实战体验 Amazon SageMaker 机器学习

(声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 亚马逊云科技开发者社区、知乎、自媒体平台、第三方开发者媒体等亚马逊云科技官方渠道)
近日,亚马逊云科技在re:Invent 2023会议现场发布了 Amazon SageMaker 的五项新功能,旨在加速构建、训练和部署大型语言模型和其他基础模型。这些新功能将帮助用户更快地进行模型开发和应用部署,提供更强大的工具和资源。本篇文章将为大家介绍 Amazon SageMaker 的工作原理,以及实战使用 Amazon SageMaker 提供的机器学习环境。
Amazon SageMaker 原理
在机器学习中,我们需要训练计算机进行预测或推理。首先,需要使用算法和示例数据来训练模型。然后,将模型集成到应用程序中,以实时、大规模地生成推理。在生产环境中,模型通常会从数百万个示例数据项中学习,并在数百到不到 20 毫秒的时间内生成推论。
下图说明了创建机器学习模型的典型工作流程:

生成示例数据
要训练模型,需要示例数据。需要的数据类型取决于你希望模型解决的业务问题。例如,假设你想要创建一个模型来预测给定手写数字输入图像的数字。要训练这样的模型,需要手写数字的示例图像。
获取数据
通常,你可以将一个或多个数据集拉入单个存储库。
清理数据
为了改进模型训练,请检查数据并根据需要清理数据。
准备或转换数据
为了提高性能,可以执行其他数据转换。例如,可以选择组合属性等等。
训练模型
要训练模型,需要算法或预训练的基础模型。您选择的算法取决于许多因素。对于快速、开箱即用的解决方案,也可以使用 SageMaker 提供的算法之一。
训练模型后,可以对其进行评估以确定推论的准确性是否可以接受。可以使用SageMaker Python SDK 通过可用的 IDE 之一向模型发送推理请求,以训练和评估你的模型。
部署模型
传统上,需要重新设计模型,然后再将其与应用程序集成并部署。借助 SageMaker 托管服务,可以独立部署模型,将其与应用程序代码解耦。
了解了基本原理,下面我们就在实际操作中了解这个功能的强大之处吧。
