Web自动化测试(一)(全网最给力自动化教程)
欢迎您来阅读和练手!您将会从本章的详细讲解中,获取很大的收获!开始学习吧!
2.1 操作元素基本方法
前言
前面已经把环境搭建好了,从这篇开始,正式学习selenium的webdriver框架。我们平常说的 selenium自动化,其实它并不是类似于QTP之类的有GUI界面的可视化工具,我们要学的是webdriver框架的API。
本篇主要讲如何用Python调用webdriver框架的API,对浏览器做一些常规的操作,如打开、前进、后退、刷新、设置窗口大小、截屏、退出等操作。
2.1.1 打开网页
1.从selenium里面导入webdriver模块
2.打开Firefox浏览器(Ie和Chrome对应下面的)
3.打开百度网址

2.1.2 设置休眠
1.由于打开百度网址后,页面加载需要几秒钟,所以最好等到页面加载完成后再继续下一步操作
2.导入time模块,time模块是Python自带的,所以无需下载
3.设置等待时间,单位是秒(s),时间值可以是小数也可以是整数

2.1.3 页面刷新
1.有时候页面操作后,数据可能没及时同步,需要重新刷新
2.这里可以模拟刷新页面操作,相当于浏览器输入框后面的刷新按钮

2.1.4 页面切换
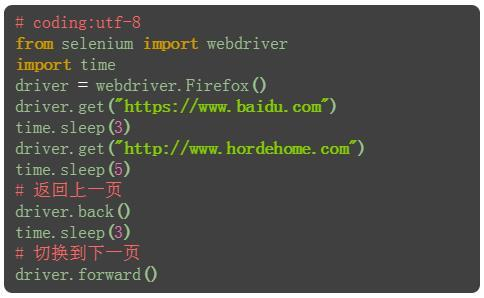
1.当在一个浏览器打开两个页面后,想返回上一页面,相当于浏览器左上角的左箭头按钮。
2.返回到上一页面后,也可以切换到下一页,相当于浏览器左上角的右箭头按钮。
2.1.5 设置窗口大小
1.可以设置浏览器窗口大小,如设置窗口大小为手机分辨率540*960
2.也可以最大化窗口

?2.1.6 截屏
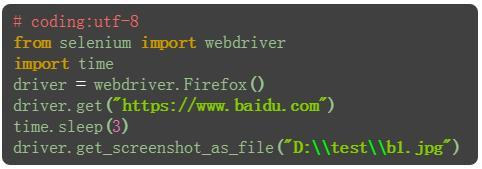
1. 打开网站之后,也可以对屏幕截屏
2.截屏后设置指定的保存路径+文件名称+后缀
2.1.7 退出
1.退出有两种方式,一种是close;另外一种是quit。
2.close用于关闭当前窗口,当打开的窗口较多时,就可以用close关闭部分窗口。
3.quit用于结束进程,关闭所有的窗口。
4.最后结束测试,要用quit。quit可以回收c盘的临时文件。

掌握了浏览器的基本操作后,接下来就可以开始学习元素定位了,元素定位需要有一定的html基础。没有基础的可以按下浏览器的F12快捷键先看下html的布局,先了解一些就可以了。
2.1.8 加载浏览器配置
启动浏览器后,发现右上角安装的插件不见了,这是因为webdriver启动浏览器时候,是开的一个虚拟线程,跟手工点开是有区别的,selenium的一切操作都是模拟人工(不完全等于人工操作)。
加载Firefox配置
? ?有小伙伴在用脚本启动浏览器时候发现原来下载的插件不见了,无法用firebug在打开的页面上继续定位页面元素,调试起来不方便 。加载浏览器配置,需要用FirefoxProfile(profile_directory)这个类来加载,profile_directory既为浏览器配置文件的路径地址。
一、遇到问题
1.在使用脚本打开浏览器时候,发现右上角原来下载的插件firebug不见了,到底去哪了呢?
