亚马逊云科技AI应用 SageMaker 新突破,机器学习优势显著
(声明:本篇文章授权活动官方亚马逊云科技文章转发、改写权,包括不限于在 亚马逊云科技开发者社区、知乎、自媒体平台、第三方开发者媒体等亚马逊云科技官方渠道)
Amazon SageMaker是一种机器学习服务,帮助开发人员快速准备、构建、训练和部署高质量的机器学习模型。本文主要讲解了SageMaker的五项新功能,并使用Sagemaker部署模型并进行推理,最后对数据处理。新功能给SageMaker的使用带来极大的便利,期待未来有更多的创新应用。
SageMaker五项新功能
近日,亚马逊云科技re:Invent大会宣布了Amazon SageMaker中的五项新功能,这些新功能将使用户能够更轻松地构建、训练和部署生成人工智能模型。随着模型不断改变各行业的客户体验,SageMaker使组织能够更轻松、更快速地构建、训练和部署机器学习 (ML) 模型,为各种生成式AI使用案例提供支持。然而,为了成功使用模型,客户需要先进的功能来有效管理模型开发、使用和性能,这些新功能具体如下:
1、SageMaker HyperPod使客户能够自动将训练工作负载分配到数百或数千个加速器上,从而通过缩短模型训练时间来进一步增强 SageMaker 的模型扩展能力。
2、SageMaker Inference允许多个模型部署到同一个实例(虚拟服务器),通过降低模型的部署成本和延迟来优化托管 ML 基础设施操作。
3、SageMaker Clarify可以更轻松地根据支持负责任地使用 AI 的质量参数选择正确的模型。
4、为了帮助客户跨组织应用这些模型,亚马逊云科技还在SageMaker Canvas中引入了新的无代码功能,使客户可以使用自然语言指令更快、更轻松地准备数据。
5、SageMaker Canvas使客户能够更轻松地使用模型来提取见解、进行预测以及使用组织的专有数据生成内容,从而继续实现模型构建和定制的民主化。
这些新的突破建立在SageMaker广泛的功能之上,帮助用户利用ML进行大规模创新,详细可以访问Amazon SageMaker官网:aws.amazon.com/sagemaker。
SageMaker进行模型训练
模型训练采用Stable Diffusion模型,简单地根据文本输入来生成文本和图像,帮助你创建逼真的AIGC应用程序。
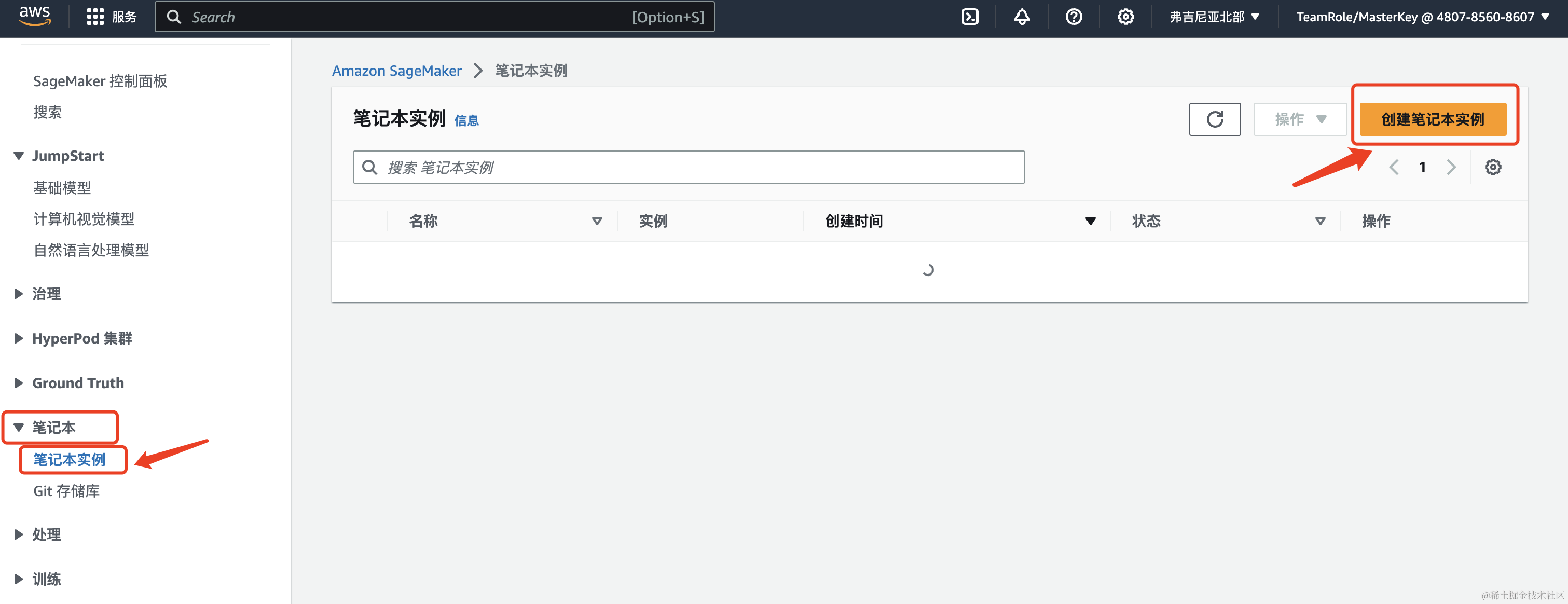
1、创建notebook实例
创建笔记本实例
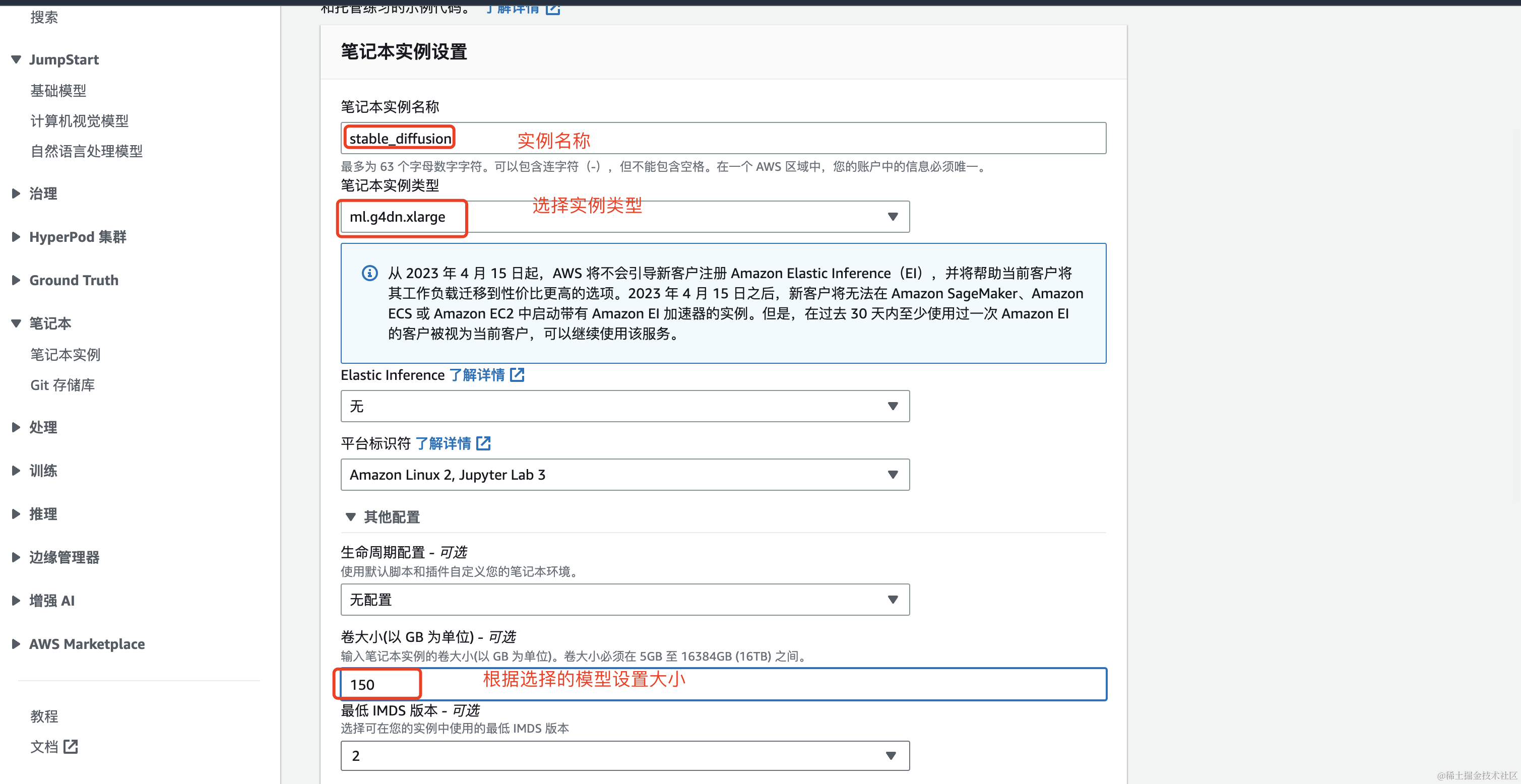
填写笔记本实例的详细信息
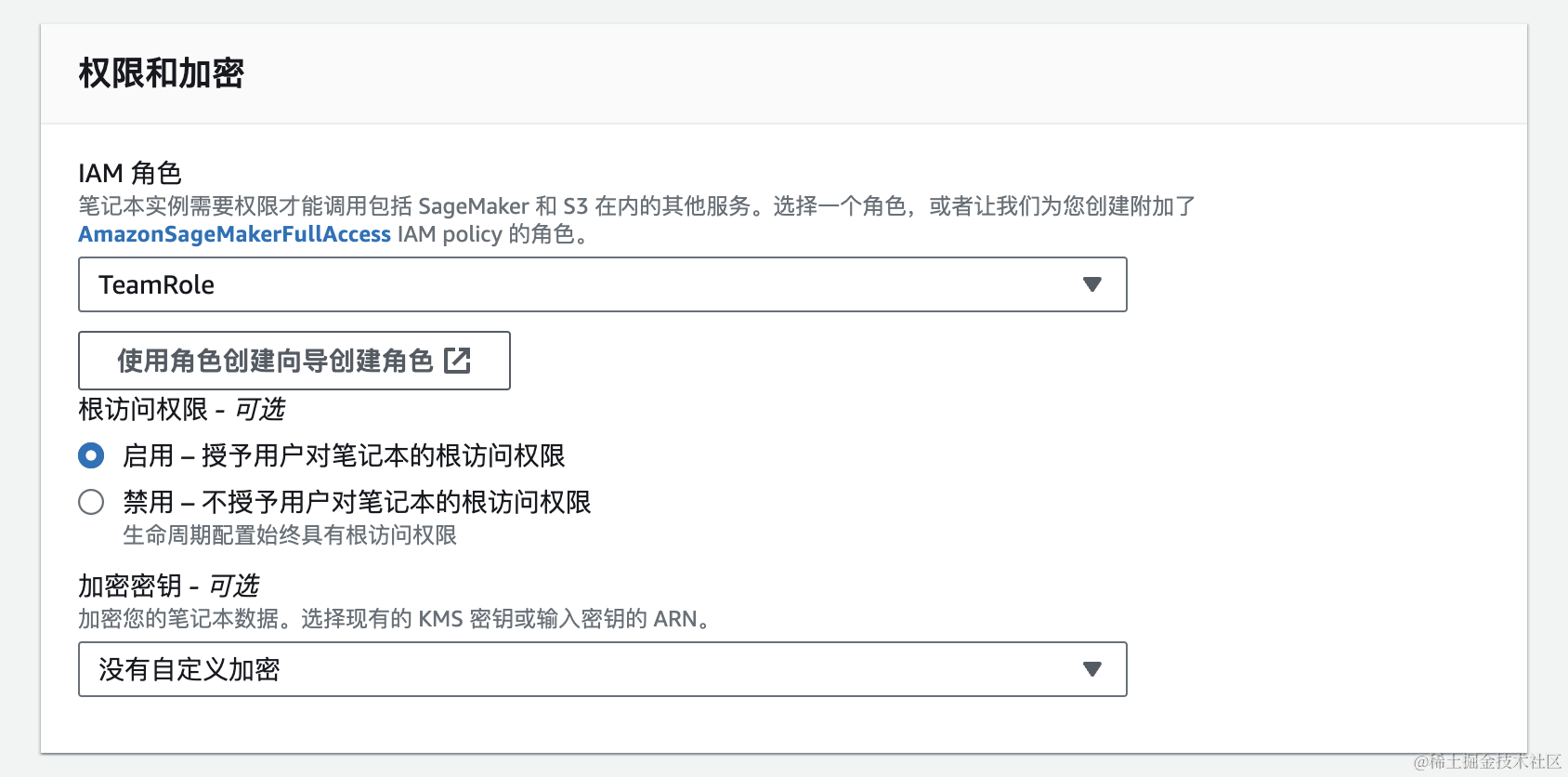
创建角色,没有的话点击使用角色创建向导创建角色
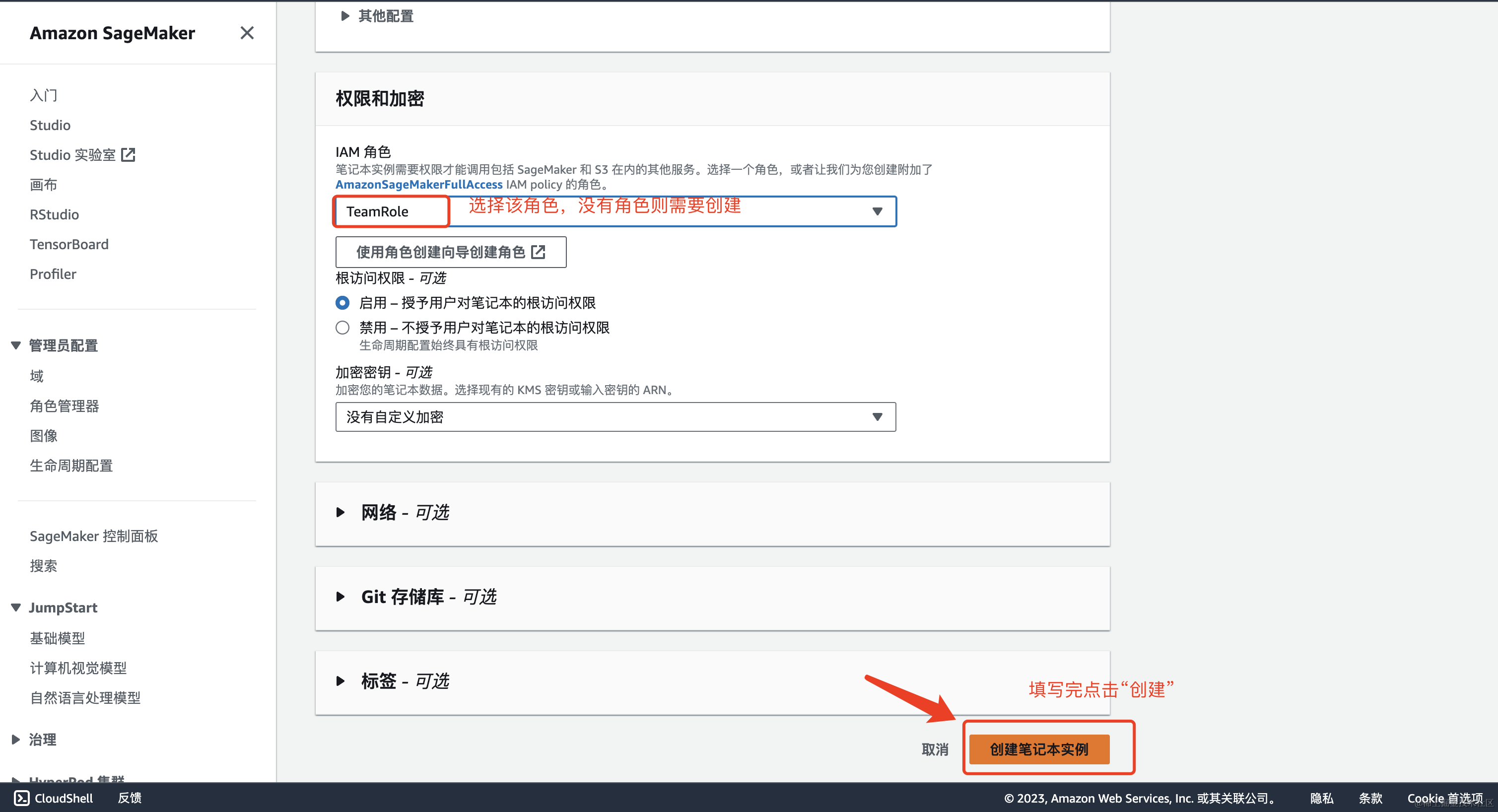
在创建笔记本实例时候,提示实例名称不合规范

因此,修改笔记本实例名称为stable-diffusion
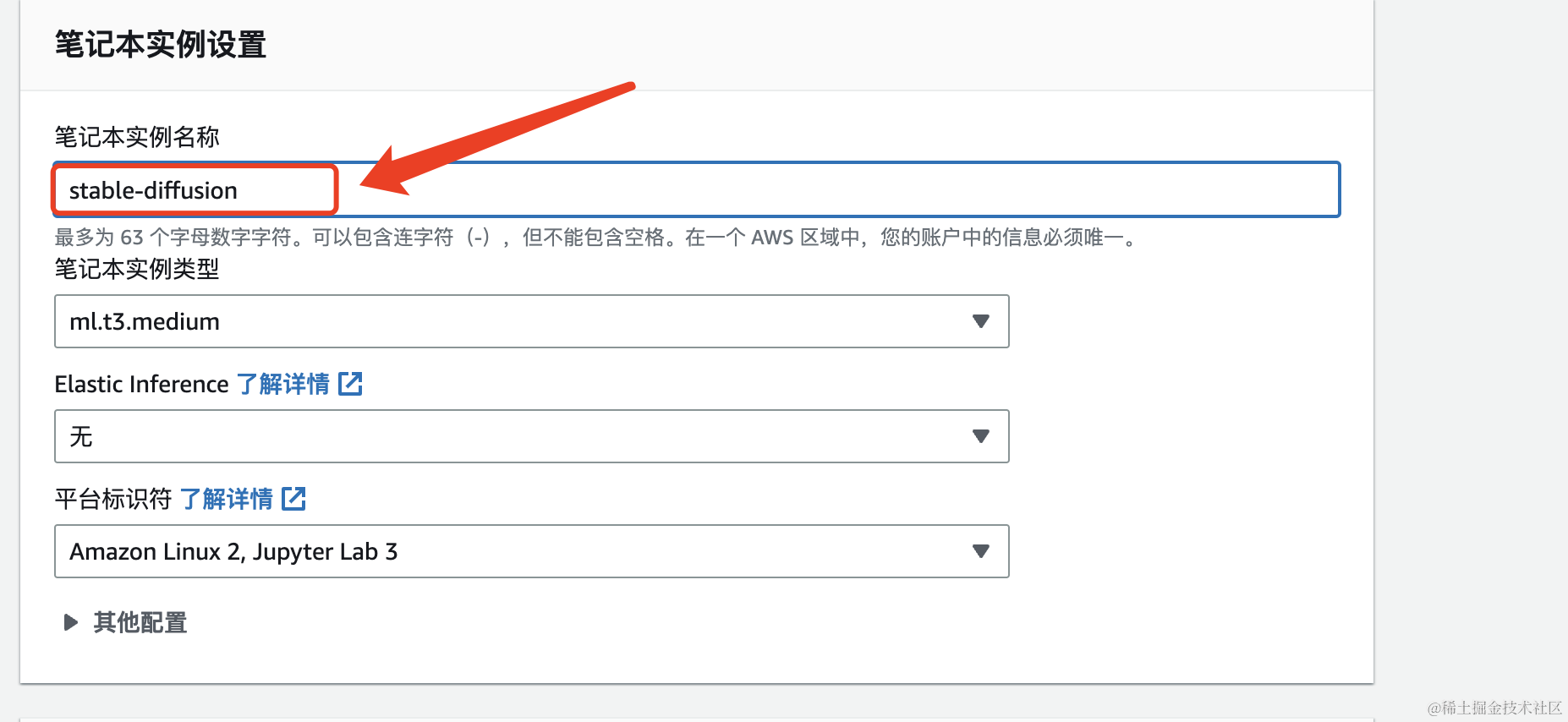
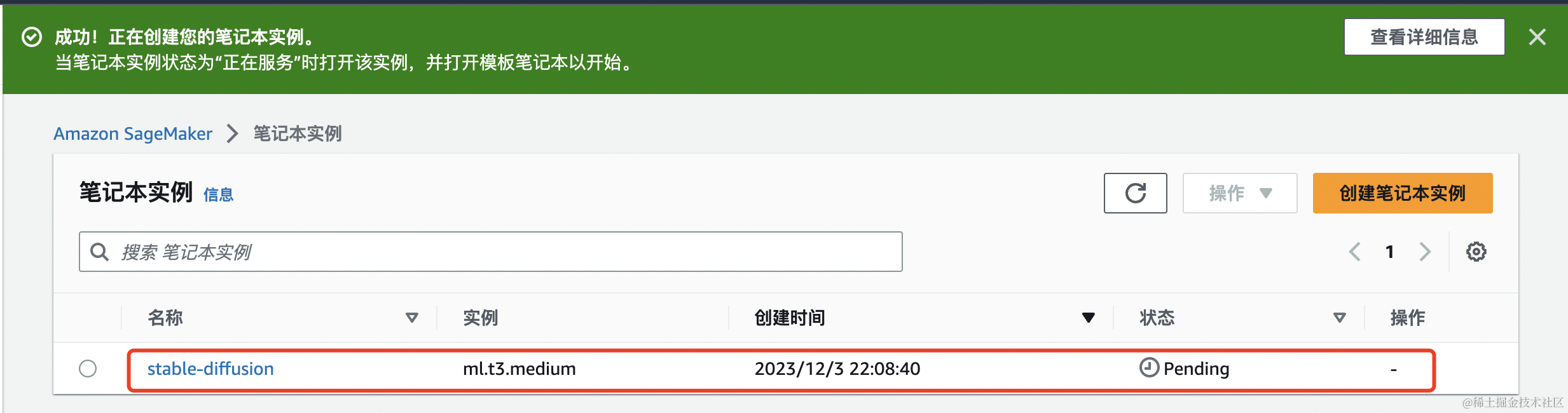
创建成功,此时实例正在创建中,如图中的Pending状态,需要等大概5分钟左右。
此时实例已经创建成功,状态变成InService,然后点击打开Jupyter
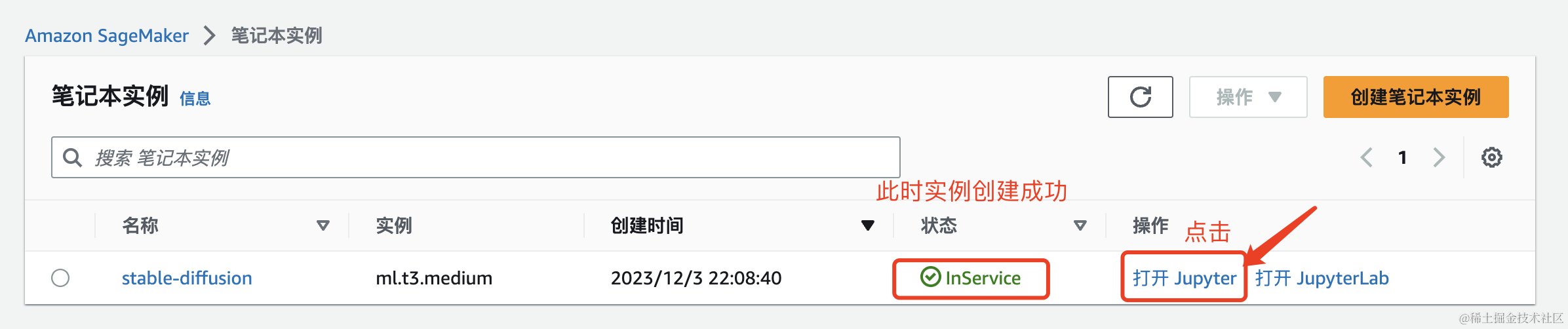
2、使用Sagemaker Notebook Instance部署模型并进行推理
