PyTorch|保存与加载自己的模型
发布时间:2024年01月09日
训练好一个模型之后,我们往往要对其进行保存,除非下次用时想再次训练一遍。
下面以一个简单的回归任务来详细讲解模型的保存和加载。
来看这样一组数据:
x=torch.linspace(-1,1,50)x=x.view(50,1)y=x.pow(2)+0.3*torch.rand(50).view(50,1)
画图:
plt.scatter(x.numpy(),y.numpy())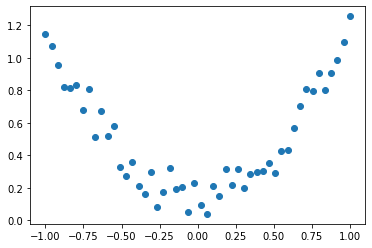
很显然,x与y基本呈二次函数关系,那么接下来我们就来拟合整个函数。
import torchimport matplotlib.pyplot as pltimport torch.nn as nnimport torch.optim as optimx=torch.linspace(-1,1,50)x=x.view(50,1)y=x.pow(2)+0.3*torch.rand(50).view(50,1)net1=nn.Sequential(nn.Linear(1,10),nn.ReLU(),nn.Linear(10,1))criterion=nn.MSELoss()optimizer=optim.SGD(net1.parameters(),lr=0.2)#训练模型for i in range(1000):pred=net1(x)loss=criterion(pred,y)optimizer.zero_grad()loss.backward()optimizer.step()#测试模型net1.eval()with torch.no_grad():y1=net1(x)plt.plot(x.numpy(),y1.numpy(),'r-')plt.scatter(x.numpy(),y.numpy())

结果似乎不错!
这里我们得到了一个网络net1,它可以被当作一个二次函数,用于描述之前的x,y数据的关系。
得到这个网络后,我们想保存它,主要有两种方式:
1,保存整个网络,包括训练后的各个层的参数
???????
#保存整个网络,包括训练后的各个层的参数torch.save(net1,'net1weight.pkl')
2,只保存训练好的网络的参数,速度更快
???????
#只保存训练好的网络的参数,速度更快torch.save(net1.state_dict(),'net1_params.pkl')
假设我们按第一种方式保存,那么下次想要使用次网络时需要这样做:
network=torch.load('net1weight.pkl')#测试模型network.eval()with torch.no_grad():y1=network(x)plt.plot(x.numpy(),y1.numpy(),'b-')plt.scatter(x.numpy(),y.numpy())

假设我们按第二种方式保存,那么下次想要使用次网络时需要这样做:
network=nn.Sequential(nn.Linear(1,10),nn.ReLU(),nn.Linear(10,1))network.load_state_dict(torch.load('net1_params.pkl'))???????
#测试模型network.eval()with torch.no_grad():y1=network(x)plt.plot(x.numpy(),y1.numpy(),'g-')plt.scatter(x.numpy(),y.numpy())
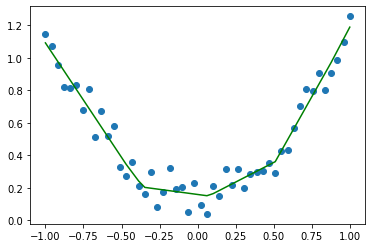
可以看出,第二次首先需要构造出一个一模一样的模型,接着再导入参数即可。当然,这只是个简单的回归模型,其它模型保存与加载同样如此。
总结一下:
模型保存与导入有两种方式:
方式一:???????
#模型保存torch.save(net1,'net1weight.pkl')#模型导入network=torch.load('net1weight.pkl')
方式二:???????
#模型保存torch.save(net1.state_dict(),'net1_params.pkl')#模型导入network.load_state_dict(torch.load('net1_params.pkl'))
文章来源:https://blog.csdn.net/m0_57569438/article/details/135465297
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CodeWave智能开发平台--03--目标:应用创建--10初级采购管理系统总结
- 有趣的代码——手机通讯录的简单实现
- 【JavaScript】 发送 POST 请求并带有 JSON 请求体的几种方法
- 基于Java SSM框架实现学生寝室管理系统项目【项目源码+论文说明】
- AWS 专题学习 P7 (FSx、SQS、SNS)
- Android BroadcastReceiver和EventBus区别
- 取消UD程序
- Python爬取哈尔滨旅游爆火视频数据并进行可视化分析
- uniapp中组件库丰富的Switch 开关选择器使用方法
- nestjs上传文件