【初识LOCUST -- 最新官方文档说明】

前言
locust测试本质上只是一个 Python 程序,向您要测试的系统发出请求。这使得它非常灵活,特别擅长实现复杂的用户流。但它也可以做简单的测试,所以让我们从它开始:
from locust import HttpUser, task
class HelloWorldUser(HttpUser):
@task
def hello_world(self):
self.client.get("/hello")
self.client.get("/world")
此用户将一次又一次地向 发出 HTTP 请求。有关完整的说明和更实际的示例,请参阅编写 locustfile。/hello/world
更改并更改为要测试的网站/服务上的一些实际路径,将代码放在当前目录中命名的文件中,然后运行:/hello/worldlocustfile.pylocust
$ locust
[2021-07-24 09:58:46,215] .../INFO/locust.main: Starting web interface at http://*:8089
[2021-07-24 09:58:46,285] .../INFO/locust.main: Starting Locust 2.20.1
locust的 Web 界面
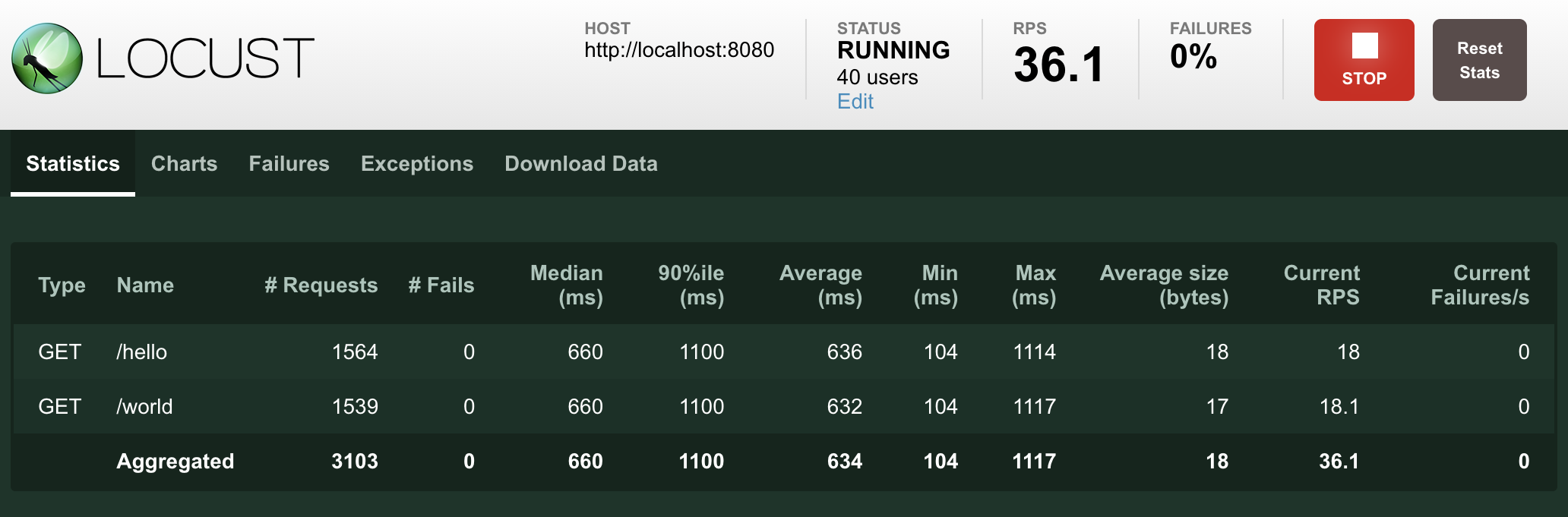
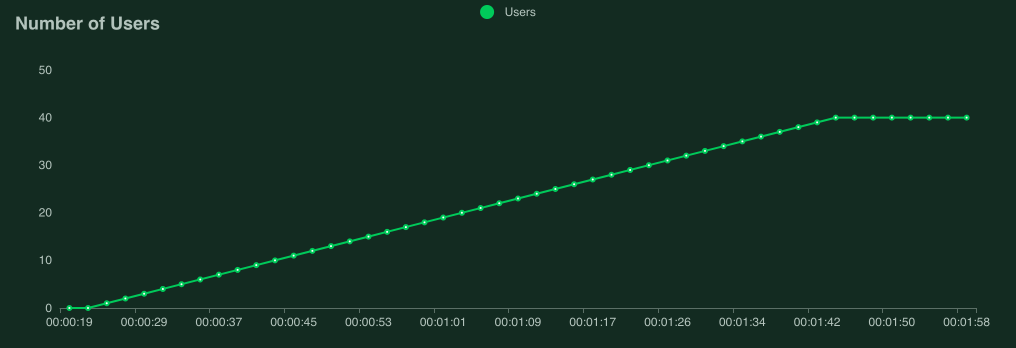
以下屏幕截图显示了使用 40 个并发用户(上升速率为 0.5 个用户/秒)针对性能稍差的服务器运行此测试时可能是什么样子。


注意
解释性能测试结果非常复杂(而且大多超出了本手册的范围),但是如果您的图形开始看起来像这样,则目标服务/系统无法处理负载,并且您发现了瓶颈。
当我们达到大约 9 个用户时,响应时间开始快速增加,即使 Locust 仍在产生更多用户,每秒的请求数量也不再增加。目标服务处于“过载”或“饱和”状态。
如果响应时间没有增加,则添加更多用户,直到找到服务的中断点,或者庆祝服务的性能已经足以满足预期的负载。
如果你在挖掘服务器端问题时需要一些帮助,或者你在生成足够的负载来使你的系统饱和时遇到困难,请查看?Locust FAQ。
现在有一个现代版本的 Web UI 可用!通过设置标志来尝试一下。--modern-ui
注意
此功能是实验性的,您可能会遇到重大更改。
直接命令行使用/无头
使用 Locust Web UI 是完全可选的。您可以在命令行上提供加载参数,并以文本形式获取有关结果的报告:
$ locust --headless --users 10 --spawn-rate 1 -H http://your-server.com
[2021-07-24 10:41:10,947] .../INFO/locust.main: No run time limit set, use CTRL+C to interrupt.
[2021-07-24 10:41:10,947] .../INFO/locust.main: Starting Locust 2.20.1
[2021-07-24 10:41:10,949] .../INFO/locust.runners: Ramping to 10 users using a 1.00 spawn rate
Name # reqs # fails | Avg Min Max Median | req/s failures/s
