hive 用户自定义函数udf,udaf,udtf
udf:一对一的关系
udtf:一对多的关系
udaf:多对一的关系
使用Java实现步骤
自定义编写UDF函数注意:
1.需要继承org.apache.hadoop.hive.ql.exec.UDF
2.需要实现evaluete函数
编写UDTF函数注意:
1.需要继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF
2.实现 initialize, process, close三个方法
1.自定义实现一个大小写转换的函数(UDF)
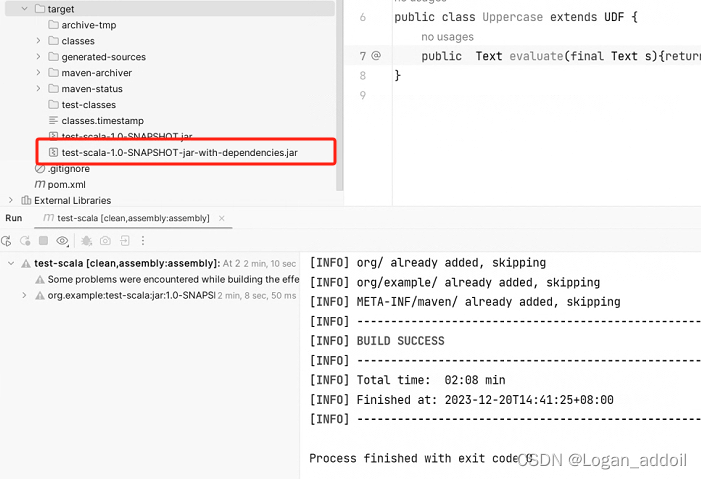
执行mvn命令
将jar包上传到服务器上
上传之后,进入hive,添加jar包
add jar ///xxx.jar(jar包全路径)
创建临时函数
create temporary function upper_func as ‘org.example.Uppercase’;

之后,可以直接在查询中使用

transform方式
hive中除了使用Java编写udf,还可以使用transform,支持多种语言
例如: 将表第一列与第二列用 _ (下划线) 连接
1.Linux中的 awk
创建一个transform.awk
内容
{
print $1"_"$2
}
在hive中使用add file 添加 transform.awk
然后就可以调用函数了
select transform(col1,col2) using “awk -f transform.awk” as (uu) from test_table limit 10;
2.使用python
在hive中使用 add file 添加 transform.py
使用命令调用函数
select transform(col1,col2) using “python transform.py” as (uu) from test_table limit 10;
3.基于python实现wordcount
整个过程模拟map 和 reduce
add file 上传 mapper.py 和 reduce.py
创建一张表,保存结果
create table word_cnt(
word string ,
cnt int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
WITH map_cnt as (
select transform(line) using "python mapper.py" as word , cnt
from docs
cluster by word ),
insert overwrite table word_cnt
select transform(word,cnt) using "python reduce.py" as w, c
from map_cnt
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机Java项目|基于SSM的微课学习系统
- Npm使用技巧
- 使用 Matplotlib 和 mplcursors 创建交互式数据可视化,鼠标悬停动态显示数据
- 面试必备:C++ 多态 (附:多态重载重写区别)
- 语雀邀请码(OUHOUW 30 天语雀会员)
- 上门服务系统|上门服务小程序|上门服务系统的发展趋势
- 人工智能领域2023年12月15日-12月24日大事件
- SpringMVC环境搭配
- 竞赛保研 基于深度学习的视频多目标跟踪实现
- Leetcode