数据库和表的操作
文章目录
前言
一、库的操作
创建数据库
语法:
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [, create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name
说明:
- 大写的表示关键字
- [] 是可选项
- CHARACTER SET: 指定数据库采用的字符集
- COLLATE: 指定数据库字符集的校验规则
我们看到创建一个目录后,Linux的/var/lib/mysql下也会出现对应的目录。
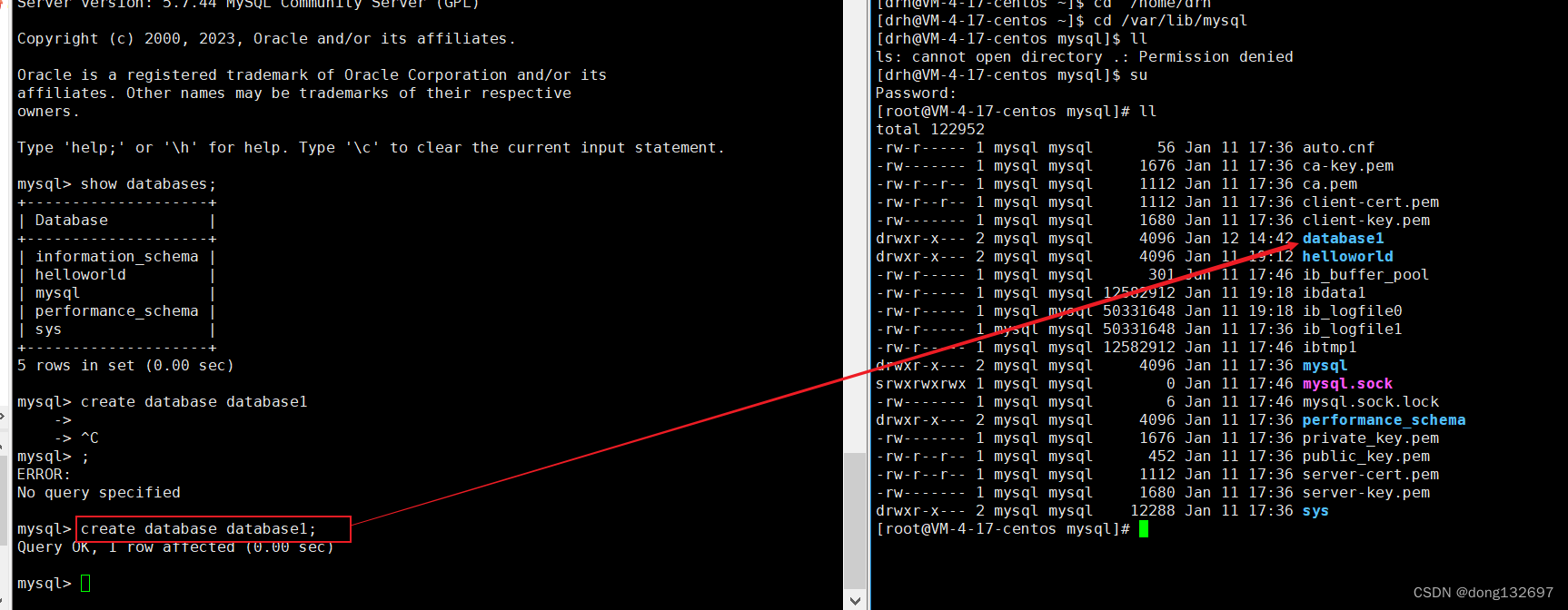
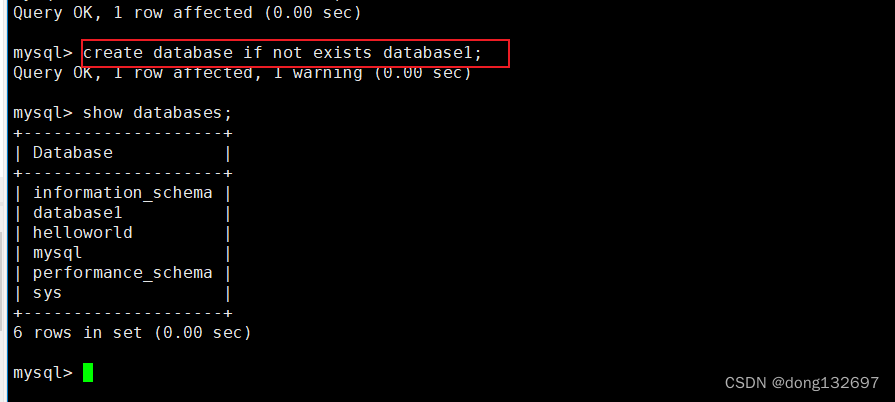
我们也可以在创建数据库时进行判断,如果当前数据库已存在,那么就不再创建。
我们还可以在创建数据库时,指定这个数据库的字符集和校验规则。
下面为创建一个使用utf8字符集的数据库。使用下面的两种方式都可以指定数据库的字符集。
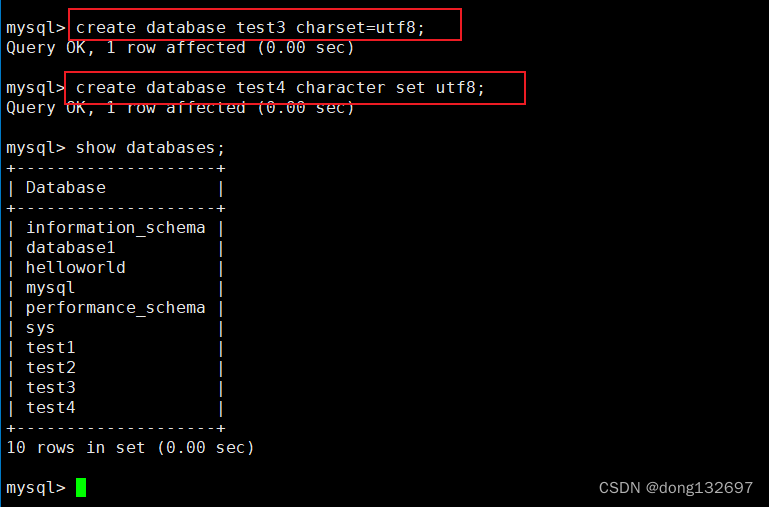
下面创建一个使用utf8字符集,并且校对规则为utf8_general_ci的数据库。

当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则是:utf8_general_ ci
字符集和校验规则
创建数据库的时候还可以设置两个编码集:
