Kubernetes架构概述
Kubernetes 是由谷歌开源的面向应用的容器集群部署和管理的系统,为容器化应用提供了资源调度、部署运行、服务发现、扩缩容等一整套功能。Kubernetes 最初来源于谷歌内部的 Borg。Kubernetes 的目标旨在消除编排物理/虚拟计算,网络和存储基础设施的负担,并使应用程序运营商和开发人员完全将重点放在以容器为中心的原语上进行自助运营。构建在Kubernetes上的系统不仅可以独立运行在物理机、虚拟机集群或者企业私有云上,也可以被托管在公有云上。Kubernetes整体架构的逻辑视图如下所示:

可以看到Kubenetes架构由Master和Node两种节点组成,而这两种角色分别对应控制节点和计算节点。其中"控制节点",即Master节点,由3个紧密协作的独立组件组合而成,分别是负责API服务的API Server、负责调度的Scheduler以及负责容器编排的Controller Manager。整个集群的持久化数据,则由API Server处理后保存在etcd中。
计算节点,即Node节点,由以下组件组成,分别管理Pod和同容器运行时交互和监控容器和节点资源的kubelet&、负责Service的透明代理兼负载均衡器,辅助将到达某个Service的访问请求转发到后端的多个Pod实例上的kube-proxy。此外,Kubernetes还支持通过插件的方式,来扩展资功能。而这些插件通常都部署在计算节点上,如coreDNS等。
API Server简介
API Server的核心功能是提供Kubernetes各类资源对象(如Pod、RC、Service等)的增、删、改、查及Watch等HTTP REST接口(资源对象的管理和监听),成为集群内各个功能模块之间数据交互和通信的中心枢纽,是整个系统的数据总线和数据中心。除此之外,它还是集群管理的API入口,是资源配额控制的入口,提供了完备的集群安全机制。
API Server通过一个名为kube-apiserver的进程提供服务,该进程运行在Master上。在默认情况下,kube-apiserver进程在本机的8080端口(对应参数–insecure-port)提供REST服务。也可以启动HTTPS安全端口(–secure-port=6443)来启动安全机制,加强 REST API访问的安全性。通常通过命令行工具kubectl与Kubernetes API Server交互,它们之间的接口是RESTful API。由于API Server是Kubernetes集群数据的唯一访问入口,因此安全性与高性能成为API Server设计和实现的两大核心目标。
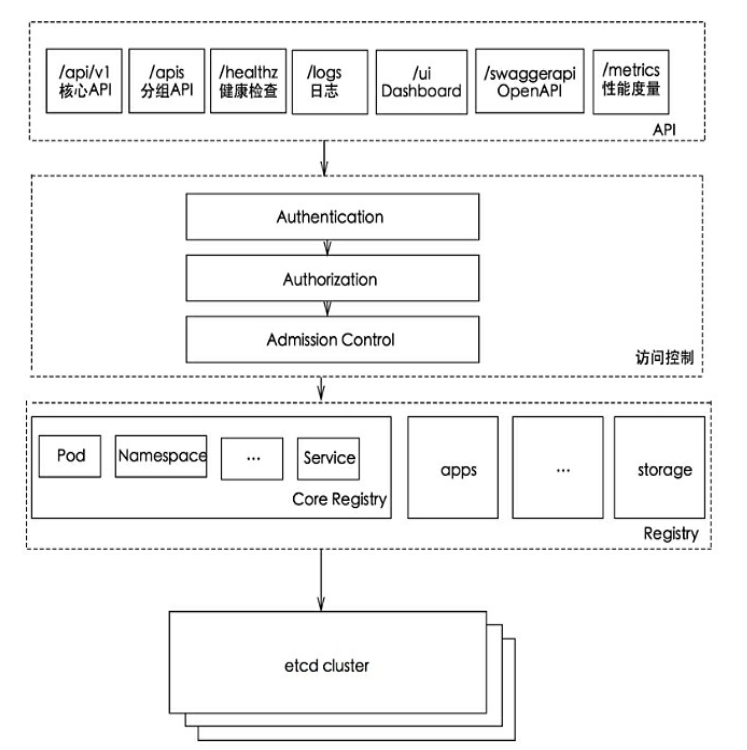
API Server架构从上到下可以分为以下几层:
(1) API层:主要以REST方式提供各种API接口,除了有 Kubernetes资源对象的CRUD和Watch等主要API,还有健康检查、UI、日志、性能指标等运维监控相关的API。Kubernetes从1.11版本开始废弃 Heapster监控组件,转而使用Metrics Server提供Metrics API接口,进一步完善了自身的监控能力。
(2) 访问控制层:当客户端访问API接口时,访问控制层负责对用户身份鉴权,验明用户身份,核准用户对Kubernetes资源对象的访问权限,然后根据配置的各种资源访问许可逻辑(Admission Control),判断是否允许访问。
(3) 注册表层:Kubernetes把所有资源对象都保存在注册表(Registry)中,针对注册表中的各种资源对象都定义了资源对象的类型、如何创建资源对象、如何转换资源的不同版本,以及如何将资源编码和解码为JSON或ProtoBuf格式进行存储。
(4) etcd数据库:用于持久化存储Kubernetes资源对象的KV数据库。etcd的Watch API接口对于API Server来说至关重要,因为通过这个接口,API Server创新性地设计了List-Watch这种高性能的资源对象实时同步机制,使Kubernetes可以管理超大规模的集群,及时响应和快速处理集群中的各种事件。
集群内功能模块的通信枢纽