Stable Diffusion是一种文本生成图像模式,给它一个文本提示(prompt),它将返回与文本匹配的图像。本文将在Sagemaker Notebook Instance中运行Stable Diffusion模型,并使用Sagemaker Notebook Instance部署模型进行推理。到达Jupyter主界面后,点击NEW下面的Terminal启动终端。
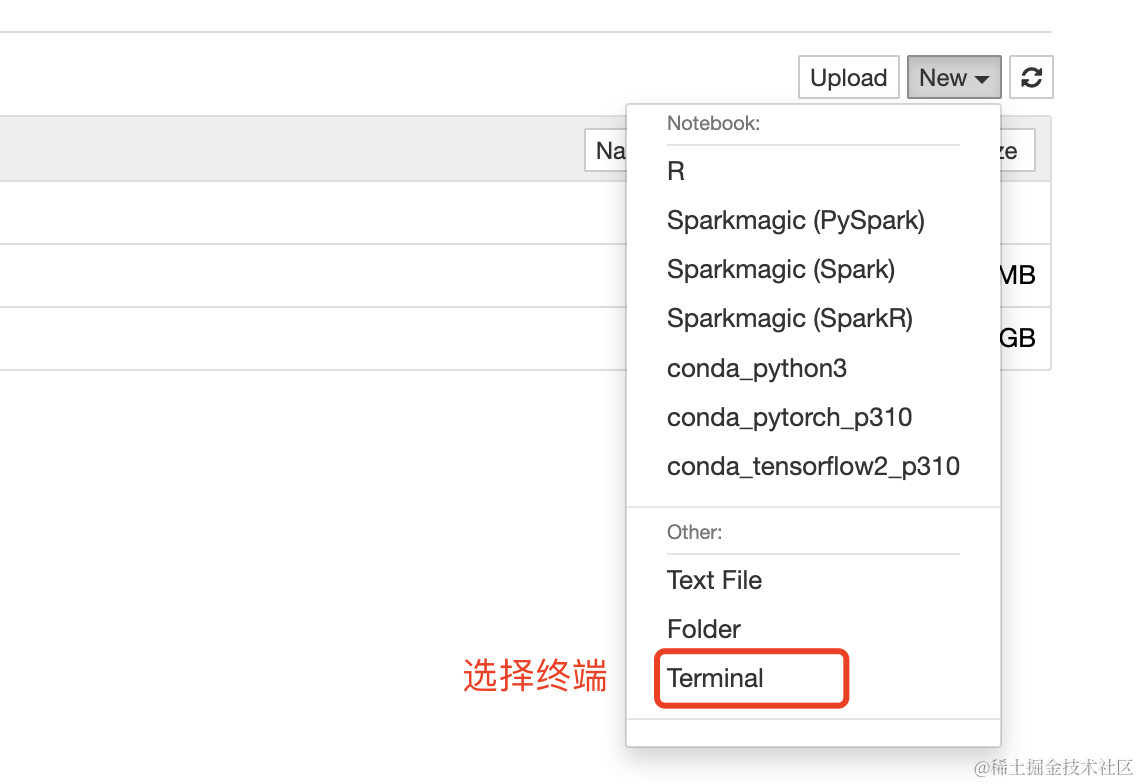
然后在终端中输入下面命令,下载数据集并解压。或者直接拿https链接在浏览器中下载后上传。
wget https://static.us-east-1.prod.workshops.aws/public/648e1f0c-f5e0-40eb-87b1-7f3638dba539/static/code/notebook-stable-diffusion.ipynb
此时实验代码已经下载完成,然后点击打开文件。

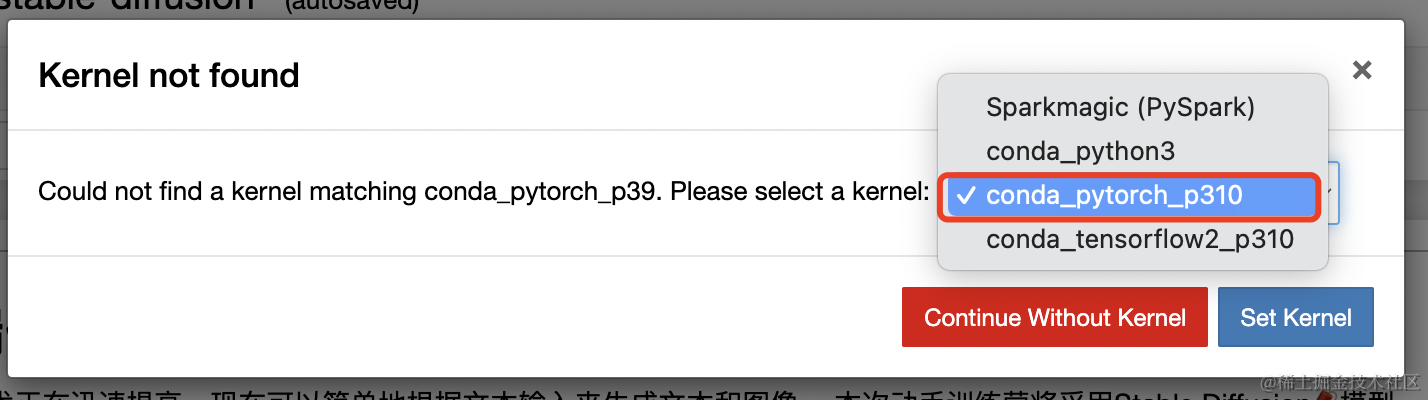
打开文件会有下面提示,选择conda_pytorch_p310
notebook-stable-diffusion.ipynb
在使用模型生成时,通常会有以下步骤:
(1)设定模型版本的环境变量
#Clone the Stable Diffusion model from HuggingFace
?
Stable Diffusion V1
SD_SPACE="runwayml/"
SD_MODEL = "stable-diffusion-v1-5"
SD_EXCLUDE_MODEL="!v1-5-pruned.ckpt"
?
Stable Diffusion V2
SD_SPACE="stabilityai/"
SD_MODEL = "stable-diffusion-2-1"
SD_EXCLUDE_MODEL="!v2-1_768-nonema-pruned.ckpt"
(2)在Notebook中配置并使用模型
pytorch训练绘图部分代码,我们修改提示词,描述要生成的图片,比如我修改prompts为[ `` "A white cat sleeping in nature", `` "A Husky, wearing a mask, singing at a KTV" ``],意思是:一只白色猫,在大自然中睡觉。一只哈士奇,带着口罩,在KTV唱歌。
# move Model to the GPU
torch.cuda.empty_cache()
pipe = pipe.to("cuda")
?
V1 Max-H:512,Max-W:512
V2 Max-H:768,Max-W:768
?
print(datetime.datetime.now())
prompts =[
? ?"A white cat sleeping in nature",
? ?"A Husky, wearing a mask, singing at a KTV"
]
generated_images = pipe(
? ?prompt=prompts,
? ?height=512,
? ?width=512,
? ?num_images_per_prompt=1
).images ?# image here is in [PIL format](https://pillow.readthedocs.io/en/stable/)
?
print(f"Prompts: {prompts}\n")
print(datetime.datetime.now())
?
for image in generated_images:
? display(image)
为模型设定输入参数,可使用的部分参数如下:
- prompt (str or List[str]): 引导图像生成的文本提示或文本列表
