C++刷题笔记
C++刷题笔记
1.钞票和硬币
题目
读取一个带有两个小数位的浮点数,这代表货币价值。
在此之后,将该值分解为多种钞票与硬币的和,每种面值的钞票和硬币使用数量不限,要求使用的钞票和硬币的总数量尽可能少。
钞票的面值是 100,50,20,10,5,2
硬币的面值是 1,0.50,0.25,0.10,0.05和0.01
经过实验证明:在本题中,优先使用面额大的钞票和硬币可以保证所用的钞票和硬币总数量最少。
输入格式
输入一个浮点数 N。
输出格式
参照输出样例,输出每种面值的钞票和硬币的需求数量。
数据范围
0≤N≤1000000.000
输入样例:
576.73
输出样例:
NOTAS:
5 nota(s) de R$ 100.00
1 nota(s) de R$ 50.00
1 nota(s) de R$ 20.00
0 nota(s) de R$ 10.00
1 nota(s) de R$ 5.00
0 nota(s) de R$ 2.00
MOEDAS:
1 moeda(s) de R$ 1.00
1 moeda(s) de R$ 0.50
0 moeda(s) de R$ 0.25
2 moeda(s) de R$ 0.10
0 moeda(s) de R$ 0.05
3 moeda(s) de R$ 0.01
题解
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
int a1[]={100,50,20,10,5,2};
int a2[]={100,50,25,10,5,1};
double m;
cin>>m;
double s;
s=m;
cout<<"NOTAS:"<<endl;
for(int i=0;i<6;i++)
{
int num=int(m)/a1[i];
cout<<num<<" nota(s) de R$ "<<a1[i]<<".00"<<endl;
m=int(m)%a1[i];
s=s-num*a1[i];
}
//此时s的值是用大额兑换过的
s=s*100+10e-9;//关键地方防止精度缺失
cout<<"MOEDAS:"<<endl;
for(int i=0;i<6;i++)
{
printf("%d moeda(s) de R$ %.2f\n",int(s)/a2[i],float(a2[i])/100);
s=int(s)%a2[i];
}
return 0;
}
2.DDD
题目
给定一个整数,请根据下表确定并输出其对应的城市名称:

如果输入数字不在上表中,则输出 DDD nao cadastrado。
输入格式
共一行,包含一个整数。
输出格式
输出对应城市名称,如果没有对应城市名称,则输出 DDD nao cadastrado。
输入样例:
11
输出样例:
Sao Paulo
题解
#include <iostream>
using namespace std;
int main()
{
int DDD[8] = {61, 71, 11, 21, 32, 19, 27, 31};
string Destination[8] = {"Brasilia", "Salvador", "Sao Paulo", "Rio de Janeiro", "Juiz de Fora", "Campinas", "Vitoria", "Belo Horizonte"};
int n;
cin >> n;
for (int i = 0; i < 8; i ++ )
{
if(n==DDD[i])
{
cout << Destination[i];
break;
}
else if (i==7)
{
cout << "DDD nao cadastrado";
}
}
return 0;
}
3.时间转换
题目
读取四个整数 A,B,C,D,用来表示游戏的开始时间和结束时间。
其中 A 和 B 为开始时刻的小时和分钟数,C 和 D为结束时刻的小时和分钟数。
请你计算游戏的持续时间。
比赛最短持续 1分钟,最长持续 24 小时。
输入格式
共一行,包含四个整数 A,B,C,D。
输出格式
输出格式为 O JOGO DUROU X HORA(S) E Y MINUTO(S),表示游戏共持续了 X� 小时 Y� 分钟。
数据范围
0≤A,C≤23
0≤B,D≤59
输入样例1:
7 8 9 10
输出样例1:
O JOGO DUROU 2 HORA(S) E 2 MINUTO(S)
输入样例2:
7 7 7 7
输出样例2:
O JOGO DUROU 24 HORA(S) E 0 MINUTO(S)
输入样例3:
7 10 8 9
输出样例3:
O JOGO DUROU 0 HORA(S) E 59 MINUTO(S)
题解
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
int main()
{
int a,b,c,d;
cin >> a>>b>>c>>d;
int t=(c*60+d)-(a*60+b);
if(t==0)
{
cout << "O JOGO DUROU 24 HORA(S) E 0 MINUTO(S)"<<endl;
}
else if(t>0)
