使用爬虫从主要电商网站快速批量下载产品详情图片
发布时间:2023年12月27日
? ? ? ? 电商购物网站的产品详情面图片美观、漂亮,但是有些图片能正常下载,有些不能正常下载,需要通过页面代码进行查找。如果自己做电商要准备产品详情图片消耗人工和时间。博客页面已上传核心实现代码。所有爬虫代码已上传网盘,可以关注公众号【站在前沿】,回复product,获取网盘下载链接。有其它需求也可以在微信公众号留言。
? ? ? ? 近两天通过通过对京东、天猫和1688的产品详情页面的代码分析,使用python爬虫实现了批量下载产品详情图片的代码,主要使用的多线程和常用爬虫技术实现。程序代码主要实现功能是三个电商网站产品页面的宣传图片和详情页面图片的下载,可以快速批量下载所有产品详情图片,程序运行效果如下
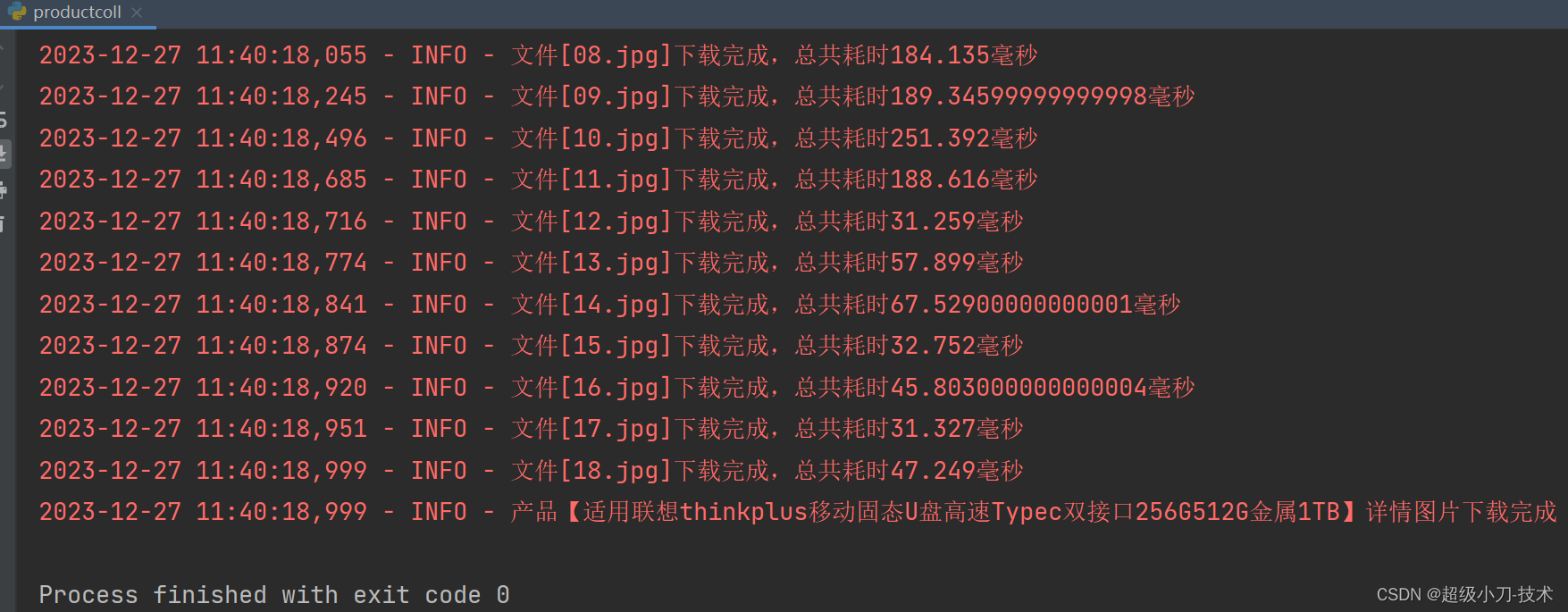
1、京东产品详情页面代码分析
产品宣传图片
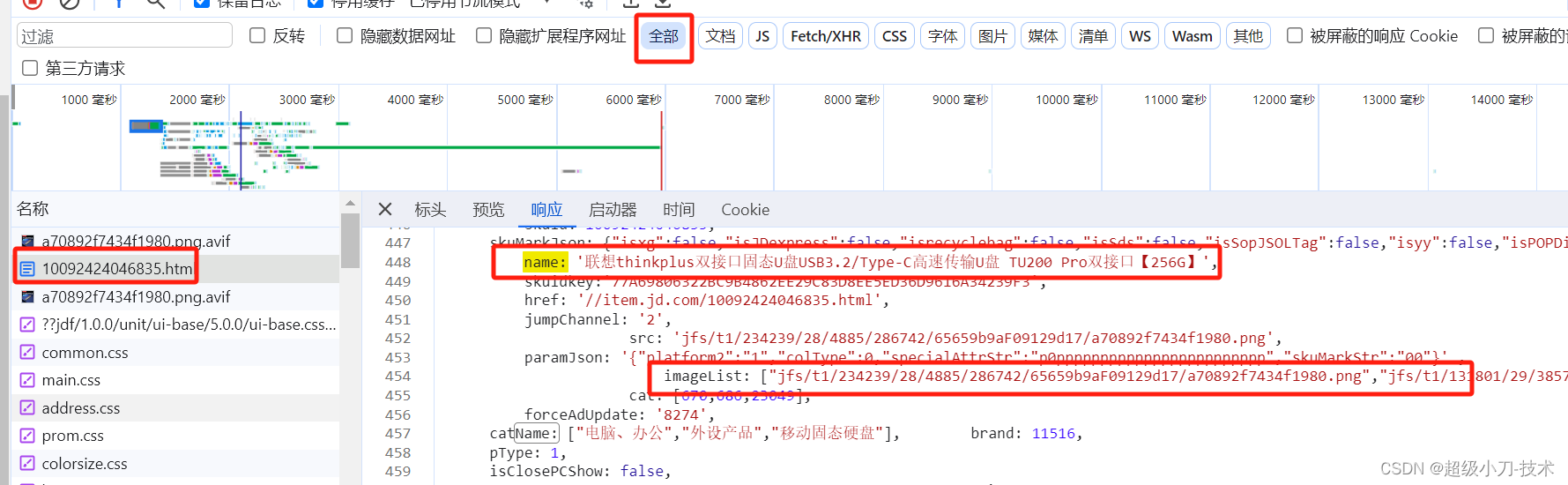
产品详情图片

2、天猫产品详情页面代码分析
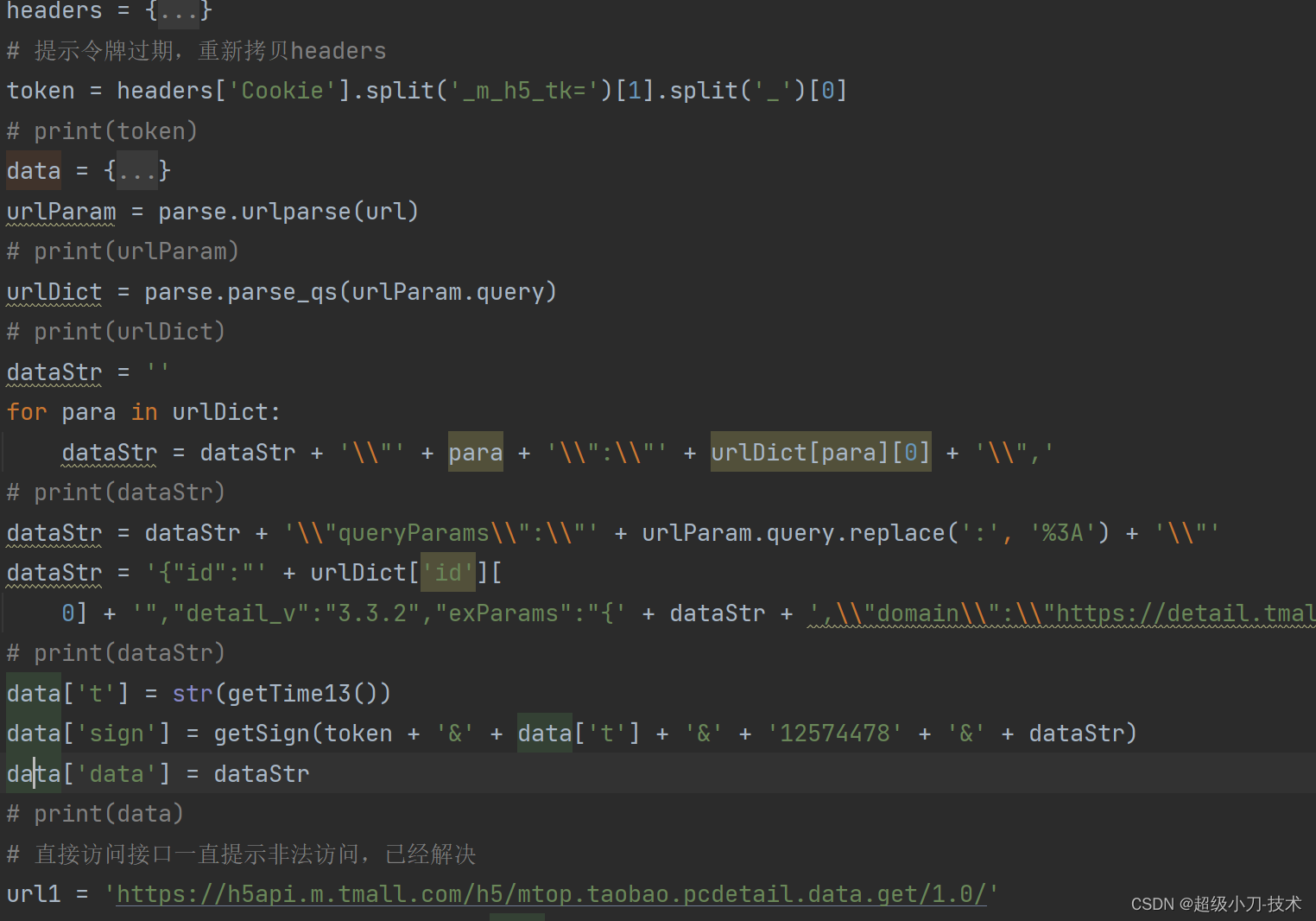
token过期时间较短,运行代码产拷贝和替换新的Cookie
产品宣传图片
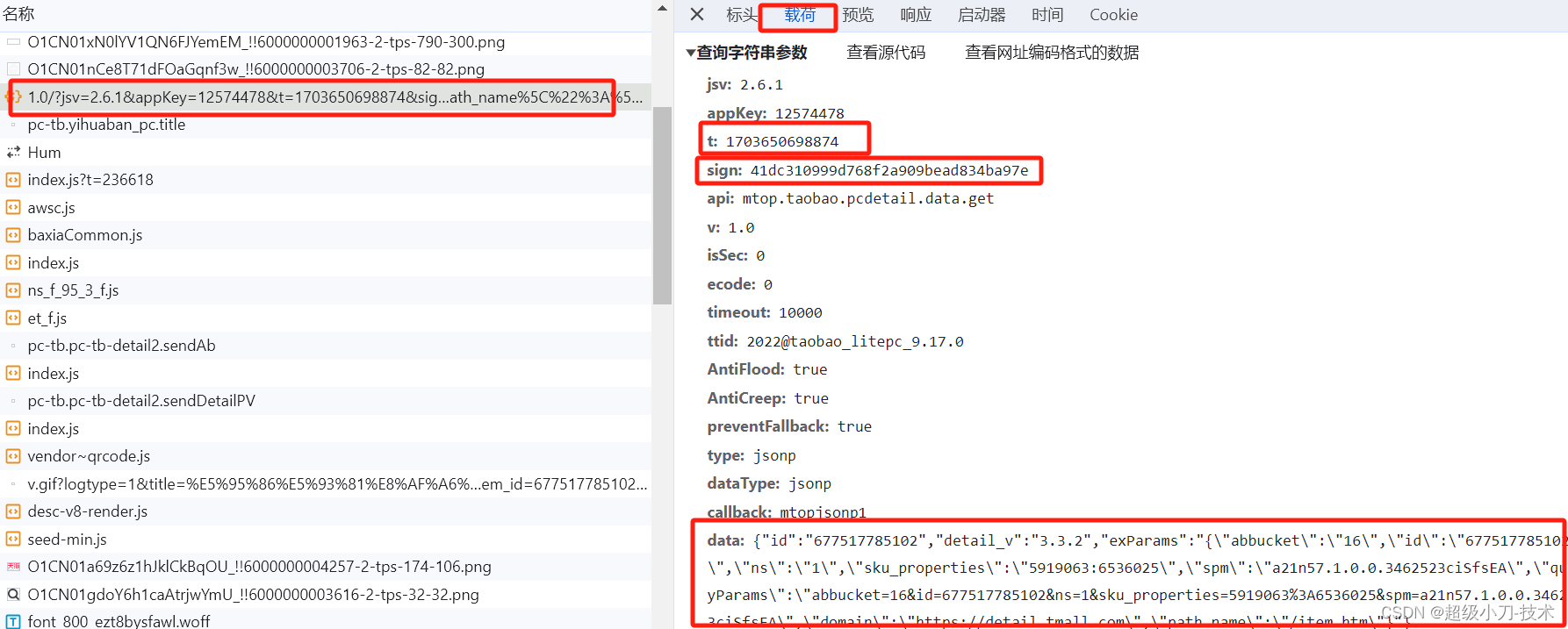
sign传入错误,会一直提示“非法请求”。

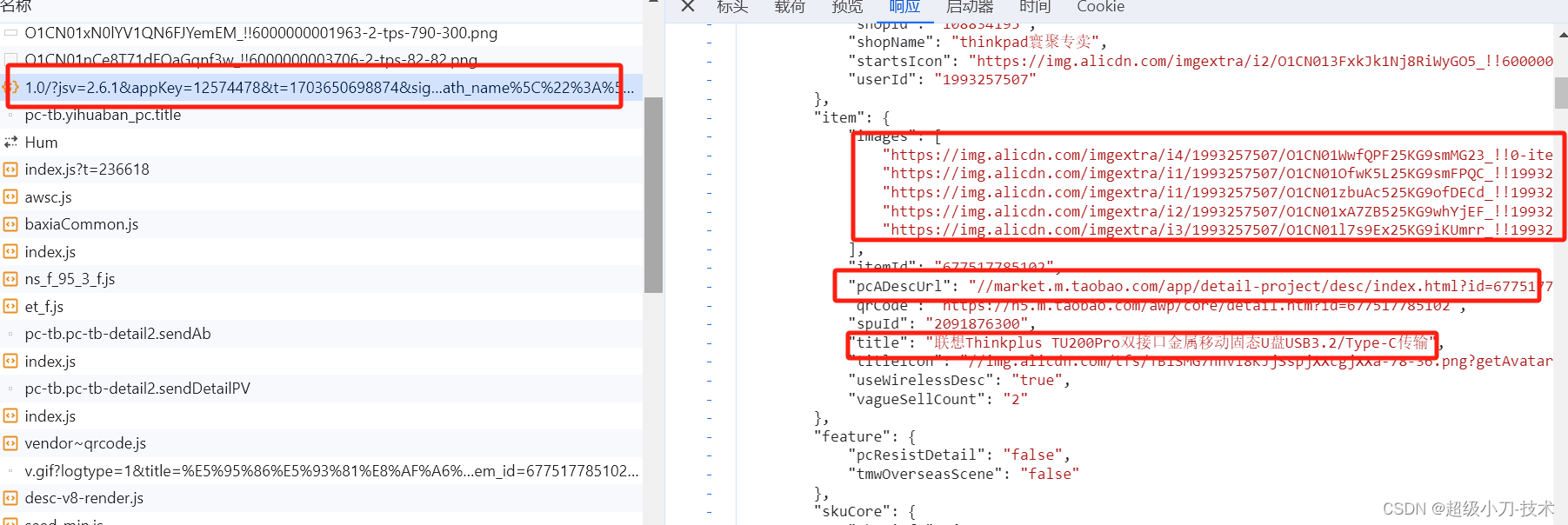
产品详情图片
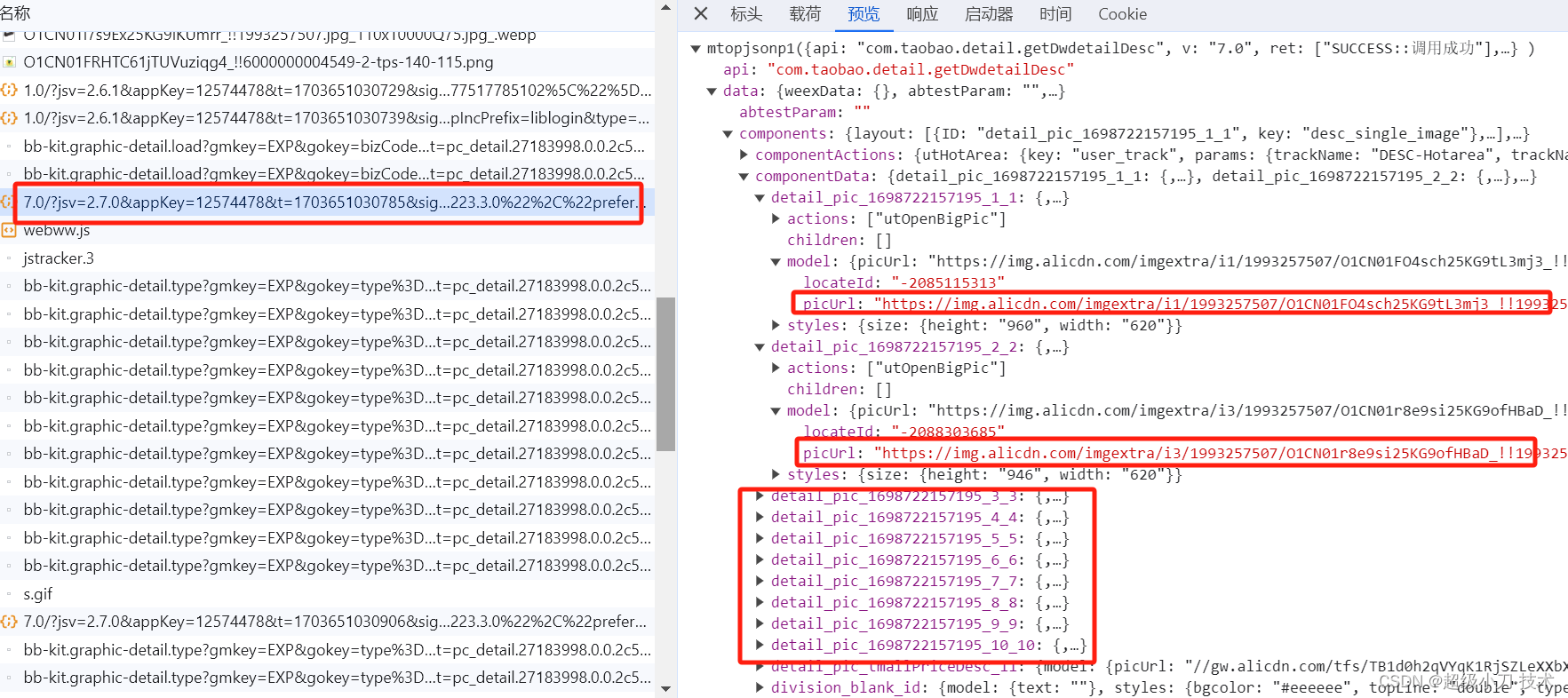