- height (int, optional, 默认为 V1模型可支持到512像素,V2模型可支持到768像素): 生成图像的高度(以像素为单位)
- width (int, optional, 默认为 V1模型可支持到512像素,V2模型可支持到768像素): 生成图像的宽度(以像素为单位)
- num_inference_steps (int, optional, defaults to 50): 降噪步数。更多的去噪步骤通常会以较慢的推理为代价获得更高质量的图像
- guidance_scale (float, optional, defaults to 7.5): 较高的指导比例会导致图像与提示密切相关,但会牺牲图像质量。 如果指定,它必须是一个浮点数。 guidance_scale<=1 被忽略。
- negative_prompt (str or List[str], optional): 不引导图像生成的文本或文本列表。不使用时忽略,必须与prompt类型一致(如果 guidance_scale 小于 1 则忽略)
- num_images_per_prompt (int, optional, defaults to 1): 每个提示生成的图像数量
(3)编写初始化的Sagemaker代码用于部署推理终端节点
使用 SageMaker 托管服务部署模型有多种选择。 你可以使用 亚马逊云科技开发工具包(例如,Python 开发工具包 (Boto3))、SageMaker Python 开发工具包、 亚马逊云科技 CLI 以编程方式部署模型, 或者您可以使用 SageMaker 控制台以交互方式部署模型。并且SageMaker Inference允许多个模型部署到同一个实例。
使用 SageMaker 托管服务部署模型是一个三步过程(如果您使用的是适用于 Python (Boto3)、 亚马逊云科技 CLI 或 SageMaker 控制台的 亚马逊云科技开发工具包):
1、在 SageMaker 中创建 SageMaker 模型。
2、为 HTTPS 端点创建端点配置。
3、创建 HTTPS 端点。
使用 SageMaker Python 开发工具包部署模型不需要您创建终端节点配置。 因此,这是一个两步过程:
1、从创建模型对象 Model可以部署到 HTTPS 端点的类。
2、使用模型对象的预构建创建 HTTPS 端点 deploy()方法。
编写初始化的Sagemaker代码用于部署推理终端节点,具体代码如下:
import sagemaker
import boto3
sess = sagemaker.Session()
sagemaker session bucket -> used for uploading data, models and logs
sagemaker will automatically create this bucket if it not exists
sagemaker_session_bucket=None
?
if sagemaker_session_bucket is None and sess is not None:
? ?# set to default bucket if a bucket name is not given
? sagemaker_session_bucket = sess.default_bucket()
?
try:
? role = sagemaker.get_execution_role()
except ValueError:
? iam = boto3.client('iam')
? role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']
?