2.用脚本去打开浏览器时候,其实是重新打开了一个进程,跟手动打开浏览器不是一个进程。
所以没主动加载插件,不过selenium里面其实提供了对应的方法去打开,只是很少有人用到。
二、FirefoxProfile
1.要想了解selenium里面API的用法,最好先看下相关的帮助文档打开cmd窗口,
输入如下信息:
->python
->from selenium import webdriver
->help(webdriver.FirefoxProfile)

Help on class FirefoxProfile in module
selenium.webdriver.firefox.firefox_profile:
class FirefoxProfile(builtin.object)
| ?Methods defined here:
|
| ?init(self, profile_directory=None)
| ? ? ?Initialises a new instance of a Firefox Profile
| ? ?
| ? ? ?:args:
| ? ? ? - profile_directory: Directory of profile that you want to use.
| ? ? ? ? This defaults to None and will create a new
| ? ? ? ? directory when object is created.
2.翻译过来大概意思是说,这里需要profile_directory这个配置文件路径的参数
3.profile_directory=None,如果没有路径,默认为None,启动的是一个新的,有的话就加载指定的路径。
三、profile_directory
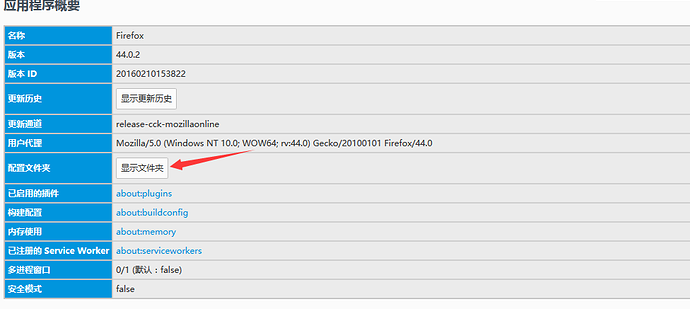
1.问题来了:Firefox的配置文件地址如何找到呢?
2.打开Firefox点右上角设置>?(帮助)>故障排除信息>显示文件夹
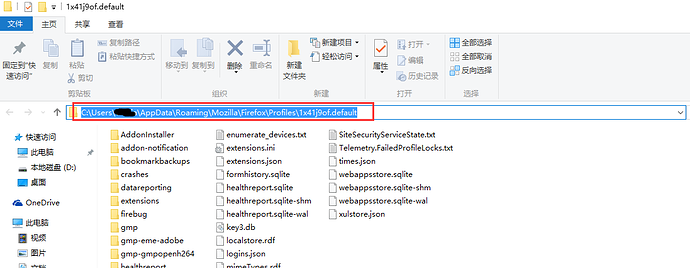
3.打开后把路径复制下来就可以了:
C:\Users\xxx\AppData\Roaming\Mozilla\Firefox\Profiles\1x41j9of.default
四、启动配置文件
1.由于文件路径存在字符:\ ,反斜杠在代码里是转义字符,这个有点代码基础的应该都知道。
不懂什么叫转义字符的,自己翻书补下基础吧!
2.遇到转义字符,为了不让转义,有两种处理方式:
第一种:\ (前面再加一个反斜杠)
第二种:r”\"(字符串前面加r,使用字符串原型)
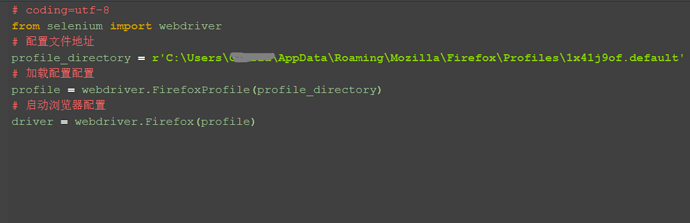
五、参考代码:
# coding=utf-8 from selenium import webdriver # 配置文件地址 profile_directory = r'C:\Users\xxx\AppData\Roaming\Mozilla\Firefox\Profiles\1x41j9of.default'
# 加载配置配置
profile = webdriver.FirefoxProfile(profile_directory)
# 启动浏览器配置
driver = webdriver.Firefox(profile)
?其实很简单,在调用浏览器的前面,多加2行代码而已,主要是要弄清楚原理。
2.2 常用8种元素定位(Firebug和firepath)
前言???