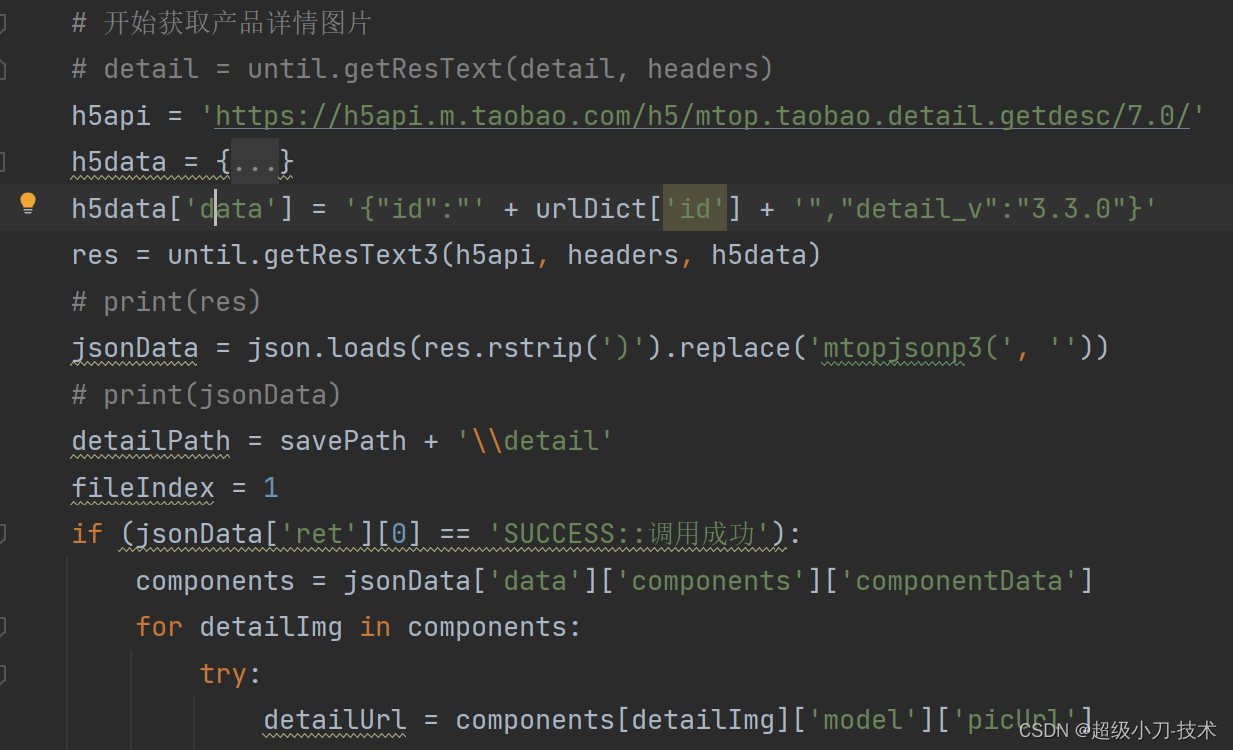
3、1688产品详情页面代码分析
产品页面访问频繁,可能需要人工验证,可以等一段时间或替换新的Cookie
产品宣传图片
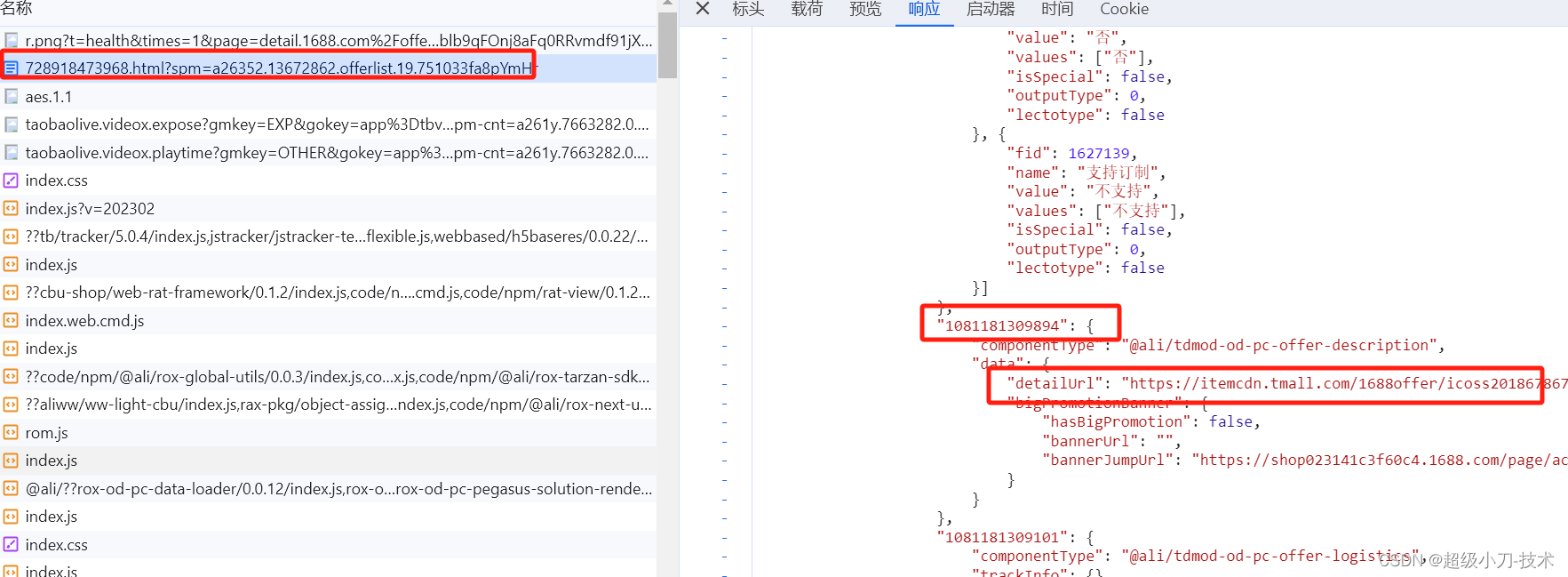
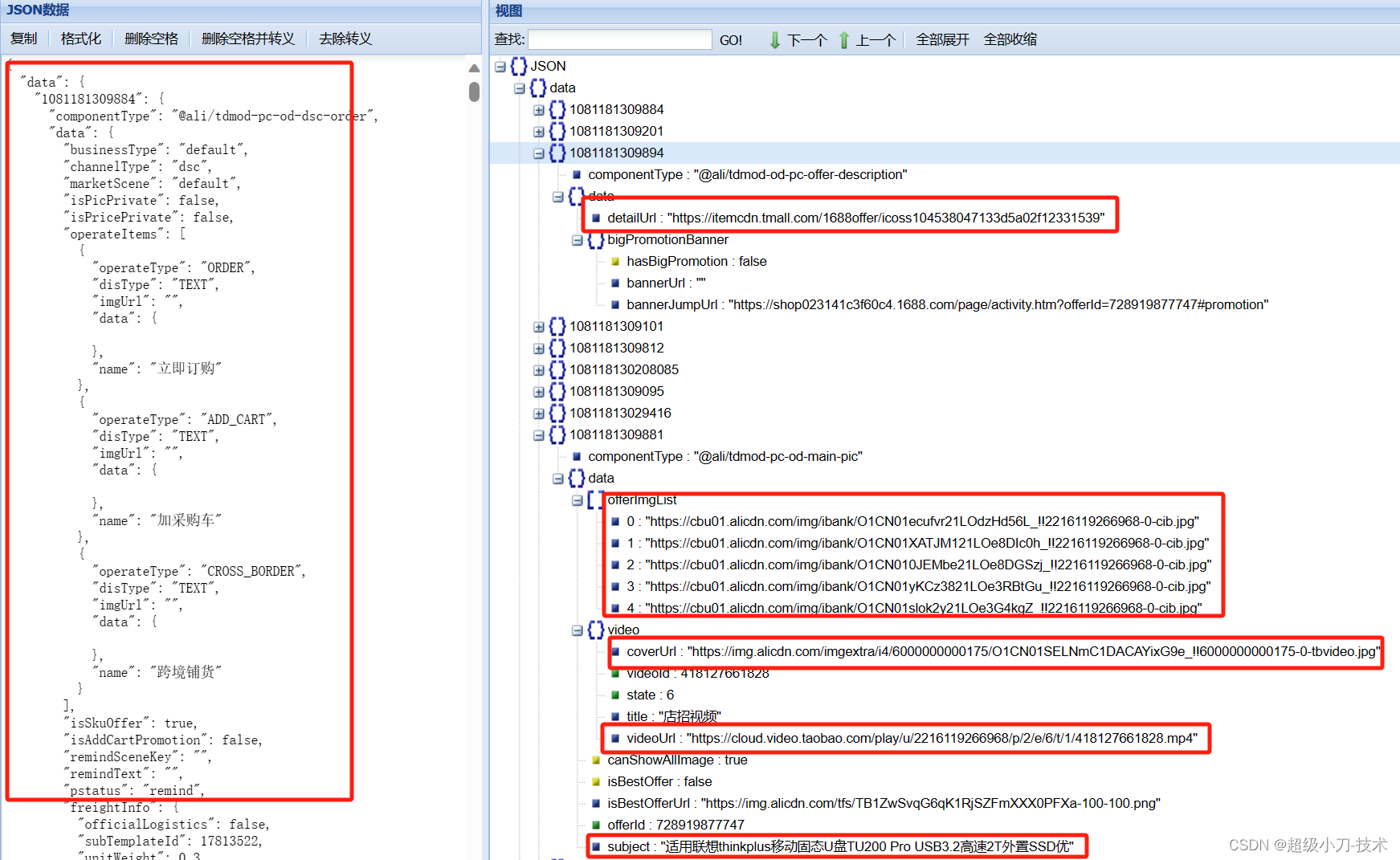

产品详情图片
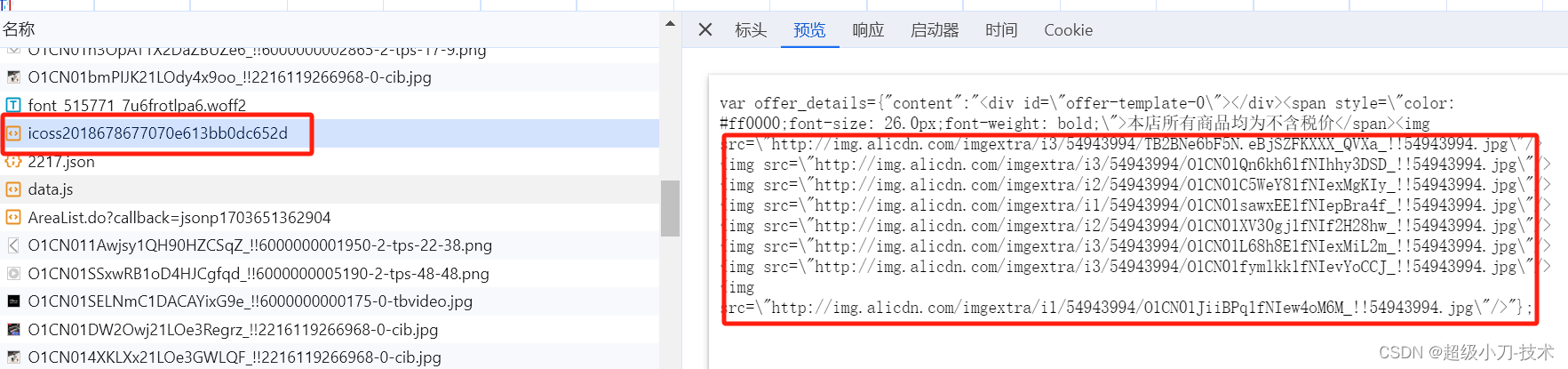

4、部分核心代码
def down1688(url, savePath):
headers = {
'Cookie': '请拷贝浏览器的Cookie',
'Referer': 'https://s.1688.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
res = until.getResText(url, headers)
# print(res)
if ('window.__INIT_DATA' not in res):
logging.info('由于频繁访问网页,页面返回需要人工验证,可以等一段时间或者替换最新Cookie再试')
jsonStr = re.findall('window.__INIT_DATA=(.*?)</script>', res, re.S)[0]
# print(jsonStr)
jsonData = json.loads(jsonStr)
