基于MyCat2.0实现MySQL分库分表方案

目录
7.2.1 配置Mycat2原型库的数据源(database)信息
7.2.2 配置 master和slave数据库的数据源信息
一、MyCat概述
Mycat 是基于 java 语言编写的数据库中间件,Java程序与数据库紧密关联耦合严重,高访问量高并发对数据库的压力巨大,因此可以引入数据库中间件MyCat解决。其核心功能是分库分表和读写分离,即将?个大表水平分割为 N 个小表,存储在后端MySQL 服务器里。
Mycat对于我们Java程序员来说,就是?个近似等于 MySQL 的数据库服务器,你可以用连接 MySQL 的方式去连接 Mycat(除了端口不同,默认的Mycat 端口是 8066 而非MySQL 的 3306,因此需要在连接字符串上增加端口信息)。

官网地址:MyCat2
二、MyCat作用
2.1 数据分片
数据分片包括里:垂直分片和水平分片,垂直分片包括:垂直分库和垂直分表,水平分片包括: 水平分库和水平分表。
2.1.1 垂直拆分
2.1.1.1 垂直分库
- 数据库中不同的表对应着不同的业务,垂直切分是指按照业务的不同将表进行分类,分布到不同的数据库上面
- 将数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果
2.1.1.2 垂直分表
表中字段太多且包含大字段的时候,在查询时对数据库的IO、内存会受到影响,同时更新数据时,产生的binlog文件会很大,MySQL在主从同步时也会有延迟的风险。
- 将?个表按照字段分成多表,每个表存储其中?部分字段。
- 对职位表进?垂直拆分, 将职位基本信息放在?张表, 将职位描述信息存放在另?张表
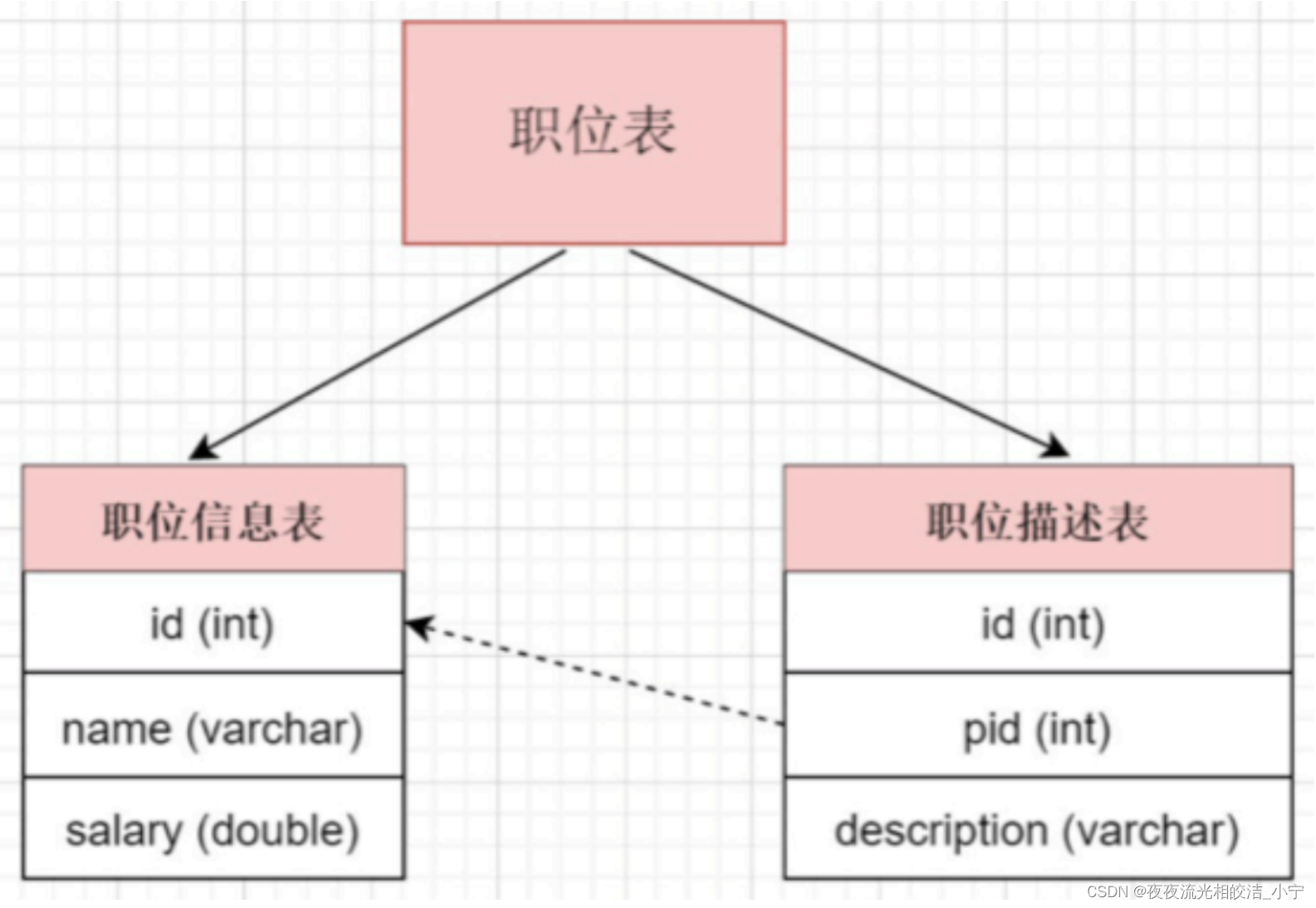
2.1.1.3 总结
垂直拆分带来的?些提升
- 解决业务层面的耦合,业务清晰
- 能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直分库?定程度的提高访问性能
- 垂直拆分没有彻底解决单表数据量过大的问题
2.1.2 水平拆分
2.1.2.1 水平分库
将单张表的数据切分到多个服务器上去,每个服务器具有相应的库表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。

简单讲就是根据表中的数据的逻辑关系,将同?个表中的数据按照某种条件拆分到多台数据库(主机)上面, 例如将订单表 按照id是奇数还是偶数, 分别存储在不同的库中。
2.1.2.2 水平分表
针对数据量巨大的单张表(比如订单表),按照规则把?张表的数据切分到多张表里面去。 但是这些表还是在同?个库中,所以库级别的数据库操作还是有IO瓶颈。

2.1.2.3 总结
- 垂直分表: 将?个表按照字段分成多表,每个表存储其中?部分字段。
- 垂直分库: 根据表的业务不同,分别存放在不同的库中,这些库分别部署在不同的服务器.
- 水平分库: 把?张表的数据按照?定规则,分配到不同的数据库,每?个库只有这张表的部分数据.
- 水平分表: 把?张表的数据按照?定规则,分配到同?个数据库的多张表中,每个表只有这个表的部分数据.
2.2 读写分离
读写分离指的是:主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
注意: 读写分离的数据节点中的数据内容是?致,所以要先搭建主从复制架构

