YOLOv5模型训练及检测
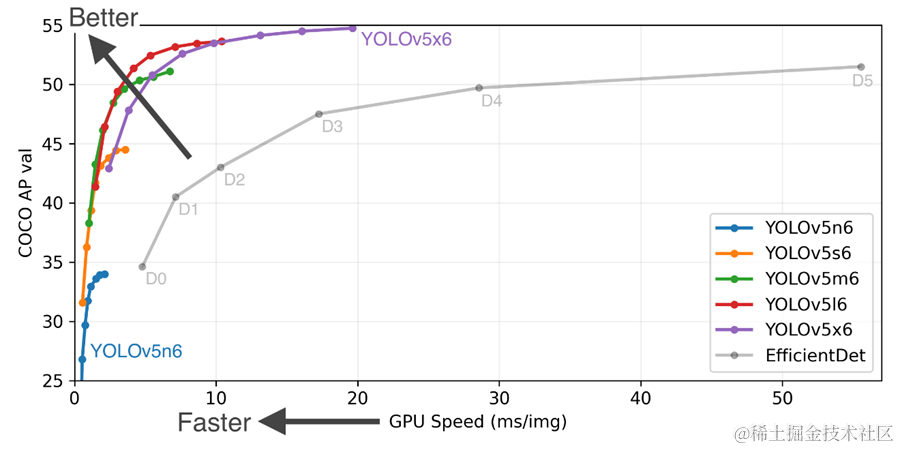
一、为什么使用YOLOv5
二、软件工具
2.1 Anaconda
https://www.anaconda.com/products/individual
2.2 PyCharm
https://www.jetbrains.com/zh-cn/pycharm/download/
2.3 LabelImg
https://github.com/tzutalin/labelImg
三、图片标注
为了训练自己的数据集,需要将自己的图片及要识别的物体进行标注,俗称“打标签”,本文使用LabelImg工具对图像进行标注。
3.1 左侧工具栏

Open Dir:待标注图片数据的路径文件夹
Change Save Dir:保存类别标签的路径文件夹
PascalVOC:标注的标签保存成VOC格式
3.2 上方菜单栏
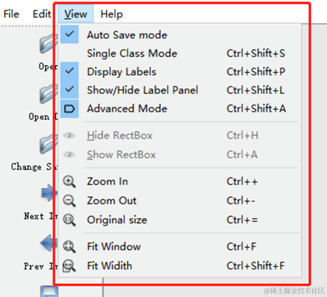
Auto Save mode:当你切换到下一张图片时,就会自动把上一张标注的图片标签自动保存下来,这样就不用每标注一样图片都按Ctrl+S保存一下了
Display Labels:标注好图片之后,会把框和标签都显示出来
Advanced Mode:这样标注的十字架就会一直悬浮在窗口,不用每次标完一个目标,再按一次W快捷键,调出标注的十字架。
3.3 其它快捷键:
W:调出标注的十字架,开始标注
A:切换到上一张图片
D:切换到下一张图片
Ctrl+S:保存标注好的标签
del:删除标注的矩形框
Ctrl+鼠标滚轮:按住Ctrl,然后滚动鼠标滚轮,可以调整标注图片的显示大小
Ctrl+U:选择要标注图片的文件夹
Ctrl+R:选择标注好的label标签存放的文件夹
↑→↓←:移动标注的矩形框的位置
3.4 标注样例