name = until.checkFileName(jsonData['data']['1081181309881']['data']['subject'])
savePath = savePath + '\\' + name
imagePath = savePath + '\\image'
fileIndex = 1
for img in jsonData['data']['1081181309881']['data']['offerImgList']:
until.downBinFile(img, headers, imagePath,
str(fileIndex).zfill(2) + '.' + str(img).rsplit('.', 1)[1].split('?')[0])
fileIndex = fileIndex + 1
if (jsonData['data']['1081181309881']['data']['video']['videoId'] != 0):
videoPath = savePath + '\\video'
downUrl = jsonData['data']['1081181309881']['data']['video']['coverUrl']
until.downBinFile(downUrl, headers, videoPath, 'img.' + str(downUrl).rsplit('.', 1)[1])
downUrl = jsonData['data']['1081181309881']['data']['video']['videoUrl']
until.downBinFile(downUrl, headers, videoPath, 'video.' + str(downUrl).rsplit('.', 1)[1])
# 开始获取产品详情图片
detail = until.getResText(jsonData['data']['1081181309894']['data']['detailUrl'], headers)
# print(detail)
pattern = r'offer_details={"content":"(.*?)"};'
html = re.findall(pattern, detail, re.S)[0]
soup = BeautifulSoup(html, "html.parser")
details = soup.select("img")
detailPath = savePath + '\\detail'
fileIndex = 1
for img in details:
imgUrl = img["src"].replace('\\', '').replace('"', '').strip('/')
until.downBinFile(imgUrl, headers, detailPath,
str(fileIndex).zfill(2) + '.' + str(imgUrl).rsplit('.', 1)[1].split('?')[0])
fileIndex = fileIndex + 1
# print(imgUrl)
logging.info('产品【' + name + '】详情图片下载完成')