{
int h=t/60;
int m=t%60;
printf("O JOGO DUROU %d HORA(S) E %d MINUTO(S)",h,m);
}
else if(t<0)
{
int h=(c+24)*60;
int x=(h+d)-(a*60+b);
printf("O JOGO DUROU %d HORA(S) E %d MINUTO(S)",x/60,x%60);
}
return 0;
}
4.简单排序(sort排序)
题目
这里用到了sort排序
具体文章在CSDN
读取三个整数并按升序对它们进行排序。
输入格式
共一行,包含三个整数。
输出格式
首先,将三个整数按升序顺序输出,每行输出一个整数。
然后,输出一个空行。
紧接着,将三个整数按原输入顺序输出,每行输出一个整数。
数据范围
?100≤输入整数≤100,
输入整数各不相同。
输入样例:
7 21 -14
输出样例:
-14
7
21
7
21
-14
题解:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
int main()
{
int a[3];
int b[3];
for (int i = 0; i < 3; i ++ )
{
cin>>a[i];
b[i]=a[i];
}
sort(a,a+3);
for (int i = 0; i <3; i ++ )
{
cout << a[i]<<endl;
}
cout << endl;
for (int i = 0; i <3; i ++ )
{
cout << b[i]<<endl;
}
return 0;
}
5.PUM(矩阵)
题目
输入两个整数 N 和 M,构造一个 N 行 M 列的数字矩阵,矩阵中的数字从第一行到最后一行,按从左到右的顺序依次为 1,2,3,…,N×M。
矩阵构造完成后,将每行的最后一个数字变为 PUM。
输出最终矩阵。
输入格式
共一行,包含两个整数 N 和 M。
输出格式
输出最终矩阵,具体形式参照输出样例。
数据范围
1≤N,M≤20
输入样例:
7 4
输出样例:
1 2 3 PUM
5 6 7 PUM
9 10 11 PUM
13 14 15 PUM
17 18 19 PUM
21 22 23 PUM
25 26 27 PUM
题解:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
int main()
{
int x,y;
cin >> x >> y;
int a[x][y];
int s=1;
for(int i=0;i<x;i++)
{
for (int j = 0; j < y-1; j ++ )
{
cout <<s++<<" ";
if(j==y-2)
{
cout << "PUM";
s++;
}
}
cout << endl;
}
return 0;
}
6.实验
题目
医学部一共进行了 N 场动物实验。
共有三种小动物可用来实验,分别是青蛙、老鼠和兔子。
每次实验都会选取其中一种动物来参与实验,选取数量若干。
现在请你统计一下医学部一共用了多少小动物,每种分别用了多少,每种动物使用数量占总量的百分比分别是多少。
输入格式
第一行包含整数 N,表示实验次数。
接下来 N 行,每行包含一个整数 A(表示一次实验使用的小动物的数量)和一个字符 T(表示一次实验使用的小动物的类型,C 表示兔子(coney),R 表示老鼠(rat),F 表示青蛙(frog))。
输出格式
请你参照输出样例,输出所用动物总数,每种动物的数量,以及每种动物所占百分比。
注意输出百分比时,保留两位小数。
数据范围
1≤N≤100
1≤A≤15
输入样例:
10
10 C
6 R
15 F
5 C
14 R
9 C
6 R
8 F
5 C
14 R
输出样例:
Total: 92 animals
Total coneys: 29
Total rats: 40
Total frogs: 23
Percentage of coneys: 31.52 %
Percentage of rats: 43.48 %
Percentage of frogs: 25.00 %
题解:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
int main()
{
int n;
cin >> n;
int m;
char t;
int c=0,r=0,f=0,sum=0;
double s1,s2,s3;
for(int i=0;i<n;i++)
{
cin >> m>>t;
switch(t)
{
case 'C':
c=c+m;
break;
case 'R':
r=r+m;
break;
case 'F':
f=f+m;
break;
}
sum=sum+m;
}
s1=(double)c/(double)sum*100;
s2=(double)r/(double)sum*100;
s3=(double)f/(double)sum*100;
cout << "Total: "<<sum<<" animals"<< endl ;
cout <<"Total coneys: "<<c<<endl;