2.3 多数据源整合
Java?程?需要同时控制(连接)多个数据源:
- 业务需要。比如项目里要实现两个DB的双写/数据迁移,或者微服务边界划分不清使得?个工程直连了多个DB。
- 读写分离。大型?点的网站,为了提升DB的吞吐量和性能以及高可用性,数据库?般都会采用集群部署(1个Master+N个Slave模式)。
- NoSQL数据库。使用NOSQL数据库存储大量的?次性非业务数据,比如日志类的数据。

三、MyCat 与ShardingJDBC的区别
在MySql 分库分表技术选型中,主要有MyCat 中间件和ShardingJDBC技术,我们来看下两种技术的区别。
3.1 MyCat
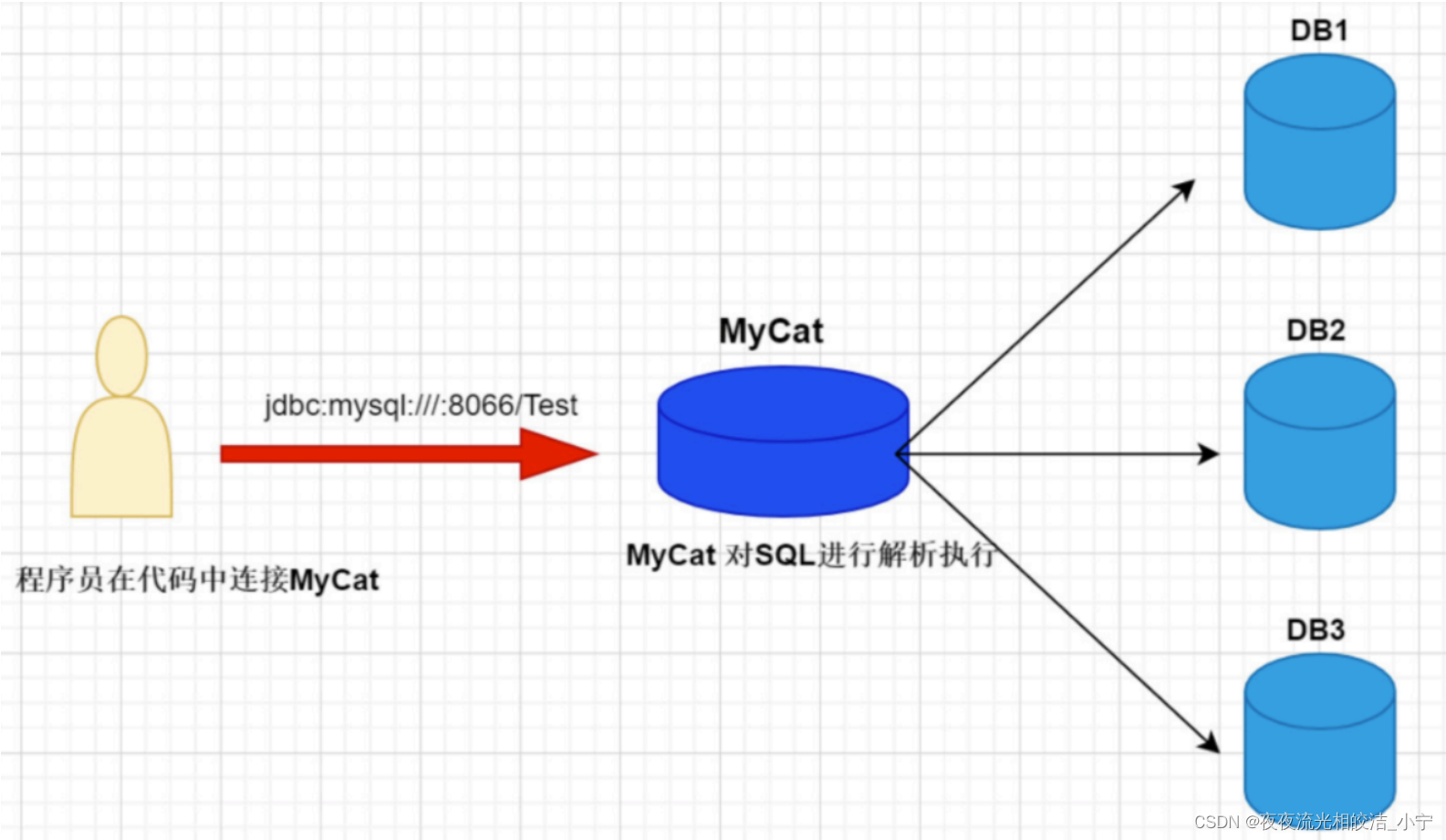
Mycat 是基于 Proxy,它复写了 MySQL 协议,它在程序和数据库之间充当一个代理,它们的关系如下如:
3.2 ShardingJDBC
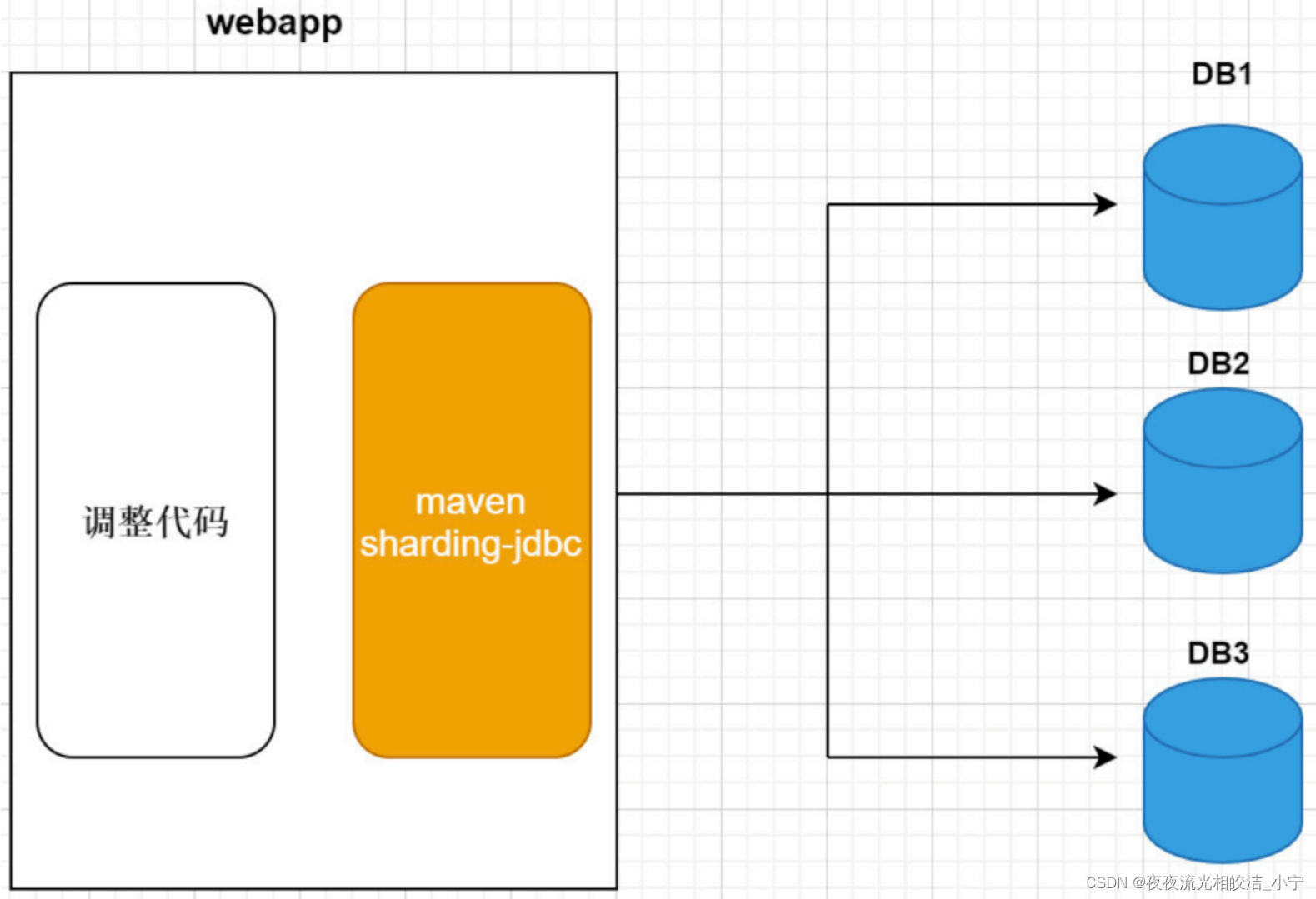
Sharding-JDBC 是基于 JDBC 的扩展,是以 jar包的形式提供轻量级服务的,需要应用程序集成和配置使用,它和应用程序以及数据库之间的关系如下图:
3.3 总结
- mycat是?个中间件的第三方应用,sharding-jdbc是?个jar包
- 使用mycat时不需要修改代码,而使用sharding-jdbc时需要修改代码
- Mycat 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server 伪装成?个 MySQL 数据库,而Sharding-JDBC 是基于 JDBC 的扩展,是以 jar包的形式提供轻量级服务的
四、MyCat2新特性
Mycat1.6版本之后,陷?了?段时间的沉寂。从2021年11底重新推出了新版本Mycat2。
4.1 支持多语句执行
多语句,指的是可以批量执?建表语句。
4.2 支持blob
支持blob,blob二进制?对象。
4.3 支持全局二级索引
用全局二级索引后,能有效减少全表扫描,对于减少连接使用,减少计算节点与存储节点的数据传输有帮助。
4.4 支持跨库Join 查询
支持任意跨库跨表join语句查询。
4.5 支持跨库子查询
支持跨库跨表的关联子查询。
4.6 分库分表统一规划
支持分库同时分表,把分库分表合一,统一规划。
4.7 存储过程增强
存储过程支持多结果集返回、支持接收affectRow。
4.8 持执行计划管理
Mycat2的执行计划管理主要作?是管理执行计划,加快SQL到执行计划的转换。
4.9 自动hash分片算法
由1.6版本的手动配置算法,到2.0的自动hash分片。