四、环境配置
4.1 打开Anaconda Prompt
在安装好Anaconda之后,Win+S进入搜索框,搜索Anaconda Prompt,打开


4.2 创建PyTorch环境
输入指令:
conda create -n pytorch python=3.9
如出现提示询问“是否”,一律输入y,回车,即可。
其中“pytorch”为该环境名称,可改为任意名称,为方便起见,下文一律使用pytorch作为该环境名
4.3 使用PyTorch环境
输入命令:
conda activate pytorch
4.4 安装PyTorch
在使用pytorch环境后,进入PyTorch官网(PyTorch官网),选择自己电脑相应配置,下图为本机使用配置,可作为参考。注意Compute Platform查看好设备显卡是否支持CUDA以及支持版本。
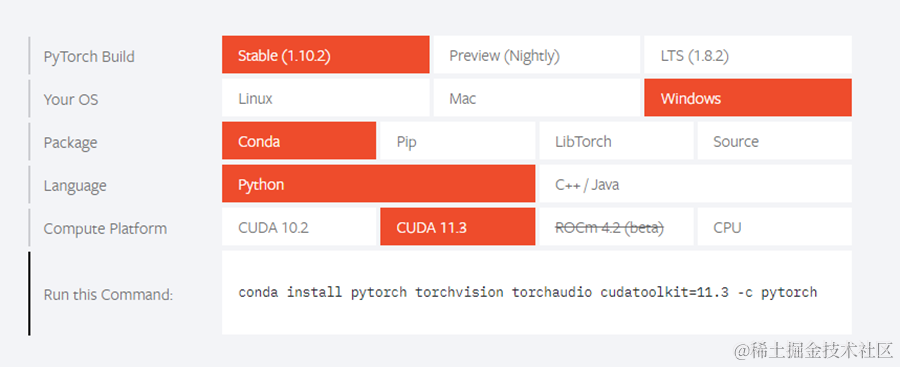
复制Run this Command中的命令到Anaconda Prompt中,回车,即可运行。如询问问题,一律选择y即可。
至此,环境配置安装完成。
五、YOLOv5代码
5.1 代码获取
进入GitHub上官方网页(ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite (github.com)。
