Python利用Excel读取和存储测试数据完成接口自动化教程
发布时间:2024年01月19日
http_request2.py用于发起http请求
#读取多条测试用例
#1、导入requests模块
import requests
#从 class_12_19.do_excel1导入read_data函数
from do_excel2 import read_data
from do_excel2 import write_data
from do_excel2 import count_case
#定义http请求函数
COOKIE=None
def http_request2(method,url,data):
if method=='get':
print('发起一个get请求')
result=requests.get(url,data,cookies=COOKIE)
else:
print('发起一个post请求')
result=requests.post(url,data,cookies=COOKIE)
return result #返回响应体
# return result.json() #返回响应结果:结果是字典类型:{'status': 1, 'code': '10001', 'data': None, 'msg': '登录成功'}
#从Excel读取到多条测试数据
sheets=['login','recharge','withdraw']
for sheet1 in sheets:
max_row=count_case(sheet1)
print(max_row)
for case_id in range(1,max_row):
data=read_data(sheet1,case_id)
print('读取到第{}条测试用例:'.format(data[0]))
print('测试数据 ',data)
#print(type(data[2]))
#调用函数发起http请求
result=http_request2(data[4],data[2],eval(data[3]))
print('响应结果为 ',result.json())
if result.cookies:
COOKIE=result.cookies
#将测试实际结果写入excel
#write_data(case_id+1,6,result['code'])
write_data(sheet1,case_id+1,7,str(result.json()))
#对比测试结果和期望结果
if result.json()['code']==str(data[5]):
print('测试通过')
#将用例执行结果写入Excel
write_data(sheet1,case_id+1,8,'Pass')
else:
write_data(sheet1,case_id+1,8,'Fail')
print('测试失败')
do_excel2.py完成对excel中用例的读、写、统计
# 导入load_workbook
from openpyxl import load_workbook
#读取测试数据
#将excel中每一条测试用例读取到一个列表中
#读取一条测试用例——写到一个函数中
def read_data(sheet_name,case_id):
# 打开excel
workbook1=load_workbook('test_case2.xlsx')
# 定位表单(test_data)
sheet1=workbook1[sheet_name]
print(sheet1)
test_case=[] #用来存储每一行数据,也就是一条测试用例
test_case.append(sheet1.cell(case_id+1,1).value)
test_case.append(sheet1.cell(case_id+1,2).value)
test_case.append(sheet1.cell(case_id+1,3).value)
test_case.append(sheet1.cell(case_id+1,4).value)
test_case.append(sheet1.cell(case_id+1,5).value)
test_case.append(sheet1.cell(case_id+1,6).value)
return test_case #将读取到的用例返回
#调用函数读取第1条测试用例,并将返回结果保存在data中
# data=read_data(1)
# print(data)
#将测试结果写会excel
def write_data(sheet_name,row,col,value):
workbook1=load_workbook('test_case2.xlsx')
sheet=workbook1[sheet_name]
sheet.cell(row,col).value=value
workbook1.save('test_case2.xlsx')
#统计测试用例的行数
def count_case(sheet_name):
workbook1=load_workbook('test_case2.xlsx')
sheet=workbook1[sheet_name]
max_row=sheet.max_row #统计测试用例的行数
return max_row
test_case2.xlsx存储??????测试用例

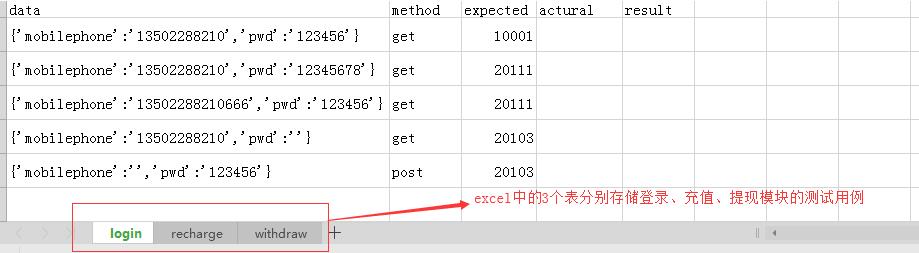 ?
?