time.sleep(1)
def downJd(url, savePath):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Cookie': '请拷贝浏览器的Cookie',
'Pragma': 'no-cache',
'Referer': 'https://search.jd.com/',
'Sec-Ch-Ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A_Brand";v="24"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': '"Windows"',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-site',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
res = until.getResText(url, headers)
# print(res)
imgList = re.findall('imageList: (.*?)],', res)[0]
imgList = imgList.replace('"', '').lstrip('[').split(',')
# print(imgList)
name = until.checkFileName(re.findall(r'name: \'(.*?)\',', res)[0])
savePath = savePath + '\\' + name
imagePath = savePath + '\\image'
fileIndex = 1
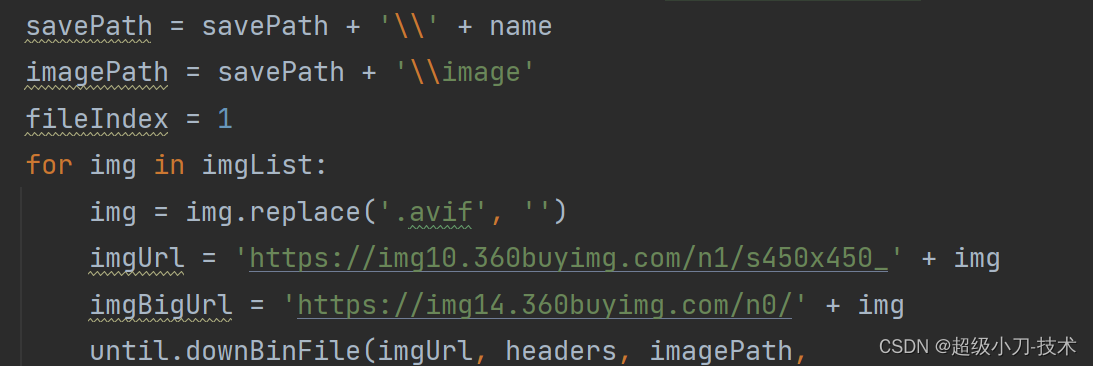
for img in imgList:
img = img.replace('.avif', '')
imgUrl = 'https://img10.360buyimg.com/n1/s450x450_' + img
imgBigUrl = 'https://img14.360buyimg.com/n0/' + img
until.downBinFile(imgUrl, headers, imagePath,
str(fileIndex).zfill(2) + '.' + str(img).rsplit('.', 1)[1].split('?')[0])
until.downBinFile(imgBigUrl, headers, imagePath,
'big' + str(fileIndex).zfill(2) + '.' + str(img).rsplit('.', 1)[1].split('?')[0])
fileIndex = fileIndex + 1
# 获取详情图片
mainSkuId = re.findall('mainSkuId:\'(.*?)\',', res)[0]
skuId = re.findall('data-sku=\"(.*?)\"', res)[0]
