探秘数据挖掘:基本任务与流程的设计之道
发布时间:2023年12月18日
目录
写在开头
在信息时代的今天,数据已成为无处不在的宝贵资源。为了从海量数据中提炼有用的信息,数据挖掘技术应运而生。本文将深入探讨数据挖掘的基本任务和流程,结合设计技巧、逻辑思考能力、逻辑表达能力和商业思维,带你走进这个充满挑战和机遇的领域。
1.数据挖掘的基本任务
数据挖掘是从大量数据中发现模式、关系和趋势的过程,旨在提取有用的信息以支持决策和预测未来趋势。数据挖掘的基本任务涵盖了多个方面,其中一些主要的任务包括:
| 任务 | 任务描述 | 任务目的 | 方法与算法 | 应用场景 |
|---|---|---|---|---|
| 分类 | 将数据划分到预定义的类别中 | 识别和归纳数据模式,便于对未知数据进行标签预测 | 决策树、支持向量机、朴素贝叶斯等 | 垃圾邮件过滤、文本分类、疾病诊断等 |
| 聚类 | 将数据实例分组,组内相似度高 | 发现数据内在的结构和关系,帮助发现潜在的群体和模式 | K均值聚类、层次聚类、DBSCAN等 | 市场细分、图像分割、社交网络分析等 |
| 关联规则挖掘 | 发现项集之间的关联关系 | 揭示数据中的关联规律,帮助了解不同数据项之间的潜在关系 | Apriori算法、FP-growth算法等 | 购物篮分析、交叉销售推荐等 |
| 回归分析 | 预测连续变量的数值输出 | 建立输入特征和输出之间的关系模型,用于预测未知数值 | 线性回归、决策树回归、神经网络回归等 | 股票价格预测、销售量预测等 |
| 异常检测 | 识别可能是异常的数据点 | 发现潜在的错误、欺诈或其他重要的特殊情况 | 离群值检测算法、聚类方法等 | 欺诈检测、设备故障检测等 |
| 特征选择 | 从大量特征中选择最相关的特征 | 提高模型性能、减少维度,加速模型训练和推理 | 方差阈值法、递归特征消除、信息增益等 | 文本分类中的词汇选择、图像识别中的特征提取等 |
| 关键点检测 | 识别数据中的关键点 | 定位重要事件、发现异常值或需要特别关注的模式 | 突变点检测、时间序列分析等 | 金融领域的市场波动点、生产制造中的设备故障点等 |
| 文本挖掘 | 从文本数据中提取有用信息 | 分析文本内容,进行情感分析、主题提取等 | TF-IDF、词嵌入、主题模型等 | 舆情分析、文档分类、信息检索等 |
| 时间序列分析 | 分析和预测时间序列数据的变化趋势 | 预测未来趋势、发现周期性模式,支持决策制定 | 季节性分解、ARIMA模型、神经网络时间序列模型等 | 股票价格预测、气象数据分析、交通流量预测等 |
| 图数据挖掘 | 分析和挖掘图结构数据中的模式、社区结构等 | 揭示图中的节点关系、社区结构,支持社交网络分析 | 图神经网络、PageRank算法、社区检测算法等 | 社交网络分析、推荐系统、生物信息学中的蛋白质互作网络分析等 |
| 集成学习 | 结合多个基本模型以提高性能和泛化能力 | 提高模型鲁棒性、降低过拟合风险,提升整体性能 | 随机森林、梯度提升机、模型融合等 | 在各种任务中应用,如分类、回归等 |
| 深度学习 | 使用深度神经网络进行学习和建模 | 处理复杂非线性关系,适用于大规模数据和高维特征 | 卷积神经网络(CNN)、循环神经网络(RNN)、变换器(Transformer)等 | 图像识别、自然语言处理、语音识别等 |
2.数据挖掘的一般流程
数据挖掘的一般流程可以划分为以下几个阶段:
-
问题定义与目标制定:
- 任务明确: 首先明确数据挖掘的任务,例如分类、聚类、关联规则挖掘等。
- 目标制定: 定义明确的挖掘目标,明确想要从数据中获得的信息。
-
数据收集:
- 数据源获取: 确定需要挖掘的数据来源,可能是数据库、日志文件、传感器数据等。
- 数据采集: 采集、抽取、整合数据,确保数据质量和可用性。
-
数据清理与预处理:
- 缺失值处理: 处理数据中的缺失值,选择适当的填充或删除策略。
- 异常值处理: 检测和处理异常值,确保数据的准确性。
- 数据转换: 对数据进行归一化、标准化、离散化等处理,以便于后续挖掘过程。
- 特征选择与抽取: 选择关键特征或进行特征抽取,减少维度和噪声。
-
数据探索与分析:
- 描述性统计: 对数据进行基本的统计分析,了解数据的分布、中心趋势和离散度。
- 可视化分析: 使用图表、图形化工具对数据进行可视化,发现潜在的模式和规律。
- 探索性数据分析: 通过数据的交叉分析和相关性分析,进一步理解数据之间的关系。
-
模型选择与建立:
- 选择算法: 根据任务类型选择合适的数据挖掘算法,例如决策树、支持向量机、神经网络等。