Kubernetes API Server作为集群的核心,负责集群各功能模块之间的通信。集群内的各个功能模块通过API Server将信息存入etcd中,当需要获取和操作这些数据时,则通过API Server提供的REST接口(用GET、LIST或WATCH方法)来实现,从而实现各模块之间的信息交互。
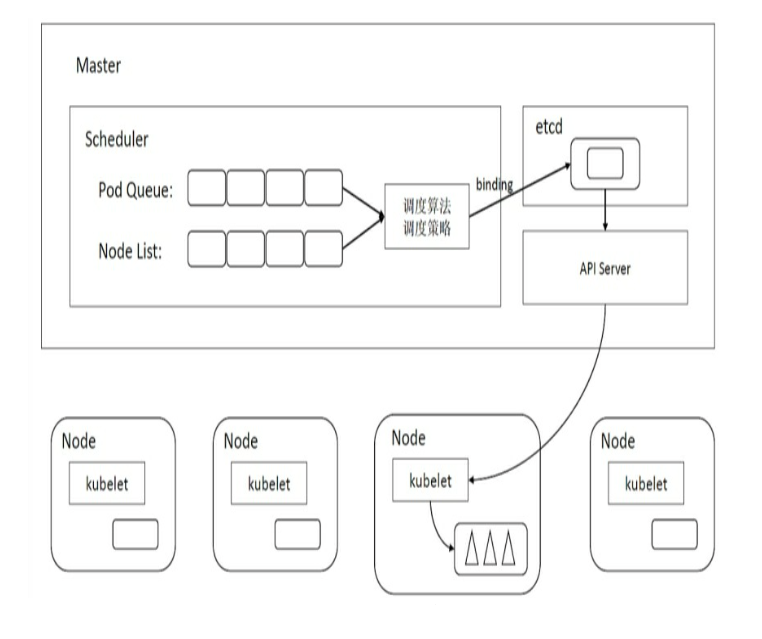
(1) Scheduler进程与API Server的交互。Scheduler在通过API Server的Watch接口监听到新建Pod副本的信息后,会检索并过滤所有符合该Pod要求的Node列表,开始执行Pod调度逻辑,在调度成功后将Pod绑定到目标节点上。
(2) Controller Manager进程与API Server的交互。如Controller Manager中的Node Controller模块通过API Server提供的Watch接口实时监控Node的信息,并做相应的处理。
(3) etcd进程与API Server的交互。API Server通过etcd的Watch API接口实现了List-Watch这种高性能的资源对象实时同步机制,使Kubernetes可以管理超大规模的集群,及时响应和快速处理集群中的各种事件。
(4) kubelet进程与API Server的交互。每个 Node 上的kubelet每隔一个时间周期就会调用一次API Server的REST接口报告自身状态,API Server在接收到这些信息后,会将节点状态信息更新到 etcd中。此外,kubelet也通过API Server的Watch接口监听Pod信息,如果监听到新的Pod副本被调度绑定到本节点,则执行Pod对应的容器创建和启动逻辑;如果监听到Pod对象被删除,则删除本节点上相应的Pod容器;如果监听到修改Pod的信息,kubelet就会相应地修改本节点的Pod容器。
(5) kube-proxy与API Server的交互。kube-proxy 通过 API Server的WATCH接口,监听Service、EndPoint、Node 等资源对象的变化情况。
Scheduler简介
Kubernetes Scheduler是负责Pod调度的组件,随着Kubernetes功能的不断增强和完善,Pod调度也变得越来越复杂,Kubernetes Scheduler内部的实现机制也在不断优化,从最初的两阶段调度机制(Predicates&Priorities,谓词(可理解为过滤)和优先级(可理解为打分))发展到后来的升级版(从1.6版本开始)的调度框架(Scheduling Framework),以满足越来越复杂的调度场景。
Scheduler调度流程简介
Kubernetes Scheduler的作用是将待调度的Pod(API新创建的Pod、Controller Manager为补足副本而创建的Pod等)按照特定的调度算法和调度策略绑定(Binding)到集群中某个合适的Node上,并将绑定信息写入etcd中。简单地说,Kubernetes Scheduler的作用就是通过调度算法为待调度Pod列表中的每个Pod都从Node列表中选择一个最适合的 Node,并将绑定信息同步到etcd。
Scheduler Framework简介
考虑到新的Scheduling Framework的代码和功能大部分来自之前旧的两阶段调度流程,所以这里有必要先介绍一下旧版本的两阶段调度流程。旧版本的Kubernetes Scheduler的调度总体上包括两个阶段:过滤(Filtering) + 打分(Scoring),随后就是绑定目标节点,完成调度。
(1) 过滤阶段:遍历所有目标Node,筛选出符合要求的候选节点。在此阶段,Scheduler会将不合适的所有Node节点全部过滤,只留下符合条件的候选节点。其具体方式是通过一系列特定的Filter(如磁盘Filter、节点上的可用端口Filter,等等)对每个Node都进行筛选,筛选完成后通常会有多个候选节点供调度,从而进入打分阶段;如果结果集为空,则表示当前还没有符合条件的Node节点,Pod会维持在Pending状态。