- 数据库字符集:数据库未来存储数据所采用的编码。
- 数据库校验集:支持数据库进行字段比较所使用的编码,本质也是一种读取数据库中数据所采用的编码格式。
数据库无论对任何数据做任何操作,都必须保证操作和编码必须是编码一致的。
我们可以通过下面的命令来查看系统默认字符集以及校验规则。
show variables like 'character_set_database'; //查看默认字符集
show variables like 'collation_database'; //查看默认校验规则
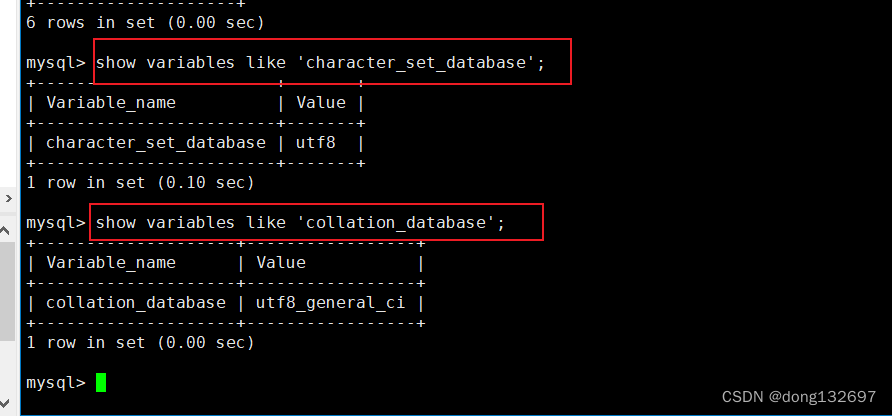
可以看到数据库默认的字符集和配置文件中的一致。
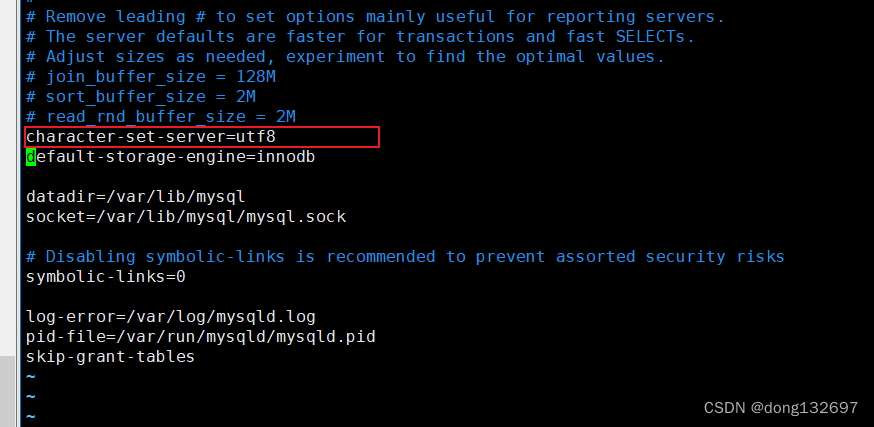
我们可以通过下面的命令来查看数据库支持的字符集。字符集主要是控制用什么语言。比如utf8就可以使用中文。
show charset;
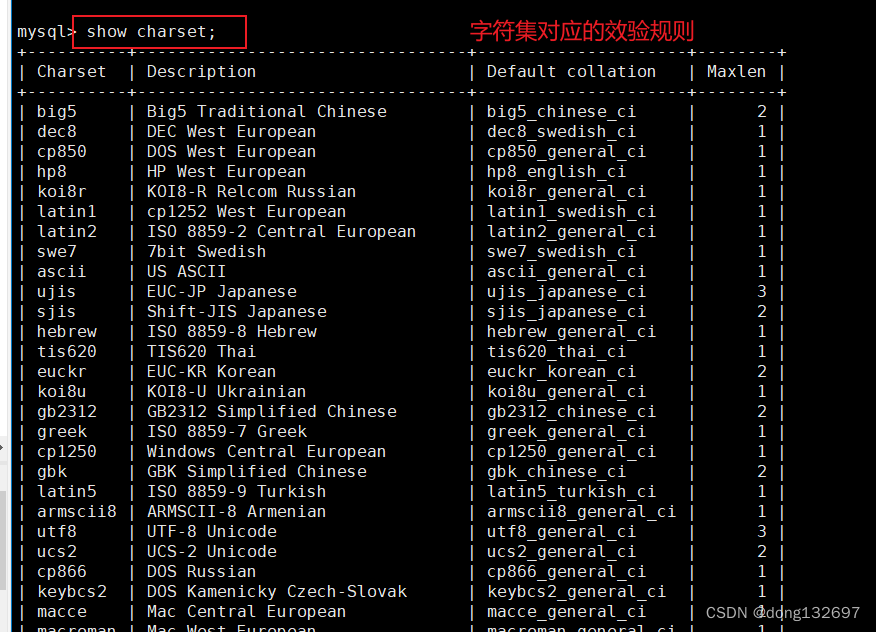
我们可以通过下面的命令查看数据库支持的字符集校验规则。字符集效验规则可用于数据库比较数据时使用。
show collation;
下面我们来体会校验规则对数据库的影响。
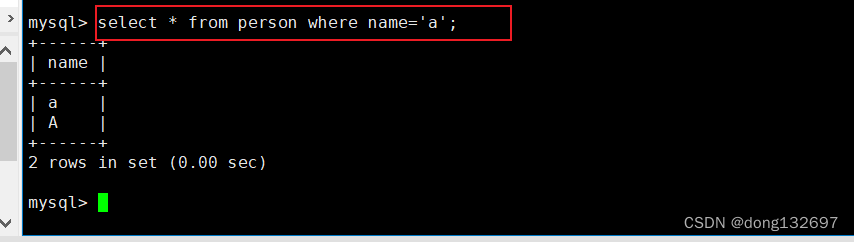
我们创建一个数据库,校验规则使用utf8_general_ci(该校验规则不区分大小写)。然后再创建一个表,并且向表里面插入数据。