五、MyCat2核心概念说明
5.1 分库分表
按照?定规则把数据库中的表拆分为多个带有数据库实例,物理库,物理表访问路径的分表。
分库:按照业务的不通,将相同业务的?类表,放到?个数据库中。比如: ?个电商项目,分为用户库、订单库等等。
分表:一张用户表的数据量达到上千万,处在MySQL单表瓶颈,可以将user表进行水平拆分,拆分到多个数据库中的多张表中,这些表的表结构相同数据不通。

5.2 逻辑库
对数据进行分片处理之后,从原有的一个库,被切分为多个分片数据库,所有的分片数据库集群构成了整个完整的数据库存储。Mycat在操作时,使用逻辑库来代表这个完整的数据库集群,便于对整个集群操作。
5.3 逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。比如我们将订单表t_order 拆分成 t_order_0 到 t_order_9 等 10张表。此时我们会发现分库分表以后数据库中已不在有 t_order 这张表,取而代之的是
t_order_n,但我们在代码中写 SQL依然按 t_order 来写。此时 t_order就是这些拆分表的逻辑表。
5.4 物理库
MySQL中真实存在的数据库。
5.5 物理表
MySQL数据库中真实存在的表。
5.6 分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。
5.7 物理分表
指已经进行数据拆分的,在数据库上面的物理表,是分片表的一个分区,多个物理分表里的数据汇总就是逻辑表的全部数据。
5.8 物理分库
一般指包含多个物理分表的库,数据切分后,一个大表被分到不同的数据库上面,每个表分片所在的数据库就是物理分库。
5.9 单表
没有分片,没有数据冗余的表。即:没有拆分数据,也没有复制数据到别的库的表。
5.10 全局表
一个真实的业务系统中,往往存在大量的类似字典表的表,这些表基本上很少变动,字典表具有以下几个特性:
- 变动不频繁;
- 数据量总体变化不大;
- 数据规模不大,很少有超过数十万条记录。
对于这类的表,在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,所以Mycat 中通过数据冗余来解决这类表的 join,即所有的分片都有一份数据的拷贝,所有将字典表或者符合字典表特性的一些表定义为全局表。数据冗余是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的另外一条重要规则。
5.11 ER表
Mycat提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上,即子表依赖于父表,通过表分组(Table Group)保证数据 join 不会跨库操作。表分组(Table Group)是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的重要一条规则。
5.12 集群
多个数据节点组成的逻辑节点。在Mycat2里,它是把对多个数据源地址视为一个数据源地址(名称),并提供自动故障恢复,转移,即实现高可用,负载均衡的组件。集群就是高可用、负载均衡的代名词。
5.13 数据源
连接后端数据库的组件,它是数据库代理中连接后端数据库的客户端。即:Mycat通过数据源连接MySQL数据库。
5.14 原型库
原型库是Mycat2后面的数据库,比如mysql库。即:原型库就是存储数据的真实数据库,配置数据源时必须指定原型库。
六、Mycat2 核心配置文件
Mycat2作为一个数据库中间件,它所有的功能其实都是通过一些列配置文件定制一系列业务规则,通过与MySQL协作,提供具体的业务功能。所有Mycat2的所有功能都体现在他的配置文件中。服务相关配置文件所在的目录是: mycat/conf

