大模型训练折戟之路
看了很多大模型平台,基本上这些平台都开源了模型建立过程,训练和微调数据等整个过程和脚本在github上描述的也比较详细,很多AI人员也分享了很多模型训练过程。经过多次比较选择,感觉还是LLaMA还是比较好,称为羊驼,国内在这个模型基础上,增强了中文能力,考虑到租用GPU成本问题,采用7B模型。
在租用资源之前,首先在笔记本电脑上部署LLaMA.CPP,使用大模型部署成功,因为资源不足,又没有GPU,所以笔记本上只是证明大模型本地化部署是没有问题的。其次是在笔记本电脑上安装虚拟机,根据中文羊驼数据训练和微调过程,练习一遍,整个过程也是基本上能够走的通,但是在训练数据(执行run_pt.sh)这一步时,会报错,缺少GPU不行。所以第三步是租用GPU服务器,月租、小时租都有,看了我一直使用的vultr作为代理服务器的租用价格,没有小时租,只有月租,32G内存,1/16共享GPU的一个月要大概200美金,但是这些资源肯定不够,真正训练时,是无法使用7B模型的,7B模型要至少39G显存,45G的CPU,看了阿里云、京东、腾讯和RAKSmart,最后选择当前阿里16G内存、62G显存的GPU服务器,只是前面100小时每个小时1.6元左右。这个网址描述最清楚,https://github.com/ymcui/Chinese-LLaMA-Alpaca,按照这个流程操作。
首先安装Python、pip和torch,注意torch和Python之间也对应的版本,一定按照兼容的版本进行安装,否则后面会遇到很多麻烦。接着安装 PyTorch、sentencepiece、protobuf,这些都是开源软件,这些软件不同版本之间会有冲突,也是要注意安装时要指定版本号,如果安装最新版本也会出现问题。源码安装 transformers、peft。可以使用pip show torch查看torch版本,使用nvcc –version查看CUDA版本,LLaMA 模型不提供商用,我从网络网络上找到一个对应的版本,放在./models/original_llama?目录,上面参考的文档中consolidated.00.pth的MD5值是6efc8dab194ab59e49cd24be5574d85e,但是我从不同渠道下载两个版本,其MD5值都是0c4837f3ef97f648452f91faed308a07,找不到与上面完全相同的版本,我只能试试是否可以训练。