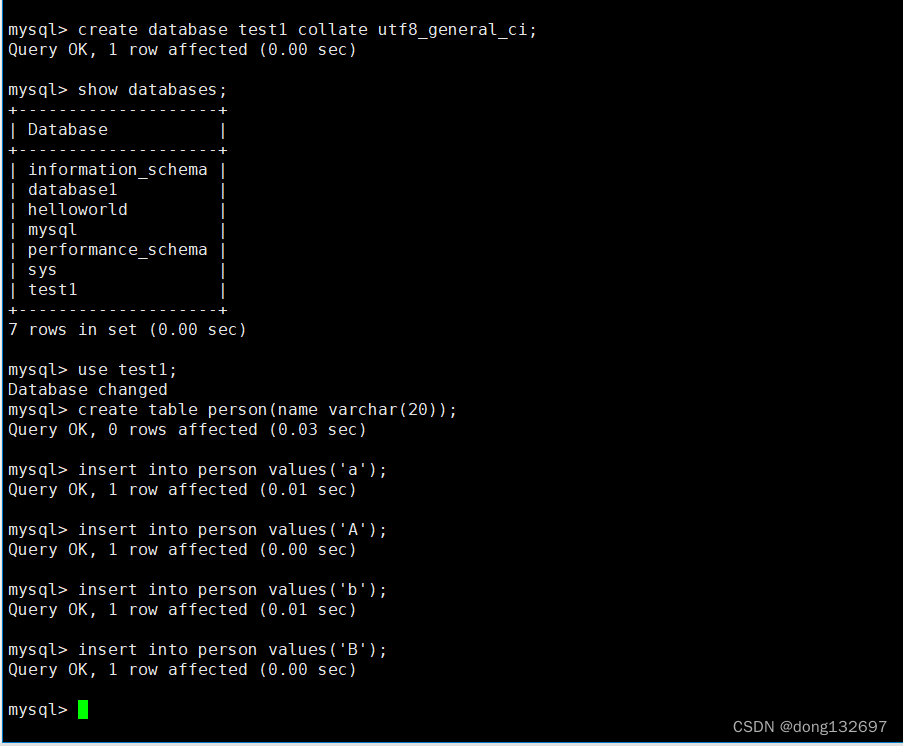
然后我们查看表中name为’a’的数据。我们看到name为’a’和’A’的数据都被显示出来了。
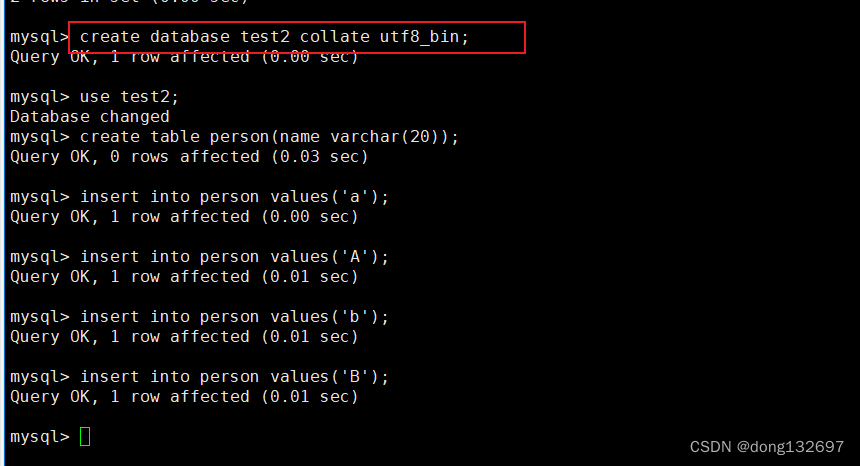
下面我们再创建一个数据库,这个数据库的校验规则使用utf8_ bin(该校验规则区分大小写)。
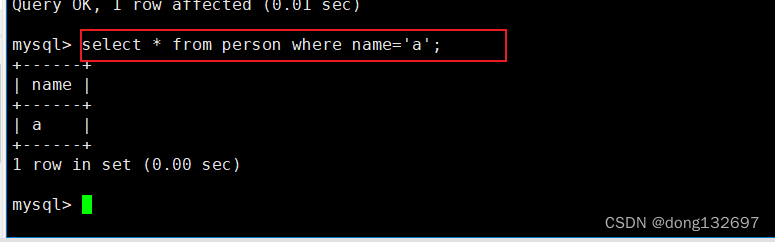
然后我们查看表中name为’a’的数据。然后我们看到只有name为’a’的数据被查询到。即校验规则会对数据库的数据比较造成影响。
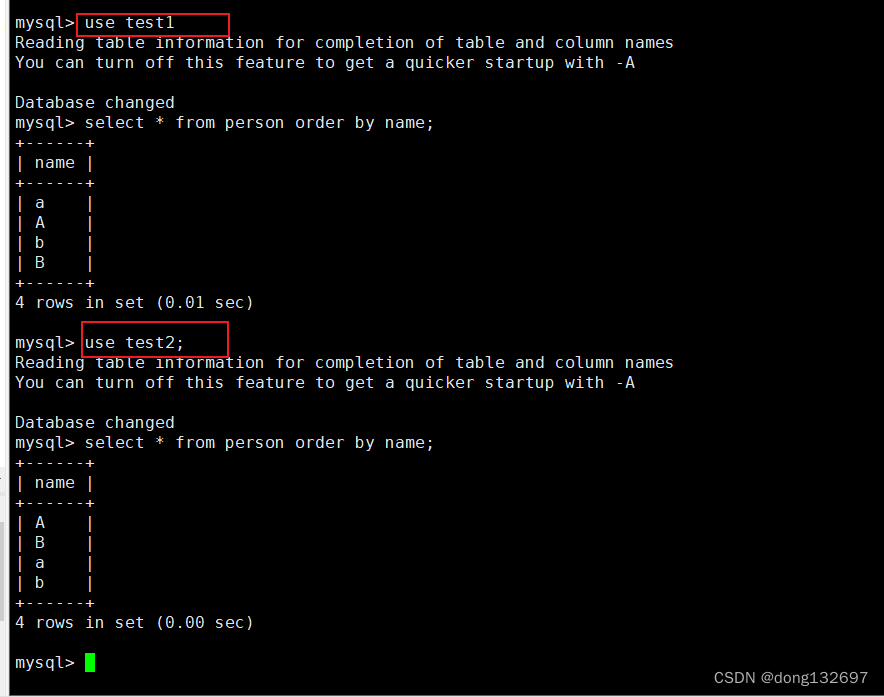
下面我们将两个数据库的person表中的数据进行排序。在test1中,不会区分大小写,所以会将’a’和’A’都放到一起。而在test2中会区分大小写,所以排序时会按照ASCII码进行排序。
操纵数据库
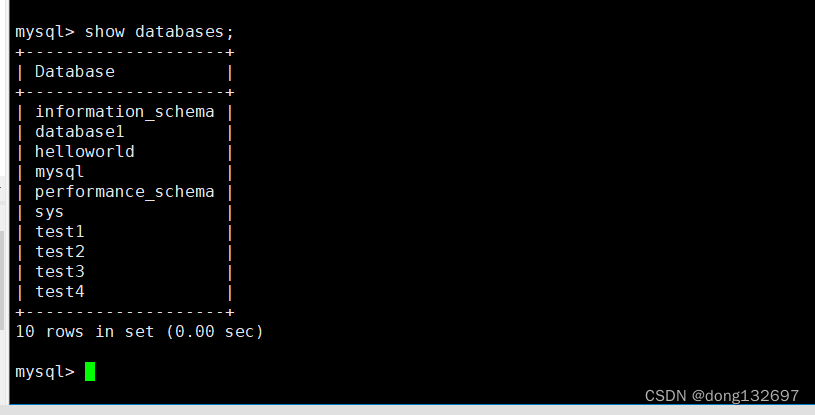
查看数据库
show databases;
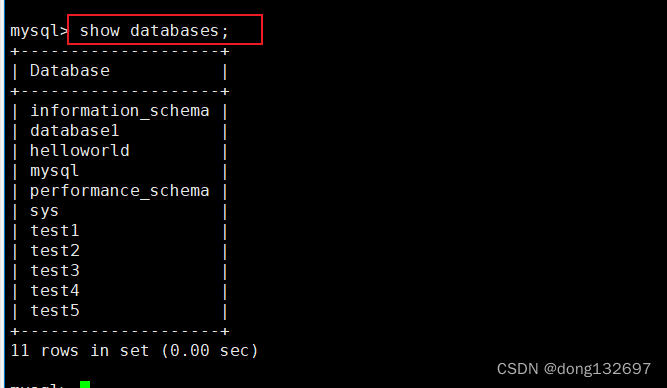
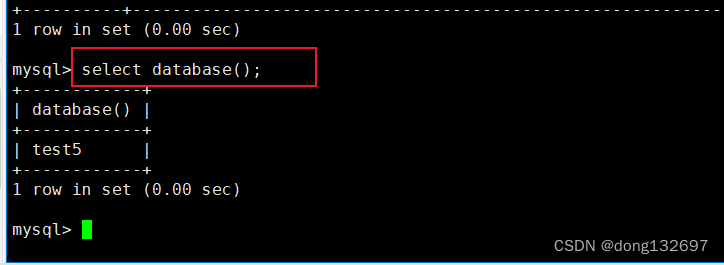
查看自己当前在哪个数据库中,可以使用下面的命令。
select database();
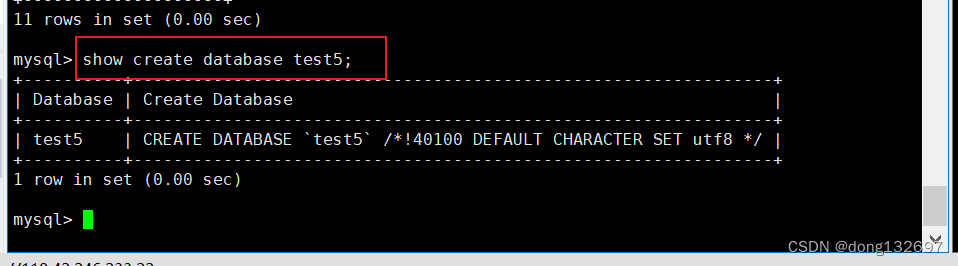