# print(mainSkuId,skuId)
data = {
'appid': 'item-v3',
'functionId': 'pc_description_channel',
'skuId': '10034368015519',
'mainSkuId': '10021308737006',
'charset': 'utf-8',
'cdn': '2',
'callback': 'showdesc'
}
data['mainSkuId'] = mainSkuId
data['skuId'] = skuId
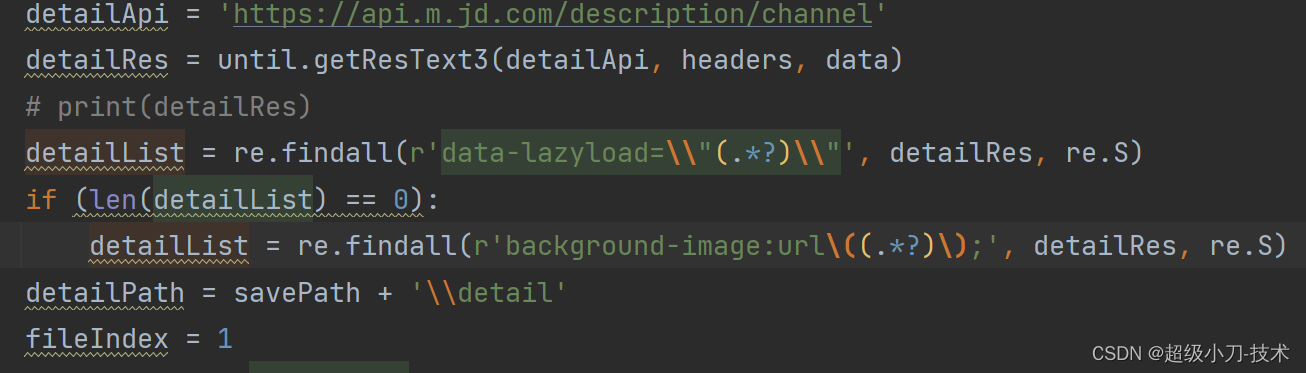
detailApi = 'https://api.m.jd.com/description/channel'
detailRes = until.getResText3(detailApi, headers, data)
# print(detailRes)
detailList = re.findall(r'data-lazyload=\\"(.*?)\\"', detailRes, re.S)
if (len(detailList) == 0):
detailList = re.findall(r'background-image:url\((.*?)\);', detailRes, re.S)
detailPath = savePath + '\\detail'
fileIndex = 1
for detail in detailList:
if (detail[0:4] != 'http'):
detail = 'https:' + detail
until.downBinFile(detail, headers, detailPath,
str(fileIndex).zfill(2) + '.' + str(detail).rsplit('.', 1)[1].split('?')[0])
fileIndex = fileIndex + 1
# print(detail)
logging.info('产品【' + name + '】详情图片下载完成')
所有爬虫代码已上传网盘,可以关注公众号【站在前沿】,回复product,获取网盘下载链接。有其它需求也可以在微信公众号留言。
文章来源:https://blog.csdn.net/wzhibin/article/details/135242098
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用代码生成器生成代码 mybatis-plus-generator
- LeetCode 1349. 参加考试的最大学生数,状压DP
- 渗透测试 | php的webshell绕过方法总结
- 浅谈VLAN和VXLAN
- C函数生成一个与文本字符串相对应的字体矩阵
- 智谱推出新一代基座大模型GLM-4
- 链动2+1模式:轻松破亿
- GCP Scanner:一款针对Google Cloud Platform(GCP)的凭证安全审计工具
- 华为OD机试真题2023 C & D卷(JAVA&JS)
- C++类与对象基础(5)——日期类的实现