(2) 打分阶段:在过滤阶段的基础上,采用优选策略(xxx Priorities,如选出资源消耗最小的节点、优先选择含有指定Label的节点,等等)计算出每个候选节点的积分,积分最高者胜出,因为积分最高者表示最佳人选。挑选出最佳节点后,Scheduler会把目标Pod安置到此节点上,调度完成。
考虑到旧版本的Kubernetes Scheduler不足以支持更复杂和灵活的调度场景,因此在Kubernetes 引入一个新的调度机制——Scheduler Framework。从整个调度流程来看,新的Scheduler Framework 是在旧流程的基础上增加了一些扩展点(基于调度Stage的扩展点),同时支持用户以插件的方式(Plugin)进行扩展。新的调度流程如下图所示:

多调度器特性
Kubernetes自带一个默认调度器,从1.2版本开始引入自定义调度器的特性,支持使用用户实现的自定义调度器,多个自定义调度器可以与默认的调度器同时运行,由Pod选择是用默认的调度器调度还是用某个自定义调度器调度。
Kubernetes通过一个Scheduler进程加上多个配置文件的方式来实现多调度器特性。只要针对不同的调度规则编写不同的Profile配置文件,并给它们起一个自定义Scheduler的名称,然后把这个配置文件传递给Kubernetes Scheduler加载、生效,Kubernetes Scheduler就立即实现了多调度器支持的特性。
Controller Manager简介
一般来说,智能系统和自动系统通常会通过一个"操作系统"不断修正系统的工作状态。在Kubernetes集群中,每个Controller都是这样的一个"操作系统",它们通过API Server提供的(List-Watch)接口实时监控集群中特定资源的状态变化,当发生各种故障导致某资源对象的状态变化时,Controller会尝试将其状态调整为期望的状态。比如当某个Node意外宕机时,Node Controller会及时发现此故障并执行自动化修复流程,确保集群始终处于预期的工作状态下。Controller Manager是 Kubernetes中各种操作系统的管理者,是集群内部的管理控制中心,也是Kubernetes自动化功能的核心。这里介绍常见的几种Controller。
ResourceQuota Controller
作为完备的企业级的容器集群管理平台,Kubernetes也提供了 ResourceQuota Controller(资源配额管理)这一高级功能,资源配额管理确保指定的资源对象在任何时候都不会超量占用系统物理资源,避免由于某些业务进程在设计或实现上的缺陷导致整个系统运行紊乱甚至意外宕机,对整个集群的平稳运行和稳定性都有非常重要的作用。
目前Kubernetes支持如下三个层次的资源配额管理:
(1) 容器级别,可以对一个容器的CPU和Memory的可用资源进行限制。
(2) Pod级别,可以对一个Pod内所有容器的可用资源进行限制。
(3) Namespace级别,为Namespace(多租户)级别的资源限制,包括:Pod数量、Replication Controller数量、Service数量、ResourceQuota数量、Secret数量和可持有的PV数量等。
Kubernetes的配额管理是通过Admission Control(准入控制)来控制的,Admission Control当前提供了两种方式的配额约束,分别是 LimitRanger与ResourceQuota,其中LimitRanger作用于Pod和Container;ResourceQuota则作用于Namespace,限定一个Namespace里各类资源的使用总额。
Namespace Controller
Namespace Controller定时通过API Server读取Namespace的信息。如果Namespace被API标识为优雅删除(通过设置删除期限实现,即设置 DeletionTimestamp属性),则将该NameSpace的状态设置成Terminating并保存在etcd中。同时,Namespace Controller删除该Namespace下的 ServiceAccount、RC、Pod、Secret、PersistentVolume、ListRange、ResourceQuota和Event等资源对象。