显示创建语句
我们看到显示的创建数据库时的语句和我们自己输入的不一样,这是因为数据库将我们输入的语句进行了规范化。
MySQL 建议我们关键字使用大写,但是不是必须的。
数据库名字的反引号``,是为了防止使用的数据库名刚好是关键字
/*!40100 default… */ 这个不是注释,表示当前mysql版本大于4.01版本,就执行这句话。
show create database 数据库名;
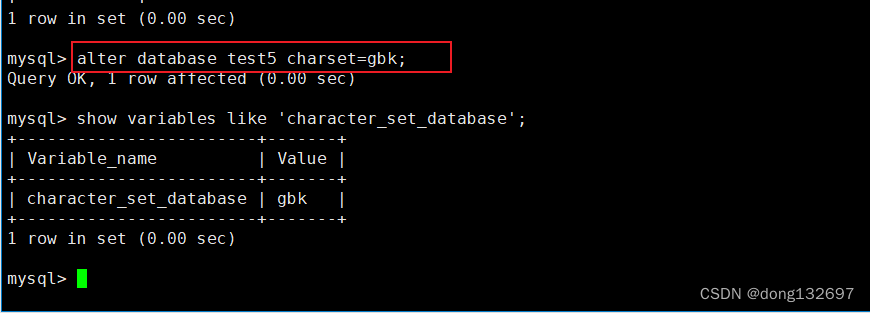
修改数据库
对数据库的修改主要指的是修改数据库的字符集,校验规则。
下面为将 test5 数据库字符集改成 gbk。
alter database test5 charset=gbk;
下面为将test5数据库的校验规则改为gbk_chinese_ci。
alter database test5 collate gbk_chinese_ci;
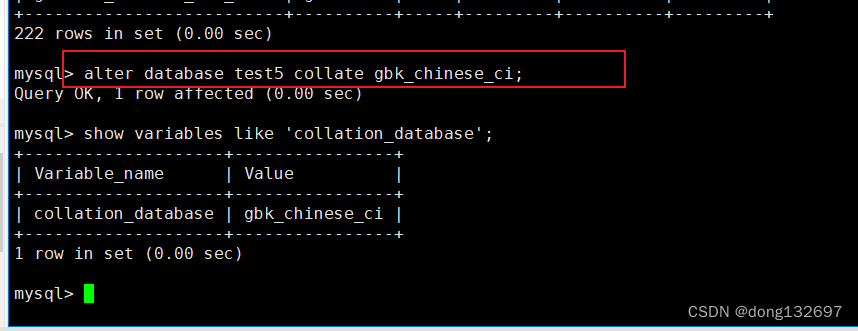
我们看到当我们修改了数据库后,查看数据库创建时的语句时,发现语句也被更改了。

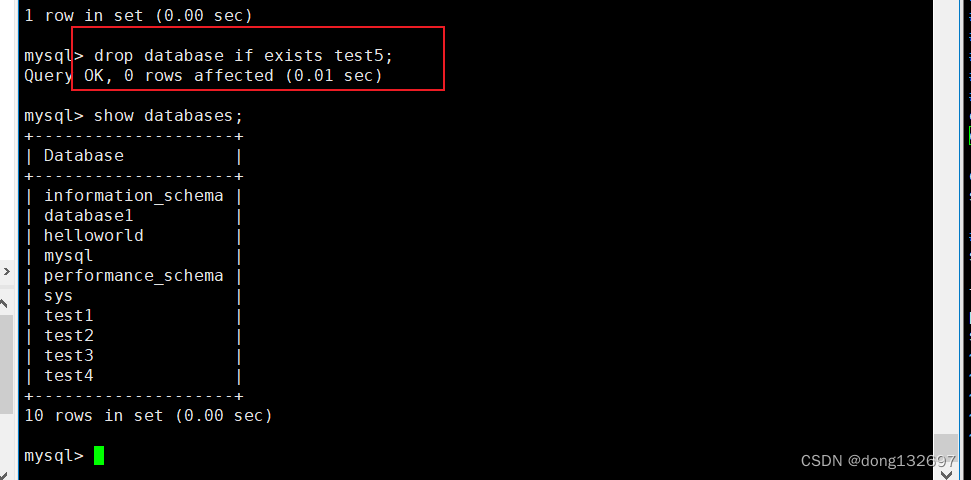
删除数据库
drop database if exists 数据库名;
当数据库被删除后,数据库内部看不到对应的数据库。对应的数据库文件夹被删除,级联删除,里面的数据表全部被删。
备份和恢复