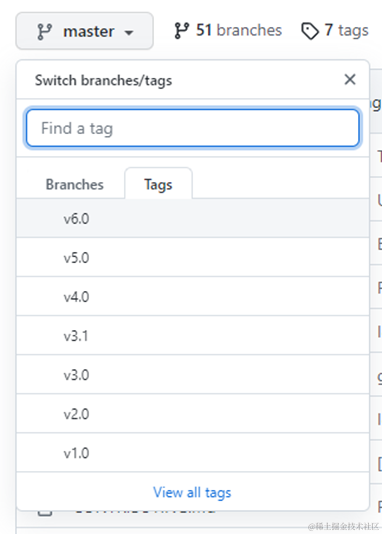
点击左上角分支按钮,点击Tags,可以选择代码版本,本文使用v6.0
右上角点击点击Code → Download ZIP
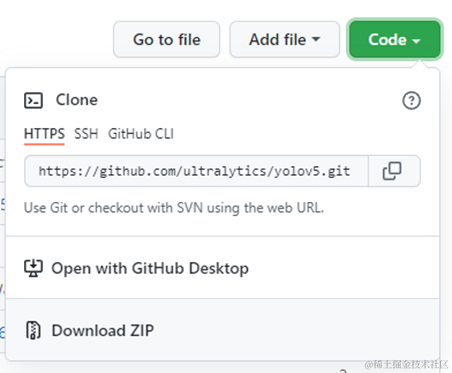
解压后放在想要的项目文件夹中即可。
5.2 打开项目以及环境配置
右键项目文件夹→Open Folder as PyCharm Project
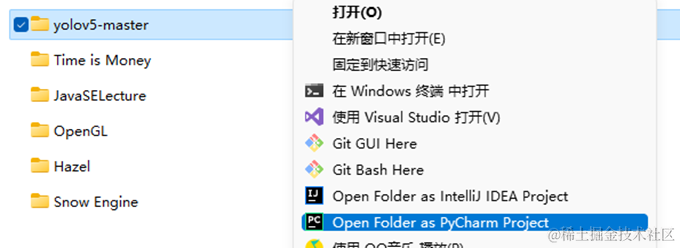
进入PyCharm后,左上角菜单栏选择File→Settings进入设置界面。找到Project:xxxx选项→Python Interpreter,下拉菜单选择环境。
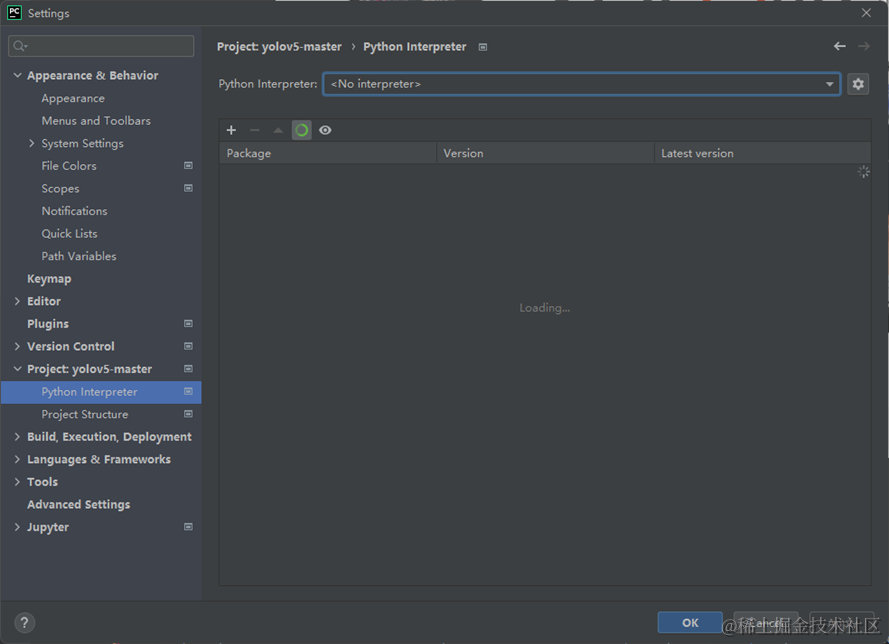
如果没有选项,可以点击右侧齿轮图标,在Conda Environment→Existing environment中找到相应位置,选择编译器。
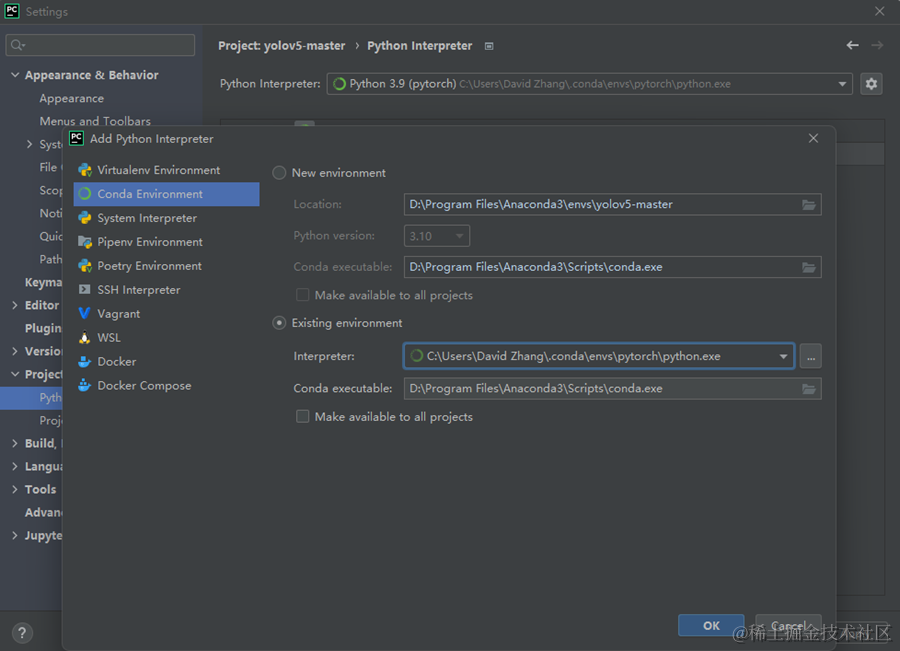
设置好后如图,然后点击Apply。