6.1 用户配置
6.1.1 配置说明
配置用户相关信息的目录在: mycat/conf/users
命名方式:{用户名}.user.json
配置内容如下:
{
"dialect":"mysql",
"ip":null,
"password":"123456",
"transactionType":"xa",
"username":"root"
}字段含义:
ip:客户端访问ip,建议为空,填写后会对客户端的ip进行限制
username:用户名
password:密码
isolation:设置初始化的事务隔离级别
READ_UNCOMMITTED :1
READ_COMMITTED :2
REPEATED_READ:3,默认
SERIALIZABLE:4
tractionType:事务类型,可选值, 可以通过语句实现切换。
set transaction policy ='xa'
set transaction.policy ='proxy'
proxy 表示本地事务,在涉及大于1个数据库的事务, commit阶段失败会导致不一致,但是兼容性最好xa事务,需要确认存储节点集群类型是否支持XA。
6.2 数据源配置
配置Mycat连接的数据源信息。
6.2.1 配置说明
所在目录 mycat/conf/datasources
命名方式 {数据源名字} . datasource.json
配置内容如下:
{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"prototypeDs",
"password":"123456",
"type":"JDBC",
"url":"jdbc:mysql://192.168.58.100:3310/mysql?
useUnicode=true&serverTimezone=Asia/Shanghai&characterEnco
ding=UTF-8",
"user":"mycat",
"weight":0
}字段含义:
dbType:数据库类型,mysql
idleTimeout:空闲连接超时时间
initSqls:初始化sql
initSqlsGetConnection:对于jdbc每次获取连接是否都执行initSqls
instanceType:配置实例只读还是读写, 可选值:READ_WRITE,READ,WRITE
maxRetryCount:最大重试次数
name:数据源名称,不要修改
password:密码
type:数据源类型,默认JDBC
url:访问数据库地址
user:用户名
weight:负载均衡权重
6.3 集群配置
6.3.1 配置说明
配置集群信息,所在目录 mycat/conf/clusters
命名方式:{集群名字} . cluster.json
配置内容如下:
{
"clusterType":"MASTER_SLAVE", //主从集群
"heartbeat":{ //?跳检查
"heartbeatTimeout":1000,
"maxRetry":3,
"minSwitchTimeInterval":300,
"slaveThreshold":0
?},
"masters":[
"prototypeDs" //主节点
?],
"maxCon":200,
"name":"prototype", //集群名称
"readBalanceType":"BALANCE_ALL", //负载均衡策略
"switchType":"SWITCH" //表示进?主从切换
}字段含义:
clusterType:集群类型,
可选值:SINGLE_NODE:单?节点;
MASTER_SLAVE:普通主从;
JSTER:garela- cluster/PXC 集群;
MHA: MHA集群;
MGR: MGR集群
readBalanceType:查询负载均衡策略,
可选值:BALANCE_ALL(默认值),获取集群中所有数据源;
BALANCE_ALL_READ,获取集群中允许读的数据源;
BALANCE_READ_WRITE,获取集群中允许读写的数据源,但允许读的数据源优先;
BALANCE_NONE,获取集群中允许写数据源,即主节点中选择
switchType:切换类型
6.4 逻辑库表配置
6.4.1 配置说明
配置逻辑库表,实现分库分表,所在目录 mycat/conf/schemas
命名方式 {库名} . schema.json
配置内容如下:
vim mysql.schema.json
{
?"customTables":{},
?"globalTables":{}, //全局表配置
?"normalProcedures":{},
?"normalTables":{ // MySQL中真实表信息
?"users":{
//建表语句
?"createTableSQL":"CREATE TABLE user_db.users (\n\tid
INT(11) PRIMARY KEY AUTO_INCREMENT,\n\tNAME VARCHAR(20)
DEFAULT NULL,\n\tage INT(11) DEFAULT NULL\n)",
?"locality":{
?"schemaName":"user_db", //物理库
?"tableName":"users", //物理表
?"targetName":"prototype" //指向集群或者数据源
?}
?}
},
?"schemaName":"user_db",?
?"shardingTables":{}, //分?表配置
?"views":{}
}
// 详细分库分表配置,后续的内容会有讲解注意:配置的schema的逻辑库逻辑表必须在原型库(prototype)中有对应的物理库物理表,否则不能启动。
七、MyCat实操
7.1 MyCat 安装
7.1.1 MyCat 环境依赖说明
MyCat 依赖JDK 1.8 ,所以运行MyCat 的机器需要安装JDK 1.8,这里我就不演示如何安装JDK了,不会安装的可自行百度。
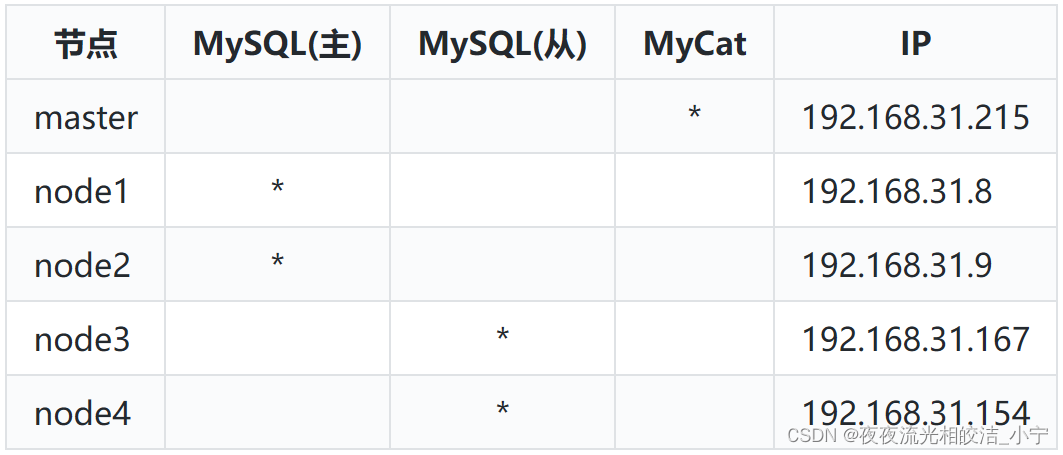
各节点信息如下:
7.1.2 MyCat 安装步骤
Mycat2不提供安装包,只提供核心JAR包,JAR包可以独立运行,安装包是使用Java Service Wrapper做壳的,如果需要安装包,需要自己制作。JAR可以作为Java库引入自己业务项目中使用,Mycat2中的各个组件的设计都是可以独立使用的。
7.1.2.1 下载安装包
zip包地址:http://dl.mycat.io/2.0/install-template/mycat2-install-te
mplate-1.20.zip
jar包地址:http://dl.mycat.io/2.0/1.21-release/mycat2-1.21-release-j
ar-with-dependencies-2022-3-14.jar
7.1.2.2 ?解压包
解压下载下来的zip包, 然后将下载好的jar包放?到 mycat/lib 目录下,如下图:

7.1.2.3 启动MyCat
#进?bin?录
# 查看状态
./mycat status
# 启动
./mycat start
# 停?
./mycat stop
# 重启服务
./mycat restart
# 暂停
./mycat pause7.2 MyCat 实现读写分离(二主二从)
本次基于MySQL 二主二从实现,而且要说明一点,MySQL 二主二从架构,本身就支持读写分离,本身不依赖MyCat实现读写分离机制。在MySQL 二主二从架构中,主数据库读、写,从数据库读,且从数据库会从主数据库中同步数据,实现数据库中数据的一致性。本次关于MySQL 二主二从架构的部署就不做演示,如果不会部署的,可以关注我的博文MYSQL二主二从集群部署-CSDN博客,里面有详细的部署过程。
7.2.1 配置Mycat2原型库的数据源(database)信息
7.2.1.1 创建MyCat 原型库
# 在master1主节点创建mycat数据库,供mycat内部使?,Mycat 在启动时,会?动在原型库下创建其运?时所需的数据表。
CREATE DATABASE mycat CHARACTER SET utf8;
7.2.1.2 配置数据源
#配置原型库的数据源信息prototypeDs.datasource.json
{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"prototypeDs",
"password":"xiaoning",
"type":"JDBC",
"url":"jdbc:mysql://192.168.31.8:3306/mysql?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"root",
"weight":0
}7.2.1.3 创建逻辑库
7.2.1.3.1 登录MyCat
使用连接工具连接登录MyCat ,MyCat 默认的端口是8806,登录的用户名和密码,在mycat/conf/users/root.user.json 里配置。

7.2.1.3.2 创建逻辑库
CREATE DATABASE mydb1 CHARACTER SET utf8;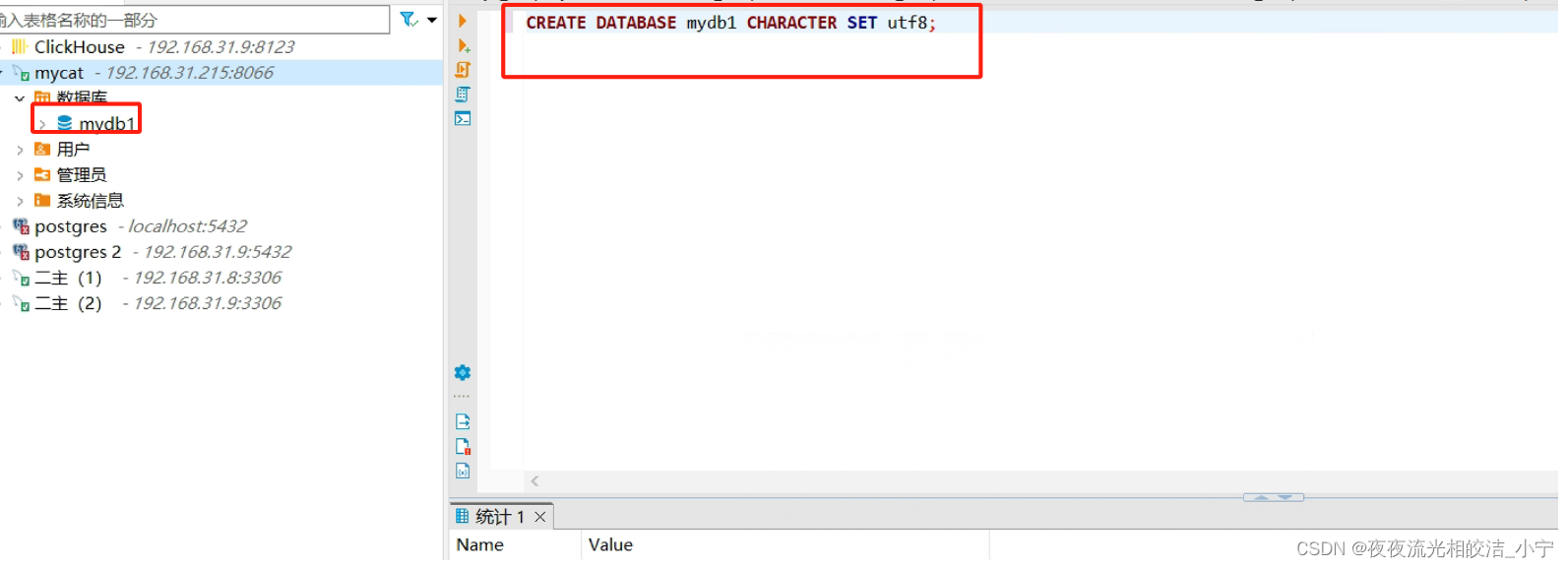
执行创建库语句后,将在/mycat/conf/schemas/自动生成mydb1.schema.json?件

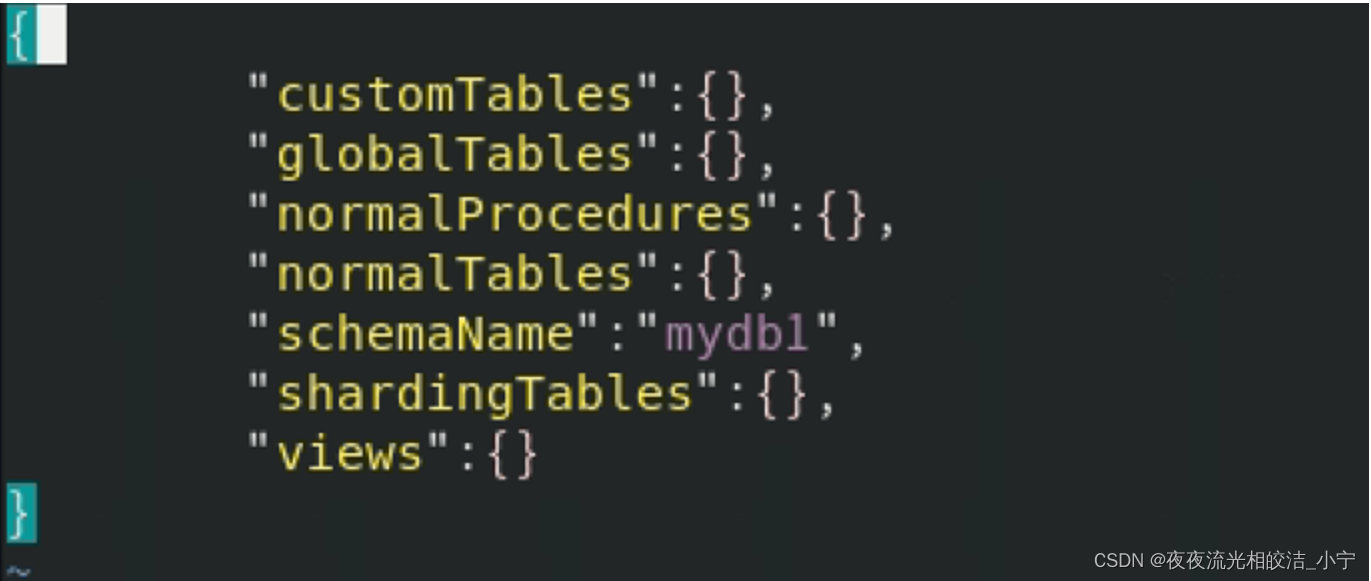
7.2.1.4 修改schema 配置
修改schema的配置,指定mydb逻辑库默认的targetName,mycat会自动加载mydb下已经有的物理表或者视图作为单表。