mysqldump -P3306 -u root -p 密码 -B 数据库名 > 数据库备份存储的文件路径
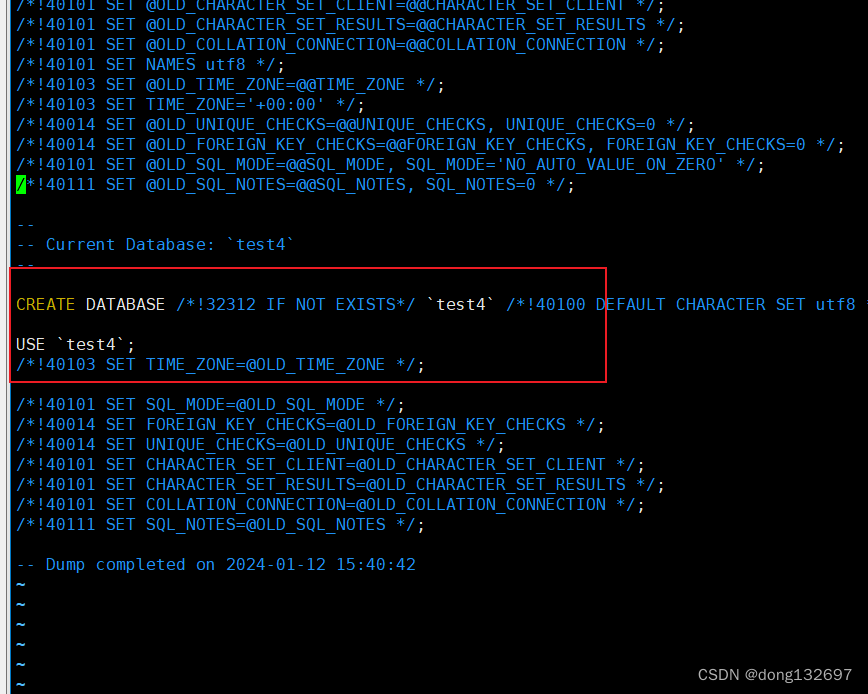
例如下面将数据库test4备份当前目录下的test4.sql。
mysqldump -P3306 -uroot -p -B test4 > test4.sql

我们查看test4.sql这个文件可以看到其实就是把我们整个创建数据库,建表,导入数据的语句都装载这个文
件中。
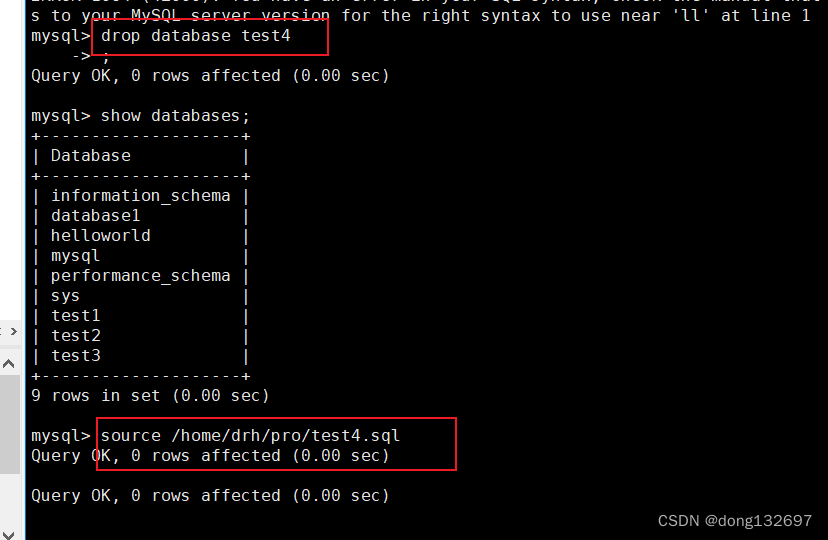
数据库还原
source D:/mysql-5.7.22/mytest.sql;
例如下面我们将数据库test4删除,然后再使用备份文件test4.sql恢复数据库test4。
source /home/drh/pro/test4.sql
如果我们备份的不是整个数据库,而是一张表时,可以使用下面的语句。
mysqldump -u root -p 数据库名 表名1 表名2 > /home/drh/pro/test.sql
如果我们同时备份多个数据库时,可以使用下面的语句。
mysqldump -u root -p -B 数据库名1 数据库名2 ... > 数据库存放路径
如果备份一个数据库时,没有带上-B参数, 在恢复数据库时,需要先创建空数据库,然后使用数据库,再使用source来还原。
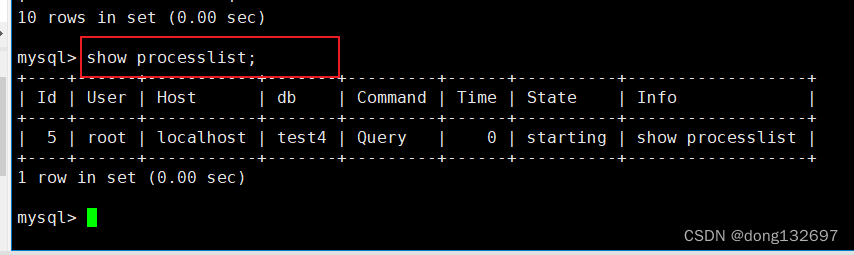
查看连接情况