----------------------------------------------------------------------------------------------
GET /hello 1 0(0.00%) | 115 115 115 115 | 0.00 0.00
GET /world 1 0(0.00%) | 119 119 119 119 | 0.00 0.00
----------------------------------------------------------------------------------------------
Aggregated 2 0(0.00%) | 117 115 119 117 | 0.00 0.00
(...)
[2021-07-24 10:44:42,484] .../INFO/locust.runners: All users spawned: {"HelloWorldUser": 10} (10 total users)
(...)
有关更多详细信息,请参阅不使用 Web UI 运行。
更多选项
要运行分布在多个 Python 进程或机器上的 Locust,请启动单个 Locust 主进程 使用命令行参数,然后使用命令行参数对任意数量的 Locust 工作进程进行操作。有关详细信息,请参阅分布式负载生成。--master--worker
要查看所有可用选项,请键入: 或选中配置。`locust?--help
写入locust文件
现在,让我们看一个更完整/更现实的测试示例:
import time
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
wait_time = between(1, 5)
@task
def hello_world(self):
self.client.get("/hello")
self.client.get("/world")
@task(3)
def view_items(self):
for item_id in range(10):
self.client.get(f"/item?id={item_id}", name="/item")
time.sleep(1)
def on_start(self):
self.client.post("/login", json={"username":"foo", "password":"bar"})
让我们来分解一下
import time
from locust import HttpUser, task, between
locust文件只是一个普通的 Python 模块,它可以从其他文件或包中导入代码。
class QuickstartUser(HttpUser):
在这里,我们为将要模拟的用户定义一个类。它继承给每个用户一个属性, 这是?的实例,即 可用于向我们想要加载测试的目标系统发出 HTTP 请求。当测试开始时, Locust 将为它模拟的每个用户创建一个此类的实例,并且每个用户 用户将开始在他们自己的绿色 gevent 线程中运行。client
要使文件成为有效的 locustfile,它必须包含至少一个继承自?的类。
wait_time = between(1, 5)
我们的类定义了一个,它将使模拟用户在每个任务后等待 1 到 5 秒(见下文) 被执行。有关详细信息,请参阅wait_time属性。wait_time
@task
def hello_world(self):
...
