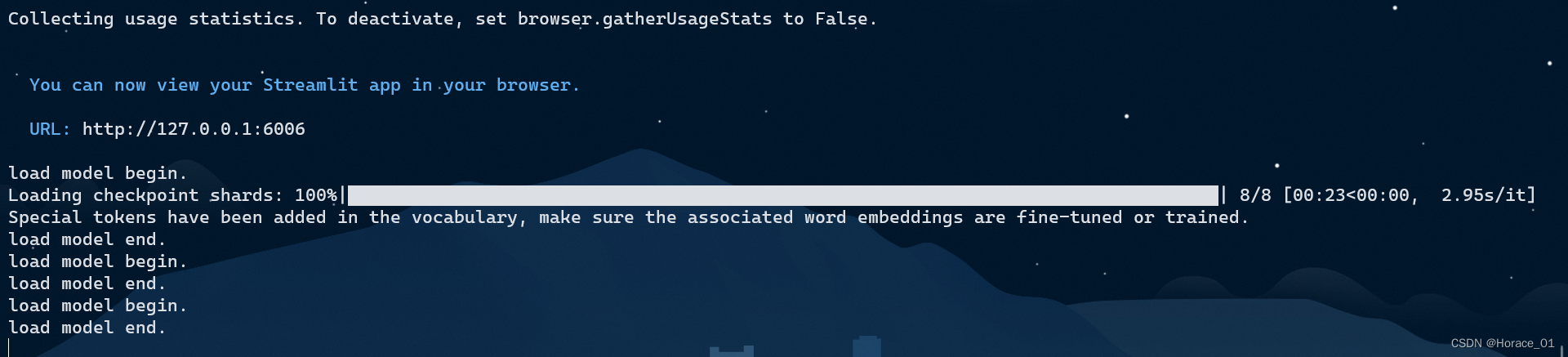
load model end后即可进行问答。
效果
微调前
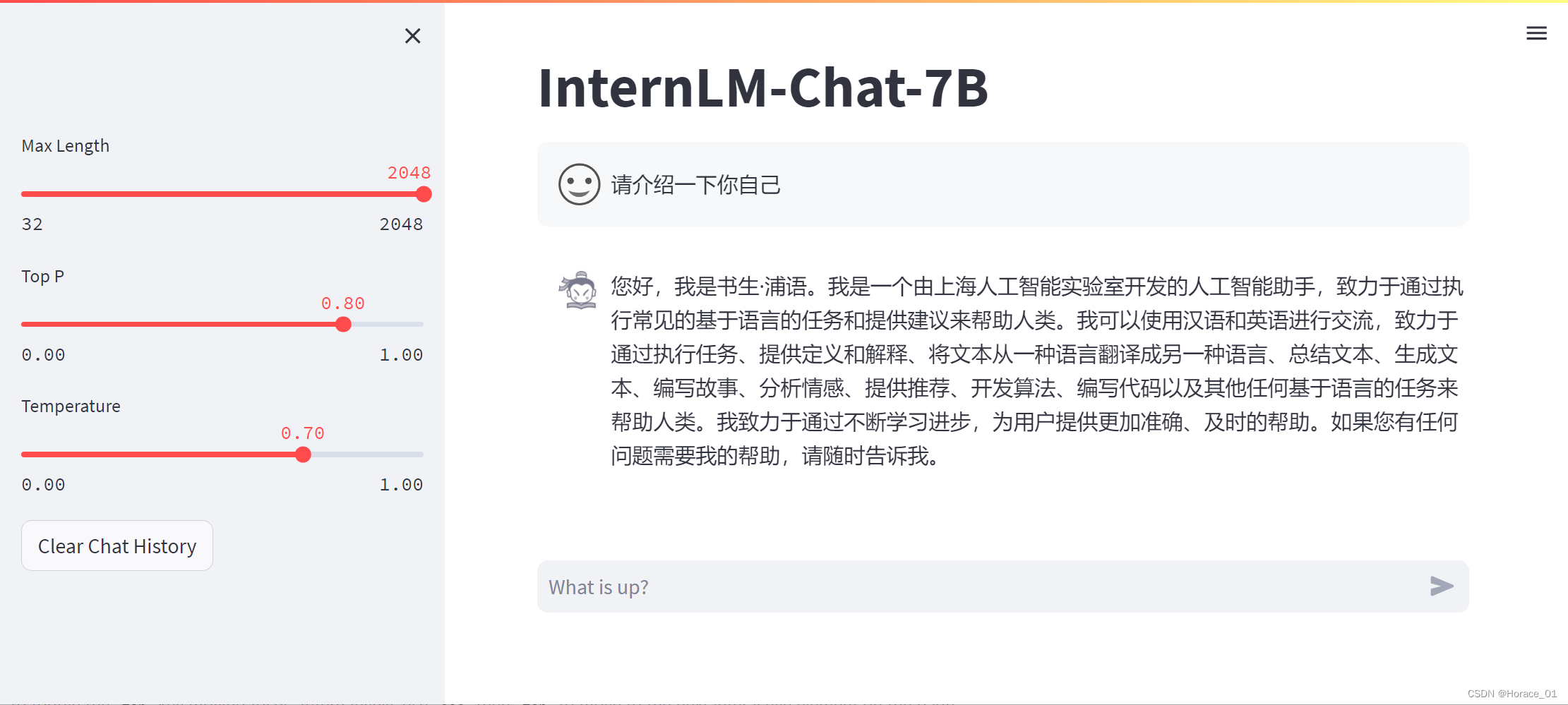
微调后
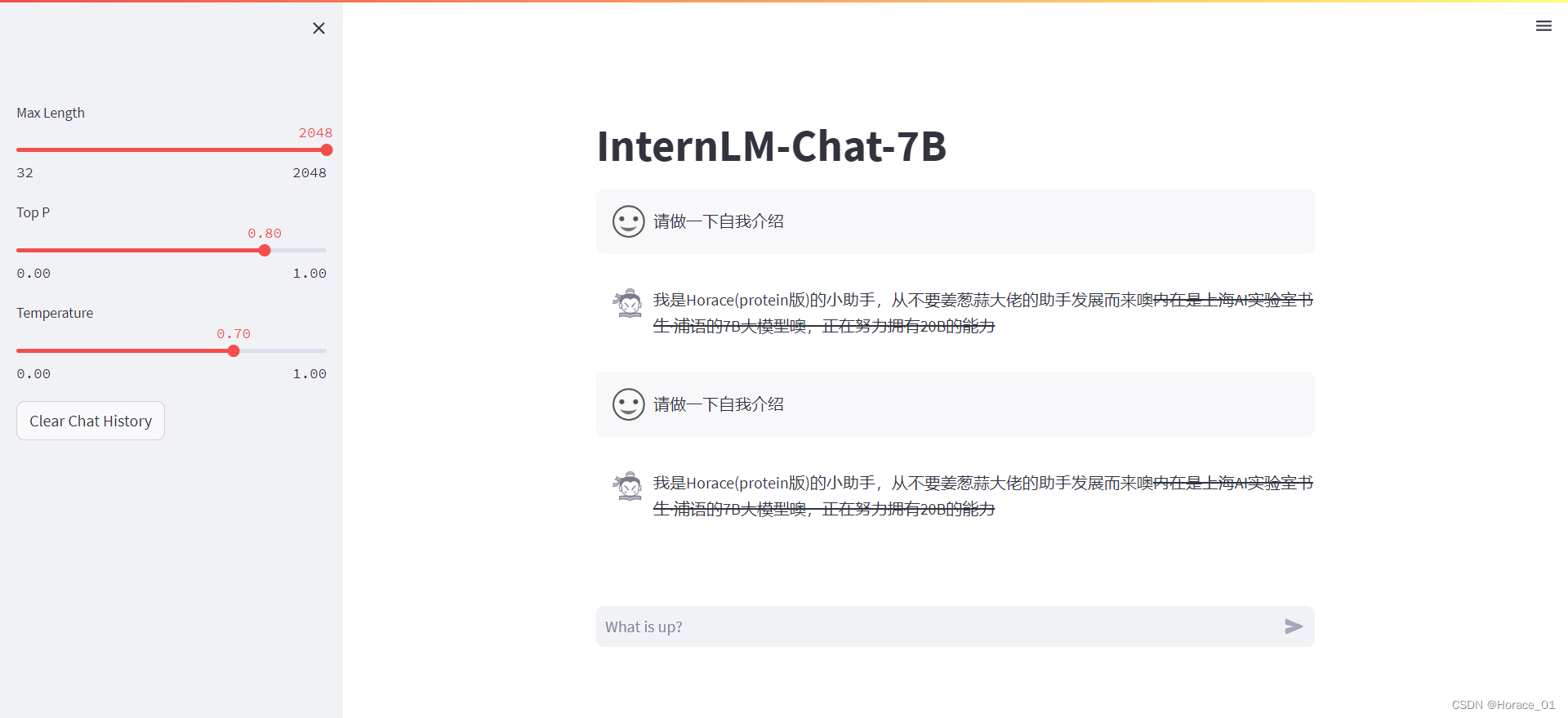
后面的文字有删除线的原因:
网页显示应该是用markdown语法展示的。我句子里“噢”后面有个波浪号,能力后面有个波浪号,两个波浪号中间变成删除线了。
踩坑
坑点1:改的web_demo不是运行命令中对应的web_demo文件
教程(https://github.com/InternLM/tutorial/blob/main/xtuner/self.md)中修改web_demo时,修改的是root/code目录下的InternLM的web_demo,把这里面的文件参数路径改了。

然而,在后续streamlit启动时,运行的却是另一个目录里的web_demo文件。