我们可以通过下面的语句来查看数据库连接情况。这个语句可以告诉我们当前有哪些用户连接到我们的MySQL。
show processlist
二、表的操作
创建表
语法:
CREATE TABLE table_name (
field1 datatype,
field2 datatype,
field3 datatype
) character set 字符集 collate 校验规则 engine 存储引擎;
说明:
- field 表示列名
- datatype 表示列的类型
- character set 字符集,如果没有指定字符集,则以所在数据库的字符集为准
- collate 校验规则,如果没有指定校验规则,则以所在数据库的校验规则为准
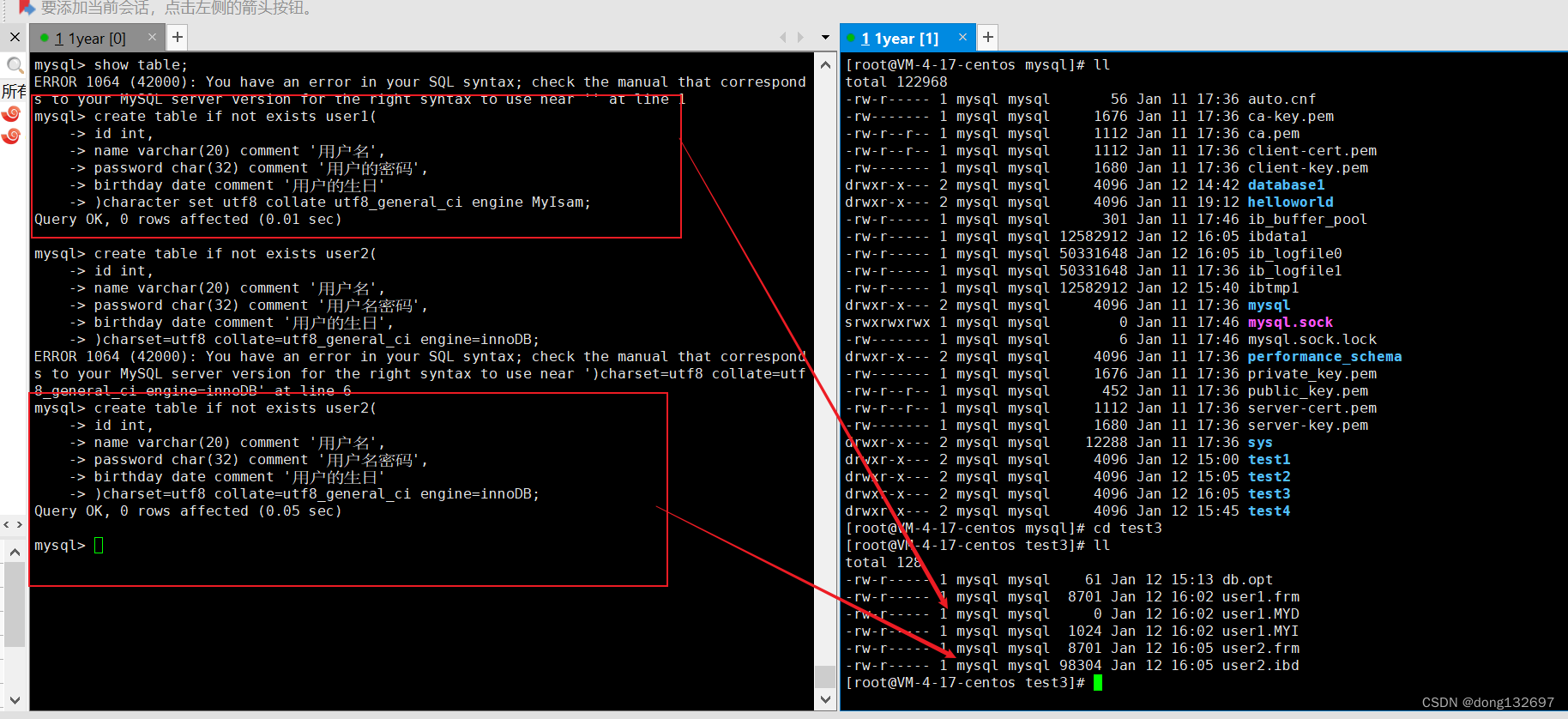
下面我们创建两个字符集为utf8,校验规则为utf8_general_ci,但是存储引擎不同的数据表。我们看到不同的存储引擎,创建表的文件不一样。
user1 表存储引擎是 MyISAM ,在数据目中有三个不同的文件,分别是:
user1.frm:表结构
user1.MYD:表数据
user1.MYI:表索引
user2表存储引擎是 innoDB ,在数据目中有两个个不同的文件,分别是:
user2.frm
user2.ibd
如果我们创建表时没有指定存储引擎,那么就会使用配置文件中的默认存储引擎。
查看表结构
查看当前数据库中的所有表
show tables; //查看当前数据库中的表