元素定位在firefox上可以安装Firebug和firepath辅助工具进行元素定位。
2.2.1 环境准备
1.浏览器选择:Firefox
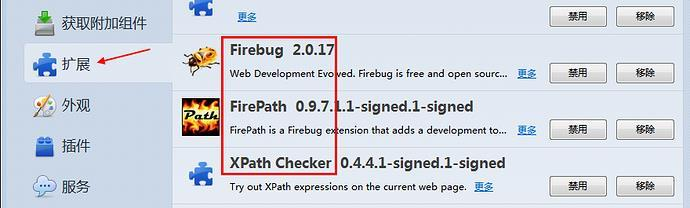
2.安装插件:Firebug和FirePath(设置》附加组件》搜索:输入插件名称》下载安装后重启浏览器)
3.安装完成后,页面右上角有个小爬虫图标
4.快速查看xpath插件:XPath Checker这个可下载,也可以不用下载
5.插件安装完成后,点开附加组件》扩展,如下图所示
2.2.2 查看页面元素
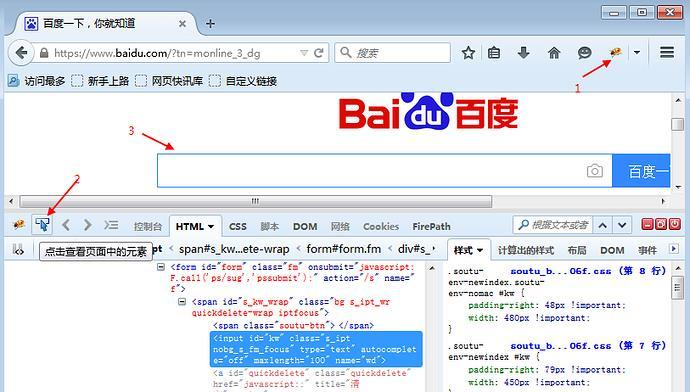
以百度搜索框为例,先打开百度网页
1.点右上角爬虫按钮
2.点左下角箭头
3.将箭头移动到百度搜索输入框上,输入框高亮状态
4.下方红色区域就是单位到输入框的属性:
<input id="kw" class="s_ipt" type="text" autocomplete="off" maxlength="100" name="wd">
2.2.3 find_element_by_id()
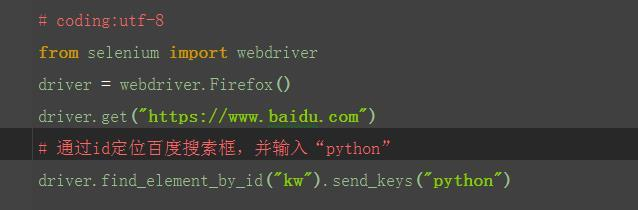
1.从上面定位到的元素属性中,可以看到有个id属性:id="kw",这里可以通过它的id属性定位到这个元素。
2.定位到搜索框后,用send_keys()方法,输入文本。
2.2.4 find_element_by_name()?