7.2.1.5 重启MyCat
./mycat restart7.2.2 配置 master和slave数据库的数据源信息
7.2.2.1 基于注解方式配置Master数据源
# 添加Master1数据源
/*+ mycat:createDataSource{
"name":"write1","url":"jdbc:mysql://192.168.31.8:3306/my
db1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true",
"user":"root","password":"xiaoning" } */;
# 添加Master2数据源
/*+ mycat:createDataSource{
"name":"write2","url":"jdbc:mysql://192.168.31.9:3306/my
db1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true",
"user":"root","password":"xiaoning" } */;7.2.2.2 基于注解方式配置Slave数据源
# 添加Slave1数据源
/*+ mycat:createDataSource{
"name":"read1","url":"jdbc:mysql://192.168.31.167:3306/my
db1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true",
"user":"root","password":"xiaoning" } */;
# 添加Slave2数据源
/*+ mycat:createDataSource{
"name":"read2","url":"jdbc:mysql://192.168.31.154:3306/my
db1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true",
"user":"root","password":"xiaoning" } */;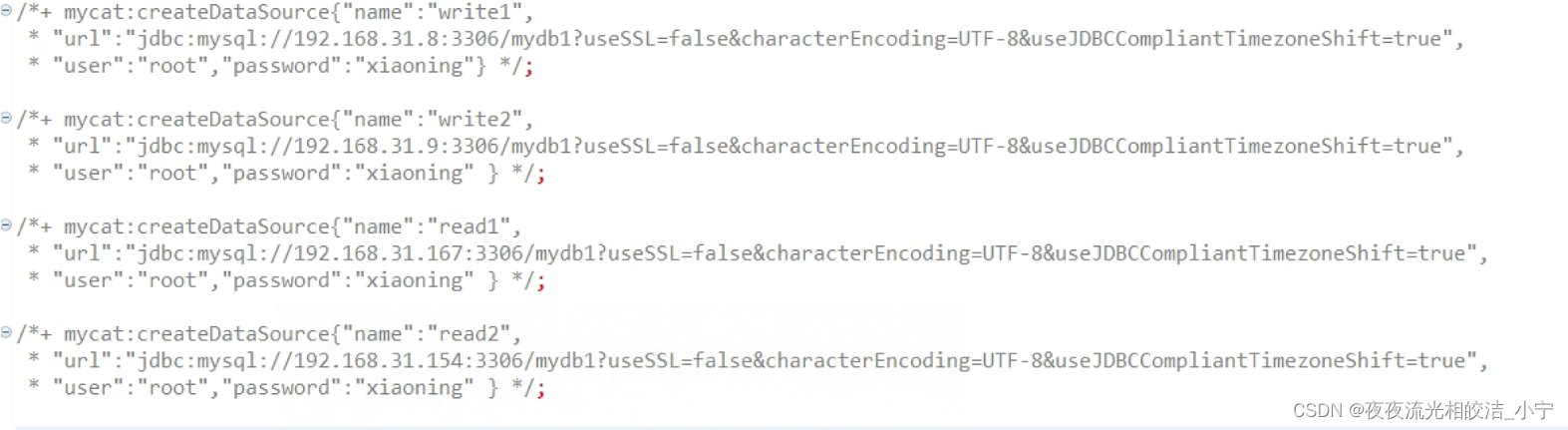
7.2.2.3 查询结果
/*+ mycat:showDataSources{} */;
通过注释命名添加数据源后,在对应目录会生成相关配置文件,查看数据源配置文件:mycat/conf/datasources

7.2.3 配置集群(cluster)信息
7.2.3.1 注解方式配置集群信息
使?mycat?带的默认集群: prototype,对其修改更新
/*! mycat:createCluster{"name":"prototype","masters":
["write1","write2"],"replicas":["read1","read2","write2"]}
*/;
7.2.3.2 查看配置集群信息
/*+ mycat:showClusters{} */;
查看集群配置文件,发现集群配置信息已经更新
vim conf/clusters/prototype.cluster.json
好了,到此基于MyCat中间件实现的二主二从读写分离就配置完成了,下面我们来看下分库分表。
7.3 MyCat 实现分库分表
我们在二中二从读写分离的基础上,实现分库分表方案
7.3.1 Hash算法分库分表
7.3.1.1 运行建表语句进行数据分片
CREATE TABLE mydb1._user (
?? ?id BIGINT primary key AUTO_INCREMENT,
?? ?username VARCHAR(30) DEFAULT NULL,
?? ?age INT,
?? ?type INT
) ENGINE = INNODB DEFAULT CHARSET = utf8?
dbpartition BY mod_hash(type)
tbpartition BY mod_hash( id )?
tbpartitions 1?
dbpartitions 2;- dbpartition:数据库分片规则
- tbpartition :表分片规则
- mod_hash :分片规则
- tbpartitions 1 dbpartitions 2:创建2个库且每个库各创建1个分片表
7.3.1.2 插入数据
INSERT INTO mydb1._user(id,username,age,type)VALUES(1,'mycat1',15,1);
INSERT INTO mydb1._user(id,username,age,type)VALUES(2,'mycat2',20,2);
INSERT INTO mydb1._user(id,username,age,type)VALUES(3,'mycat3',15,1);
INSERT INTO mydb1._user(id,username,age,type)VALUES(4,'mycat4',20,2);7.3.1.3 查看数据库是否分库分表
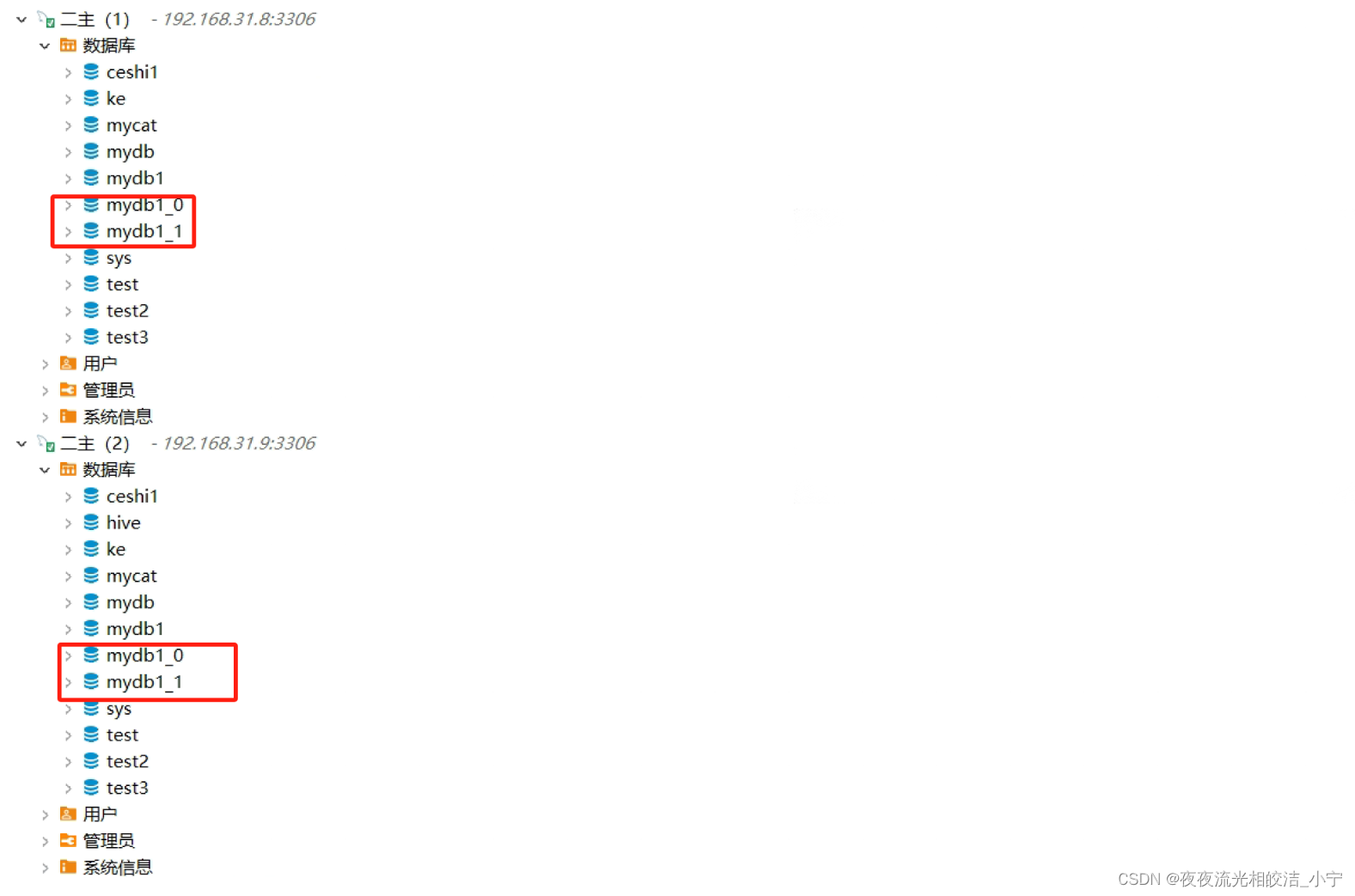


