强化学习(二)多臂老虎机 “Multi-armed Bandits”——2
1、增量算法估计动作价值
由之前的内容可知,某一个动作被选择
n
?
1
n-1
n?1 次后,该动作的价值估计值为
Q
n
?
R
1
+
R
2
+
?
+
R
n
?
1
n
?
1
Q_n\doteq\dfrac{R_1+R_2+\cdots+R_{n-1}}{n-1}
Qn??n?1R1?+R2?+?+Rn?1??
很明显,随着时间的推移,内存和计算的需求逐渐增长,为此设计增量算法,已知
Q
n
Q_n
Qn? 和第
n
n
n 次的奖励
R
n
R_n
Rn?,则这
n
n
n 次奖励的新平均值计算如下:
Q
n
+
1
=
1
n
∑
i
=
1
n
R
i
=
1
n
(
R
n
+
∑
i
=
1
n
?
1
R
i
)
=
1
n
(
R
n
+
(
n
?
1
)
1
n
?
1
∑
i
=
1
n
?
1
R
i
)
=
1
n
(
R
n
+
(
n
?
1
)
Q
n
)
=
1
n
(
R
n
+
n
Q
n
?
Q
n
)
=
Q
n
+
1
n
[
R
n
?
Q
n
]
\begin{aligned} Q_{n+1}&=\dfrac{1}{n}\sum_{i=1}^nR_i\\[3ex] &=\dfrac{1}{n}\Big(R_n+\sum_{i=1}^{n-1}R_i\Big)\\[3ex] &=\dfrac{1}{n}\Big(R_n+(n-1)\dfrac{1}{n-1}\sum_{i=1}^{n-1}R_i\Big)\\[3ex] &=\dfrac{1}{n}\Big(R_n+(n-1)Q_n\Big)\\[3ex] &=\dfrac{1}{n}\Big(R_n+nQ_n-Q_n\Big)\\[3ex] &=Q_n+\dfrac{1}{n}\Big[R_n-Q_n\Big] \end{aligned}
Qn+1??=n1?i=1∑n?Ri?=n1?(Rn?+i=1∑n?1?Ri?)=n1?(Rn?+(n?1)n?11?i=1∑n?1?Ri?)=n1?(Rn?+(n?1)Qn?)=n1?(Rn?+nQn??Qn?)=Qn?+n1?[Rn??Qn?]?
这种方法只需要
Q
n
Q_n
Qn? 和
n
n
n 的内存,且每次只需要很小的计算量。这是一种后面会经常出现的形式,其一般表示为:
N
e
w
E
s
t
i
m
a
t
e
←
O
l
d
E
s
t
i
m
a
t
e
+
S
t
e
p
S
i
z
e
[
T
a
r
g
e
t
?
O
l
d
E
s
t
i
m
a
t
e
]
NewEstimate\leftarrow OldEstimate+StepSize\Big[Target-OldEstimate\Big]
NewEstimate←OldEstimate+StepSize[Target?OldEstimate]
其中 [ T a r g e t ? O l d E s t i m a t e ] \Big[Target-OldEstimate\Big] [Target?OldEstimate] 是估计的误差,它通过向“目标”靠近来降低。在增量算法中使用的步长参数( S t e p S i z e StepSize StepSize)随时间而变化,该方法用的是 1 n \dfrac{1}{n} n1?,后续我们一般用 α \alpha α 或 α t ( a ) \alpha_t(a) αt?(a) 来表示步长参数。
下面展示使用增量算法计算样本平均值以及
?
?
\epsilon-
?? 贪心算法的伪代码

2、奖励随时间变化问题
目前未知,我们讨论的方法都是基于奖励不随时间变化的问题,而对于奖励随时间变化的情况下,我们一般侧重于近期奖励,即给予近期奖励比以往奖励更多的权重。最常用的方法之一就是用定步长参数,
Q
n
+
1
?
Q
n
+
α
[
R
n
?
Q
n
]
Q_{n+1}\doteq Q_n+\alpha\Big[R_n-Q_n\Big]
Qn+1??Qn?+α[Rn??Qn?]
其中步长参数
α
∈
(
0
,
1
]
\alpha\in(0,1]
α∈(0,1] 为常数,这就导致
Q
n
+
1
Q_{n+1}
Qn+1? 是过去奖励与初始估计
Q
1
Q_1
Q1?的加权平均值
Q
n
+
1
=
Q
n
+
α
[
R
n
?