- 模型建立: 使用选定的算法在训练集上建立数据挖掘模型,调整参数以提高模型性能。
- 模型评估: 使用测试集对模型进行评估,考察模型的泛化能力和性能。
-
模型验证与优化:
- 验证结果: 验证模型的有效性,确保模型在实际应用中能够产生可靠的结果。
- 优化调整: 根据验证结果对模型进行调整和优化,提高模型的性能和稳定性。
-
模型应用与部署:
- 应用场景: 将训练好的模型应用到实际场景中,用于实际问题的解决。
- 系统集成: 将数据挖掘模型集成到现有系统中,确保系统的稳定性和兼容性。
-
结果解释与报告:
- 结果解释: 解释模型输出的结果,理解模型对数据的解释和预测。
- 报告撰写: 撰写数据挖掘过程和结果的报告,清晰地呈现数据挖掘的发现和结论。
-
反馈与迭代:
- 反馈机制: 根据实际应用中的反馈,对模型和流程进行迭代和改进。
- 持续优化: 持续监控模型性能,对系统进行优化,以适应数据和业务环境的变化。
这一般流程被称为 CRISP-DM(Cross Industry Standard Process for Data Mining),是一种常用的数据挖掘流程模型。在实际应用中,流程的具体步骤和顺序可能根据问题和数据的特性而有所不同。
3.数据挖掘演示代码
3.1 分类
这里简单利用k-近邻实现分类的代码作为展示,后续文章中会进行详细的展开描述。
Python代码:
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# 数据准备
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2)
# 模型训练
knn_classifier = KNeighborsClassifier()
knn_classifier.fit(X_train, y_train)
# 模型评估
accuracy = knn_classifier.score(X_test, y_test)
print(f"分类准确率:{
accuracy}")
3.2 聚类
此处使用kmeans进行聚类模型进行展示:
Python代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# 更改 matplotlib 的默认字体
plt.rcParams['font.family'] = 'DejaVu Sans'
# 生成模拟数据
data, _ = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 使用 KMeans 聚类
kmeans = KMeans(n_clusters=4)
kmeans.fit(data)
labels = kmeans.labels_
centers = kmeans.cluster_centers_
# 可视化结果
plt.scatter(data[:, 0], data[:, 1], c=labels, cmap='viridis', edgecolor='k', s=50)
plt.scatter(centers[:, 0], centers[:, 1], c='red', marker='X', s=200, alpha=0.75)
plt.title('KMeans Clustering')
plt.show()
聚类后,效果图如下:
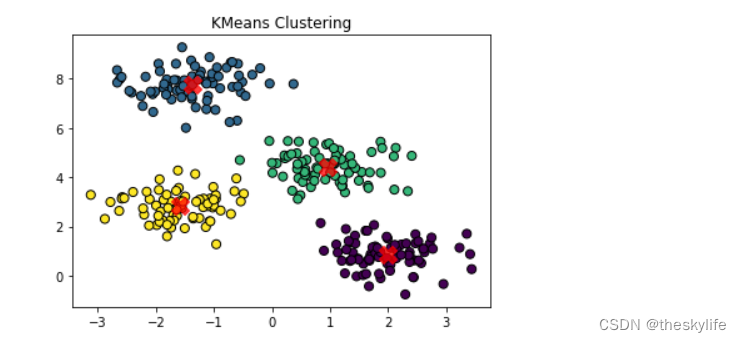
3.3 关联规则挖掘
这里选用mlxtend库进行举例:
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori, association_rules
import pandas as pd
# 示例数据(每一行代表每一个人的购买情况)
dataset = [['Milk', 'Onion', 'Nutmeg', 'Kidney Beans', 'Eggs', 'Yogurt'],
['Dill', 'Onion', 'Nutmeg', 'Kidney Beans', 'Eggs', 'Yogurt'],
['Milk', 'Apple', 'Kidney Beans', 'Eggs'],
['Milk', 'Unicorn', 'Corn'
文章来源:https://blog.csdn.net/qq_41780234/article/details/134990182
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!