GRU算法
发布时间:2024年01月02日
前置知识:RNN,LSTM
LSTM需要训练的参数很多,极消耗计算资源。GRU是一种LSTM的改进算法,参数更少,更容易训练。
它将忘记门和输入门合并成为一个单一的更新门,同时合并了数据单元状态和隐藏状态,使得模型结构比之于LSTM更为简单。
结构
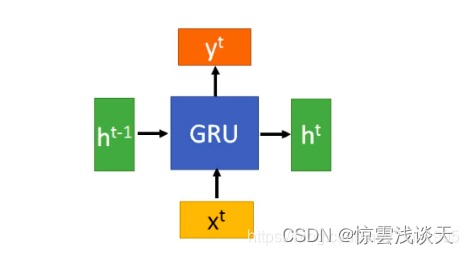
GRU的整体结构图与RNN没有区别

reset重置门
rt就是重置门,得到rt后,将rt与上一时刻传入的ht-1进行点乘,得到重置之后的数据,并与xt进行拼接。
h'包含了输入信息xt,经过选择后的上一时刻的信息h't-1,
update更新门
-
z*ht-1:表示对隐藏状态选择性的遗忘;
-
(1-z)*h':表示对包含当前节点信息的h'选择性的记忆
文章来源:https://blog.csdn.net/lty1392309506/article/details/135329813
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大学物理-实验篇——用拉伸法测定金属丝的杨氏(弹性)模量(胡克定律、杨氏模量、平面反射镜、三角函数、螺旋测微器)
- 7-验证码识别
- 新年第一枪!Nature子刊:新技术揭示根际免疫制约病原菌的过程与微生态机制
- 不断发展的识别技术为多个行业带来新机遇
- 面试题:如何停止一个正在运行的线程?
- 做到这几点,澳福3天的收益比得上3年的交易
- Java异常处理--异常处理的方式1
- Docker从入门到精通
- 常用设计模式全面总结版(Java&Kotlin)
- 72.批量执行Redis命令的4种方式!