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
?
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
(4)基于推理终端节点生成自定义图片
from PIL import Image
from io import BytesIO
import base64
?
helper decoder
def decode_base64_image(image_string):
? base64_image = base64.b64decode(image_string)
? buffer = BytesIO(base64_image)
? return Image.open(buffer)
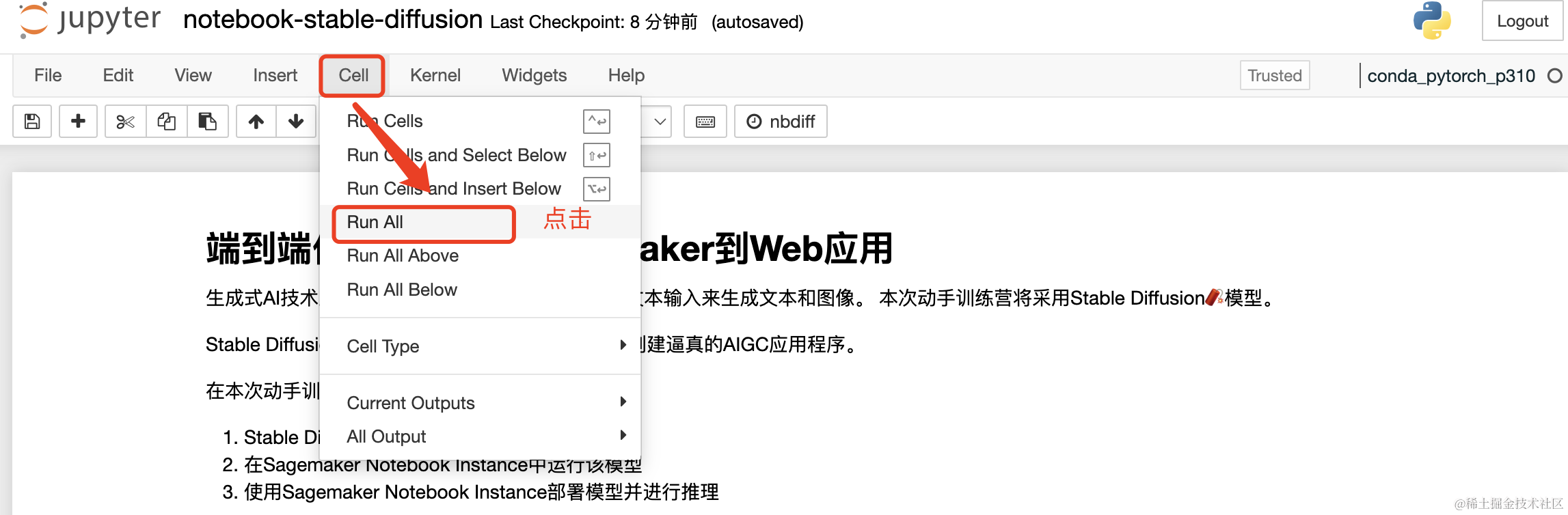
(5)Run
之后点击Cell中的Run All去执行代码。
最终生成下图,爱了爱了。


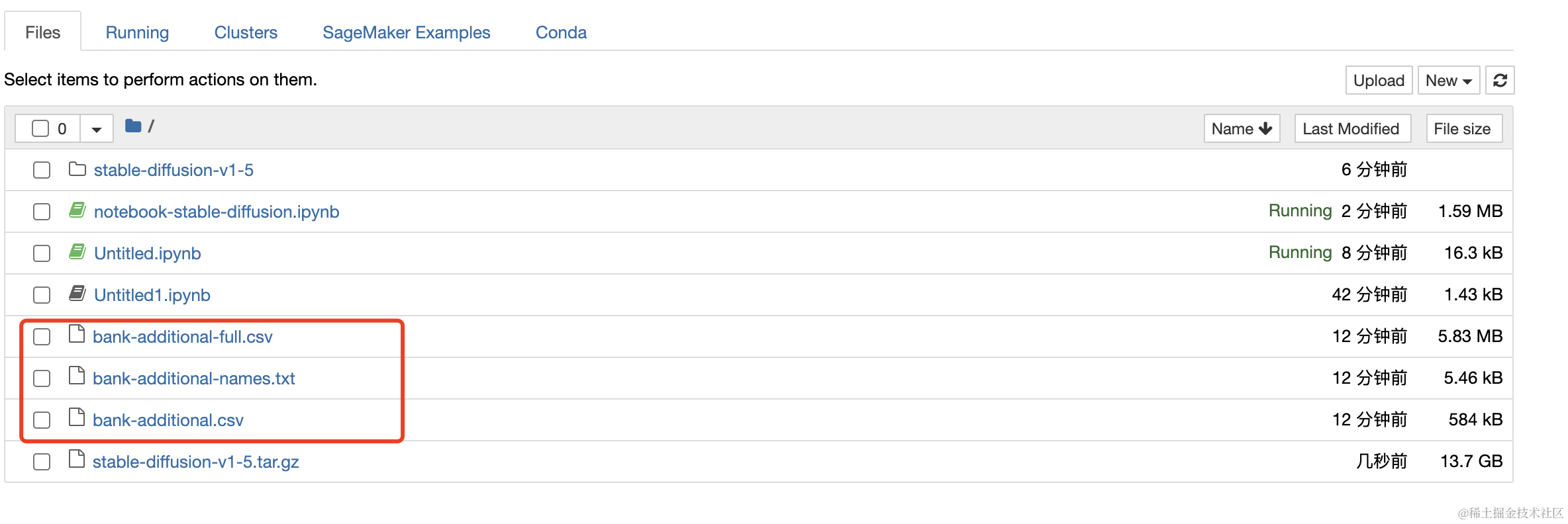
3、下载数据集
浏览器打开下载下面资源,然后上传到Jupyter中的Files。
https://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank-additional.zip
上传完成如下图所示:
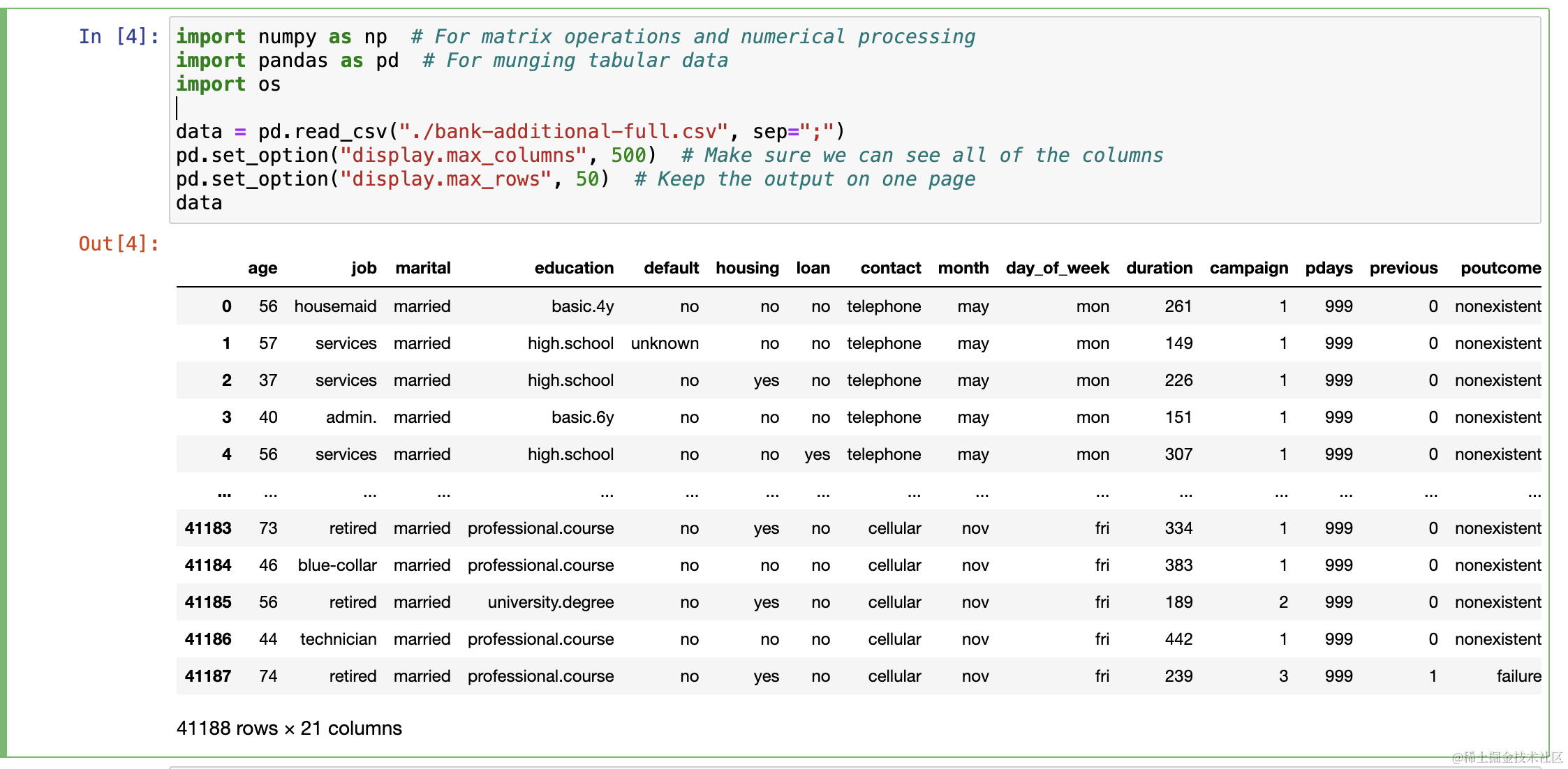
接下来通过pandas展示数据集。使用 bank-additional-full.csv 数据集文件,将其通过 pandas 读入并展示。点击NEW中的conda_pytorch_p310,然后输入下面代码。
import numpy as np ?# For matrix operations and numerical processing
import pandas as pd ?# For munging tabular data
import os
?