后面证明也是可以的,不会报错。使用?transformers?提供的脚本?convert_llama_weights_to_hf.py,将原版 LLaMA 模型转换为 HuggingFace 格式,这些脚本在中文LLaMA2的官方网站上都能下载到。转换完成后,其文档结构如下:

词表扩充这一步是没有问题的,将原版 LLaMA 的词表与该项目的所提供的专门针对中文扩充的 20000 个 tokens 做合并,合并代码见:merge_tokenizers.py。执行合并后,可以看到下面页面:

生成两个文件夹merged_tokenizer_hf? merged_tokenizer_sp?
在做4.4第1步进行模型合并时,报错:
Base model: ./models/original_llama_hf_7b
LoRA model(s) ['./models/chinese_llama_plus_lora_7b']:
Loading ./models/chinese_llama_plus_lora_7b
Traceback (most recent call last):
File "/root/transformers/scripts/merge_llama_with_chinese_lora_low_mem.py", line 245, in <module>
lora_config = peft.LoraConfig.from_pretrained(lora_model_path)
File "/usr/local/lib/python3.9/site-packages/peft/config.py", line 137, in from_pretrained
config = config_cls(**kwargs)
TypeError: __init__() got an unexpected keyword argument 'enable_lora'
解决办法是adapter_config.json权重文件中enable_lora中,删除这一行
? "enable_lora": null,
执行再报错,这里又报错,再次删除下面这个参数。
? "merge_weights": false,
删除掉上面两个参数后, 模型合并成功。