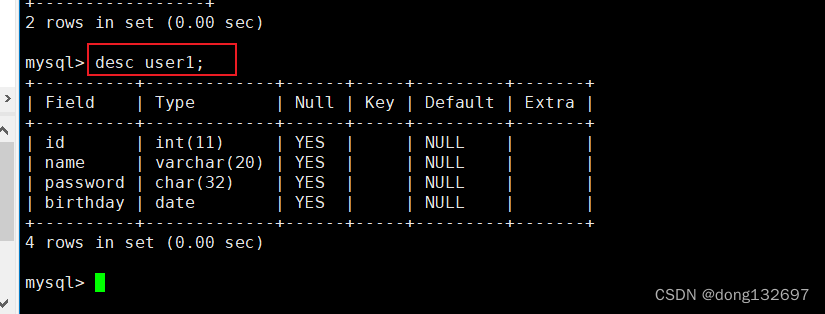
查看某一个表的详细信息。
desc 表名;
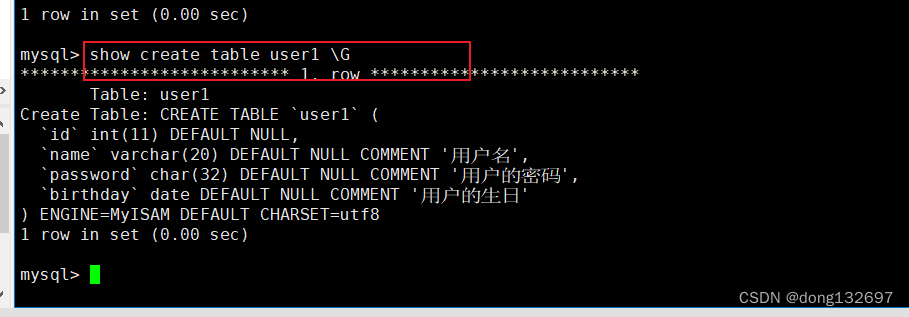
我们还可以通过下面的命令查看创建表时的语句。我们看到据库记录的表创建语句和我们输入的不一样,这是因为数据库记录的是优化后的语句
show create table 表名 \G; //加上\G可以格式化显示
修改表
在项目实际开发中,经常修改某个表的结构,比如字段名字,字段大小,字段类型,表的字符集类型,表的存储引擎等等。我们还有需求,添加字段,删除字段等等。这时我们就需要修改表。
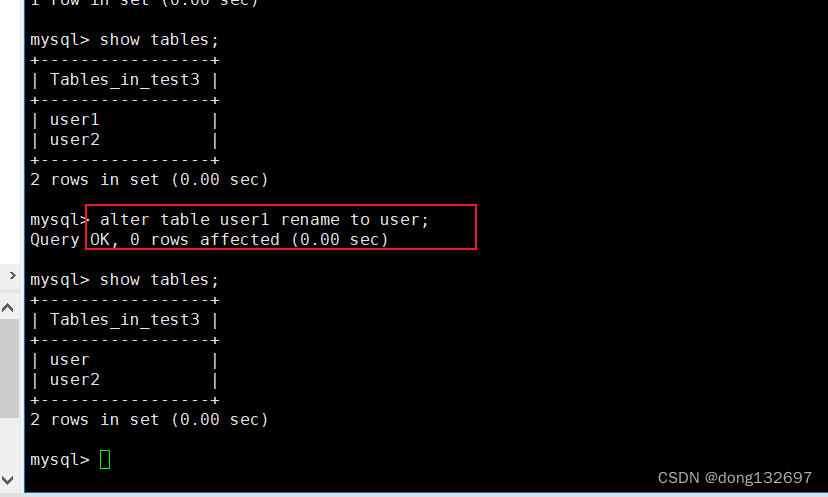
修改表名
修改表user1的名称为user。其中to可以省略。
//修改表user1的名称为user
alter table user1 rename to user;
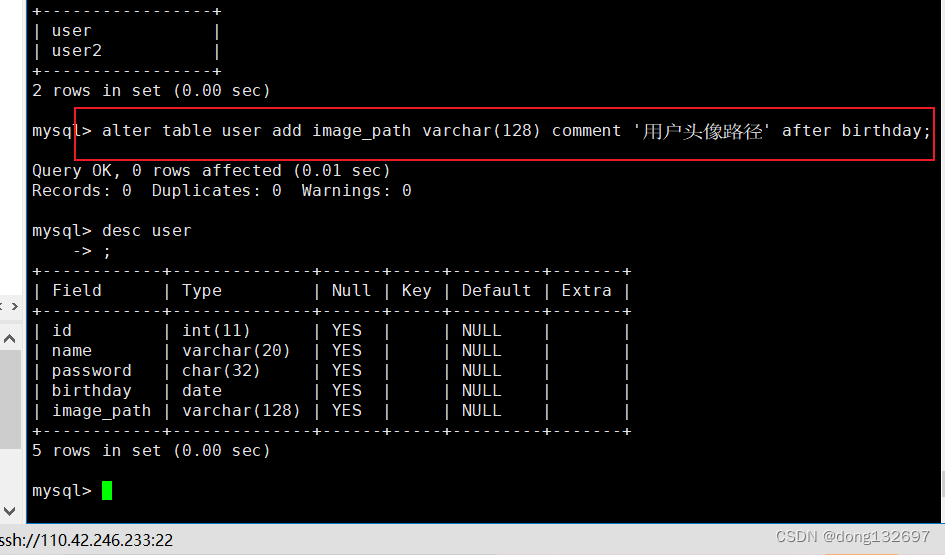
添加一列
下面为在user表中添加一列用来记录用户头像路径,并且这一列在birthday后面。
alter table user add image_path varchar(128) comment '用户头像路径' after birthday;
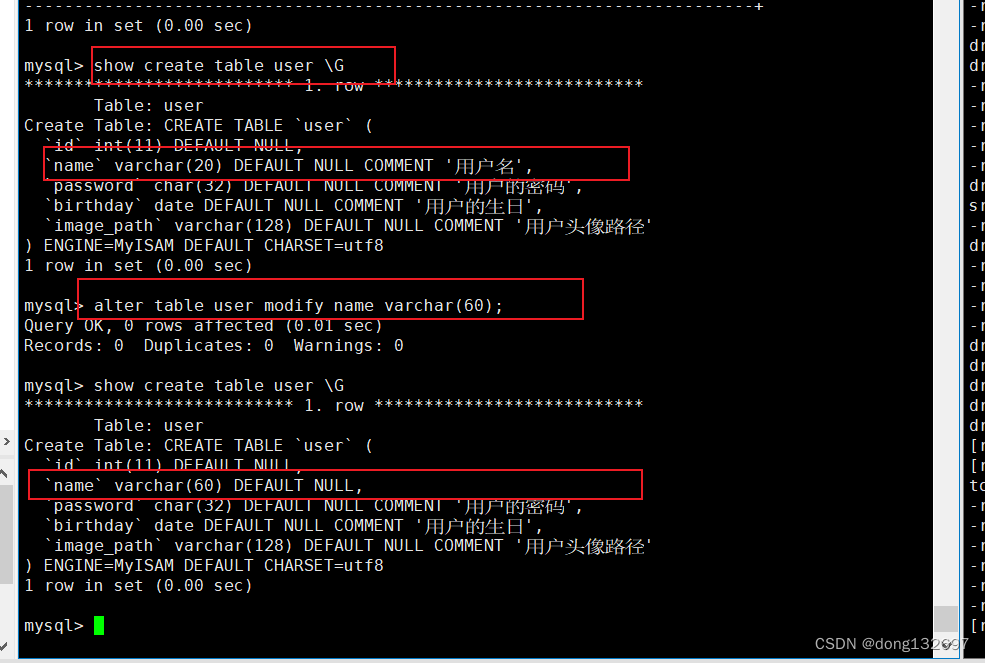
修改某一列属性
