【C语言】浅谈参数定义及调用时的堆栈空间分配及内存优化控制(传参优化以及模拟栈)
【C语言】浅谈参数定义及调用时的堆栈空间分配及内存优化控制(传参优化以及模拟栈)
首先明确一点:
全局变量分配在堆空间
临时变量分配在栈空间
局部静态变量相当于全局变量分配在堆空间
这里探讨的是嵌入式系统中的编程情况 Windows下空间足够大且够用 就不用抠抠搜搜的
文章目录
函数中不要使用大数组临时变量
请看下面代码:
typedef struct
{
unsigned short valid_number;
float data[600];
float b_ID[50];
} g_cluster_t;
void codegen_cluster_algorithm(const Target_t TargetList[100],
Cluster_t ClusterList[64],
const g_cluster_t g_cluster[64], float timestamp)
{
g_cluster_t b_g_cluster[64];
float All_A;
float All_R;
float All_V;
float f;
float max_SNR;
int b_i;
int c_i;
int d_i;
int e_i;
int i1;
int j;
可以看到 b_g_cluster变量是一个临时变量
在结构体按1对齐的情况下 b_g_cluster的大小为64*(4600+450+2)=166,528字节=162.625KB
那么这个函数在调用时 就直接会在堆空间中申请至少162.625KB的空间
而嵌入式系统很多堆空间也就只有1KB左右 所以明显是跑不了的
不过这个函数在Windows下可以跑 因为PC电脑的栈足够大
那么解决方案就是 将这个变量作为全局变量存储在堆空间中 这样就能跑通了 但需要注意的是 全局变量只给这个函数服务 所以在进入函数中需要清零
如:
g_cluster_t b_g_cluster[64];
#pragma DATA_SECTION(b_g_cluster, ".l3ram");
void codegen_cluster_algorithm(const Target_t TargetList[100],
Cluster_t ClusterList[64],
const g_cluster_t g_cluster[64], float timestamp)
{
memset(&b_g_cluster, 0,sizeof(g_cluster_t)*64);
其中 DATA_SECTION这是TI嵌入式开发中的一种指定变量存储位置的写法 我这样写就是存储在l3ram中

而此MCU的系统栈只有1200
相比之下 L3RAM却有786k

这样做有个弊端 就是每次进入函数都需要给这个变量清零 而且在函数退出以后 并不会自动释放 所以最好的方法是malloc分配内存进行操作 并且在函数退出前使用free释放内存
传参时的内存优化
请看下列代码:
#include<stdio.h>
int a=0;
void fun1(int x)
{
x=1;
printf("fun1 %d\n",&x);
}
void fun2(int* x)
{
*x=1;
printf("fun2 %d\n",x);
}
int main()
{
printf("%d\n",&a);
fun1(a);
printf("%d\n",a);
fun2(&a);
printf("%d\n",a);
return 0;
}
运行结果:
4223024
fun1 6422016
0
fun2 4223024
1
在函数声明中定义的参数为形参 而调用时需要将实参传入到函数中
a作为全局 地址为4223024
在fun1中 传入以后变为临时变量 地址为6422016
改变临时变量的值并不能改变a
在fun2中 传入的是变量a的地址 所以地址不变 改变值会同步改变a的值
那么 在函数fun1中 临时变量就会被存储在栈空间中
如果a这个变量比较大 那么就会浪费栈空间
所以当传入全局变量时 如果不需要对变量进行改变(只读) 则直接调用 而不是以传参的形式传入 当然也可以传入地址
如果需要改变时 则传入地址
那么就不会分配多余的栈空间来存储变量
如果只是读取 然后又要定义一个中间变量来改变 则回到上一章节中的那种处理方式
用堆模拟栈空间而达到扩大栈区的目的
很多情况下 临时变量比较多 不宜使用堆内存分配的方式进行 那么就可以使用到模拟栈
RTOS等嵌入式系统都有相关功能
如多线程操作时:
Task_Params_init(&taskParams);
taskParams.priority = MMWDEMO_MMWAVE_CTRL_TASK_PRIORITY;
taskParams.stackSize = 3*1024;
gMmwMCB.taskHandles.mmwaveCtrl = Task_create(MmwDemo_mmWaveCtrlTask, &taskParams, NULL);