补充知识:python用unittest+HTMLTestRunner+csv的框架测试并生成测试报告
直接贴代码:
import csv # 导入scv库,可以读取csv文件
from selenium import webdriver
import unittest
from time import sleep
import time
import os
import HTMLTestRunner
import codecs
import sys
dr = webdriver.Chrome()
class testLo(unittest.TestCase):
def setUp(self):
pass
def test_login(self):
'''登陆测试'''
path = 'F:\\Python_test\\'
# 要读取的scv文件路径
my_file = 'F:\\pythonproject\\interfaceTest\\testFile\\ss.csv'
# csv.reader()读取csv文件,
# Python3.X用open,Python2.X用file,'r'为读取
# open(file,'r')中'r'为读取权限,w为写入,还有rb,wd等涉及到编码的读写属性
#data = csv.reader(codecs.open(my_file, 'r', encoding='UTF-8',errors= 'ignore'))
with codecs.open(my_file, 'r', encoding='UTF-8',errors= 'ignore') as f:
data=csv.reader((line.replace('\x00','') for line in f))
# for循环将读取到的csv文件的内容一行行循环,这里定义了user变量(可自定义)
# user[0]表示csv文件的第一列,user[1]表示第二列,user[N]表示第N列
# for循环有个缺点,就是一旦遇到错误,循环就停止,所以用try,except保证循环执行完
print(my_file)
for user in data:
print(user)
dr.get('https://passport.cnblogs.com/user/signin')
# dr.find_element_by_id('input1').clear()
dr.find_element_by_id('input1').send_keys(user[0])
# dr.find_element_by_id('input2').clear()
dr.find_element_by_id('input2').send_keys(user[1])
dr.find_element_by_id('signin').click()
sleep(1)
print('\n' + '测试项:' + user[2])
dr.get_screenshot_as_file(path + user[3] + ".jpg")
try:
assert dr.find_element_by_id(user[4]).text
try:
error_message = dr.find_element_by_id(user[4]).text
self.assertEqual(error_message, user[5])
print('提示信息正确!预期值与实际值一致:')
print('预期值:' + user[5])
print('实际值:' + error_message)
except:
print('提示信息错误!预期值与实际值不符:')
print('预期值:' + user[5])
print('实际值:' + error_message)
except:
print('提示信息类型错误,请确认元素名称是否正确!')
def tearDown(self):
dr.refresh()
# 关闭浏览器
dr.quit()
if __name__ == "__main__":
# 定义脚本标题,加u为了防止中文乱码
report_title = u'登陆模块测试报告'
# 定义脚本内容,加u为了防止中文乱码
desc = u'登陆模块测试报告详情:'
# 定义date为日期,time为时间
date = time.strftime("%Y%m%d")
time = time.strftime("%Y%m%d%H%M%S")
# 定义path为文件路径,目录级别,可根据实际情况自定义修改
path = 'F:\\Python_test\\' + date + "\\login\\" + time + "\\"
# 定义报告文件路径和名字,路径为前面定义的path,名字为report(可自定义),格式为.html
report_path = path + "report.html"
# 判断是否定义的路径目录存在,不能存在则创建
if not os.path.exists(path):
os.makedirs(path)
else:
pass
# 定义一个测试容器
testsuite = unittest.TestSuite()
# 将测试用例添加到容器
testsuite.addTest(testLo("test_login"))
# 将运行结果保存到report,名字为定义的路径和文件名,运行脚本
report = open(report_path, 'wb')
#with open(report_path, 'wb') as report:
runner = HTMLTestRunner.HTMLTestRunner(stream=report, title=report_title, description=desc)
runner.run(testsuite)
# 关闭report,脚本结束
report.close()
csv文件格式:
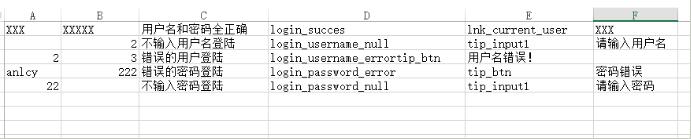
备注:
使用python处理中文csv文件,并让execl正确显示中文(避免乱码)设施编码格式为:utf_8_sig,示例:
'''''
将结果导出到result.csv中,以UTF_8 with BOM编码(微软产品能正确识别UTF_8 with BOM存储的中文文件)存储
'''
#data.to_csv('result_utf8_no_bom.csv',encoding='utf_8')#导出的结果不能别excel正确识别
data.to_csv('result_utf8_with_bom.csv',encoding='utf_8_sig')
总结:
感谢每一个认真阅读我文章的人!!!
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
?????视频文档获取方式:
这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享,点下方小卡片即可自行领取。????
文章来源:https://blog.csdn.net/2301_77645834/article/details/135707222
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- TypeScript实现一个贪吃蛇小游戏
- 操作系统系列:Unix进程系统调用fork,wait,exec
- 用ChatGPT搜索电商产品!全球最大超市-沃尔玛与微软合作
- 复合机器人颠覆传统上下料,实现高效精准生产
- 基于ssm的驾校预约管理系统+jsp论文
- 【Python百宝箱】抓取世界:网络爬虫和数据提取全家桶
- 代码随想录算法训练营第三十四天 | 1005.K次取反后最大化的数组和 、134. 加油站、135. 分发糖果
- 无线网的几种组网架构
- PyTorch深度学习实战(21)——从零开始实现Faster R-CNN目标检测
- Java循环高级(无限循环,break,continue,Random,逢七过,平方根,判断是否是质数,猜数字小游戏)