在Namespace的状态被设置成Terminating后,由Admission Controller的NamespaceLifecycle插件来阻止为该Namespace创建新的资源。同时,在Namespace Controller删除该Namespace中的所有资源对象后,Namespace Controller会对该Namespace执行finalize操作,删除 Namespace的spec.finalizers域中的信息。
如果Namespace Controller观察到Namespace设置了删除期限,同时Namespace的spec.finalizers域值是空的,那么Namespace Controller将通 过API Server删除该Namespace资源。
Service Controller与Endpoints Controller
Endpoints表示一个Service对应的所有Pod副本的访问地址,Endpoints Controller就是负责生成和维护所有Endpoints对象的控制器。
Endpoints Controller负责监听Service和对应的Pod副本的变化,如果监测到Service被删除,则删除和该Service同名的Endpoints对象。如果监测到新的Service被创建或者修改,则根据该Service信息获得相关的Pod列表,然后创建或者更新Service对应的Endpoints对象。如果监测到Pod的事件,则更新它所对应的Service的Endpoints对象(增加、删除或者修改对应的Endpoint条目)。
Service Controller则是Kubernetes集群与外部通信的一个接口控制器。Service Controller监听Service的变化,如果该Service是一个LoadBalancer类型的Service(externalLoadBalancers=true),则Service Controller确保该Service对应的LoadBalancer实例在外部的云平台上被相应地创建、删除及更新路由转发表(根据Endpoints的条目)。
Service、Endpoints、Pod的关系
Service、Endpoints、Pod的关系如下图所示:
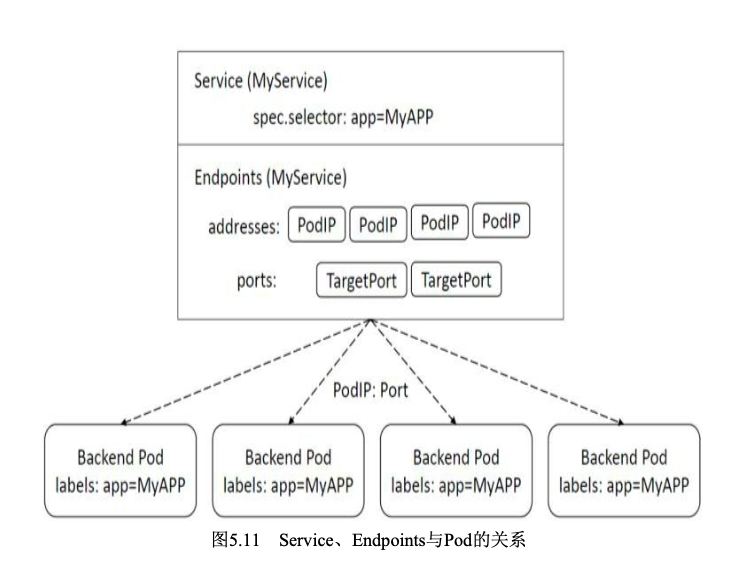
可以看到,Endpoints记录一个Service和多个Pod的对应关系,帮助从Service路由到特定的Pod。
kubelet 简介
在Kubernetes集群中,在每个Node上都会启动一个kubelet服务进程。在Node节点上,最核心的一个组件是kubelet。kubelet负责节点、Pod的管理,容器的健康检查,资源监控,与容器运行时交互等职责。
在与容器运行时交互时,kubelet依赖的是—个称作CRI(container runtime interface)的远程调用接口,该接口定义了容器运行时的各项核心操作,比如启动一个容器需要的所有参数。kubelet的另—个重要功能,则是调用网络插件和存储插件为容器配置网络和持久化存储。这两个插件与kubelet进行交互的接口,分别是CNI(container networking interface)和CSI(container storage interface)。Kubectl通过接口标准化实现了对特定组件的解耦。
节点管理
节点通过设置kubelet的启动参数"–register-node",来决定是否向API Server注册自己。如果在集群运行过程中遇到集群资源不足的情况,用户就很容易通过添加机器及运用kubelet的自注册模式来实现扩容。在某些情况下,Kubernetes集群中的某些kubelet没有选择自注册模式,用户需要自己去配置Node的资源信息,同时告知Node上kubelet API Server的位置。
kubelet在启动时通过API Server注册节点信息,并定时向API Server 发送节点的新消息,API Server在接收到这些信息后,会将其写入etcd中。通过kubelet的启动参数–node-status-update-frequency可设置kubelet 每隔多长时间向API Server报告节点的状态,默认为10秒。