cout <<"Total rats: "<<r<<endl;
cout <<"Total frogs: "<<f<<endl;
printf("Percentage of coneys: %.2lf %\n",s1);
printf("Percentage of rats: %.2lf %\n",s2);
printf("Percentage of frogs: %.2lf %\n",s3);
return 0;
}
7.区间奇数和
题目
问题:写的时候交换两个数的值的时候代码写错
输入 N 对整数对 X,Y,对于每对 X,Y,请你求出它们之间(不包括 X 和 Y)的所有奇数的和。
输入格式
第一行输入整数 N,表示共有 N 对测试数据。
接下来 N 行,每行输入一组整数 X 和 Y。
输出格式
每对 X,Y 输出一个占一行的奇数和。
数据范围
1≤N≤100
?1000≤X,Y≤1000
输入样例:
7
4 5
13 10
6 4
3 3
3 5
3 4
3 8
输出样例:
0
11
5
0
0
0
12
题解:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
int main()
{
int n;
cin >> n;
int sum=0;
for (int i = 0; i < n; i ++ )
{
int a,b;
cin >> a >> b;
if(a>b){
b=a;
int t=b;
a=t;
}
for ( int j=a+1; j < b; j ++ )
{
if(abs(j)%2==1)
{
sum=sum+j;
}
}
cout <<sum<<endl;
sum=0;
}
return 0;
}
8.数字序列和它的和
题目
输入若干个整数对 M,N,对于每个数对,输出以这两个数为最大值和最小值的公差为 11 的等差数列。
注意,当输入整数对中,任意一个数为 00 或负整数时,立即停止输入,且该组数对无需作任何处理。
输入格式
输入共若干行,每行包含两个整数。
最后一行的两个整数中,至少有一个是非正整数。
输出格式
对于每组需作处理的数对,输出一个结果,每个结果占一行。
结果包含从最小值到最大值的数字序列以及数字序列各数字之和。
具体格式请参照输出样例。
数据范围
M,N≤100
输入样例:
2 5
6 3
5 0
输出样例:
2 3 4 5 Sum=14
3 4 5 6 Sum=18
题解:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
int main()
{
int n=10000;
for (int i = 0; i < n; i ++ )
{
int x,y;
int sum=0;
cin >> x>>y;
if(x<=0||y<=0)
break;
if(x>y)
swap(x,y);
int t=y-x;
for (int i = 0; i <=t; i ++ )
{
sum=sum+x;
cout << x++<<" ";
}
cout <<"Sum="<<sum<<endl;
}
return 0;
}
9.完全数(***)
题目
一个整数,除了本身以外的其他所有约数的和如果等于该数,那么我们就称这个整数为完全数。
例如,66就是一个完全数,因为它的除了本身以外的其他约数的和为 1+2+3=6。
现在,给定你 N个整数,请你依次判断这些数是否是完全数。
输入格式
第一行包含整数 N,表示共有 N 个测试用例。
接下来 N 行,每行包含一个需要你进行判断的整数 X。
输出格式
每个测试用例输出一个结果,每个结果占一行。
如果测试数据是完全数,则输出 X is perfect,其中 X 是测试数据。
如果测试数据不是完全数,则输出 X is not perfect,其中 X 是测试数据。
数据范围
1≤N≤100
1≤X≤10^8
输入样例:
3
6
5
28
输出样例:
6 is perfect
5 is not perfect
28 is perfect
#include <iostream>
#include <cstring>
#include <algorithm>
#include <cmath>
using namespace std;
int main()
{
int n;
cin >> n;
for (int i = 0; i < n; i ++ )
{
int ans=0;
int a;
cin >> a;
for (int i = 1; i <=sqrt(a); i ++ )//暴力优化,举例6,2是6的约数,那么6/2=3也是
{
if(a%i==0)
{
ans+=i;
if(i!=a/i)
ans=ans+a/i;
}
}
ans=ans-a;//在i=1 != 6/1时加上了6本身
if (ans==a&&a!=1)
{
cout << a<<" is perfect"<<endl;
}
else
{
cout << a<<" is not perfect"<<endl;
}
}
return 0;
}
10.打印菱形(曼哈顿距离)
题目
使用曼哈顿距离公式打印菱形_c++曼哈顿距离棱形-CSDN博客
输入一个奇数 n,输出一个由 * 构成的 n 阶实心菱形。