Q
n
]
=
α
R
n
+
(
1
?
α
)
Q
n
=
α
R
n
+
(
1
?
α
)
[
α
R
n
?
1
+
(
1
?
α
)
Q
n
?
1
]
=
α
R
n
+
(
1
?
α
)
α
R
n
?
1
+
(
1
?
α
)
2
Q
n
?
1
=
(
1
?
α
)
n
Q
1
+
∑
i
=
1
n
α
(
1
?
α
)
n
?
i
R
i
\begin{aligned} Q_{n+1}&=Q_n+\alpha\Big[R_n-Q_n\Big]\\[2ex] &=\alpha R_n + (1-\alpha)Q_n\\[2ex] &=\alpha R_n + (1-\alpha)[\alpha R_{n-1}+(1-\alpha)Q_{n-1}]\\[2ex] &=\alpha R_n + (1-\alpha)\alpha R_{n-1}+(1-\alpha)^2Q_{n-1}\\[2ex] &=(1-\alpha)^nQ_1 + \sum_{i=1}^n\alpha(1-\alpha)^{n-i}R_i \end{aligned}
Qn+1??=Qn?+α[Rn??Qn?]=αRn?+(1?α)Qn?=αRn?+(1?α)[αRn?1?+(1?α)Qn?1?]=αRn?+(1?α)αRn?1?+(1?α)2Qn?1?=(1?α)nQ1?+i=1∑n?α(1?α)n?iRi??
为什么称其为加权平均,因为权重之和 ( 1 ? α ) n + ∑ i = 1 n α ( 1 ? α ) n ? i = 1 (1-\alpha)^n+ \sum_{i=1}^n\alpha(1-\alpha)^{n-i} =1 (1?α)n+∑i=1n?α(1?α)n?i=1。另外可以看出, R i R_i Ri? 的权重随着奖励数量的增加而减小,因此我们也称为指数近期加权平均(exponential recency-weighted average)。
接下来我们讨论一下变步长参数。设
α
n
(
a
)
\alpha_n(a)
αn?(a) 为第
n
n
n 次选择动作
a
a
a 时,用于处理所获奖励的步长参数。如前所述,
α
n
(
a
)
=
1
n
\alpha_n(a)=\dfrac{1}{n}
αn?(a)=n1?,该方法由大数定律可以保证动作价值的估计值收敛于其真实值。当然并不是所有的变步长都保证收敛,可以保证以概率 1 收敛的必要条件是:
∑
n
=
1
∞
α
n
(
a
)
=
∞
a
n
d
∑
n
=
1
∞
α
n
2
(
a
)
<
∞
\sum_{n=1}^\infty\alpha_n(a)=\infty\quad {and} \quad\sum_{n=1}^\infty\alpha^2_n(a)<\infty
n=1∑∞?αn?(a)=∞andn=1∑∞?αn2?(a)<∞
这两个收敛条件可以理解为:第一个条件要保证步长足够大,从而克服任何的初始条件或随机波动;第二个条件保证最终步长变小到足以保证收敛。由此可以看出,对于 α n ( a ) = 1 n \alpha_n(a)=\dfrac{1}{n} αn?(a)=n1? 满足两个收敛条件,而对于 α n ( a ) = α \alpha_n(a)=\alpha αn?(a)=α 不满足第二个收敛条件,这表明估计值一直不会完全收敛,而是继续变化以相应最近收到的奖励,这对于奖励随时间变化的情况是有利的,此外满足上述两个收敛条件的步长参数往往收敛速度很慢,因此实际中很少使用。
3、初始值
到目前为止,所有讨论的方法都在一定程度上依赖初始的动作价值估计 Q 1 ( a ) Q_1(a) Q1?(a),也就是说这些方法都会因为 Q 1 ( a ) Q_1(a) Q1?(a) 的取值而产生偏差。对于样本平均方法,一旦所有动作至少被选择一次,那么偏差就会消失,但是对于定步长参数的方法,偏差会随着时间的推移而减少但不会消失。这其实有好有坏,不利的一面是,初始值设定变成了一组必须用户进行挑选的参数;有利的一面是,这也提供了一种简单的方法,通过合理设置初始值从而加快收敛速度。
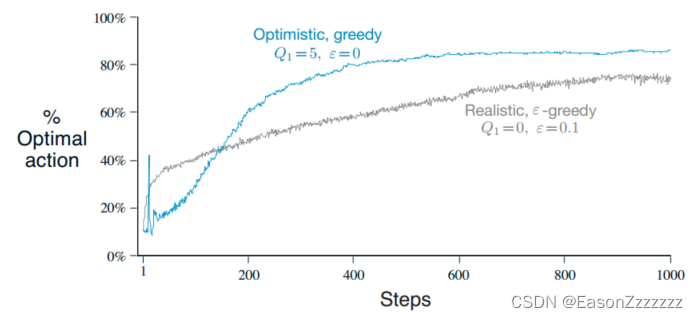
初始动作价值的设定也可以作为鼓励探索的简单方法,例如之前的多臂老虎机问题,其真实动作价值 q ? q_\ast q?? 服从期望为 0,方差为 1 的正态分布,若我们将初始动作价值估计设为 5,那么无论选择哪种动作,奖励都小于初始的动作价值估计,那么无论是完全的贪心方法还是 ? ? \epsilon- ?? 贪心方法,系统总是会进行相当数量的探索。
代码部分
import numpy as np
import matplotlib.pyplot as plt
# 初始值设定
step = 2000
alpha = 0.1
q_true = np.random.normal(0, 1, 10) # 真实的动作价值
optimal_true = np.argmax(q_true) # 最优动作
q_estimate1 = np.zeros(10) # 估计的动作价值