Pod管理
所有以非API Server方式创建的Pod都叫作静态Pod(Static Pod)。反之,通过API Server方式创建的Pod叫做动态Pod。
常见的静态Pod创建方式有两种:(1) 静态Pod配置文件:kubelet通过启动参数–config指定目录下的Pod YAML文件(默认目录为/etc/kubernetes/manifests/),kubelet会持续监控指定目录下的文件变化,以创建或删除Pod。这种类型的Pod没有通过kube-controller-manager管理。另外,可以 通过启动参数–file-check-frequency设置检查该目录的时间间隔,默认为 20 秒。(2) HTTP端点(URL):通过–manifest-url参数设置,通过–http- check-frequency设置检查该HTTP端点数据的时间间隔,默认为 20 秒。
kubelet将静态Pod的状态汇报给API Server,API Server为该Static Pod创建一个镜像Pod(Mirror Pod)与其匹配。镜像Pod的状态将真实反映静态Pod的状态。当静态Pod被删除时,与之相对应的镜像Pod也会被删除。
每个 Node 上的kubelet每隔一个时间周期就会调用一次API Server的REST接口报告自身状态,API Server在接收到这些信息后,会将节点状态信息更新到etcd中。此外,kubelet也通过API Server的Watch接口监听Pod信息,如果监听到新的Pod副本被调度绑定到本节点,则执行Pod对应的容器创建和启动逻辑;如果监听到Pod对象被删除,则删除本节点上相应的Pod容器;如果监听到修改Pod的信息,kubelet就会相应地修改本节点的Pod容器。
容器健康检查
Kubernetes对Pod的健康状态可以通过三类探针来检查: LivenessProbe(存活探针)、ReadinessProbe(就绪探针)及StartupProbe(启动探针),其中最主要的探针为LivenessProbe与ReadinessProbe,kubelet会定期执行这两类探针来诊断容器的健康状况。其中LivenessProbe探针,用于判断容器是否健康并反馈给kubelet,如果LivenessProbe探针探测到容器不健康,则kubelet将删除该容器,并根据容器的重启策略做相应的处理;如果一个容器不包含LivenessProbe探针,则kubelet会认为该容器的LivenessProbe探针返回的值是Success。而ReadinessProbe探针,用于判断容器是否启动完成,且准备接收请求。如果ReadinessProbe探针检测到容器启动失败,则Pod的状态将被修改,Endpoint Controller将从Service的Endpoint中删除包含该容器所在Pod的IP地址的Endpoint条目。
此外,为了自定义Pod的可用性探测方式,Kubernetes在1.14版本引入Pod Readiness Gates。Pod Readiness Gates给予了Pod之外的组件控制某个Pod就绪的能力,通过Pod Readiness Gates机制,用户可以设置自定义的Pod可用性探测方式来告诉Kubernetes某个Pod是否可用,具体使用方式是用户提供一个外部的控制器(Controller)来设置相应Pod的可用性状态。
资源监控
在Kubernetes集群中,应用程序的执行情况可以在不同的级别监测到,这些级别包括容器、Pod、Service和整个集群。作为Kubernetes集群的一部分,Kubernetes希望提供给用户详细的各个级别的资源使用信息,这将使用户深入地了解应用的执行情况,并找到应用中可能的瓶颈。
kubelet作为连接Kubernetes Master和各Node的桥梁,管理运行在Node上的Pod和容器。kubelet将每个Pod都转换成它的成员容器,同时获取单独的容器使用统计信息,然后通过该REST API暴露这些聚合后的Pod资源使用的统计信息。
