ETL项目总结
发布时间:2024年01月06日
ETL项目–自学笔记
1、 项目介绍
E extract 数据抽取(with open() as f f.read())
T transform 清洗转化(if for while)
L load 数据载入(f=open() f.write())
1.1、数据格式的分类(了解即可)
- 结构化数据
- 表数据 有行和列
- 有schema信息 (字段,字段类型)
- 半结构化数据
- json k-v数据结构 xml
- 缺失 类型说明
- 非结构化数据
- 图片(pillow,opencv),音视频(ffmpeg),普通文本(txt,log)
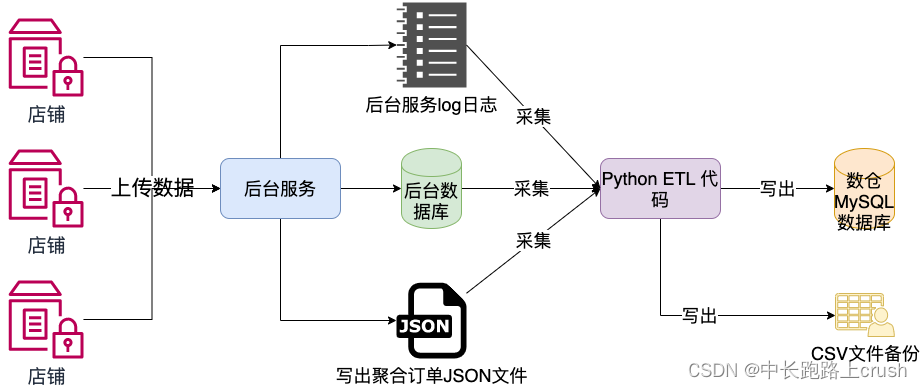
1.2、 数据源(需清楚)
-
订单数据(用户购买商品,通过网络发送到后台的订单信息)
- 存放在JSON文件内
-
商品库的数据(存储了商品信息)
- 存放在后台的MySQL数据库中
-
后台的日志数据(记录了后台的被访问信息)
- 存放在后台的日志文件中
1.3项目搭建(练多自然就知道了)
- config: 记录整个ETL工程的配置信息
- model: 数据的模型
- test: 用来做单元测试
- util: 用来封装工具方法
- app: 开发的应用程序
- logs: 项目运行时的日志
2、工具封装
2.1、config.settings
import logging
from datetime import datetime
# --------------------指定日志的配置信息----------------------
# create logger
# 创建日志对象
logger_name = "XMMC" # log名称
logger = logging.getLogger(logger_name)
logger.setLevel(logging.DEBUG)
# create file handler
base_time = datetime.now().strftime('%Y%m%d%H')
log_goal_path = f"../logs/{logger_name}_{base_time}.log" # log存储位置
fh = logging.FileHandler(log_goal_path, encoding='utf-8')
fh.setLevel(logging.INFO)
# create formatter
# 输出的格式
fmt = "%(asctime)s - [%(levelname)s] - %(filename)s[%(lineno)d]: %(message)s"
formatter = logging.Formatter(fmt)
# add handler and formatter to logger
fh.setFormatter(formatter)
logger.addHandler(fh)
# ---------------- 指定数据yuan目录-----------------
json_source_path = 'C:/***/***/Desktop/ETL/json_data'
# ---------------- 指定保存csv数据目录-----------------
csv_goal_path = 'C:/***/***/Desktop/ETL/csv_data/'
# ----------------指定数据库的配置信息-----------------
mysql_conf = {
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': 'root'
}
2.2、utils.mysql_util
1. 使用类封装,是因为可以使用__init__方法,在创建对象时可以自动创建连接
2. 创建库语句(需要注意:charset=utf8容易忘记)
3. 创建表语句(首先得清晰传进来的是什么数据类型,把之前的SQL建表语句写旁边,就知道是如何拼接k,v的了。)--字典类型,k + '有一个空格' + v +','
4. 插入语句(提到插入语句最先想到的是什么?--得提交。首先得清晰传进来的是什么数据,把SQL建表语句写在一旁)','.join(data_dict.keys()) 【不是字符串【是字符串又是null,NULL【只是字符串】】】
5. 查询语句(where=None) --坑的地方在需要使用self.result = 来获取数据执行结果
优化的点:
- 插入有两个语句 insert into 和replace into ##replace可以根据主键判断,如果源数据修改则目标数据库也修改,解决源数据修改再次插入目标数据库报错的问题
- 每次只将最大的处理时间插入元数据表中,以提高查询效率。
2.3、utils.files_util
1. 获取全部数据
1. 使用for root,dirs,files in os.walk:
2. 获取已经处理的数据(读取元数据库)
1. 先判断im.result是否为空,为空则返回None(后面需要用到)
2. 不为空则 for i im.rseult: list.append(i[1])
3. 获取未处理的数据
1. 先判断old_files(已经处理的数据)是否为空,是则返回全部数据