data = pd.read_csv("./bank-additional-full.csv", sep=";")
pd.set_option("display.max_columns", 500) ?# Make sure we can see all of the columns
pd.set_option("display.max_rows", 50) ?# Keep the output on one page
data
结果如下:
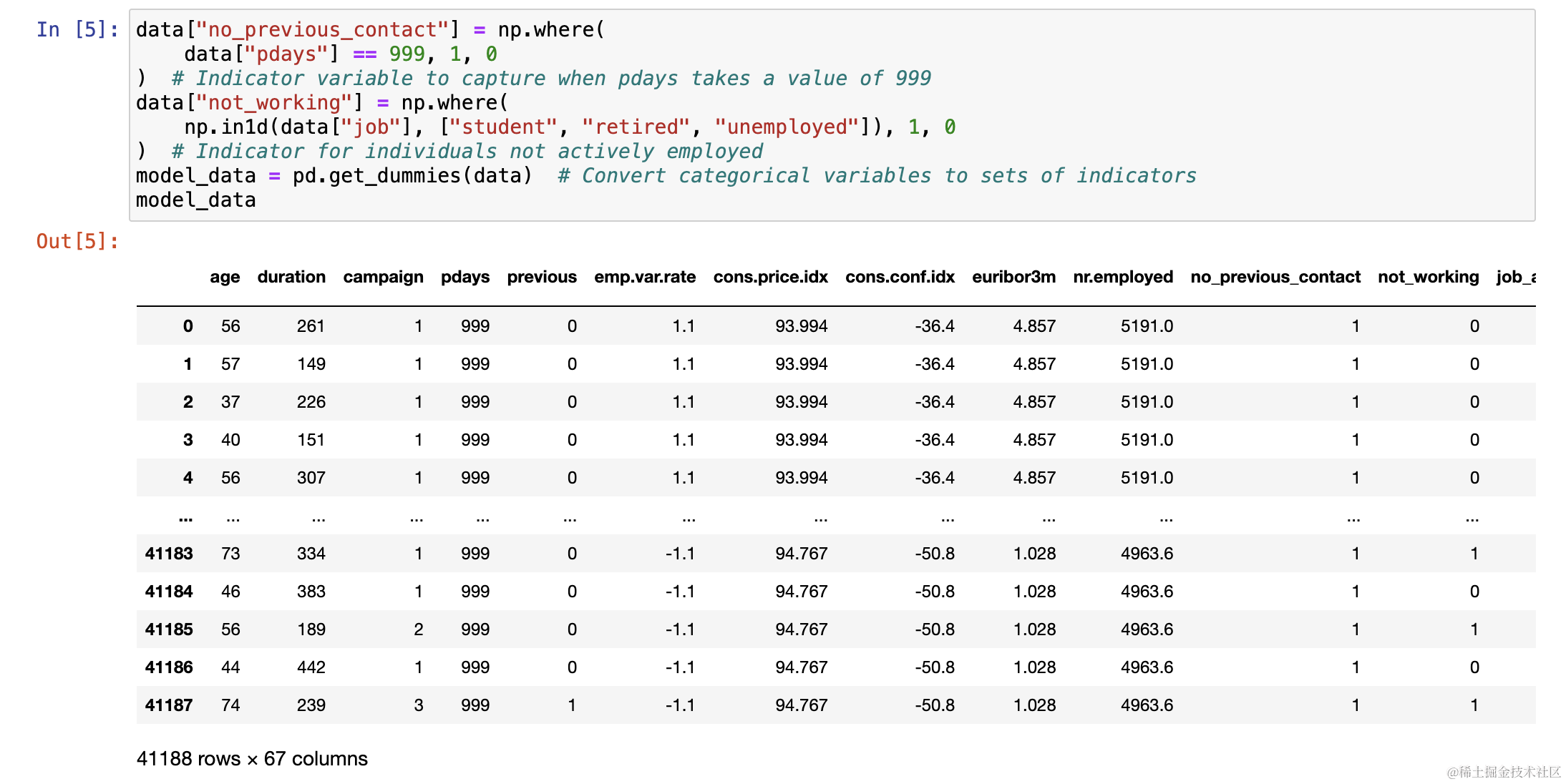
4、数据预处理
将数据集进行数据清洗,将分类类型数据通过独热编码转换为数字。
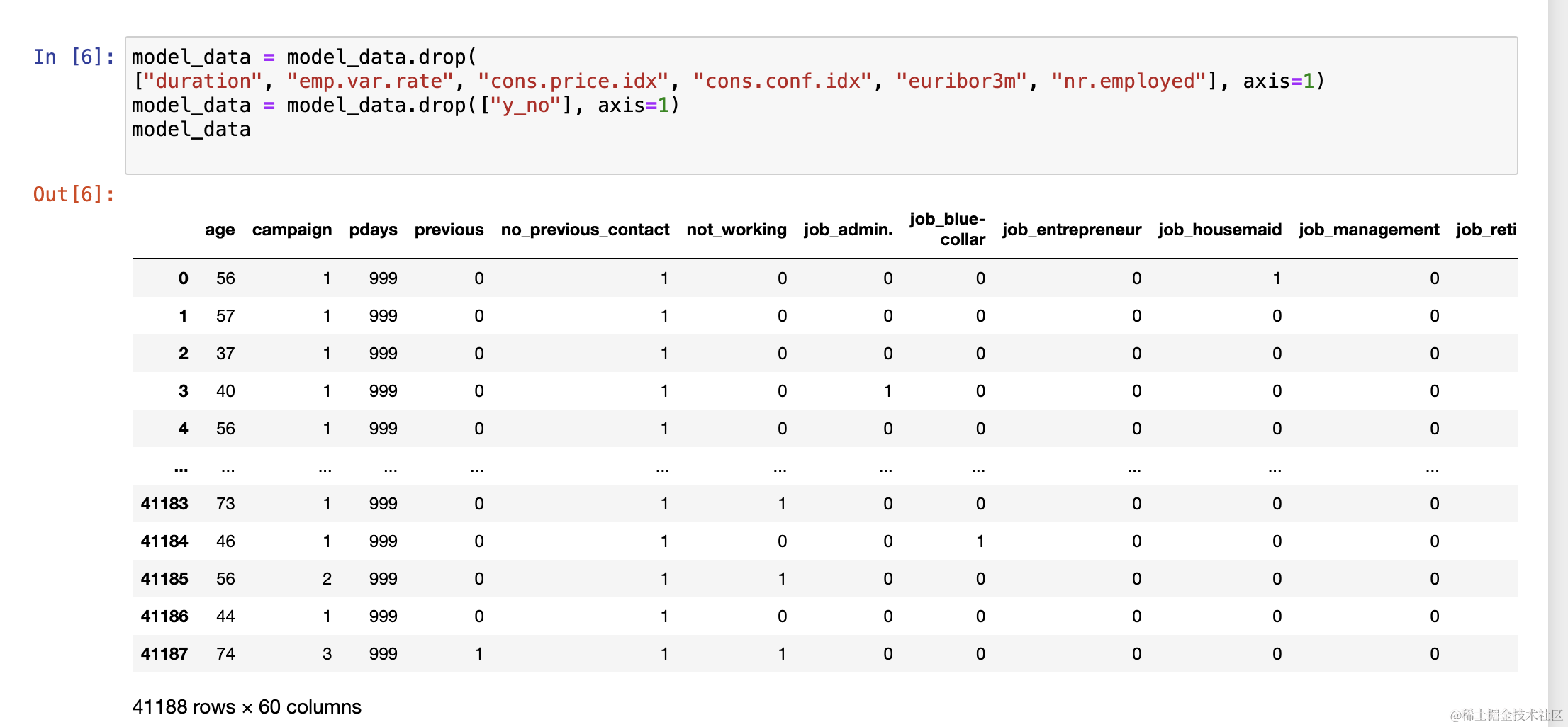
通过 drop 方法删除不需要的列,简化模型的输入数据。
model_data = model_data.drop(
["duration", "emp.var.rate", "cons.price.idx", "cons.conf.idx", "euribor3m", "nr.employed"], axis=1)
model_data = model_data.drop(["y_no"], axis=1)
model_data
SageMaker HyperPod
SageMaker HyperPod 通过为大规模分布式训练提供专门构建的基础设施,有助于减少训练基础模型 (FM) 的时间。 他还能够主动监控集群运行状况,并通过替换故障节点并从检查点恢复模型训练来提供自动化节点和作业弹性。
在SageMaker控制台中的左侧菜单中选择HyperPod 集群下的集群管理,点击右侧的创建集群按钮
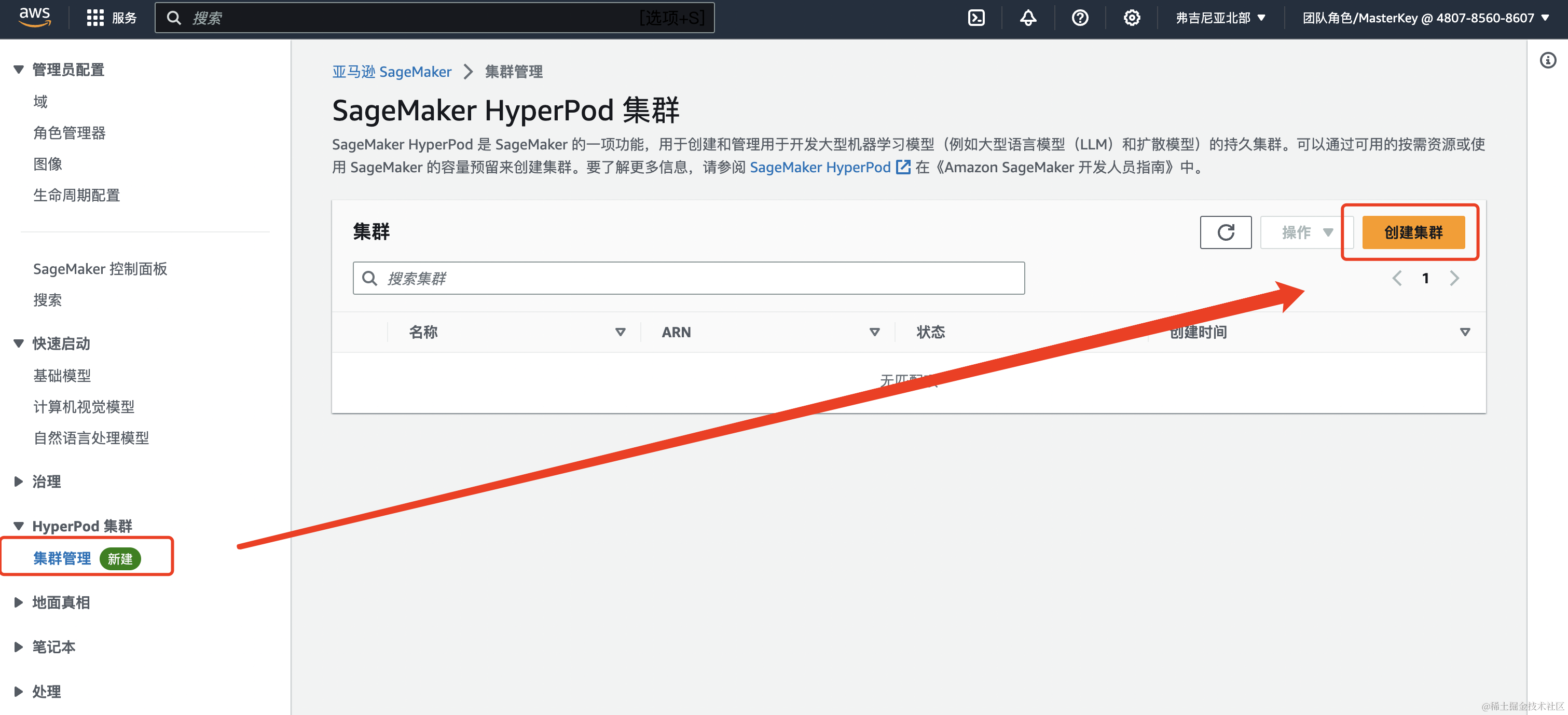
输入集群名称,然后下一步
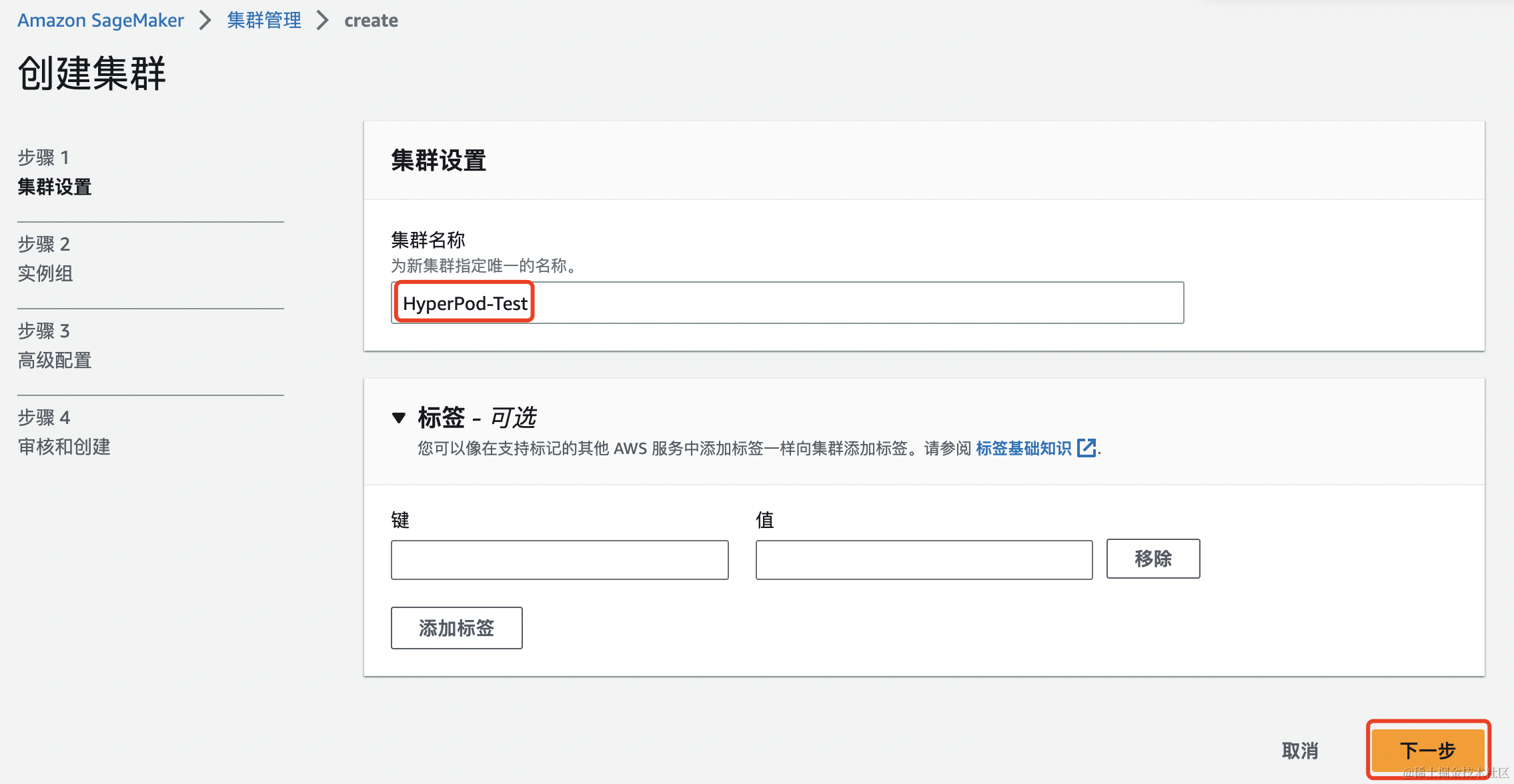
点击创建实例组
创建实例需要填写下面的基本信息,另外准备一个或多个生命周期脚本并将其上传到Amazon Simple Storage Service (Amazon S3)存储桶,以便在集群创建期间在每个实例组中运行。
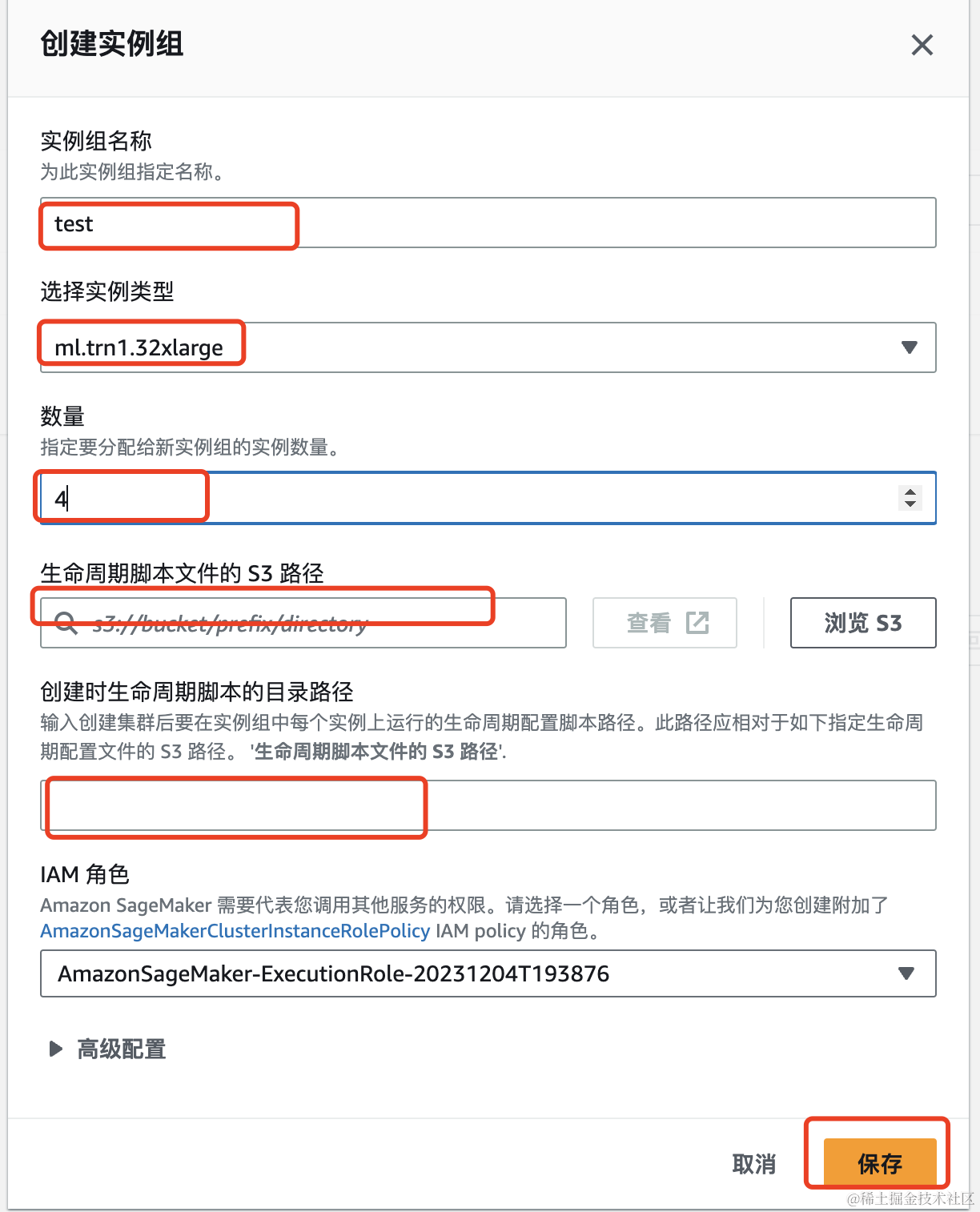