从Kubernetes 1.8版本开始,性能指标数据的查询接口升级为标准的Metrics API,后端服务则升级为全新的Metrics Server。Metrics Server 可以提供Core Metrics(核心指标),包括Node和Pod的CPU和内存使用数据。其他 Custom Metrics(自定义指标)则由第三方组件(如Prometheus)采集和存储。
容器运行时
kubelet负责本节点上所有Pod的全生命周期管理,其中就包括相关容器的创建和销毁这种基本操作。容器的创建和销毁等操作的代码不属于Kubernetes的代码范畴。kubelet需要通过某种进程间的调用方式如gRPC来实现与Docker容器引擎之间的调用控制功能。
"容器"概念是早于Docker出现的,容器技术最早来自Linux,又被称为Linux Container。LXC项目是一个Linux容器的工具集,也是真正意义上的一个Container Runtime,它的作用就是将用户的进程包装成一个Linux容器并启动运行。Docker最初使用了LXC项目代码作为Container Runtime来运行容器,但从0.9版本开始就使用新一代容器运行时Libcontainer替代,再后来,Libcontainer项目更名为runC,被Docker公司捐赠给了OCI组织,成为OCI容器运行时规范的第1个标准参考实现。所以,LXC与runC其实都可被看作开源的 Container Runtime,但它们都属于低级别的容器运行时(low-level container runtimes),因为它们不涉及容器运行时所依赖的镜像操作功能,如拉取镜像,也没有对外提远程供编程接口以方便其他应用集成。
后来又有了高级别容器运行时(high-level container runtimes),其中最知名的就是Docker公司开源的containerd。containerd 被设计成嵌入一个更大的系统,如Kubernetes中使用,而不是直接由开发人员或终端用户使用,containerd底层驱动runC来实现底层的容器运行时,对外则提供了镜像拉取及基于gRPC接口的容器CRUD封装接口。发展至今,containerd已经从Docker里的一个内部组件,变成一个流行的、工业级的开源容器运行时,已经支持容器镜像的获取和存储、容器的执行和管理、存储和网络等相关功能。
除了containerd,还有类似的其他一些高级别容器运行时也都在runC的基础上发展而来,目前比较流行的有红帽开源的CRI-O、openEuler社区开源的iSula等。这些Container Runtime还有另外一个共同特点,即都实现了Kubernetes提出的CRI接口规范(Container Runtime Interface), 可以直接接入Kubernetes中。
CRI接口规范,就是容器运行时接口规范,这个规范是Kubernetes顺应容器技术标准化发展潮流的一个重要历史产物,早在Kubernetes 1.5版本中就引入了CRI接口规范。引入了CRI接口规范后,kubelet就可以通过CRI插件来实现容器的全生命周期控制,不同厂家的Container Runtime只需实现对应的 CRI插件代码即可,Kubernetes无须重新编译就可以使用更多的容器运行时。
随着CRI机制的成熟及第三方Container Runtime的不断涌现,用户有了新的需求:在一个Kubernetes集群中配置并启用多种Container Runtime,不同类型的Pod可以选择不同特性的Container Runtime来运行,以实现资源占用或者性能、稳定性等方面的优化,这就是RuntimeClass出现的背景和动力。Kubernetes从1.12版本开始引入 RuntimeClass,用于在启动容器时选择特定的容器运行时。在1.14 之后,它又作为一种内置集群资源对象 RuntimeClass 被引入进来。1.16 又在 1.14 的基础上扩充了 Scheduling 和 Overhead 的能力。