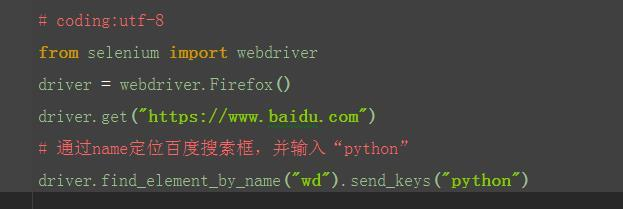
???1.从上面定位到的元素属性中,可以看到有个name属性:name="wd",这里可以通过它的name属性单位到这个元素。
????说明:这里运行后会报错,说明这个搜索框的name属性不是唯一的,无法通过name属性直接定位到输入框
2.2.5 find_element_by_class_name()
1.从上面定位到的元素属性中,可以看到有个class属性:class="s_ipt",这里可以通过它的class属性定位到这个元素。

2.2.6 find_element_by_tag_name()
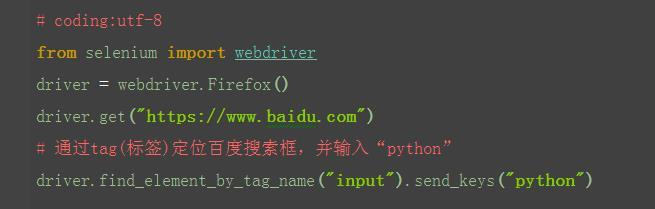
1.从上面定位到的元素属性中,可以看到每个元素都有tag(标签)属性,如搜索框的标签属性,就是最前面的input。
2.很明显,在一个页面中,相同的标签有很多,所以一般不用标签来定位。以下例子,仅供参考和理解,运行肯定报错。
?2.2.7 find_element_by_link_text()
1.定位百度页面上"hao123"这个按钮
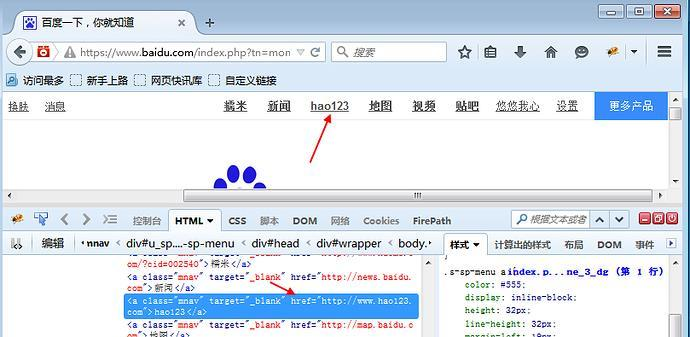
查看页面元素:
<a class="mnav" target="_blank" href="http://www.hao123.com">hao123</a>
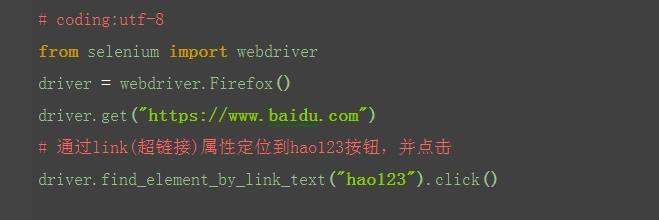
2.从元素属性可以分析出,有个href?= "http://www.hao123.com
说明它是个超链接,对于这种元素,可以用以下方法:
?2.2.8 find_element_by_partial_link_text()
1.有时候一个超链接它的字符串可能比较长,如果输入全称的话,会显示很长,这时候可以用一模糊匹配方式,截取其中一部分字符串就可以了
2.如“hao123”,只需输入“ao123”也可以定位到

2.2.9 find_element_by_xpath()
1.以上定位方式都是通过元素的某个属性来定位的,如果一个元素它既没有id、name、class属性也不是超链接,这么办呢?或者说它的属性很多重复的。这个时候就可以用xpath解决。
2.xpath是一种路径语言,跟上面的定位原理不太一样,首先第一步要先学会用工具查看一个元素的xpath。
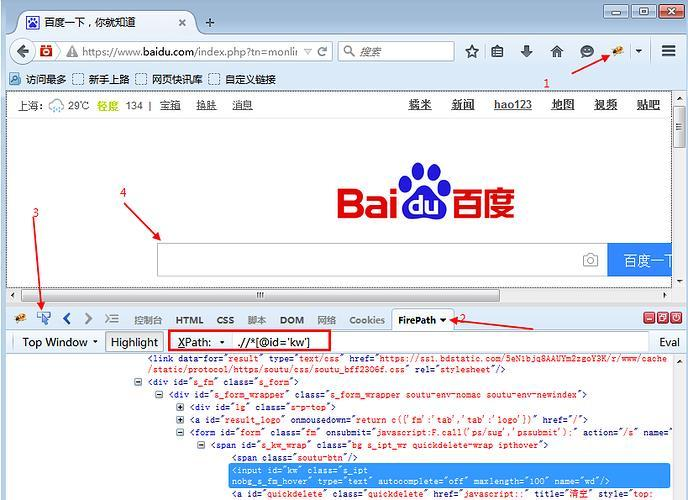
?3.按照上图的步骤,在FirePath插件里copy对应的xpath地址。

?2.2.10 find_element_by_css_selector()
1.css是另外一种语法,比xpath更为简洁,但是不太好理解。这里先学会如何用工具查看,后续的教程再深入讲解
2.打开FirePath插件选择css
3.定位到后如下图红色区域显示