使用亚马逊云科技 CLI 创建和管理集群,选择 JSON 文件中指定集群配置。这里选择创建两个实例组,一个用于集群控制器节点,另一个用于集群工作节点。下面的例子中,在demo-cluster.json文件中创建了controller-group以及worker-group两个实例。
// demo-cluster.json
[
? {
? ? ? ?"InstanceGroupName": "controller-group",
? ? ? ?"InstanceType": "ml.m5.xlarge",
? ? ? ?"InstanceCount": 1,
? ? ? ?"LifeCycleConfig": {
? ? ? ? ? ?"SourceS3Uri": "s3://<your-s3-bucket>/<lifecycle-script-directory>/",
? ? ? ? ? ?"OnCreate": "on_create.sh"
? ? ? ? ? },
? ? ? ?"ExecutionRole": "arn:aws:iam::111122223333:role/my-role-for-cluster",
? ? ? ?"ThreadsPerCore": 1
? },
? {
? ? ? ?"InstanceGroupName": "worker-group",
? ? ? ?"InstanceType": "ml.trn1.32xlarge",
? ? ? ?"InstanceCount": 4,
? ? ? ?"LifeCycleConfig": {
? ? ? ? ? ?"SourceS3Uri": "s3://<your-s3-bucket>/<lifecycle-script-directory>/",
? ? ? ? ? ?"OnCreate": "on_create.sh"
? ? ? ? ? },
? ? ? ?"ExecutionRole": "arn:aws:iam::111122223333:role/my-role-for-cluster",
? ? ? ?"ThreadsPerCore": 1
? }
]
接下来就开始创建集群
aws sagemaker create-cluster \
? ?--cluster-name antje-demo-cluster \
? ?--instance-groups file://demo-cluster.json