在建立线程时 会创建一个模拟栈空间为3*1024的空间 来跑MmwDemo_mmWaveCtrlTask函数
实际上这个栈空间是在堆上面进行模拟的 本质上的临时变量还是存储在堆空间中
刚刚我提到了 TI的这个mcu栈空间只有1200B
如果1200不够用 那么就可以单独建立一个线程 用堆空间来模拟
那么 就可以跑大于1200B空间的代码了
附录:压缩字符串、大小端格式转换
压缩字符串
首先HART数据格式如下:


重点就是浮点数和字符串类型
Latin-1就不说了 基本用不到
浮点数
浮点数里面 如 0x40 80 00 00表示4.0f
在HART协议里面 浮点数是按大端格式发送的 就是高位先发送 低位后发送
发送出来的数组为:40,80,00,00
但在C语言对浮点数的存储中 是按小端格式来存储的 也就是40在高位 00在低位
浮点数:4.0f
地址0x1000对应00
地址0x1001对应00
地址0x1002对应80
地址0x1003对应40
若直接使用memcpy函数 则需要进行大小端转换 否则会存储为:
地址0x1000对应40
地址0x1001对应80
地址0x1002对应00
地址0x1003对应00
大小端转换:
void swap32(void * p)
{
uint32_t *ptr=p;
uint32_t x = *ptr;
x = (x << 16) | (x >> 16);
x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);
*ptr=x;
}
压缩Packed-ASCII字符串
本质上是将原本的ASCII的最高2位去掉 然后拼接起来 比如空格(0x20)
四个空格拼接后就成了
1000 0010 0000 1000 0010 0000
十六进制:82 08 20
对了一下表 0x20之前的识别不了
也就是只能识别0x20-0x5F的ASCII表
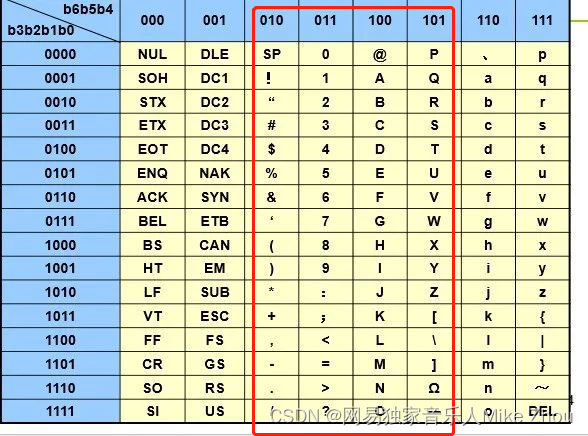
压缩/解压函数后面再写:
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_ASCII_to_Pack(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{
if(str_len%4)
{
return 0;
}
uint8_t i=0;
memset(buf,0,str_len/4*3);
for(i=0;i<str_len;i++)
{
if(str[i]==0x00)
{
str[i]=0x20;
}
}
for(i=0;i<str_len/4;i++)
{
buf[3*i]=(str[4*i]<<2)|((str[4*i+1]>>4)&0x03);
buf[3*i+1]=(str[4*i+1]<<4)|((str[4*i+2]>>2)&0x0F);
buf[3*i+2]=(str[4*i+2]<<6)|(str[4*i+3]&0x3F);
}
return 1;
}
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_Pack_to_ASCII(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{
if(str_len%4)
{
return 0;
}
uint8_t i=0;
memset(str,0,str_len);
for(i=0;i<str_len/4;i++)
{
str[4*i]=(buf[3*i]>>2)&0x3F;
str[4*i+1]=((buf[3*i]<<4)&0x30)|(buf[3*i+1]>>4);
str[4*i+2]=((buf[3*i+1]<<2)&0x3C)|(buf[3*i+2]>>6);
str[4*i+3]=buf[3*i+2]&0x3F;
}
return 1;
}
大小端转换
在串口等数据解析中 难免遇到大小端格式问题
什么是大端和小端
所谓的大端模式,就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
所谓的小端模式,就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
简单来说:大端——高尾端,小端——低尾端
举个例子,比如数字 0x12 34 56 78在内存中的表示形式为:
1)大端模式:
低地址 -----------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
2)小端模式:
低地址 ------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
可见,大端模式和字符串的存储模式类似。
数据传输中的大小端
比如地址位、起止位一般都是大端格式