修饰的方法是 locust 文件的核心。对于每个正在运行的用户, Locust 创建一个 greenlet(微线程),它将调用这些方法。@task
@task
def hello_world(self):
self.client.get("/hello")
self.client.get("/world")
@task(3)
def view_items(self):
...
我们通过装饰两个方法声明了两个任务,其中一个方法被赋予了更高的权重 (3)。 当我们运行时,它将选择一个声明的任务 - 在本例中为 或 - 并执行它。任务是随机选择的,但您可以为它们分配不同的权重。以上 配置将使 Locust 选择的可能性是 的三倍。当任务具有 执行完成后,用户将在等待时间内(在本例中为 1 到 5 秒)进入睡眠状态。 在等待时间之后,它会选择一个新任务并继续重复。@taskQuickstartUserhello_worldview_itemsview_itemshello_world
请注意,将只选择修饰的方法,因此你可以以任何你喜欢的方式定义自己的内部帮助程序方法。@task
self.client.get("/hello")
该属性使得进行将由 Locust 记录的 HTTP 调用成为可能。有关如何操作的信息 要发出其他类型的请求、验证响应等,请参阅使用 HTTP 客户端。self.client
注意
HttpUser 不是真正的浏览器,因此不会解析 HTML 响应来加载资源或呈现页面。不过,它会跟踪 cookie。
@task(3)
def view_items(self):
for item_id in range(10):
self.client.get(f"/item?id={item_id}", name="/item")
time.sleep(1)
在任务中,我们使用可变查询参数加载 10 个不同的 URL。 为了在 Locust 的统计数据中不获得 10 个单独的条目 - 因为统计数据是在 URL 上分组的 - 我们使用?name 参数,用于将所有这些请求分组到一个名为 instead 的条目下。view_items"/item"
def on_start(self):
self.client.post("/login", json={"username":"foo", "password":"bar"})
此外,我们还声明了一种on_start方法。将为每个模拟调用具有此名称的方法 用户。有关详细信息,请参阅?on_start 和 on_stop 方法。
自动生成locust文件
您可以使用?har2locust?根据浏览器记录(HAR 文件)生成locust文件。
它对于不习惯编写自己的 locustfile 的初学者特别有用,但对于更高级的用例也可以高度定制。
注意
har2locust 仍处于测试阶段。它可能并不总是生成正确的 locustfile,并且其界面可能会在版本之间更改。
User 类
用户类表示系统的一种用户/方案类型。执行测试运行时,指定并发数 您要模拟的用户,Locust 将为每个用户创建一个实例。您可以向这些属性添加任何您喜欢的属性 类/实例,但有一些对 Locust 有特殊意义:
wait_time属性
用户的方法可以很容易地在以下时间引入延迟 每个任务执行。如果未指定wait_time,则下一个任务将在完成任务后立即执行。
-
在固定的时间内
-
最小值和最大值之间的随机时间
例如,要使每个用户在每次任务执行之间等待 0.5 到 10 秒:
from locust import User, task, between
class MyUser(User):
@task
def my_task(self):
print("executing my_task")
wait_time = between(0.5, 10)
-
用于确保任务每秒运行(最多)X 次的自适应时间。
-
用于确保任务每 X 秒(最多)运行一次的自适应时间(它是?constant_throughput?的数学倒数)。
注意
例如,如果您希望 Locust 在峰值负载下每秒运行 500 次任务迭代,则可以使用?wait_time = constant_throughput(0.1)?和 5000 的用户计数。
等待时间只会限制吞吐量,而不能启动新用户来达到目标。因此,在我们的示例中,如果任务迭代时间超过 10 秒,则吞吐量将小于 500。
等待时间是在任务执行后应用的,因此,如果您的生成率/爬坡率很高,您最终可能会在爬坡期间超过您的目标。
等待时间适用于任务,而不是请求。例如,如果您指定?wait_time = constant_throughput(2)?并在任务中执行两个请求,则您的请求速率/RPS 将为每个用户 4。
也可以直接在类上声明自己的 wait_time 方法。 例如,下面的 User 类将休眠一秒钟,然后是两秒钟,然后是三秒钟,依此类推。
class MyUser(User):
last_wait_time = 0
def wait_time(self):
self.last_wait_time += 1
return self.last_wait_time
...