输入格式
一个奇数 n。
输出格式
输出一个由 * 构成的 n 阶实心菱形。
具体格式参照输出样例。
数据范围
1≤n≤99
输入样例:
5
输出样例:
*
***
*****
***
*
题解:
#include <iostream>
#include <cmath>
using namespace std;
int main()
{
int n;
cin >> n;
int x=n/2;
int y=n/2;
for (int i = 0; i < n; i ++ )
{
for (int j = 0; j < n; j ++ ){
if(abs(i-x)+abs(j-y)<=n/2)
cout << "*";
else
cout << " ";
}
cout << endl;
}
return 0;
}
11.数组求部分和
左上部分
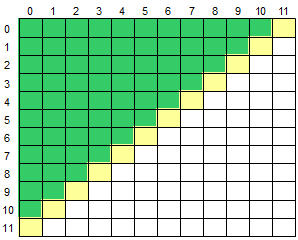
i+j<11
右上部分
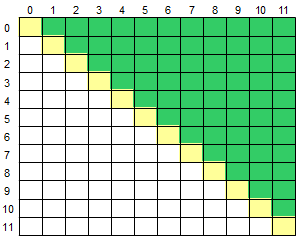
i<j
12.平方矩阵Ⅰ
题目
输入整数 N,输出一个 N阶的回字形二维数组。
数组的最外层为 1,次外层为 2,以此类推。
输入格式
输入包含多行,每行包含一个整数 N。
当输入行为 N=0 时,表示输入结束,且该行无需作任何处理。
输出格式
对于每个输入整数 N,输出一个满足要求的 N 阶二维数组。
每个数组占 N 行,每行包含 N个用空格隔开的整数。
每个数组输出完毕后,输出一个空行。
数据范围
0≤N≤100
输入样例:
1
2
3
4
5
0
输出样例:
1
1 1
1 1
1 1 1
1 2 1
1 1 1
1 1 1 1
1 2 2 1
1 2 2 1
1 1 1 1
1 1 1 1 1
1 2 2 2 1
1 2 3 2 1
1 2 2 2 1
1 1 1 1 1
题解:
#include <iostream>
using namespace std;
int main()
{
int n;
while(cin>>n,n)
{
for (int i = 1; i <= n; i ++ )
{
for (int j = 1; j <= n; j ++ )
{
int up=i,left=j,right=n-j+1,low=n-i+1;
cout << min(min(up,low),min(left,right))<<" ";
}
cout << endl;
}
cout << endl;
}
}
13.平方矩阵Ⅱ
题目:
输入整数 N,输出一个 N阶的二维数组。
数组的形式参照样例。
输入格式
输入包含多行,每行包含一个整数 N。
当输入行为 N=0 时,表示输入结束,且该行无需作任何处理。
输出格式
对于每个输入整数 N,输出一个满足要求的 N 阶二维数组。
每个数组占 N 行,每行包含 N个用空格隔开的整数。
每个数组输出完毕后,输出一个空行。
数据范围
0≤N≤100
输入样例:
1
2
3
4
5
0
输出样例:
1
1 2
2 1
1 2 3
2 1 2
3 2 1
1 2 3 4
2 1 2 3
3 2 1 2
4 3 2 1
1 2 3 4 5
2 1 2 3 4
3 2 1 2 3
4 3 2 1 2
5 4 3 2 1
题解:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 110;
int n;
int a[N][N];
int main()
{
while(cin>>n,n)
{
for (int i = 1; i <= n; i ++ ){
for (int j = i,k=1; j <=n; j ++ ,k++){
a[i][j]=k;
a[j][i]=k;
}
}
for (int i = 1; i <= n; i ++ ){
for (int j = 1; j <= n; j ++ ){
cout << a[i][j]<<" ";
}
cout << endl;
}
cout << endl;
}
}
###解答2、
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 110;
int n;
int a[N][N];
int main()
{
while(cin>>n,n)
{
for (int i = 1; i <= n; i ++ ){
for (int j = 1; j <= n; j ++ ){
a[i][j]=abs(i-j)+1;
cout << a[i][j]<<" ";
}
cout << endl;
}
cout << endl;
}
}
14.找数字
题目:
输入一个整数 N和一个长度为 N 的整数数组 X。
请你找到数组中最小的元素,并输出它的值和下标。
注意,如果有多个最小值,则返回下标最小的那个。
输入格式
第一行包含整数 N。
第二行包含 N 个用空格隔开的整数 X[i]。
输出格式
第一行输出 Minimum value: x,其中 x 为数组元素最小值。
第二行输出 Position: y,其中 y为最小值元素的下标(下标从 00 开始计数)。
数据范围
1<N≤1000
?1000≤X[i]≤1000