实战机器学习
下面是 SageMaker 提供的机器学习环境。

其中有 11 中环境,下面我们选择其中的一个进行实战使用。选择 SageMaker Studio 实验室组件。

注册账号
可以注册免费账号,注册也不麻烦只需要填一个邮箱就可以。
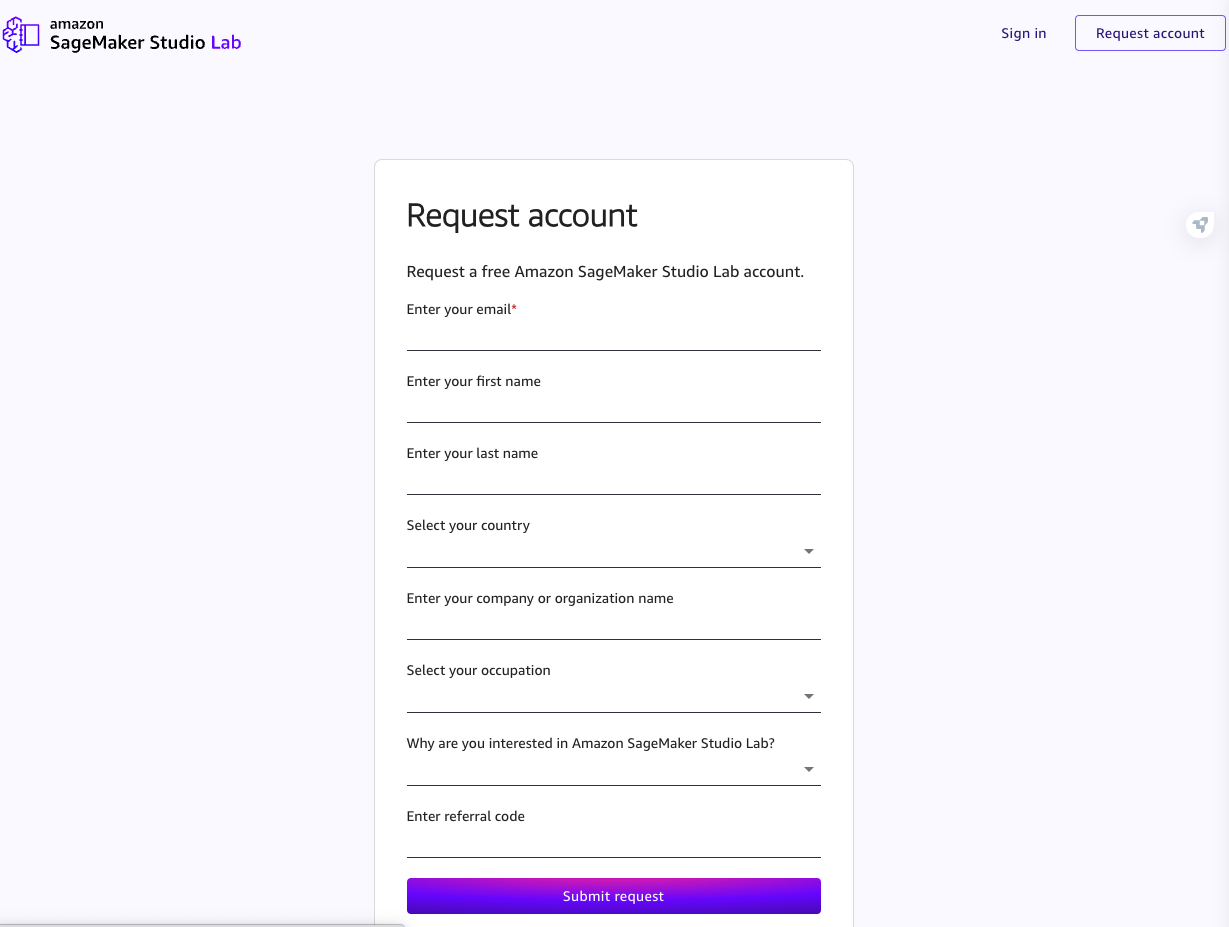
填写之后,到邮箱中验证账号
Studio Lab 项目
登陆成功之后,可以看到 Studio Lab 用户界面中的项目描述。如下图
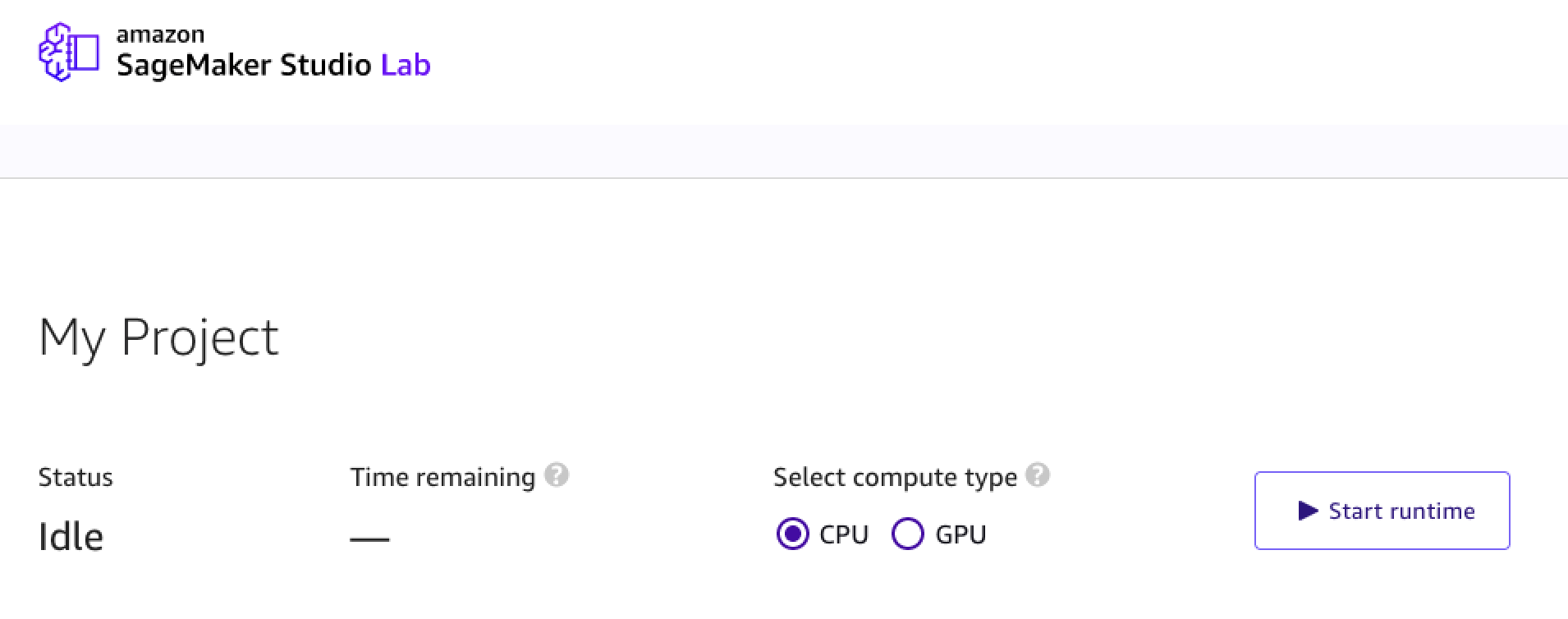
项目中包含了所有文件和文件夹,包括 Jupyter 笔记本。可以完全控制项目中的文件。项目中还包含了基于 JupyterLab 的用户界面。从此界面中,可以与 Jupyter 笔记本进行交互、编辑源代码文件、与 GitHub 集成以及连接到 Amazon S3。
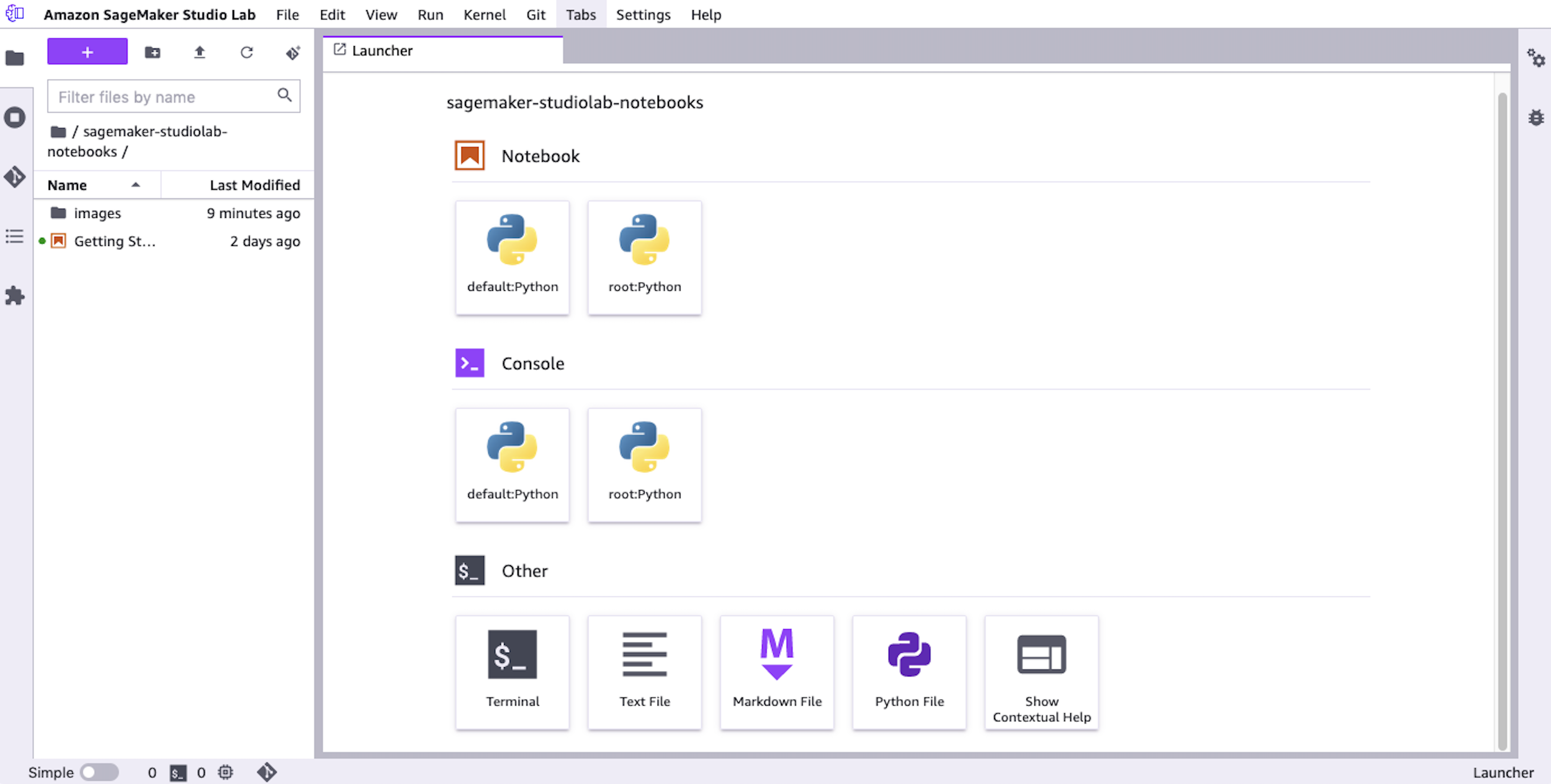
项目预览
打开文件浏览器并显示 Studio Lab 启动器的 Studio Lab 项目。如下图:
查看环境
要在 Studio Lab 中查看环境,你可以使用终端或 Jupyter 笔记本电脑。以下命令将适用于 Studio Lab 终端。
打开文件浏览器面板打开 Studio Lab 终端,选择文件浏览器顶部菜单上的加号 (+) 以打开启动器,然后选择终端。在 Studio Lab 终端上,通过运行以下命令列出 conda 环境。
conda env list
此命令输出 conda 环境的列表及其在文件系统中的位置。当你加入 Studio Lab 时,你会自动激活 studiolab conda 环境。以下是列出的环境的示例。
# conda environments: #
default /home/studio-lab-user/.conda/envs/default
studiolab * /home/studio-lab-user/.conda/envs/studiolab