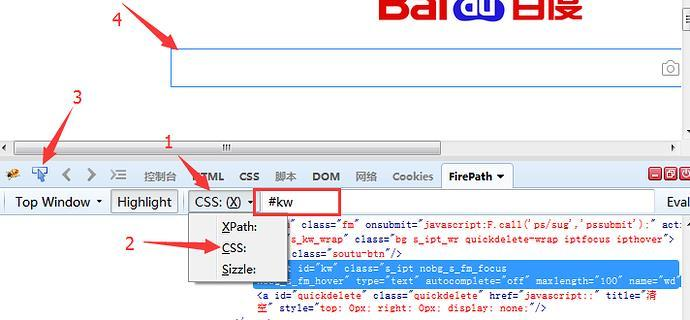
总结:
selenium的webdriver提供了18种(注意是18种,不是8种)的元素定位方法,前面8种是通过元素的属性来直接定位的,后面的xpath和css定位更加灵活,需要重点掌握其中一个。
前八种是大家都熟悉的,经常会用到的:
1.id定位:find_element_by_id(self, id_) 2.name定位:find_element_by_name(self, name) 3.class定位:find_element_by_class_name(self, name) 4.tag定位:find_element_by_tag_name(self, name) 5.link定位:find_element_by_link_text(self, link_text) 6.partial_link定位find_element_by_partial_link_text(self, link_text) 7.xpath定位:find_element_by_xpath(self, xpath) 8.css定位:find_element_by_css_selector(self, css_selector)
这八种是复数形式(2.8和2.27章节有介绍)
9.id复数定位find_elements_by_id(self, id_) 10.name复数定位find_elements_by_name(self, name) 11.class复数定位find_elements_by_class_name(self, name) 12.tag复数定位find_elements_by_tag_name(self, name) 13.link复数定位find_elements_by_link_text(self, text) 14.partial_link复数定位find_elements_by_partial_link_text(self, link_text) 15.xpath复数定位find_elements_by_xpath(self, xpath) 16.css复数定位find_elements_by_css_selector(self, css_selector
这两种是参数化的方法,会在以后搭建框架的时候,会经常用到PO模式,才会用到这个参数化的方法(将会在4.2有具体介绍)
17.find_element(self, by='id', value=None) 18.find_elements(self, by='id', value=None)
2.3 xpath定位
前言????
在上一篇简单的介绍了用工具查看目标元素的xpath地址,工具查看比较死板,不够灵活,有时候直接复制粘贴会定位不到。这个时候就需要自己手动的去写xpath了,这一篇详细讲解xpath的一些语法。
什么是xpath呢?