输入样例:
10
1 2 3 4 -5 6 7 8 9 10
输出样例:
Minimum value: -5
Position: 4
题解:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
int main()
{
int n;
cin >> n;
int a[n];
int b[n];
for (int i = 0; i < n; i ++ )
{
cin >> a[i];
b[i]=a[i];
}
sort(a,a+n);
cout << "Minimum value: "<<a[0]<<endl;
int k=0;
for (int i = 0; i < n; i ++ )
{
if(a[0]==b[i])
{
k=i;
break;
}
}
cout << "Position: "<<k;
return 0;
}
15.蛇形矩阵
题目:
输入两个整数 n 和 m,输出一个 n 行 m 列的矩阵,将数字 1到 n×m 按照回字蛇形填充至矩阵中。
具体矩阵形式可参考样例。
输入格式
输入共一行,包含两个整数 n 和 m。
输出格式
输出满足要求的矩阵。
矩阵占 n行,每行包含 m 个空格隔开的整数。
数据范围
1≤n,m≤100
输入样例:
3 3
输出样例:
1 2 3
8 9 4
7 6 5
题解:
#include <iostream>
using namespace std;
int arr[100][100];
int main()
{
int n,m;
cin >> n>>m;
int dx[4] = {-1, 0, 1, 0}, dy[4] = {0, 1, 0, -1};
int x=0,y=0;
int d=0;
for (int i = 1; i <=n*m; i ++ )
{
arr[x][y]=i;
int a=x+dx[d],b=y+dy[d];
if(a<0||a>=n||b<0||b>=m||arr[a][b])
{
d=(d+1)%4;
a=x+dx[d];
b=y+dy[d];
}
x=a;
y=b;
}
for (int i = 0; i < n; i ++ ){
for (int j = 0; j < m; j ++ )
{
cout << arr[i][j]<<" ";
}
cout << endl;
}
return 0;
}
16.旋转数组
题目:
输入一个 n,再输入 n个整数。将这个数组顺时针旋转 k(k≤n)次,最后将结果输出。旋转一次是指:将最左边的数放到最右边。
17.只出现一次的字符
题目:
给你一个只包含小写字母的字符串。
请你判断是否存在只在字符串中出现过一次的字符。
如果存在,则输出满足条件的字符中位置最靠前的那个。
如果没有,输出 no。
输入格式
共一行,包含一个由小写字母构成的字符串。
数据保证字符串的长度不超过 100000。
输出格式
输出满足条件的第一个字符。
如果没有,则输出 no。
输入样例:
abceabcd
输出样例:
e
题解:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
char arr[100010];
int ant[26];
int main()
{
cin >> arr;
for (int i = 0; arr[i]; i ++ )
{
ant[arr[i]-'a']++;
}
for (int i = 0; arr[i]; i ++ )
{
if(ant[arr[i]-'a']==1)
{
cout << arr[i];
return 0;
}
}
puts("no");
return 0;
}
18.字符串插入
题目:
有两个不包含空白字符的字符串 str 和 substr,str的字符个数不超过 10,substr 的字符个数为 3。(字符个数不包括字符串结尾处的 \0。)
将 substr 插入到 str中 ASCII 码最大的那个字符后面,若有多个最大则只考虑第一个。
输入格式
输入包括若干行,每一行为一组测试数据,格式为
str substr
输出格式
对于每一组测试数据,输出插入之后的字符串。
输入样例:
abcab eee
12343 555
输出样例:
abceeeab
12345553
题解:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
int main()
{
string a,b;
while(cin>>a>>b)
{
int max=0;
for(int i=0;i<a.size();i++)
{
if(a[i]>a[max])
max=i;
}
cout << a.insert(max+1,b)<<endl;
}
return 0;
}
19.去掉多余空格(双指针算法)
题目:
输入一个字符串,字符串中可能包含多个连续的空格,请将多余的空格去掉,只留下一个空格。
输入格式
共一行,包含一个字符串。
输出格式
输出去掉多余空格后的字符串,占一行。
数据范围
输入字符串的长度不超过 200。
保证输入字符串的开头和结尾没有空格。
输入样例:
Hello world.This is c language.