下面我们修改name列的长度为60。我们可以看到修改列属性为覆盖式修改。并且当修改表后,数据库中记录的表创建语句也会跟着更改。
删除某一列
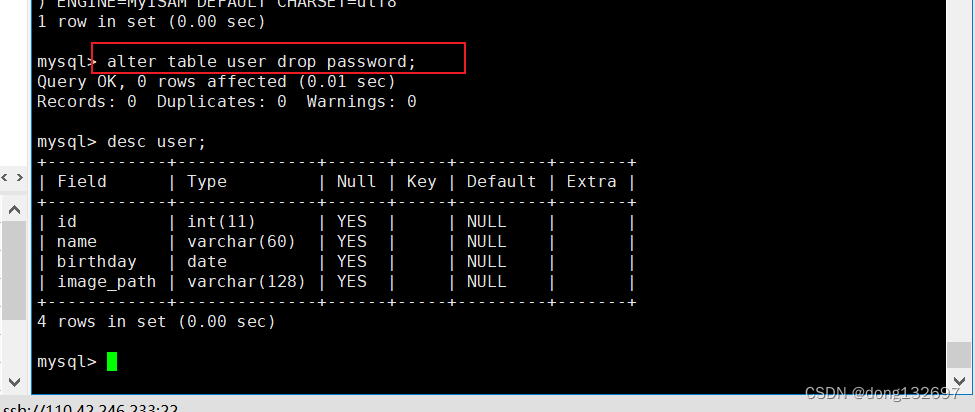
下面我们删除user表中的password这一列。
alter table user drop password;
删除表
语法:
DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name] ...
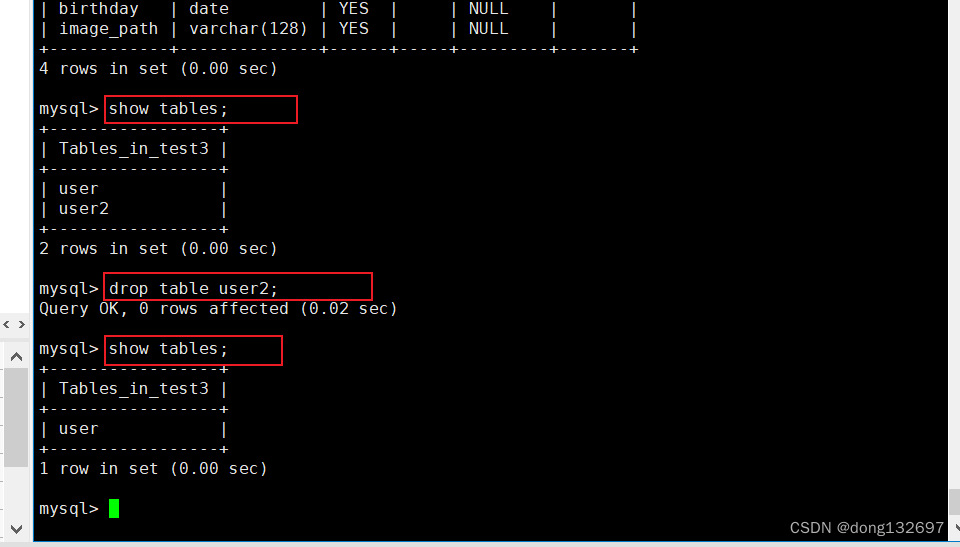
下面我们删除表user2。
drop table user2;
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 给vue的data动态添加新的属性详解(超详细)
- 如何在 Umi /Umi 4.0 中配置自动删除 console.log 语句?
- 解决小程序字体在最左上角问题
- macbook电脑2024免费好用的系统清理优化软件CleanMyMac X4.14.7
- OceanBase基础概念
- 消费数据积压
- 记一次less-loader 报错
- [足式机器人]Part2 Dr. CAN学习笔记-Advanced控制理论 Ch04-3Phase Portrait相图,相轨迹
- centos7 使用openssl 配置证书服务器(史上最详细版本)
- 跨境电商平台的物流服务:解析与利用