下方点击Terminal打开命令行窗口,输入指令:
conda activate pytorch
pip install -r requirements.txt

等待安装好所有所需文件即可。
5.3 代码文件
其中主要涉及到的两个文件,一个是train.py用于训练,一个是detect.py用于检测。
5.3.1 train.py
主要需要了解的是451行开始的parse_opt函数,代码如下
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt
epochs:指的就是训练过程中整个数据集将被迭代多少次。
batch-size:一次看完多少张图片才进行权重更新,梯度下降的mini-batch。
cfg:存储模型结构的配置文件
data:存储训练、测试数据的文件
img-size:输入图片宽高。
rect:进行矩形训练
resume:恢复最近保存的模型开始训练
nosave:仅保存最终checkpoint
notest:仅测试最后的epoch
evolve:进化超参数
bucket:gsutil bucket
cache-images:缓存图像以加快训练速度
weights:权重文件路径
name: 重命名results.txt to results_name.txt
device:cuda device, i.e. 0 or 0,1,2,3 or cpu
adam:使用adam优化
multi-scale:多尺度训练,img-size +/- 50%
single-cls:单类别的训练集
5.3.2 detect.py
其中需要了解的是第216行开始的parse_opt函数,代码如下:
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path(s)')
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(FILE.stem, opt)
return opt
weights:训练的权重
source:测试数据,可以是图片/视频路径,也可以是’0’(电脑自带摄像头),也可以是rtsp等视频流
output:网络预测之后的图片/视频的保存路径
img-size:网络输入图片大小
conf-thres:置信度阈值
iou-thres:做nms的iou阈值
device:设置设备
view-img:是否展示预测之后的图片/视频,默认False
save-txt:是否将预测的框坐标以txt文件形式保存,默认False
classes:设置只保留某一部分类别,形如0或者0 2 3
agnostic-nms:进行nms是否也去除不同类别之间的框,默认False
augment:推理的时候进行多尺度,翻转等操作(TTA)推理
update:如果为True,则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息,默认为False
六、训练自定义数据集
6.1 文件夹及数据准备
在项目文件夹中创建dataset文件夹

在dataset文件夹中创建三个文件夹:images,annotations,imagesets

将标注过的图片移入images文件夹
将标注生成的xml文件移入annotations文件夹

在imagesets文件夹中创建main文件夹
在dataset文件夹中创建python代码split_train_val.py:
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='imagesets/main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
注意其中有些目录需要修改为自己计算机上对应目录
运行代码,会在main文件夹中自动生成如下四个文件:

6.2 准备标签文件
在dataset文件夹中新建python代码文件voc_label.py:
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["hat", "no hat"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
#修改自己电脑上对应文件目录
in_file = open('D:/dev/yolov5-master/dataset/annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('D:/dev/yolov5-master/dataset/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
#修改为自己电脑上对应目录
if not os.path.exists('D:/dev/yolov5-master/dataset/labels/'):
os.makedirs('D:/dev/yolov5-master/dataset/labels/')
image_ids = open('D:/dev/yolov5-master/dataset/imagesets/main/%s.txt' % (image_set)).read().strip().split()
list_file = open('D:/dev/yolov5-master/dataset/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '\images%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
注意修改代码中地址为自己计算机文件中地址、修改标签类别为标注的类别
运行后dataset文件夹中会生成labels文件夹,以及三个txt文件:test.txt,train.txt,val.txt,如下图所示:
6.3 创建数据集配置文件
在data文件夹中新建CustomData.yaml:
train: D:\dev\yolov5-master\dataset\train.txt
val: D:\dev\yolov5-master\dataset\val.txt
# number of classes
nc: 2
# class names
names: ['hat', 'no hat']
注意需要修改文件路径、标签类别数量、以及类别名称
6.4 模型配置
在项目目录下的model文件夹下是模型的配置文件,这边提供s、m、l、x版本,逐渐增大(随着架构的增大,训练时间也是逐渐增大),假设采用yolov5s.yaml,只用修改一个参数,把nc改成自己的类别数
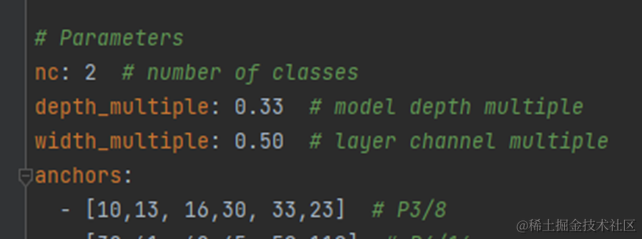
6.5 训练模型
在train.py文件中修改模型配置路径:

其他参数也可根据需要进行修改,具体请翻阅5.3.1 train.py
在命令行中输入编译运行开始训练:
python train.py --img 640 --batch 8 --epoch 200 --data data/CustomData.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt –-device 0
因为本机只有一张显卡,所以device设为0,若有多张显卡,可设为0,1等