通过在配置文件中指定Container Runtime 的类型,一旦创建好RuntimeClass资源,就可以通过Pod中的 spec.runtimeClassName字段与它进行关联了。当目标Pod被调度到某个具体的kubelet时,kubelet就会通过CRI接口调用指定的Container Runtime 来运行该Pod,如果指定的RuntimeClass不存在,无法运行相应的 Container Runtime,那么Pod会进入Failed状态。
kube-proxy 简介
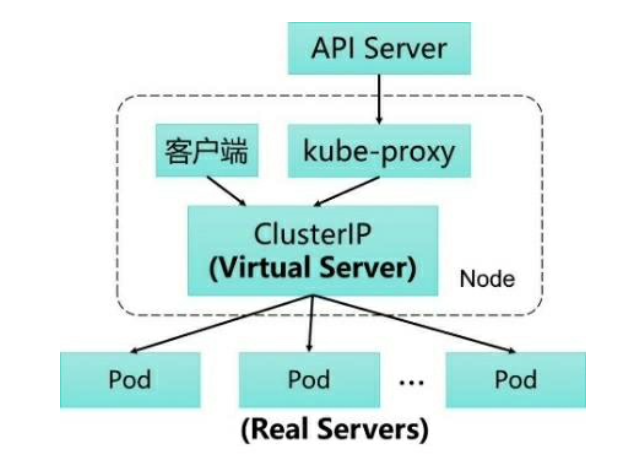
Kubernetes集群的每个Node上都会运行一个kube-proxy服务进程,可以把这个进程看作Service的透明代理兼负载均衡器,其核心功能是将到某个Service的访问请求转发到后端的多个Pod实例上。
kube-proxy在运行过程中动态创建与Service相关的iptables规则,这些规则实现了将访问服务(ClusterIP或NodePort)的请求负载分发到后端Pod的功能。由于iptables机制针对的是本地的kube-proxy端口,所以在每个Node上都要运行kube-proxy组件,这样一来,在Kubernetes集群内部,可以在任意Node上发起对Service的访问请求。综上所述,由于kube-proxy的作用,客户端在 Service调用过程中无须关心后端有几个Pod,中间过程的通信、负载均衡及故障恢复都是透明的。
Client向Service的请求流量通过IPVS(IP Virtual Server)转发到目标Pod,不经过kube-proxy进程的转发,kube-proxy进程只承担了控制层面的功能(可见kube-proxy本身无法实现请求的转发),即通过API Server的Watch接口实时跟踪Service与Endpoint的变更信息,并更新Node节点上的IPVS。
iptables与IPVS虽然都是基于Netfilter实现的,但因为定位不同,二者有着本质的差别:iptables是为防火墙设计的;IPVS专门用于高性能负载均衡,并使用更高效的数据结构(哈希表),允许几乎无限的规模。
由于IPVS无法提供包过滤、airpin-masquerade tricks(地址伪装)、 SNAT等功能,因此在某些场景(如NodePort的实现)下还要与iptables搭配使用。在IPVS模式下,kube-proxy又做了重要的升级,即使用iptables的扩展ipset,而不是直接调用iptables来生成规则链。
参考
《Kubernetes权威指南 从Docker到Kubernetes实践全接触》 龚正 吴治辉 闫健勇 编著
《深入剖析Kubernetes》 张磊 著
https://lib.jimmysong.io/kubernetes-handbook/architecture/ Kubernetes 架构
https://zhuanlan.zhihu.com/p/149403551 了解Kubernetes内部的架构
http://docs.kubernetes.org.cn/251.html Kubernetes 架构
https://zhuanlan.zhihu.com/p/444114515 Kubernetes核心架构与高可用集群详解
https://zhuanlan.zhihu.com/p/161347454 Kubernetes: 微内核的分布式操作系统
https://zhuanlan.zhihu.com/p/467382099 kubernetes核心组件的运行机制
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Odoo16 实用功能之在Form视图控制字段的显示以及禁止编辑和禁止创建
- JAVA中的回调函数
- 如何使用 Docker 搭建 Jenkins 环境?从安装到精通
- 几个简单好用Python库,让你工作效率翻倍
- 基于SSM+Bootstrap的垃圾分类管理系统(Java毕业设计)
- 在线培训考试系统的实施步骤与注意事项
- 【JVM】2.字节码文件详解
- 中国人民大学与加拿大女王大学金融硕士项目——在职读研,拒绝焦虑
- 动手搓一个kubernetes管理平台(2)-后端权限设计
- windows安装wsl ubuntu