2. 不为空,则for file in files : if file no in old_files 则添加进未处理数据列表
3、模型类封装
3.1、Barcode模型类封装
class Barcode:
def __init__(self,data):
pass
def create_tb(self,im,db,tb):
pass
def transform(self):
# self.__dict__ 可以获取当前对象下的所有属性和属性值,存在字典中
# 1-将 '',None 转为 字符串的'null'
# 2-将字符串数据的前后空格去除
# 3-将字符串数据特殊字符去除 # @ & ^
for k, v in self.__dict__.items():
if v in ['', None]:
self.__dict__[k] = "null"
else:
if type(v) == str:
v_replace = v.replace(' ', '').replace('#', '').replace('@', '').replace('&', '').replace('^',
'')
if v_replace == '':
self.__dict__[k] ='null'
else:
self.__dict__[k] = v_replace
if k == 'update_at':
self.__dict__[k] = v.strftime('%Y-%m-%d %H:%M:%S')
def insert_data(self, im, db, tb):
pass
def replace_data(self, im, db, tb)
pass
def save_csv(self):
pass
3.2、OrderModel模型类
class OrderModel:
def transform_data(self):
# self.__dict__ 可以获取当前对象下的所有属性和属性值,存在字典中
# 对空值清洗 将字段数据中的 "None","undefined","" 转为 "null"
# 省市区字段 如果先空则改为 未知省份,未知城市 未知区域
# 时间戳处理 `dateTS` `storeCreateDateTS`
# todo 首先我得承认我写错了
# todo 时间戳处理和空值处理都是先总后分
for k, v in self.__dict__.items():
if v in ['None', 'undefined', '']:
# if k in ['store_province','store_address','store_city']:
if k == 'store_province':
self.__dict__[k] = '未知省份'
elif k == 'store_city':
self.__dict__[k] = '未知城市'
elif k == 'store_address':
self.__dict__[k] = '未知地区'
else:
self.__dict__[k] = 'null'
else:
if k in ['date_ts', 'store_create_date_ts']:
# todo 报错object of type 'NoneType' has no len()
# 提到拼接和长度默认就是字符串类型,其他类型都是错误的
# if len(v) == 13:
if len(str(v)) == 13:
self.__dict__[k] = datetime.fromtimestamp(v / 100).strftime('%Y-%m-%d %H:%M:%S')
else:
# todo TypeError: an integer is required (got type NoneType)
self.__dict__[k] = datetime.fromtimestamp(v).strftime('%Y-%m-%d %H:%M:%S')
##和上面一样,这里只写处理方法
4、必错的点
datatime = '2024-1-6'
datatime1 = '"+ datatime + "'
print(datatime1)
datatime2 = " + datatime + "
print(datatime2)
f'{select * from tb where dt = datatime1}'
文章来源:https://blog.csdn.net/weixin_58026490/article/details/135373669
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 腾讯云上mysql连接不上
- Nginx多域名部署多站点
- 3.[BUUCTF HCTF 2018]WarmUp1
- 计算机网络
- C# WPF上位机开发(软件的发布和部署)
- ubuntu 执行apt-get update报错
- Spring Cloud+SpringBoot b2b2c:Java商城实现一件代发设置及多商家直播带货商城 免 费 搭 建
- 人工智能加速迈向全面应用新阶段 | 未来趋势将会如何
- 广州华锐互动:VR元宇宙技术为汽车行业带来革命性变化
- QT第四天