输出样例:
Hello world.This is c language.
题解:
#include <iostream>
using namespace std;
int main()
{
string a;
getline(cin,a);
string b;
for (int i = 0; i < a.size(); i ++ )
{
if(a[i]!=' ')b+=a[i];
else
{
b+=' ';
int j=i;
while (j<a.size()&&a[j]==' ')j++;
i=j-1;
}
}
cout << b <<endl;
return 0;
}
20.信息加密
题目:
在传输信息的过程中,为了保证信息的安全,我们需要对原信息进行加密处理,形成加密信息,从而使得信息内容不会被监听者窃取。
现在给定一个字符串,对其进行加密处理。
加密的规则如下:
- 字符串中的小写字母,a加密为 b,b 加密为 c,…,y加密为 z,z加密为 a。
- 字符串中的大写字母,A 加密为 B,B 加密为 C,…,Y加密为 Z,Z加密为 A。
- 字符串中的其他字符,不作处理。
请你输出加密后的字符串。
输入格式
共一行,包含一个字符串。注意字符串中可能包含空格。
输出格式
输出加密后的字符串。
数据范围
输入字符串的长度不超过 100。
输入样例:
Hello! How are you!
输出样例:
Ifmmp! Ipx bsf zpv!
题解:
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
int main()
{
string a;
getline(cin,a);
for (int i = 0; i < a.size(); i ++ ){
if(a[i]>='a'&&a[i]<='z') a[i]='a'+(a[i]-'a'+1)%26;
if (a[i]>='A'&&a[i]<='Z')a[i]='A'+(a[i]-'A'+1)%26;
}
cout << a<<endl;
return 0;
}
21.字符串中最长的连续出现的字符(双指针)
题目:
求一个字符串中最长的连续出现的字符,输出该字符及其出现次数,字符串中无空白字符(空格、回车和 tab),如果这样的字符不止一个,则输出第一个。
输入格式
第一行输入整数 N,表示测试数据的组数。
每组数据占一行,包含一个不含空白字符的字符串,字符串长度不超过 200。
输出格式
共一行,输出最长的连续出现的字符及其出现次数,中间用空格隔开。
输入样例:
2
aaaaabbbbbcccccccdddddddddd
abcdefghigk
输出样例:
d 10
a 1
题解:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
int n;
cin >> n;
while (n -- ){
string a;
cin >> a;
char b;
int j=0;
int cnt=0;
for(int i=0;i<a.size();i++){
j=i;
while (j<a.size()&&a[j]==a[i])j++;
if(j-i>cnt){
cnt=j-i;
b=a[i];
}
i=j-1;
}
cout << b<<" "<<cnt<<endl;
}
return 0;
}
22.最长单词(双指针算法)
题目:
一个以 . 结尾的简单英文句子,单词之间用单个空格分隔,没有缩写形式和其它特殊形式,求句子中的最长单词。
输入格式
输入一行字符串,表示这个简单英文句子,长度不超过 500。
输出格式
该句子中最长的单词。如果多于一个,则输出第一个。
输入样例:
I am a student of Peking University.