重量和fixed_count属性
如果文件中存在多个用户类,并且命令行上未指定任何用户类, locust将生成相同数量的每个用户类。您还可以指定 通过从同一个 locustfile 作为命令行参数传递它们来使用的用户类:
$ locust -f locust_file.py WebUser MobileUser
如果您希望模拟更多特定类型的用户,您可以为其设置权重属性 类。例如,网络用户的可能性是移动用户的三倍:
class WebUser(User):
weight = 3
...
class MobileUser(User):
weight = 1
...
您也可以设置属性。 在这种情况下,权重属性将被忽略,并且将生成确切的计数用户。 首先生成这些用户。在下面的示例中,只有一个 AdminUser 实例 将生成,以更准确的控制来制作一些特定的工作 请求计数与用户总数无关。
class AdminUser(User):
wait_time = constant(600)
fixed_count = 1
@task
def restart_app(self):
...
class WebUser(User):
...
host 属性
host 属性是要测试的主机的 URL 前缀(例如)。它会自动添加到请求中,因此您可以这样做。https://google.comself.client.get("/")
您可以在 Locust 的 Web UI 中或使用该选项在命令行上覆盖此值。--host
tasks 属性
User 类可以使用装饰器将任务声明为其下的方法,但也可以 使用?tasks?属性指定任务,下面将详细介绍该属性。
environment 属性
对用户正在运行的 的引用。使用它来与 环境,或它所包含的环境。例如,从任务方法中停止运行器:
self.environment.runner.quit()
如果在独立的 Locust 实例上运行,这将停止整个运行。如果在工作器节点上运行,它将停止该特定节点。
任务
启动负载测试时,将为每个模拟用户创建一个 User 类的实例 他们将开始在自己的绿色线程中运行。当这些用户运行时,他们会选择以下任务: 他们执行,睡一会儿,然后选择一个新任务,依此类推。
这些任务是普通的 python 可调用对象,如果我们对拍卖网站进行负载测试,它们可以做到 诸如“加载起始页”、“搜索某些产品”、“出价”等内容。
@task装饰器
为用户添加任务的最简单方法是使用修饰器。
from locust import User, task, constant
class MyUser(User):
wait_time = constant(1)
@task
def my_task(self):
print("User instance (%r) executing my_task" % self)
@task采用可选的权重参数,该参数可用于指定任务的执行比率。在 以下示例中,Task2?被选中的可能性是?Task1?的两倍:
from locust import User, task, between
class MyUser(User):
wait_time = between(5, 15)
@task(3)
def task1(self):
pass
@task(6)
def task2(self):
pass
tasks 属性
定义用户任务的另一种方法是设置属性。
tasks?属性可以是 Tasks 列表,也可以是?<Task : int>?字典,其中 Task 是 python callable 或?TaskSet?类。如果任务是普通的 python 函数,则它们 接收单个参数,该参数是执行任务的 User 实例。
下面是一个声明为普通 python 函数的 User 任务示例:
from locust import User, constant
def my_task(user):
pass
class MyUser(User):
tasks = [my_task]
wait_time = constant(1)
如果将 tasks 属性指定为列表,则每次执行任务时,它都是随机的 从“任务”属性中选择。但是,如果 tasks?是一个字典 - 将可调用对象作为键和整数 AS 值 - 要执行的任务将随机选择,但 int AS 比率。所以 任务如下所示:
{my_task: 3, another_task: 1}
my_task被处决的可能性是another_task的 3 倍。
在内部,上面的字典实际上将扩展为一个列表(并且属性已更新) 看起来像这样:tasks
[my_task, my_task, my_task, another_task]
然后使用 Python 从列表中选择任务。random.choice()
@tag装饰器
通过使用装饰器标记任务,您可以对任务是什么进行挑剔 在测试期间使用 和 参数执行。考虑 以下示例:--tags--exclude-tags
from locust import User, constant, task, tag
class MyUser(User):
wait_time = constant(1)
@tag('tag1')
@task
def task1(self):
pass
@tag('tag1', 'tag2')
@task
def task2(self):
pass
@tag('tag3')
@task
def task3(self):
pass
@task
def task4(self):
pass
如果使用 启动此测试,则仅执行?task1?和?task2?在测试期间。如果从 启动它,则只有?task2?和?task3?将是 执行。--tags?tag1--tags?tag2?tag3