官方介绍:XPath即为XML路径语言,它是一种用来确定XML文档中某部分位置的语言。反正小编看这个介绍是云里雾里的,通俗一点讲就是通过元素的路径来查找到这个元素的。
2.3.1 xpath:属性定位
1.xptah也可以通过元素的id、name、class这些属性定位,如下图:
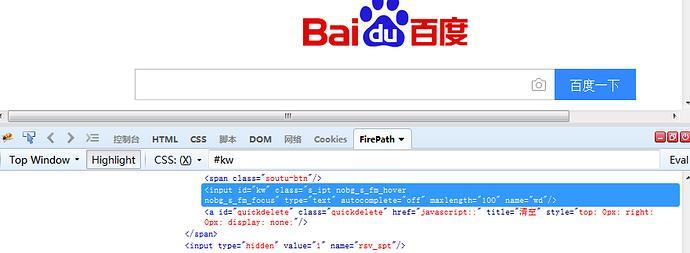
2.于是可以用以下xpath方法定位

2.3.2 xpath:其它属性
1.如果一个元素id、name、class属性都没有,这时候也可以通过其它属性定位到
2.3.3 xpath:标签
1.有时候同一个属性,同名的比较多,这时候可以通过标签筛选下,定位更准一点
2.如果不想制定标签名称,可以用*号表示任意标签
3.如果想制定具体某个标签,就可以直接写标签名称
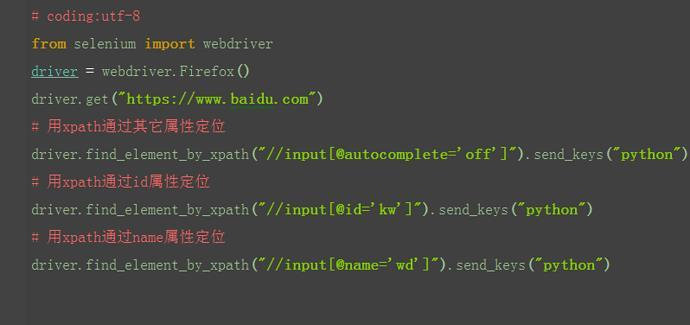
2.3.4 xpath:层级
1.如果一个元素,它的属性不是很明显,无法直接定位到,这时候我们可以先找它老爸(父元素)。
2.找到它老爸后,再找下个层级就能定位到了。
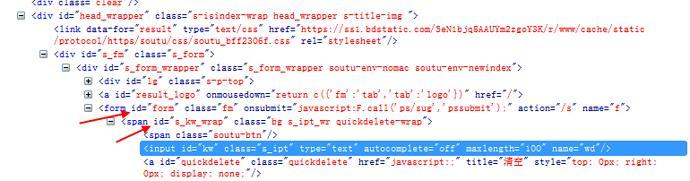
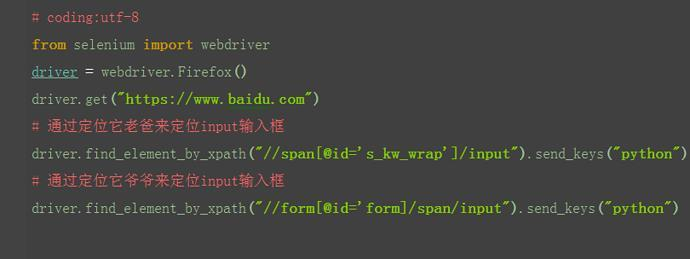
3.如上图所示,要定位的是input这个标签,它的老爸的id=s_kw_wrap。
4.要是它老爸的属性也不是很明显,就找它爷爷id=form。
5.于是就可以通过层级关系定位到。
2.3.5 xpath:索引
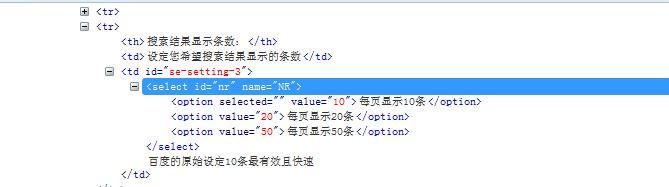
1.如果一个元素它的兄弟元素跟它的标签一样,这时候无法通过层级定位到。因为都是一个父亲生的,多胞胎兄弟。
2.虽然双胞胎兄弟很难识别,但是出生是有先后的,于是可以通过它在家里的排行老几定位到。
3.如下图三胞胎兄弟。
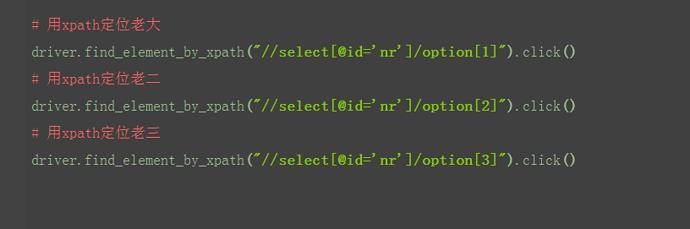
4.用xpath定位老大、老二和老三(这里索引是从1开始算起的,跟Python的索引不一样)。