创建之后,可以使用aws sagemaker describe-cluster和aws sagemaker list-cluster-nodes查看集群和节点详细信息。记下控制器节点的集群 ID 和实例 ID,需要这些信息才能连接到集群。接下来就可以设置集群环境,准备模型、分词器和数据集,然后在集群上启动作业。
SageMaker Canvas
Amazon SageMaker Canvas 无代码界面,可以访问现成的 FM 和预测模型或创建自定义模型,只需几分钟就可以从成千上万的文档、图像和文本行中提取信息并生成预测。这些即用型模型包括情绪分析、语言检测、实体提取、个人信息检测、图像中的对象和文本检测、发票和收据的费用分析、身份证件分析以及更通用的文档和表单分析。要开始使用现成的模型,只需选择模型、上传数据,然后单击即可生成模型输出,具体使用如下:
在Amazon SageMaker控制台中选择域,然后点击右侧创建域。
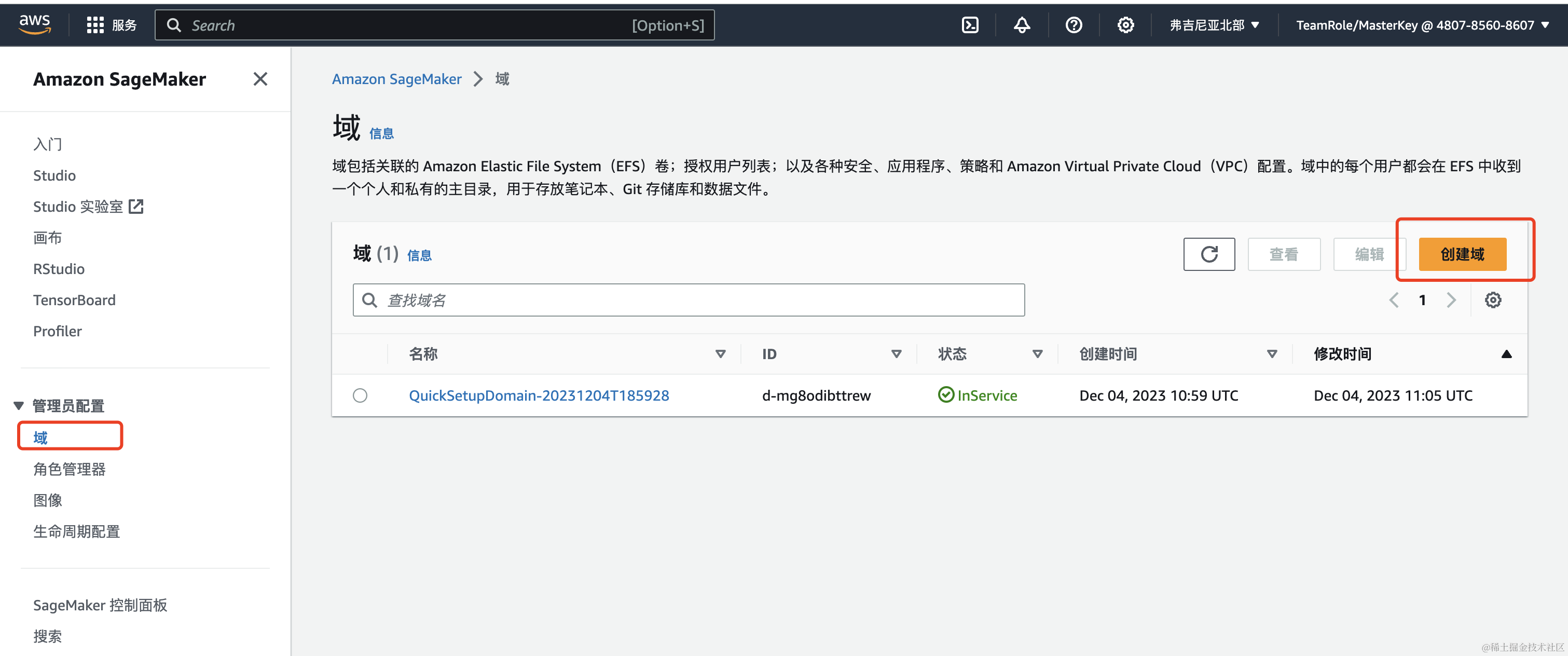
点击创建之后,第一次设置需要等待5-8分钟。
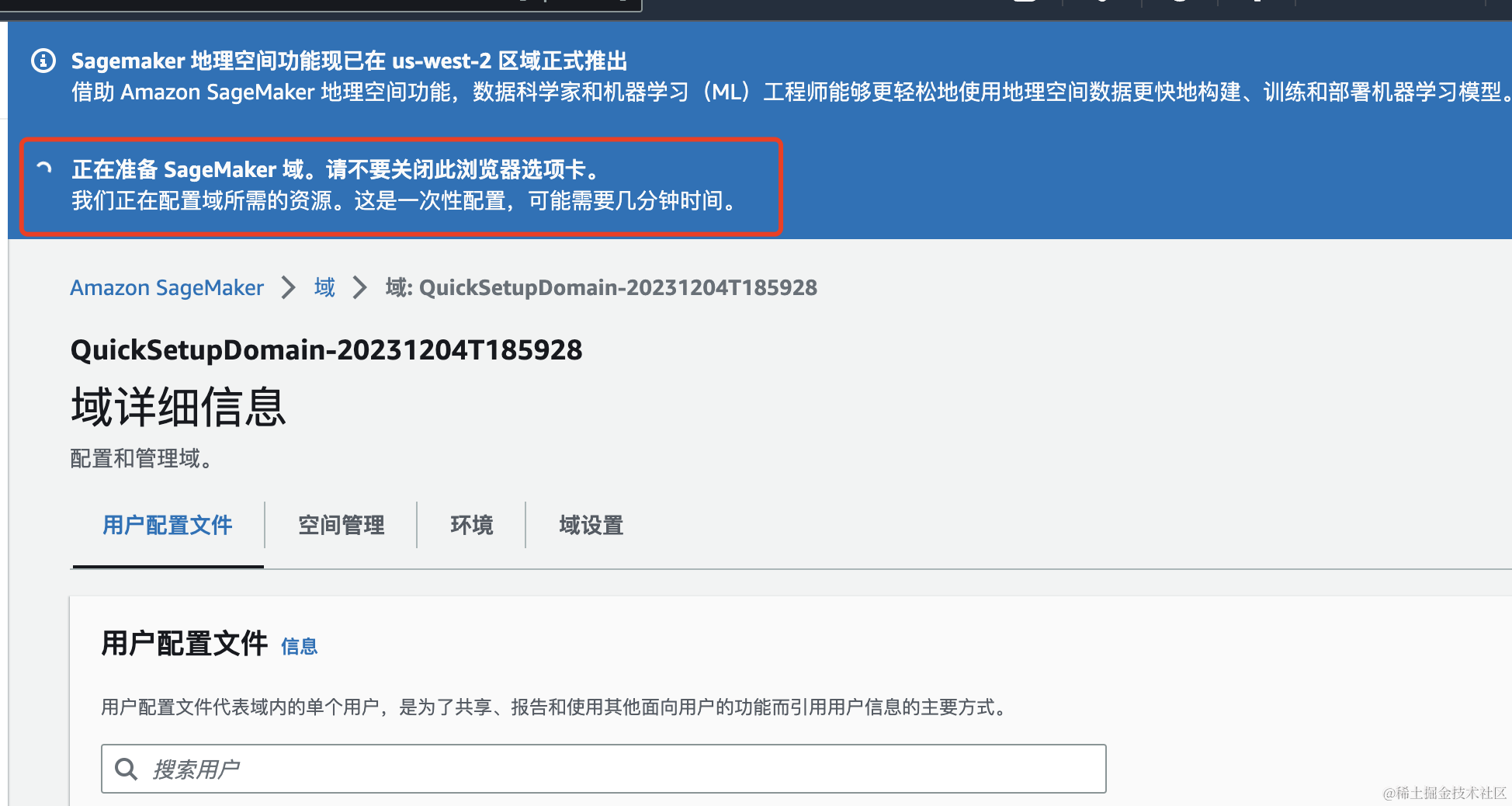
域创建完成,会有下面的提示:SageMaker域已准备就绪。

域创建完成之后,点击名称
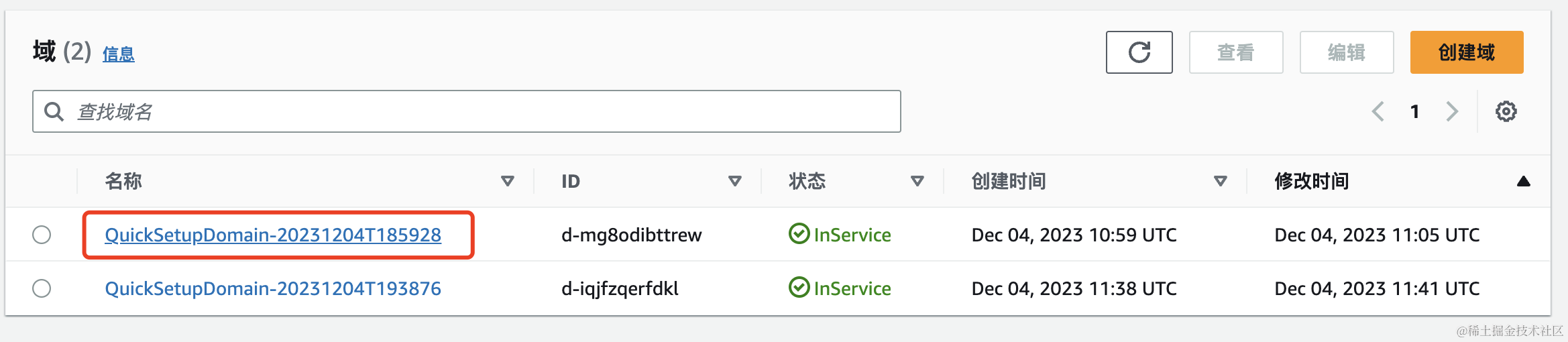
接下来点击启动按钮中Canvas按钮,到 Amazon SageMaker Canvas 页面。
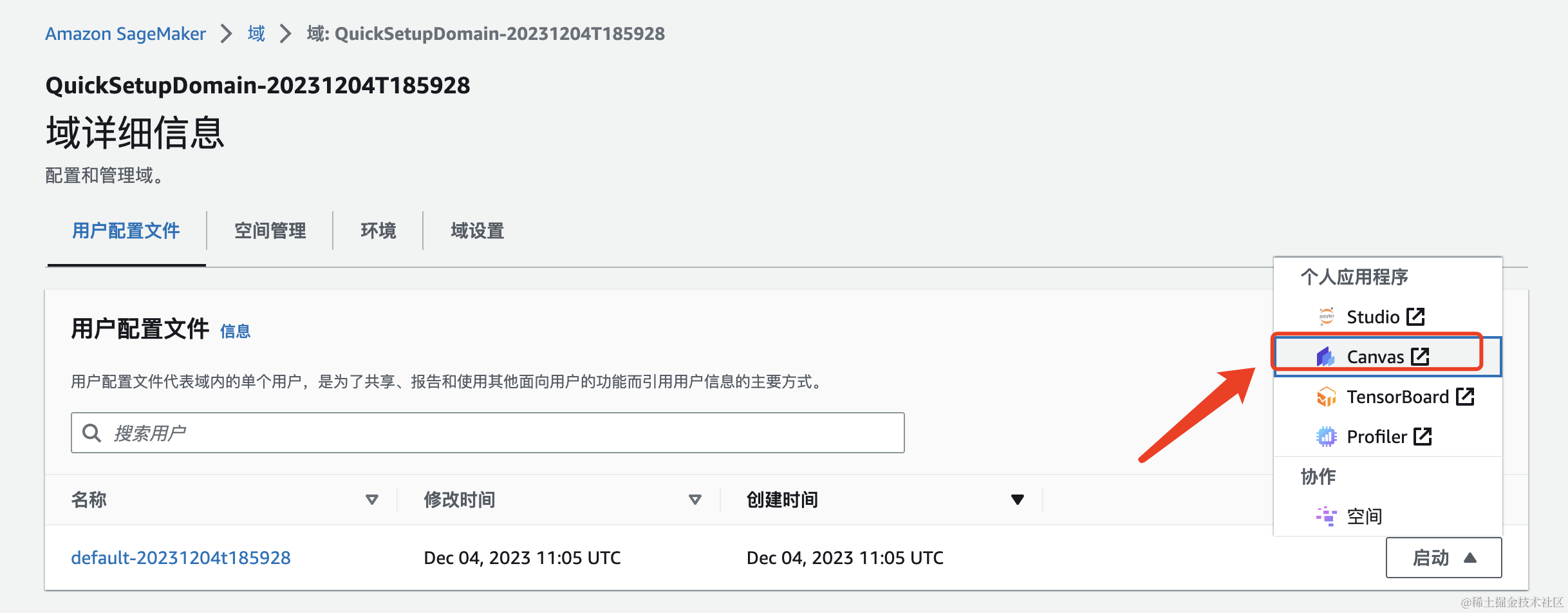
第一次进入加载时间比较慢,需要等5-8分钟。

进去之后主页如下图所示。
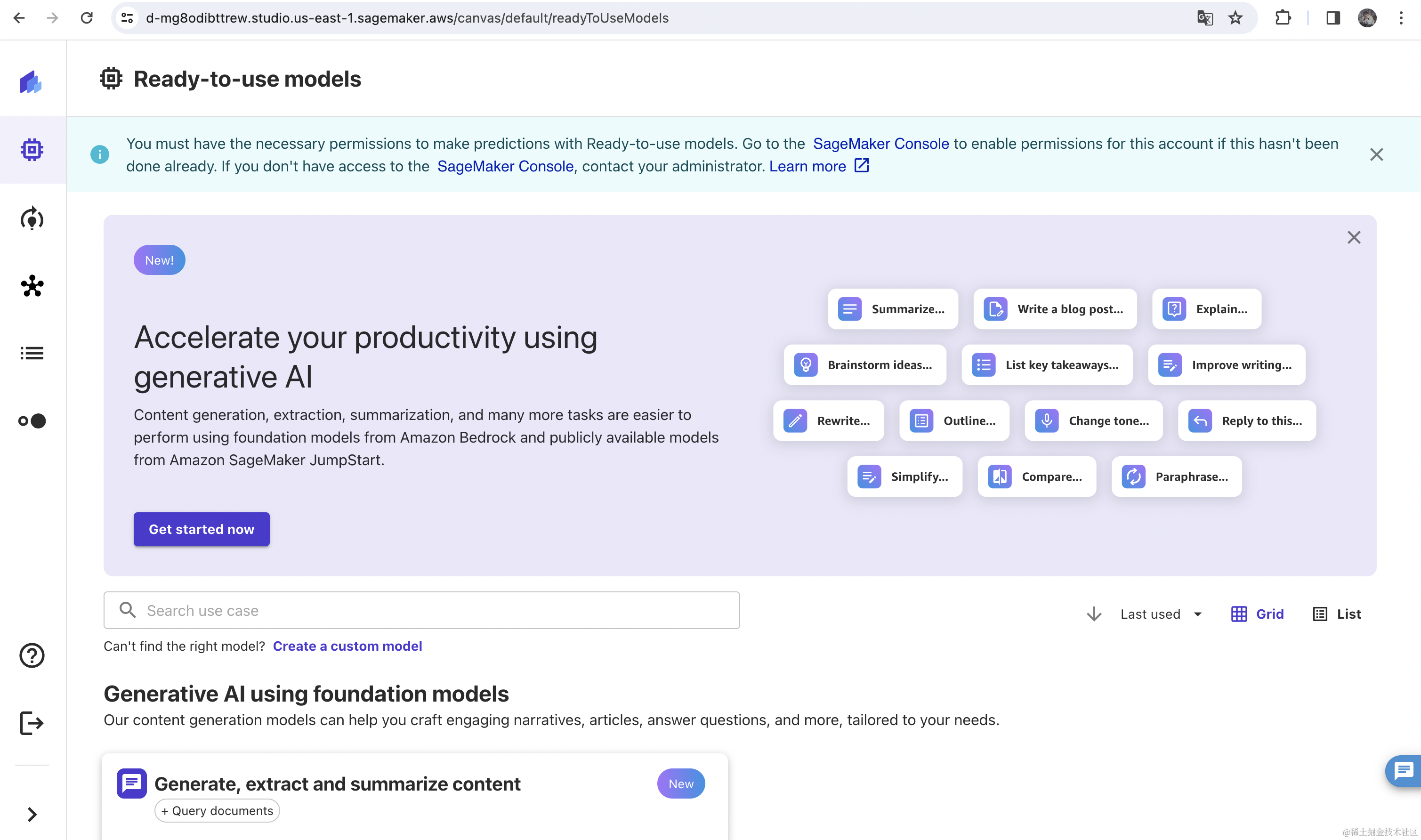
接下来,我们来体验下图像中的文本检测功能。选择左侧第二个菜单之后。选择Text detection in images(图像中的文本检测)
点击Upload Image进行上传图片
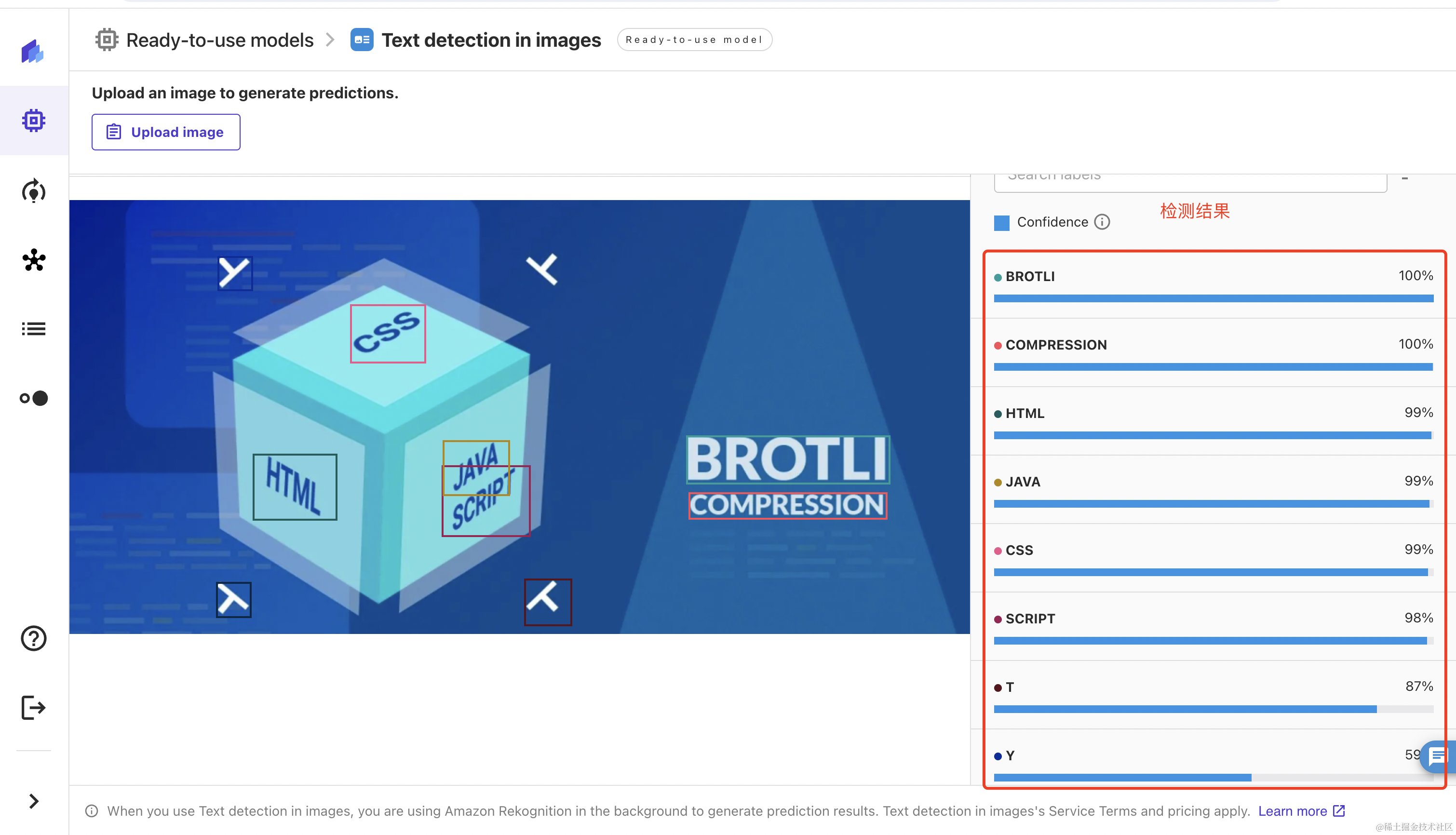
上传之后,对图片中的文本进行检测,检测结果如下所示(该功能对中文支持做的特别好,主要识别英文)。
Amazon SageMaker Canvas还有其他许多功能,你可以亲自尝试一下。官网:https://aws.amazon.com/cn/sagemaker/canvas/