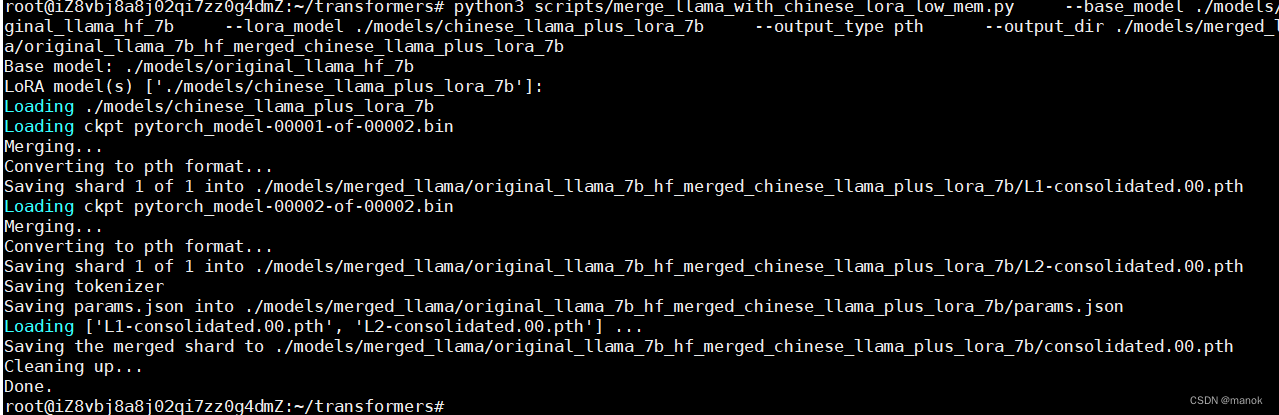
合并模型后的目录结构。

run_pt.sh中,训练数据存放路径,这个文件中data_cache是存放暂存训练数据时中间结果的目录,发现其它文件中应该是data_cache_dir,所以要进行修改。data_cache_dir=./data_cache
在文件的516行会报错,因为传入的cache_path有问题。关于处理数据可以参考上面连接中借助AI帮助产生Python脚本去处理。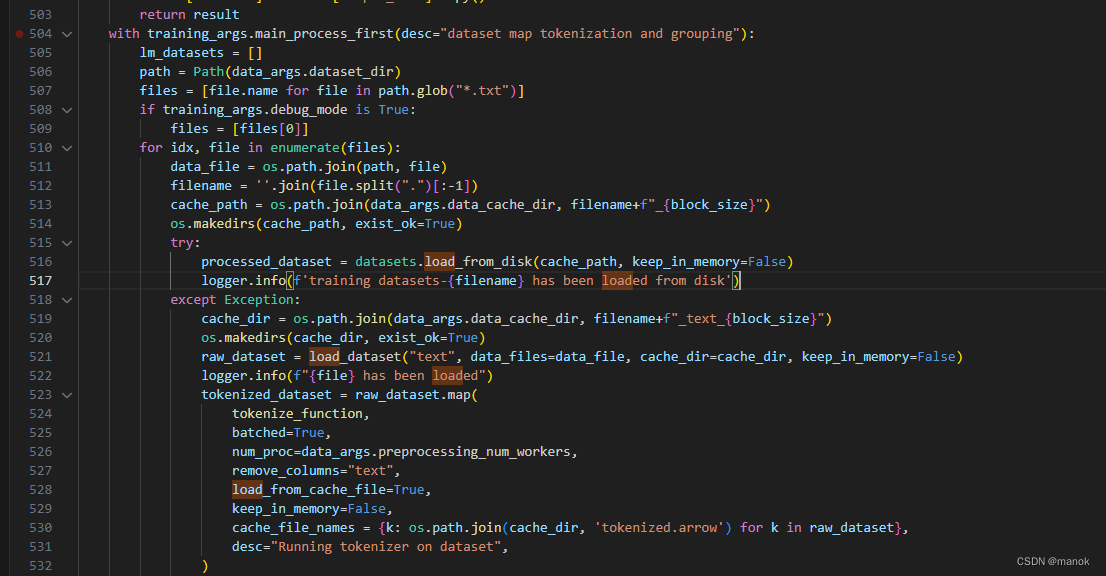
中间也出现过Base64转码的问题,这些在网络上找,总是还会找到解决方案的。所有上述问题都解决后,最后遇到下面问题:
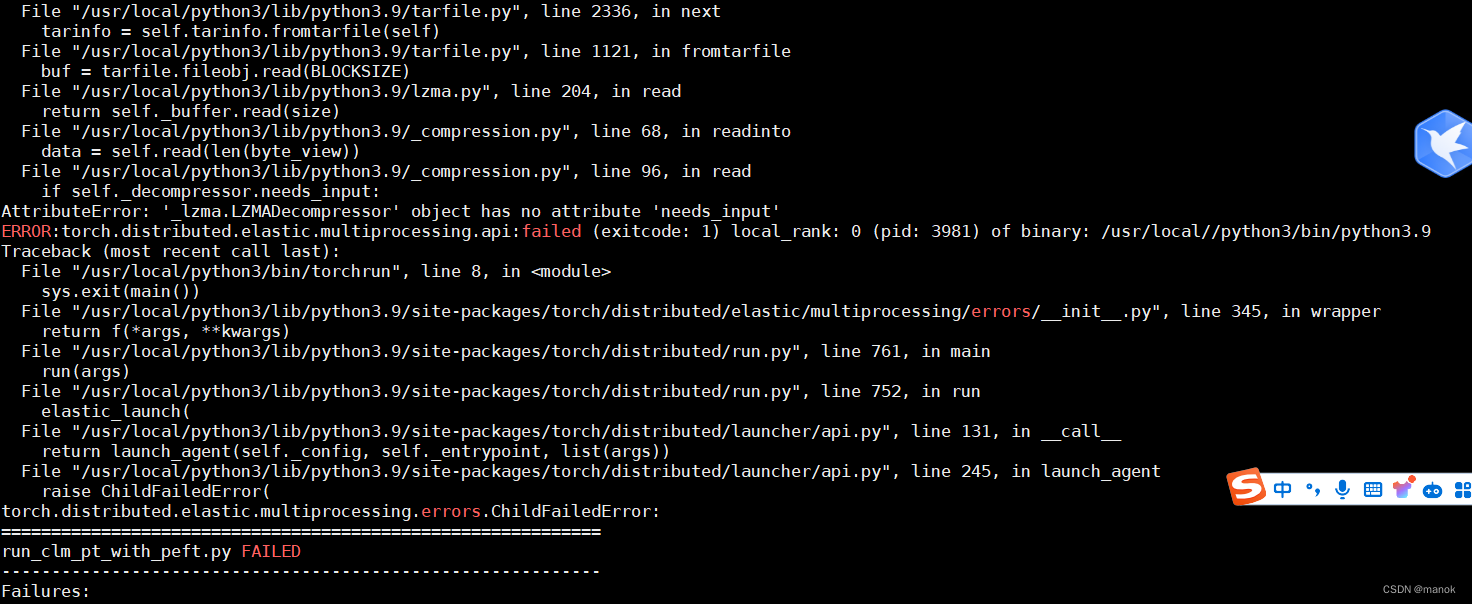
百度了很长时间,也没有找到解决办法。这时候我在阿里租用的服务器,由于忘记节省停机,很快达到了100个小时,每个小时15元左右的计费,着实有点心痛啊,一天下来300多元。加上阿里的服务器也不是太稳定,使用SSH链接最方便操作,上传文件等处理,但是非常不稳定,也只能开一个SSH窗口。
虽然自己训练数据没有最终成功,但是整个流程走了一遍,中间遇到了很多问题,逐一去百度,查找解决办法。有点不太甘心,可能感觉还是国外服务器性价比高一些,国内服务器租赁平台一堆套路,各种计费看也不看不明白,感觉干点啥都要计费。
(结束)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Day14 1047删除相邻字符 150逆波兰表达式求值 239滑动窗口最大值
- 广东省第三届职业技能大赛“网络安全项目”B模块--数字取证解析
- 内地怎么开香港个人户 香港个人户攻略 香港个人户优势
- 如何使用ThinkPHP框架(thinkphp8.0)创建定时任务?
- Leetcod面试经典150题刷题记录 —— 双指针篇
- anocanda 如何安装cx_Oracle实现jupternotebook可访问orcl库进行查询
- AI大模型时代下运维开发探索第二篇:基于大模型(LLM)的数据仓库
- latex的大括号无法显示
- 从第一性原理看大模型Agent技术
- STM32的以太网外设+PHY(LAN8720)使用详解(1):ETH和PHY介绍