如:
起始位:0x520A
则发送的buf应为{0x52,0x0A}
而数据位一般是小端格式(单字节无大小端之分)
如:
一个16位的数据发送出来为{0x52,0x0A}
则对应的uint16_t类型数为: 0x0A52
而对于浮点数4.0f 转为32位应是:
40 80 00 00
以大端存储来说 发送出来的buf就是依次发送 40 80 00 00
以小端存储来说 则发送 00 00 80 40
由于memcpy等函数 是按字节地址进行复制 其复制的格式为小端格式 所以当数据为小端存储时 不用进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={0x00,0x00,0x80,0x40};
memcpy(&dat,buf,4);
float f=0.0f;
f=*((float*)&dat); //地址强转
printf("%f",f);
或更优解:
uint8_t buf[]={0x00,0x00,0x80,0x40};
float f=0.0f;
memcpy(&f,buf,4);
而对于大端存储的数据(如HART协议数据 全为大端格式) 其复制的格式仍然为小端格式 所以当数据为小端存储时 要进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};
memcpy(&dat,buf,4);
float f=0.0f;
swap32(&dat); //大小端转换
f=*((float*)&dat); //地址强转
printf("%f",f);
或:
uint8_t buf[]={0x40,0x80,0x00,0x00};
memcpy(&dat,buf,4);
float f=0.0f;
swap32(&f); //大小端转换
printf("%f",f);
或更优解:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};
float f=0.0f;
dat=(buf[0]<<24)|(buf[0]<<16)|(buf[0]<<8)|(buf[0]<<0)
f=*((float*)&dat);
总结
固 若数据为小端格式 则可以直接用memcpy函数进行转换 否则通过移位的方式再进行地址强转
对于多位数据 比如同时传两个浮点数 则可以定义结构体之后进行memcpy复制(数据为小端格式)
对于小端数据 直接用memcpy写入即可 若是浮点数 也不用再进行强转
对于大端数据 如果不嫌麻烦 或想使代码更加简洁(但执行效率会降低) 也可以先用memcpy写入结构体之后再调用大小端转换函数 但这里需要注意的是 结构体必须全为无符号整型 浮点型只能在大小端转换写入之后再次强转 若结构体内采用浮点型 则需要强转两次
所以对于大端数据 推荐通过移位的方式来进行赋值 然后再进行个别数的强转 再往通用结构体进行写入
多个不同变量大小的结构体 要主要字节对齐的问题
可以用#pragma pack(1) 使其对齐为1
但会影响效率
大小端转换函数
直接通过对地址的操作来实现 传入的变量为32位的变量
中间变量ptr是传入变量的地址
void swap16(void * p)
{
uint16_t *ptr=p;
uint16_t x = *ptr;
x = (x << 8) | (x >> 8);
*ptr=x;
}
void swap32(void * p)
{
uint32_t *ptr=p;
uint32_t x = *ptr;
x = (x << 16) | (x >> 16);
x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);
*ptr=x;
}
void swap64(void * p)
{
uint64_t *ptr=p;
uint64_t x = *ptr;
x = (x << 32) | (x >> 32);
x = ((x & 0x0000FFFF0000FFFF) << 16) | ((x >> 16) & 0x0000FFFF0000FFFF);
x = ((x & 0x00FF00FF00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF00FF00FF);
*ptr=x;
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Netty RPC 实现(二)
- Unity开发授权系统
- 华为OD机试 - 智能驾驶(Java & JS & Python & C)
- 产线工控安全
- SQL规约
- Nginx 配置反向代理 - part 3
- 构建安全可靠的系统:第六章到第十章
- 【Python程序开发系列】5000字总结:Git-Fork模式下软件开发的工作流程和常用命令
- ASP.NET Core AOT
- 第二章 面向对象的基本概念之——结构化程序设计