总结
Amazon SageMaker的功能创新让我深切感受到机器学习这条道路越来越顺畅,案例构建、训练以及部署ML模型更加便利,并且在性能上有很大的提升,速度越来越快。从创建notebook实例到推理终端节点生成自定义图片,之后又下载数据集并对数据进行处理,这个过程让我真切体会到了Inference部署扩展能力,又详细探讨了HyperPod、Clarify、Canvas等功能,让我感受良多。
1、在使用SageMaker进行自定义图片生成以及数据处理过程中,速度非常快,并且允许多个模型部署到同一个实例,非常nice
2、分布式训练的模式能在很大程度上减少模型训练时间,并且在过程中可以监控集群的状态,为模型训练稳定进行保驾护航
3、不用怕模型训练存在偏差,Clarify提供了多种方式以及在不同时间对数据进行检测,保证了训练结果准确性。
4、如果用户不知道如何选择哪个模型,它还能根据用户选择的参数评估、比较,帮助用户适合其特定用例的最佳模型,以支持组织负责任地使用AI。
5、Canvas功能非常多,尤其是无代码的可视化操作,对新手非常友好,大大减少机器学习成本。并且提供了各种常见的模型应用,方便我们上手操作,直接使用模型来进行预测,提取数据。
6、SageMaker提供的这些扩展功能对用户来说非常友好,更重要是对模型训练的整体性能有很多提升,灵活度也更大,不仅可以自己去进行模型训练,还能直接拿现成的应用操作。
总而言之,SageMaker应用案例十分广泛,并且能够实现任何用途的高性能、低成本机器学习,用户也能够更轻松地构建、训练和部署生成人工智能模型,机器学习优势十分显著,推荐大家也快来体验一波。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 面向对象设计与分析40讲(27)奇异递归模板确实奇异
- 1.5矩阵元素的引用
- 华为云Astro,让业务专家秒变“技术大拿”
- 香港web3盛会:Unisat确认参加Big Demo Day项目路演
- C++随机数生成:std标准库和Qt自带方法(未完待续)
- qt+day4
- python虚拟环境系列(四):pycharm中创建项目时直接创建虚拟环境
- 不再悲观,投行发表2024年股市展望
- 域内定位个人PC的三种方式(3)
- 交叉验证理解