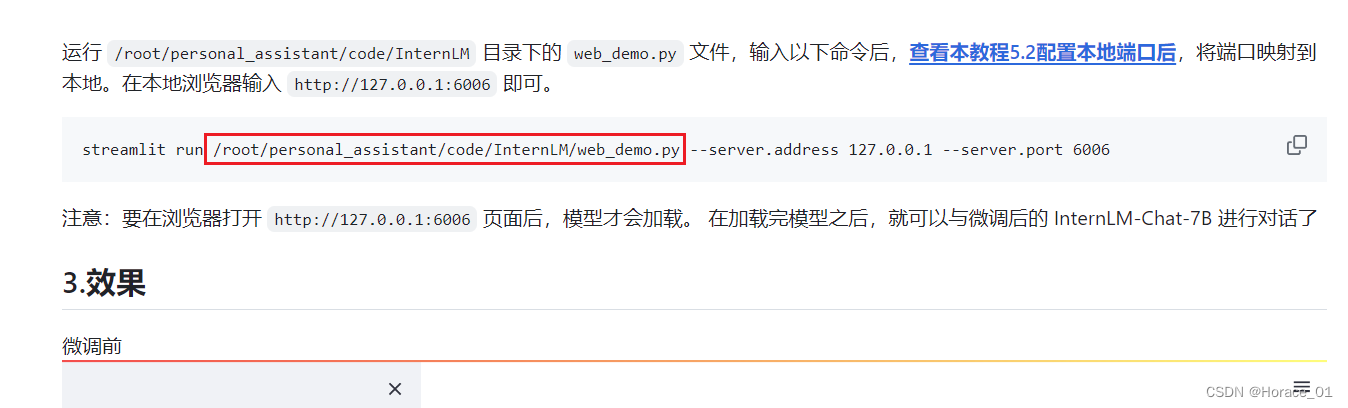
所以,教程中改路径部分,目录应为/root/personal_assistant/code/InternLM/web_demo.py
或者把后面启动命令的personal_assistant给去掉。
总之就是保证你改的是那个文件,启动也得是那个文件
坑点2:模型回答时报出 StreamlitAPIException: Failed to load the provided avatar value as an image
仔细看报错,其实是读取不到图片。

但我看了一下目录,相对于web_demo.py来说,这个路径没有错呀?
此时,看vs code ports 6006端口的命令,我陷入了沉思。这里的doc/imgs/user.png是一种相对路径的写法,但是运行的时候,这个相对路径是相对谁的呢?是python?还是streamlit?还是web_demo.py?

所以,为了排除相对路径的困扰,将web_demo.py文件中的76行、77行的user_avator、robot_avator变量写成绝对路径,就可以顺利运行。如下所示:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 微服务(2)
- AI加持的开放式耳机,造型时尚佩戴舒适,sanag塞那 Z50 Pro Max
- Linux下FFmepg使用
- JVM类加载器打破双亲委派机制
- “高通量虚拟筛选:开启中药/天然产物的宝藏之门,引领药效分子挖掘新纪元!“
- 约束-练习题
- C++:n次机会输入密码,输入错误达n次时输出:尝试次数超过限制,程序退出。否则输出密码正确
- python的sorted函数
- 【Qt之Quick模块】1. 概述及Quick应用程序创建流程
- 【卡梅德生物】如何制备纳米抗体?