从上图中我们可以看出,创建了两个数据库,分别为mydb1_0、mydb1_1,然后两个库分别建了一个user_0的表,通过分别查询这两个表数据,我们可以看出,主键为1、3的数据,存储在mydb1_1库下的user_0表中,主键为2、4的数据,存储在mydb1_0的user_0表中,实现了数据的分片存储。
7.3.1.4 分片算法 mod_hash说明
- 当分库键和分表键是不同键:
分表下标= 分片值%分表数量
分库下标= 分片值%分库数量- 当分库键和分表键是同一个键:
分表下标=分片值%(分库数量*分表数量)
分库下标=分表下标/分表数量我们使用 `mod_hash`分片规则,分库键和分表键是不同键,所以
- 分表下标:`1%1=0;2%1=0;3%1=0;4%1=0;`
- 分库下标:`1%2=1; 2%2=0;`
7.3.2 基于ER表实现分库分表
- Mycat提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上,即子表依赖于父表,通过表分组(Table Group)保证数据 join 不会跨库操作。
- 表分组(Table Group)是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的重要一条规则。
7.3.2.1 创建ER关系表
mycat2无需指定ER表,是自动识别的,具体看分片算法的接口
CREATE TABLE mydb1._user_wx (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
nickname VARCHAR(30) DEFAULT NULL,
user_id INT
) ENGINE = INNODB DEFAULT CHARSET = utf8
dbpartition BY mod_hash(id)
tbpartition BY mod_hash(user_id)
tbpartitions 1
dbpartitions 2;7.3.2.2 插入数据
INSERT INTO mydb1._user_wx(id,nickname,user_id) VALUES(1,'幸福生活',1);
INSERT INTO mydb1._user_wx(id,nickname,user_id) VALUES(2,'风和日丽',2);
INSERT INTO mydb1._user_wx(id,nickname,user_id) VALUES(3,'雄鹰展翅',3);
INSERT INTO mydb1._user_wx(id,nickname,user_id) VALUES(4,'出水芙蓉',4);7.3.2.3 查看配置的表是否具有ER关系
/*+ mycat:showErGroup{}*/
group_id表示相同的组,该组中的表具有相同的存储分布,即可以关联查询。
7.3.2.4 关联查询
SELECT * FROM mydb1._user mu INNER JOIN mydb1._user_wx muw ON mu.id=muw.user_id;
7.3.3 实现广播表
一个真实的业务系统中,往往存在大量的类似字典表的表,这些表基本上很少变动,具体回头看全局表解析部分。
7.3.3.1 创建广播表
CREATE TABLE mydb1.t_district ?(
? id BIGINT(20) PRIMARY KEY COMMENT '区域ID',
? district_name VARCHAR(100) COMMENT '区域名称',
? LEVEL INT COMMENT '等级'
)ENGINE=InnoDB DEFAULT CHARSET=utf8 BROADCAST;7.3.3.2 查看schema配置
查看schema配置,看是否自动生成广播表配置信息。
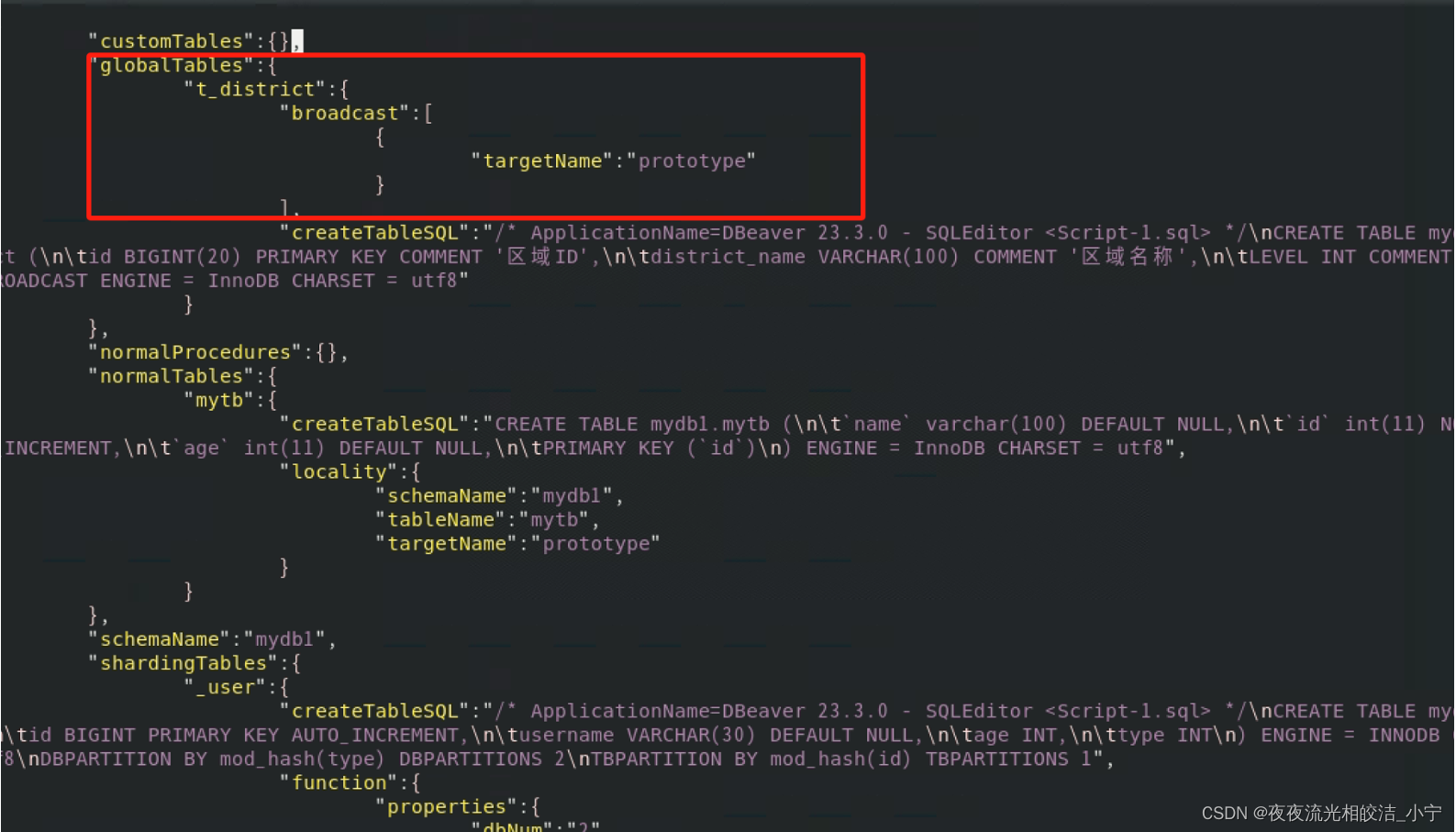
通过查看,发现已经自动生成了广播表配置信息。
7.3.3.3 插入数据,测试广播表
insert into mydb1.t_district values(2,'海淀区',1);测试广播表,在MyCat中插入数据,然后分区去对应的广播表查看是否插入成功