studiolab-safemode /opt/amazon/sagemaker/safemode-home/.conda/envs/studiolab-safemode
base /opt/conda
核心代码
在项目中的实验室实例中新增一条状态为 Pending 的数据,稍等一会儿,状态会自动变为 InService,此时改实例为可使用状态。核心代码如下:
import sagemaker
sess = sagemaker.Session()
bucket = sess.default_bucket()
!aws s3 sync s3://sagemaker-sample-files/datasets/image/caltech-101/inference/ s3://{bucket}/ground-truth-demo/images/
print('Copy and paste the below link into a web browser to confirm the ten images were successfully uploaded to your bucket:')
print(f'https://s3.console.aws.amazon.com/s3/buckets/{bucket}/ground-truth-demo/images/')
print('\nWhen prompted by Sagemaker to enter the S3 location for input datasets, you can paste in the below S3 URL')
print(f's3://{bucket}/ground-truth-demo/images/')
print('\nWhen prompted by Sagemaker to Specify a new location, you can paste in the below S3 URL')
print(f's3://{bucket}/ground-truth-demo/labeled-data/')
计算实例类型
Amazon SageMaker Studio Lab 项目运行时基于 EC2 实例。如果计算实例的可用性无法得到保证,需要额外的存储或计算资源,考虑切换到 Studio。
CPU 和 GPU
Amazon SageMaker Studio Lab 提供 CPU和 GPU 选择。
CPU
其中 CPU 目的是为了高效处理各种任务,但是它可以同时运行的任务数量受到限制。对于机器学习,建议使用 CPU 来执行计算密集型算法,例如时间序列、预测和表格数据。
CPU 计算类型一次最多可运行 4 小时,24 小时内最多可运行 8 小时。
GPU
GPU 目的是为了同时渲染高分辨率图像和视频。建议使用 GPU 来执行深度学习任务,尤其是 Transformer 和计算机视觉。
GPU 计算类型一次最多 4 小时,24 小时内限制为 4 小时。
SageMaker 提供了 11 种机器学习环境,其中选择了 SageMaker Studio 实验室组件进行实战。读者可以通过注册免费账号,验证后即可登录并体验 Studio Lab 项目。
总结
本文介绍了 Amazon SageMaker 的工作原理和实战使用机器学习环境。机器学习的基本工作流程包括生成示例数据、训练模型和部署模型。
Peter DeSantis 的演讲展示了 Amazon在云计算领域持续创新的决心。Serverless不仅是技术的突破,更是满足企业需求的全新范式。这些创新产品和服务将为开发者和企业带来更大的灵活性、效率和成本效益,为云计算的未来开辟了崭新的道路。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LeetCode977有序数组的平方两种方法实现(java实现)
- 2024第四届中国数字化人才国际峰会 热点话题
- OMP_PLACES and OMP_PROC_BIND
- JavaWeb笔记之前端开发JQuery
- Go语言程序设计-第9章--使用共享变量实现并发
- AS7343 多光谱传感器 在树莓派上的使用
- 线程的深入学习(二)
- 第五节TypeScript 运算符
- 公司OA办公系统使用阿里云服务器怎么选配置?
- 不畏浮云遮望眼 ,只因它是SAR卫星!