输出样例:
University
题解1:
双指针算法:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
string a, b;
getline(cin, a);
int cnt = 0;
for (int i = 0; i < a.size(); i++) {
int j = i;
while (j < a.size() && a[j] != ' '&&a[j]!='.') j++;
if (j - i > cnt) {
cnt = j - i;
b = ""; // 重置为空字符串,以便存储新的最长单词
for (int k = i; k < j; k++) {
b = b + a[k];
}
}
i = j;
}
cout << b << endl;
return 0;
}
题解2:
利用输入字符串的特性,但是要注意以 .结尾
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
string a,b;
while(cin>>a)
{
if(a.back()=='.')a.pop_back();
if(a.size()>b.size()) b=a;
}
cout << b<<endl;
return 0;
}
23.倒排单词
题目:
编写程序,读入一行英文(只包含字母和空格,单词间以单个空格分隔),将所有单词的顺序倒排并输出,依然以单个空格分隔。
输入格式
输入为一个字符串(字符串长度至多为 100)。
输出格式
输出为按要求排序后的字符串。
输入样例:
I am a student
输出样例:
student a am I
题解1:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
string a,b;
while(cin>>a){
b=a+' '+b;
}
cout << b <<endl;
return 0;
}
题解2:
//创建一个字符数组
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
string a[110];
int n=0;
while(cin>>a[n])n++;
for(int i=n-1;i>=0;i--){
a[i]=a[i]+' ';
cout << a[i];
}
return 0;
}
24.字符串移位包含问题(未解决)
题目:
对于一个字符串来说,定义一次循环移位操作为:将字符串的第一个字符移动到末尾形成新的字符串。
给定两个字符串 s1 和 s2,要求判定其中一个字符串是否是另一字符串通过若干次循环移位后的新字符串的子串。
例如 CDAA 是由 AABCD 两次移位后产生的新串 BCDAA 的子串,而 ABCD 与 ACBD 则不能通过多次移位来得到其中一个字符串是新串的子串。
输入格式
共一行,包含两个字符串,中间由单个空格隔开。
字符串只包含字母和数字,长度不超过 30。
输出格式
如果一个字符串是另一字符串通过若干次循环移位产生的新串的子串,则输出 true,否则输出 false。
输入样例:
AABCD CDAA
输出样例:
true
题解:
25.有时间再看

k < j; k++) {
b = b + a[k];
}
}
i = j;
}
cout << b << endl;
return 0;
}
### 题解2:
利用输入字符串的特性,但是要注意以 `.`结尾
```c++
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
string a,b;
while(cin>>a)
{
if(a.back()=='.')a.pop_back();
if(a.size()>b.size()) b=a;
}
cout << b<<endl;
return 0;
}
23.倒排单词
题目:
编写程序,读入一行英文(只包含字母和空格,单词间以单个空格分隔),将所有单词的顺序倒排并输出,依然以单个空格分隔。
输入格式
输入为一个字符串(字符串长度至多为 100)。
输出格式
输出为按要求排序后的字符串。
输入样例:
I am a student
输出样例:
student a am I
题解1:
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
string a,b;
while(cin>>a){
b=a+' '+b;
}
cout << b <<endl;
return 0;
}
题解2:
//创建一个字符数组
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
string a[110];
int n=0;
while(cin>>a[n])n++;
for(int i=n-1;i>=0;i--){
a[i]=a[i]+' ';
cout << a[i];
}
return 0;
}
24.字符串移位包含问题(未解决)
题目:
对于一个字符串来说,定义一次循环移位操作为:将字符串的第一个字符移动到末尾形成新的字符串。
给定两个字符串 s1 和 s2,要求判定其中一个字符串是否是另一字符串通过若干次循环移位后的新字符串的子串。
例如 CDAA 是由 AABCD 两次移位后产生的新串 BCDAA 的子串,而 ABCD 与 ACBD 则不能通过多次移位来得到其中一个字符串是新串的子串。
输入格式
共一行,包含两个字符串,中间由单个空格隔开。
字符串只包含字母和数字,长度不超过 30。
输出格式
如果一个字符串是另一字符串通过若干次循环移位产生的新串的子串,则输出 true,否则输出 false。
输入样例:
AABCD CDAA
输出样例:
true
题解:
25.有时间再看
[外链图片转存中…(img-8iskIOae-1704782512596)]
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 国内内卷太严重,还不考虑一下在海外接单?那这几个平台你知道吗?
- Linux:memory: THP: [迷惑行为] 要看源代码的必要性
- Nginx-nginx 负载均衡方式(超详细)
- 【linux】Linux编译器-gcc/g++使用
- 科研常用的网站
- 【Linux调试器】gdb背景和调试方法(入门看这一篇就够了)
- shell解释和权限概念
- 基于物模型的资产监控系统研发
- 【EI会议--快速录用】2024年应用力学与半导体国际学术会议(IACAMS 2024)
- 都是动词+ing 动名词与现在分词短语作目的状语的区别 英语语法 chatGPT学英语