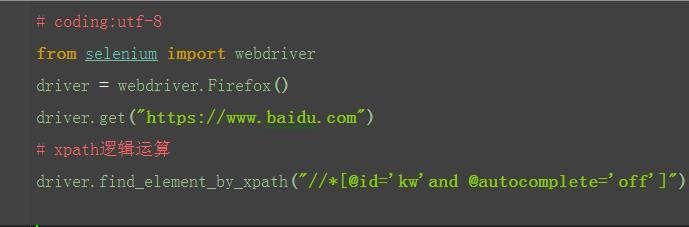
2.3.6 xpath:逻辑运算
1.xpath还有一个比较强的功能,是可以多个属性逻辑运算的,可以支持与(and)、或(or)、非(not)
2.一般用的比较多的是and运算,同时满足两个属性
2.3.7 xpath:模糊匹配
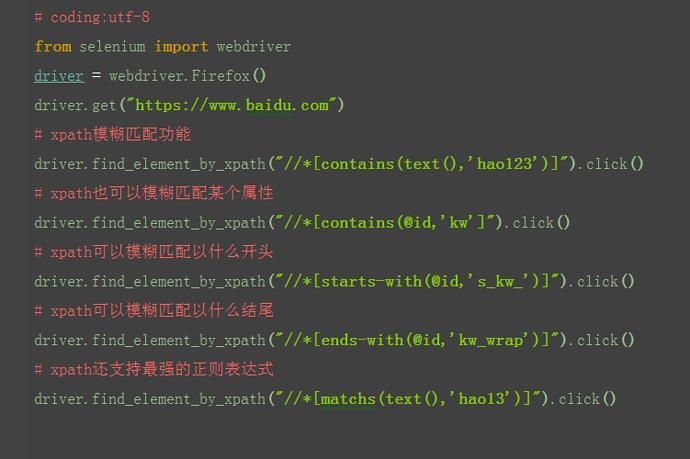
1.xpath还有一个非常强大的功能,模糊匹配。
2.掌握了模糊匹配功能,基本上没有定位不到的。
3.比如我要定位百度页面的超链接“hao123”,在上一篇中讲过可以通过by_link,也可以通过by_partial_link,模糊匹配定位到。当然xpath也可以有同样的功能,并且更为强大。
可以把xpath看成是元素定位界的屠龙刀。武林至尊,宝刀xpath,css不出,谁与争锋?下节课将亮出倚天剑css定位。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!?

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 让子元素在父元素中垂直居中的方法
- 【解决方案】物联网平台+边缘网关,助力智慧农业温室大棚项目快速落地
- python图片转灰度报错cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
- Arrow:在项目中进行时间处理的强大工具
- odoo17核心概念action5——其他文件
- java返回文件时为图片或pdf等设置在线预览或下载
- C++ 具名要求-全库范围的概念 - 能以函数调用语法进行调用的对象(FunctionObject)- 定义了调用操作的类型(Callable)
- MyBatis-Plus Generator代码生成器
- MyBatis 和 hibernate 的区别有哪些?
- 地球坐标系介绍--地心大地、地心地固直角、协议地球 坐标系