q_estimate2 = np.full(10, 5.1) # 估计的动作价值
epsilon1 = 0.9 # 贪心概率
epsilon2 = 0.9 # 贪心概率
optimal_count1 = 0
optimal_count2 = 0
optimal_probability1 = np.zeros(step)
optimal_probability2 = np.zeros(step)
action_space = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
for i in range(step):
if (np.random.uniform() > epsilon1) or (q_estimate1.all() == 0):
machine_name = np.random.choice(action_space)
if machine_name == optimal_true:
optimal_count1 += 1
optimal_probability1[i] = 100 * optimal_count1 / (i+1)
reward = np.random.normal(q_true[machine_name], 1, 1)
q_estimate1[machine_name] = q_estimate1[machine_name] + alpha * (reward - q_estimate1[machine_name])
else:
machine_name = np.argmax(q_estimate1)
if machine_name == optimal_true:
optimal_count1 += 1
optimal_probability1[i] = 100 * optimal_count1 / (i + 1)
reward = np.random.normal(q_true[machine_name], 1, 1)
q_estimate1[machine_name] = q_estimate1[machine_name] + alpha * (reward - q_estimate1[machine_name])
for i in range(step):
if (np.random.uniform() > epsilon1) or (q_estimate2.all() == 5):
machine_name = np.random.choice(action_space)
if machine_name == optimal_true:
optimal_count2 += 1
optimal_probability2[i] = 100 * optimal_count2 / (i+1)
reward = np.random.normal(q_true[machine_name], 1, 1)
q_estimate2[machine_name] = q_estimate2[machine_name] + alpha * (reward - q_estimate2[machine_name])
else:
machine_name = np.argmax(q_estimate2)
if machine_name == optimal_true:
optimal_count2 += 1
optimal_probability2[i] = 100 * optimal_count2 / (i + 1)
reward = np.random.normal(q_true[machine_name], 1, 1)
q_estimate2[machine_name] = q_estimate2[machine_name] + alpha * (reward - q_estimate2[machine_name])
plt.plot(optimal_probability1, label="Q1 = 0, e = 0.1")
plt.plot(optimal_probability2, label="Q1 = 5.1, e = 0.1")
plt.xlabel('Steps')
plt.ylabel('Optimal action')
plt.legend()
plt.show()
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- shell 数组的详细用法
- 2024.1.18
- SSM萌宠宠物用品商城设计与实现-附源码79718
- 修改opencv代码支持utf8文件名
- WebGL开发工程和建筑可视化应用
- 西门子智能分拣系统实现(博途17)
- 【科技前沿】数字孪生技术改革智慧供热,换热站3D可视化引领未来
- 实战使用工具appuploader上线发布苹果商店
- java中解码和编码出现乱码原因
- [RK-Linux] 移植Linux-5.10到RK3399(九)| 配置USB-A支持HOST功能