OpenAI 是如何一步一步把RAG做到98%的准确性得
参考OpenAI的官方演讲,如何做好RAG。本文整理的内容,均来源于此演讲内容。
【OpenAI演讲-自制中文字幕】干货-如何提升大模型表现?-提示工程、RAG与Fine-Tuning技巧详解_哔哩哔哩_bilibili
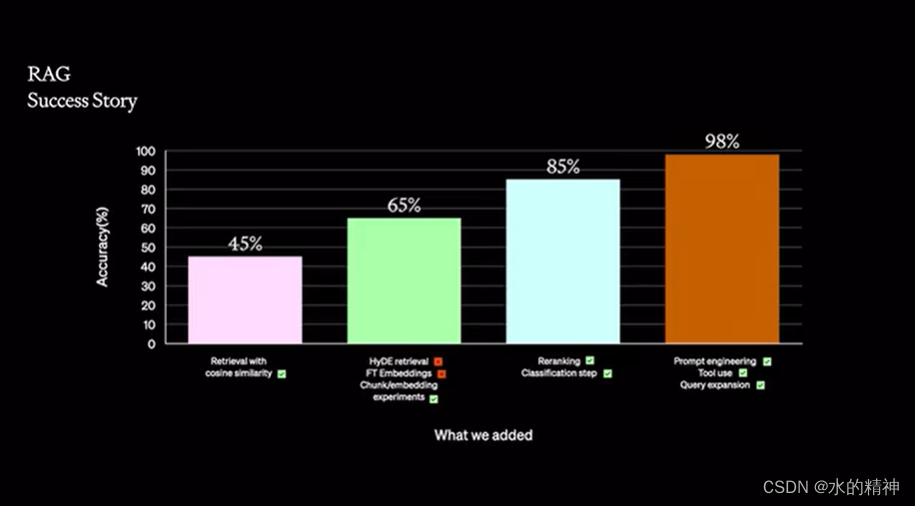
45% 的准确性
普通搜索不做任何处理的效果,OpenAI基准测试的准确性只有45% 。搜索并不是简单的切分,然后做embedding就能有不错的检索效果。
假设性问题和HyDE 提升到65%
另一个方法是让LLM为每个块生成一个假设性问题,并将这些问题以向量形式嵌入。在运行时,针对这个问题向量的索引进行查询搜索(用问题向量替换我们索引中的块向量),检索后将原始文本块作为上下文发送给LLM以获取答案。这种方法由于查询和假设性问题之间的语义相似性更高,从而提高了搜索质量。
还有一种反向逻辑的方法叫做HyDE——您可以让LLM根据查询生成一个假设性回答,然后将该回答的向量与查询向量一起用来提高搜索质量。
从65%提升到85%
尝试调整文本的切分规则,尝试不同大小的切分逻辑;尝试提取更多的内容信息;rerank 召回的数据;尝试使用模型对文本数据进行分类,不同的领域信息进行分类。将问题也进行分类,最后决定哪些数据最优意义。最后效果提升到了85%
从85%提升到98%
将数字类型的数据提取出来放在关系型数据库,因为模型通常对数据是不敏感的,并且数据检索,对检索来说也是一件很有压力的事情。
查询扩展,将一个问题拆分成问题列表。然后分别取执行查询,然后获取到结果,最后将结果合并。
关于要不要微调
OpenAI 也尝试了去微调文本嵌入模型,但是最后放弃了,因为成本高,时间长,收益小。就像OpenAI所说的,任何问题都想着去用微调来解决问题,就是浪费时间浪费金钱。
那什么时候去做微调有意义呢?通常是模型能够接受的token太小,不能满足我们的业务需求时。还有就是模型有严重的性能问题,回答太慢。再有就是将更大的模型优化成跟小的模型,但是有一样的效果,因为这样可以节省资源,也就是省钱。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 红帆HFOffice-findPass-sql注入-未公开Day漏洞复现
- 【css技巧】css设置文字不能被选中
- 485modbus转Profinet网关通信配置步骤与注意事项
- PIL/Pillow
- 如何使用队列处理 API 速率限制
- 软考最新改革版【系统架构设计师考试】如何高效备考?
- python量化学习笔记
- BFC8121防爆应急灯
- Linux文件和目录管理命令---- tail 命令
- 基于STM32的光电传感器应用开发实例