AlexNet论文精读
发布时间:2024年01月10日
1:该论文解决了什么问题?
图像分类问题
2:该论文的创新点?
- 使用了大的深的卷积神经网络进行图像分类;
- 采用了两块GPU进行分布式训练;
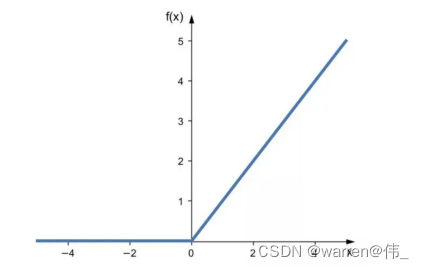
- 采用了Relu进行训练加速;
- 采用局部归一化提高模型泛化能力;
- 重叠池化,充分利用信息,提高精度;
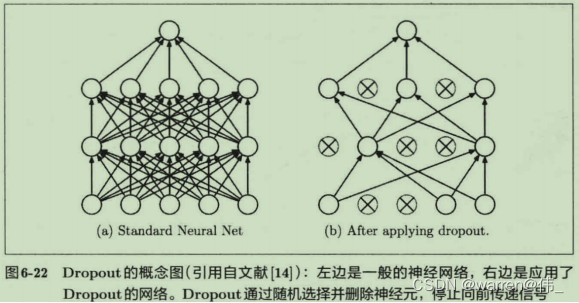
- dropout减少神经元之间的依赖性,提高模型泛化能力;
3:训练策略?
- 使用SGD(随机梯度下降)来训练,每个batch128,动量为0.9,权重衰减为0.0005(防止过拟合,在损失函数中添加一个惩罚项,对网络的权重进行约束,使其趋向于较小的值);
- 使用方差为0.1 均值为0的分布来初始化权重,用常数1来初始化第二、四、五层卷积和全连接隐藏层的偏置;
- 学习率初始化为0.1,当验证集的精度不再提高时,将学习率除以10;
4:代码地址?
无
5:论文还有什么改进之处?
1)对视频流进行处理,利用时间特征
摘要

1:训练了一个很大很深的卷积神经网络在ImageNet上进行1000个种类的分类任务;
2:top1的精度达到了62.5%;
3:该网络包含了五个卷积层以及全连接层;
4:采用了两块gpu进行分布式训练;
5:对于overfitting问题采用了dropout。
介绍


1:现实物体的识别需要较大的数据集,例如LabelMe 和ImagNet;
2:卷积网络可以通过深度和宽度来控制其识别能力;
3:编写了一个高性能程序让gpu可以很好的训练2D卷积;
4:经过实验,发现卷积网路的深度很重要;
数据集

1:ImageNet有1.5亿张高达22000个种类并且由人工进行标注的图片;
2)并没有对图像进行预处理,在原始的RGB上进行网络的训练。
结构

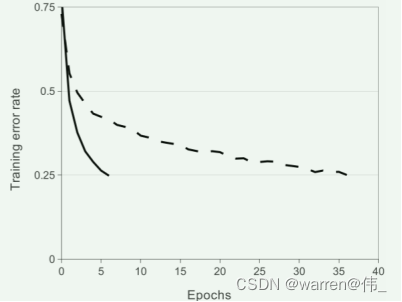
- relu可以大大减少神经网络的训练时间;
- 如图所示训练时间对比,实线为relu,虚线为tanh;

-

4)relu(x)=Max(0,x)



- 在当时,单块gpu的显存仅3GB,这无法训练一个大型的神经网络,因此采用了两块GPU进行分布式训练;
- 并行化方案采用的是讲一半的卷积核各放到一块gpu上,gpu仅在某些层进行交流,并且gpu之间可以先相互读取内存而不经过主机;
- 带来的结果就是降低了top1和top5的错误率,加快了训练。

- 虽然Relu不需要归一化来防止饱和,但依然发现了一种归一化方法来提高模型的泛华能力;(泛华:模型在未见过的数据集的能力)
- 仅在某些层使用Relu后使用该归一化,因此称为局部响应归一化,这一操作同样降低了top1和5的错误率;
 池化通常用来降低卷积层之后结果的维度;
池化通常用来降低卷积层之后结果的维度;- 不仅可以提升精度,还可以防止过拟合;
- 池化步长小于池化窗口,再池化的过程中添加相邻像素的信息以重新或得非重叠部分失去的特征;


 结构如图所示,包含了五个卷积和三个全连接;
结构如图所示,包含了五个卷积和三个全连接;
2)网络被分为两个部分,各自训练各自的;
3)第二个卷积层的输出进行了一个交叉,也就是第三个卷积层的输入,此时两个GPU互相交换参数;
4)第一个、第二个卷积层使用了LRN(局部归一化);
5)第一个、第二个、第五个卷积层使用了最大池化。



- 降低过拟合的方法之一就是人为的进行数据集扩充;
- 从256*256的图里随机提取224*224的块,这也是为什么结构里的输入为224*224;
- 对图片进行PCA(高维数据转换为低维数据,保留数据中的主要变化方向。在这里,PCA应用于RGB像素值,以找到它们之间的主要方向。)

- 为了减少误差,降低训练成本,采用了dropout(随机失活法);
2)在学习的过程中进行神经元的随机失活,以降低各个模块的依赖性,提高鲁棒性。



- 使用SGD(随机梯度下降)来训练,每个batch128,动量为0.9,权重衰减为0.0005(防止过拟合,在损失函数中添加一个惩罚项,对网络的权重进行约束,使其趋向于较小的值);
- 使用方差为0.1 均值为0的分布来初始化权重,用常数1来初始化第二、四、五层卷积和全连接隐藏层的偏置;
- 学习率初始化为0.1,当验证集的精度不再提高时,将学习率除以10;

- 卷积神经网络的精度和深度有关;
- 对于视频,希望用大的深度神经网络去预测并利用好时间结构。
文章来源:https://blog.csdn.net/warren103098/article/details/135511198
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 与Python的初识
- 【经典LeetCode算法题目专栏分类】【第7期】快慢指针与链表
- 基于Java的月子会所系统的设计和实现(源码+开题)
- 龙哥的问题(积性函数,莫比乌斯反演)
- 已解决Error:AttributeError: module ‘numpy‘ has no attribute ‘complex‘
- 机器学习笔记 - 基于Python的不平衡数据的欠采样技术
- 防止源代码泄露的10大措施
- 是时候将javax替换为Jakarta了
- Fastjson 常用语法
- 【大语言模型】Transformer原理以及运行机制