--exclude-tags将以完全相反的方式运行。因此,如果使用 开始测试,则只会执行?task1、task2?和?task4。始终排除 胜过包含,因此,如果任务具有已包含的标签和已排除的标签,则不会 伏法。--exclude-tags?tag3
事件
如果要在测试中运行一些设置代码,通常将其放在模块中就足够了 水平,但有时您需要在运行中的特定时间执行操作。为 这个需求,Locust 提供了事件钩子。
test_start和test_stop
如果需要在负载测试的开始或停止时运行某些代码,则应使用?和?事件。您可以在 locustfile 的模块级别为这些事件设置侦听器:
from locust import events
@events.test_start.add_listener
def on_test_start(environment, **kwargs):
print("A new test is starting")
@events.test_stop.add_listener
def on_test_stop(environment, **kwargs):
print("A new test is ending")
初始化
该事件在每个locust进程开始时触发。这在分布式模式下特别有用 其中每个工作进程(不是每个用户)都需要有机会进行一些初始化。例如,假设您有一些 从此过程中生成的所有用户的全局状态将需要:init
from locust import events
from locust.runners import MasterRunner
@events.init.add_listener
def on_locust_init(environment, **kwargs):
if isinstance(environment.runner, MasterRunner):
print("I'm on master node")
else:
print("I'm on a worker or standalone node")
Other events
See?extending locust using event hooks?for other events and more examples of how to use them.
HttpUser class
是最常用的。它添加了一个用于发出 HTTP 请求的属性。
from locust import HttpUser, task, between
class MyUser(HttpUser):
wait_time = between(5, 15)
@task(4)
def index(self):
self.client.get("/")
@task(1)
def about(self):
self.client.get("/about/")
客户端属性 / HttpSession
是?的实例。HttpSession 是 的子类/包装器,因此它的功能有据可查,许多人应该很熟悉。HttpSession 添加的主要是将请求结果报告给 Locust(成功/失败、响应时间、响应长度、名称)。
它包含所有 HTTP 方法的方法:、、、?...
就像?一样,它会在请求之间保留 cookie,因此可以轻松用于登录网站。
response = self.client.post("/login", {"username":"testuser", "password":"secret"})
print("Response status code:", response.status_code)
print("Response text:", response.text)
response = self.client.get("/my-profile")
HttpSession 捕获 Session 抛出的任何内容(由连接错误、超时或类似原因引起),而是返回一个虚拟文件?status_code设置为 0 且内容设置为 None 的响应对象。
验证响应
如果 HTTP 响应代码正常 (<400),则认为请求成功,但它通常对 对响应进行一些额外的验证。
您可以使用?catch_response?参数、with-statement?和 调用?response.failure()
with self.client.get("/", catch_response=True) as response:
if response.text != "Success":
response.failure("Got wrong response")
elif response.elapsed.total_seconds() > 0.5:
response.failure("Request took too long")
您还可以将请求标记为成功,即使响应代码错误:
with self.client.get("/does_not_exist/", catch_response=True) as response:
if response.status_code == 404:
response.success()
您甚至可以通过抛出异常,然后在 with-block 之外捕获它来完全避免记录请求。或者你可以抛出一个locust异常locustlocust异常,就像下面的例子一样,让locust捕捉到它。
from locust.exception import RescheduleTask
...
with self.client.get("/does_not_exist/", catch_response=True) as response:
if response.status_code == 404:
raise RescheduleTask()
REST/JSON 接口
FastHttpUser?提供了一个现成的方法,但你也可以自己做:rest
from json import JSONDecodeError
...
