DATAX的架构和运行原理
发布时间:2024年01月22日
一.概念
? DATAX呢就是把各个不同构的数据库进行同步的过程,具体有hdfs hive Oracle 等等吧。
二.架构
1.设计原理
显而易见从强连通图到星形图,大大的简化了工作量。
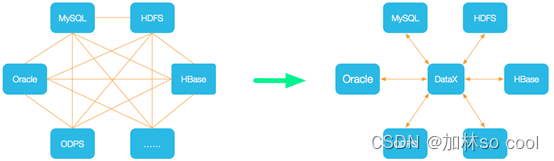
2.框架设计,变成了FrameWork和plugin的形式,以读者写者的方式(reader writer)进行数据的同步吧。

DataX在设计之初就将同步理念抽象成框架+插件的形式.框架负责内部的序列化传输,缓冲,并发,转换等而核心技术问题,数据的采集(Reader)和落地(Writer)完全交给插件执行。
- Read 数据采集模块,负责采集数据源的数据,将数据发送至FrameWork。
- Writer 数据写入模块,负责不断的向FrameWork取数据,并将数据写入目的端。
- FrameWork 用于连接reader和write,作为两者的数据传输通道,处理缓冲,流控,并发,转换等核心技术问题。
4.运行原理
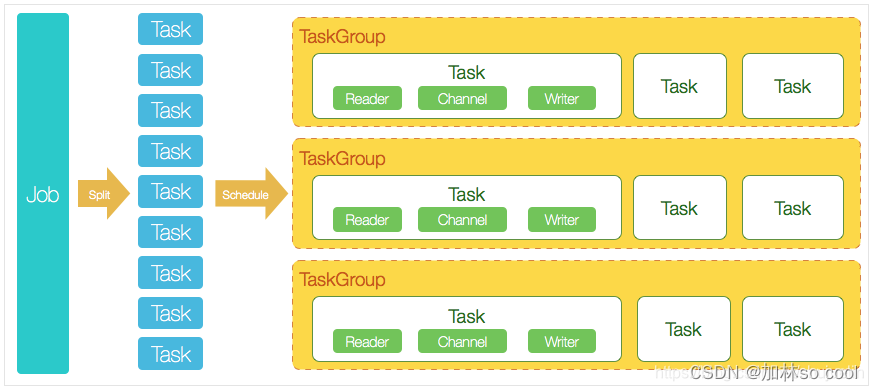
- Job 完成单个数据同步的作业称之为job。DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。负责数据清理,子任务划分,TaskGroup监控管理。
- Task 由Job切分而来,是DataX作业的最小单元,每个Task负责一部分数据的同步工作。
- Schedule 将Task组成TaskGroup,默认单个任务组的并发数量为5。
- TaskGroup 负责启动Task。
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务.
DataX调度流程
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- 1 DataXJob根据分库分表切分成了100个Task。
- 2 根据20个并发,默认单个任务组的并发数量为5,DataX计算共需要分配4个TaskGroup。
- 3 这里4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
文章来源:https://blog.csdn.net/qq_52310720/article/details/135740569
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!