6.6 训练结果
最后结果会保存在项目目录下的runs/train文件夹中,如下图:
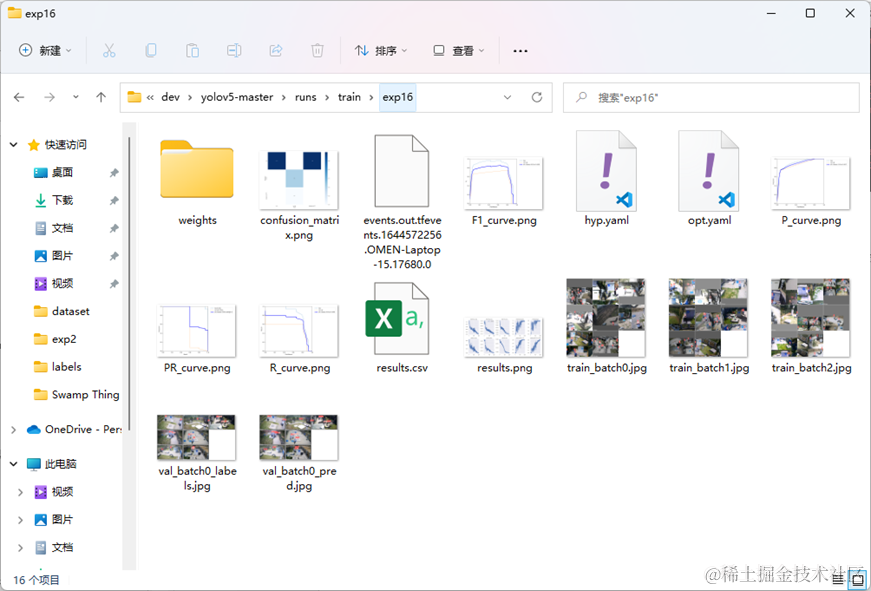
其中权重文件在weights文件夹中,包含best.pt,是效果最好的权重,以及last.pt是最后一次训练的权重。

七、目标识别
下面主要涉及detect.py代码文件
7.1 待检测目标存放
–source可以选择待检测目标的源地址,可以是图片、视频、或者rtps监控视频源等。下以保存在项目目录中data/images文件夹中为例,也就是默认文件夹。

7.2 选择权重文件
权重文件选择刚才训练好的best.pt即可,在–weights中改为刚才训练的best.pt的路径,如图:

7.3 识别
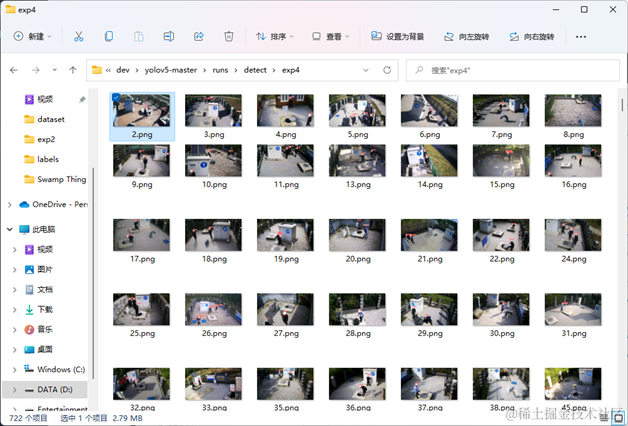
运行detect.py即可,结果默认存放在runs/detect中,如图:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- soso移动营业大厅(纯后端+MySQL数据库+JDBC)
- $.ajax()方法详解
- 【Dubbo】默认hession2反序列化机制导致dubbo接口返回HashMap
- ?人血红素加氧酶1 HO-1 (human), ELISA kit
- Linux第10步_通过终端挂载和卸载U盘
- 数据结构---顺序表
- CMMI、SPCA、CSMM,三种认证的差异有哪些?
- 智慧港口解决方案:PPT全文53页,附下载
- 超低温冰箱,还在人工监测?教你一招完成,超级简单!
- [Kubernetes]7. K8s包管理工具Helm、使用Helm部署mongodb集群(主从数据库集群)