with self.client.post("/", json={"foo": 42, "bar": None}, catch_response=True) as response:
try:
if response.json()["greeting"] != "hello":
response.failure("Did not get expected value in greeting")
except JSONDecodeError:
response.failure("Response could not be decoded as JSON")
except KeyError:
response.failure("Response did not contain expected key 'greeting'")
对请求进行分组
网站的 URL 包含某种动态参数的页面很常见。 通常,在用户的统计信息中将这些 URL 组合在一起是有意义的。这是可以做到的 通过将?name?参数传递给不同的请求方法。
例:
# Statistics for these requests will be grouped under: /blog/?id=[id]
for i in range(10):
self.client.get("/blog?id=%i" % i, name="/blog?id=[id]")
在某些情况下,可能无法将参数传递到请求函数中,例如在与库/SDK 交互时 包装 Requests 会话。通过设置属性,提供了对请求进行分组的另一种方法。client.request_name
# Statistics for these requests will be grouped under: /blog/?id=[id]
self.client.request_name="/blog?id=[id]"
for i in range(10):
self.client.get("/blog?id=%i" % i)
self.client.request_name=None
如果要使用最少的样板链接多个分组,则可以使用上下文管理器。client.rename_request()
@task
def multiple_groupings_example(self):
# Statistics for these requests will be grouped under: /blog/?id=[id]
with self.client.rename_request("/blog?id=[id]"):
for i in range(10):
self.client.get("/blog?id=%i" % i)
# Statistics for these requests will be grouped under: /article/?id=[id]
with self.client.rename_request("/article?id=[id]"):
for i in range(10):
self.client.get("/article?id=%i" % i)
使用?catch_response?并直接访问request_meta,您甚至可以根据响应中的某些内容重命名请求。
with self.client.get("/", catch_response=True) as resp:
resp.request_meta["name"] = resp.json()["name"]
HTTP 代理设置
为了提高性能,我们通过设置 请求。Session 的 trust_env 属性为 。如果您不希望这样做,可以手动设置为 。有关详细信息,请参阅请求文档。Falselocust_instance.client.trust_envTrue
连接池
正如每一个创造新的, 每个用户实例都有自己的连接池。这类似于真实用户与 Web 服务器的交互方式。
但是,如果要在所有用户之间共享连接,则可以使用单个池管理器。为此,请将 class 属性设置为 的实例。pool_managerurllib3.PoolManager
from locust import HttpUser
from urllib3 import PoolManager
class MyUser(HttpUser):
# All users will be limited to 10 concurrent connections at most.
pool_manager = PoolManager(maxsize=10, block=True)
有关更多配置选项,请参阅?urllib3 文档。
任务集
TaskSets 是一种对分层网站/系统进行结构化测试的方法。你可以在这里阅读更多关于它的信息。
例子
这里有很多 locustfile 示例
如何构建测试代码
重要的是要记住,locustfile.py 只是一个导入的普通 Python 模块 被locust。从这个模块中,你可以像往常一样自由地导入其他 python 代码 在任何 Python 程序中。当前工作目录会自动添加到 python 的 , 因此,驻留在工作目录中的任何 Python 文件/模块/包都可以使用 python 语句。sys.pathimport
对于小型测试,将所有测试代码保存在一个测试代码中应该可以正常工作,但对于 较大的测试套件,您可能希望将代码拆分为多个文件和目录。locustfile.py
当然,如何构建测试源代码完全取决于您,但我们建议您 遵循 Python 最佳实践。下面是一个虚构的 Locust 项目的示例文件结构:
-
项目根目录
-
common/-
__init__.py -
auth.py -
config.py
-
-
locustfile.py -
requirements.txt(外部 Python 依赖项通常保存在 requirements.txt 中)
-
具有多个 locustfile 的项目也可以将它们保存在单独的子目录中:
-
项目根目录
-
common/-
__init__.py -
auth.py -
config.py
-
-
my_locustfiles/-
api.py -
website.py
-
-
requirements.txt
-
使用上述任何项目结构,locustfile 可以使用以下命令导入公共库:
import common.auth

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- centos安装tomcat
- 【产品设计】详细的B端筛选设计
- 数据库迁移工具包:DBSofts ESF Database Migration Crack
- vscode debug c++代码
- Mysql 编译安装部署
- java与大数据:Hadoop与MapReduce
- 数据类型
- ArchLinux安装增强功能,光驱加载位置
- 22款奔驰GLE450升级小柏林音响 提升音质效果
- 华为OD机试真题-小明找位置-2023年OD统一考试(C卷)