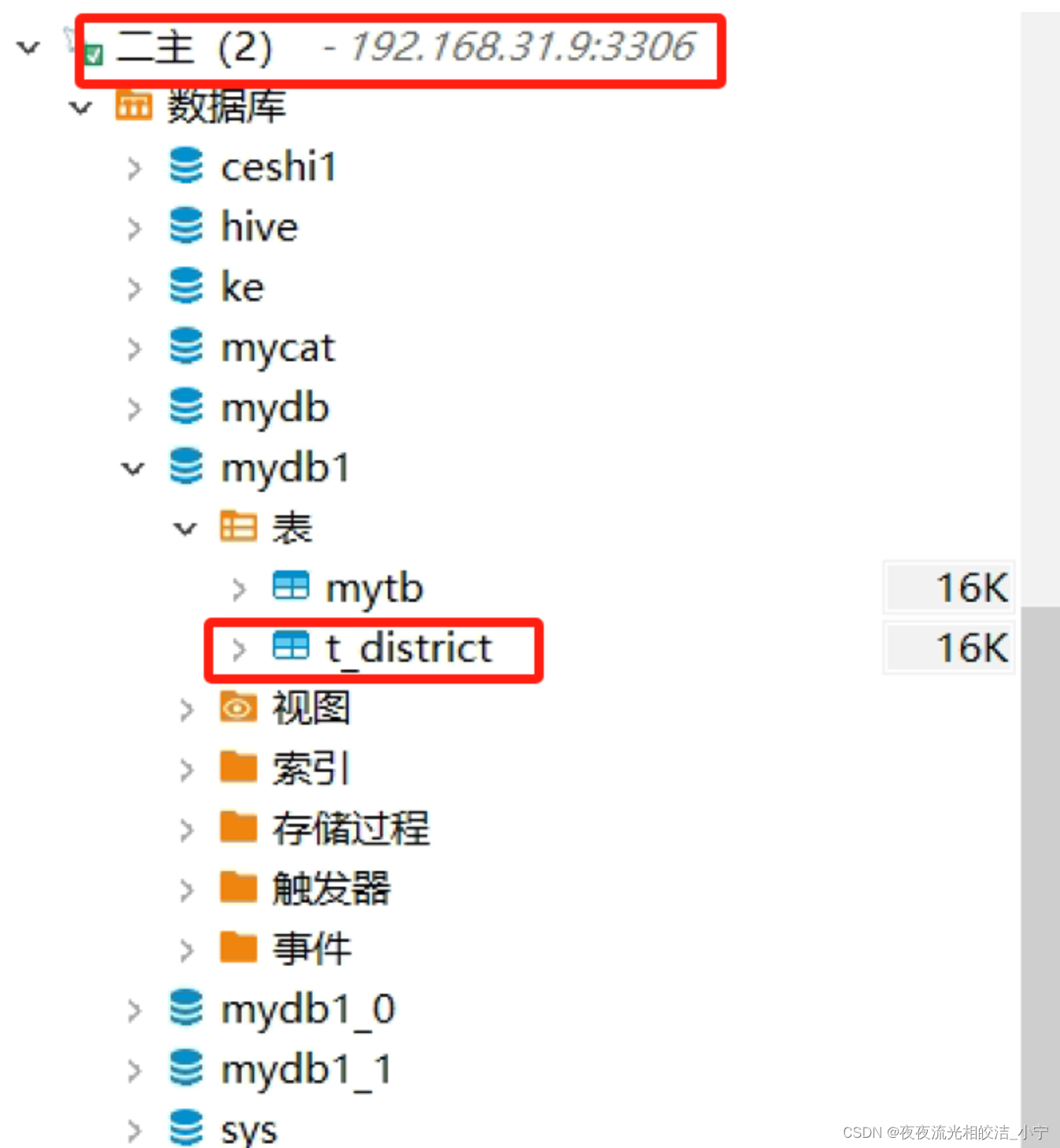
同过查询Mysql 数据库,我们发现各分区库中都存在了字典数据表。
7.3.4 常用的分片规则
7.3.4.1 分片算法介绍
MyCat2支持常用的(自动)HASH型分片算法也兼容1.6的内置的(cobar)分片算法.
HASH型分片算法默认要求集群名字以c为前缀,数字为后缀, c0就是分片表第一个节点, c1就是第二个节点。该命名规则允许用户手动改变。
7.3.4.2 分片规则与适用性

7.3.4.3 常用分片规则介绍
参考官网文档地址:MOD_HASH (yuque.com)
7.3.4.3.1 MOD_HASH
如果分片值是字符串则先对字符串进行hash转换为数值类型
1.分库键和分表键是同1个键
分表下标=分片值%(分库数量*分表数量)
分库下标=分表下标/分表数量2.分库键和分表键是不同键
分表下标= 分片值%分表数量
分库下标= 分片值%分库数量本文的7.3.1 章节,就是基于Hash 取模算法实现的分库分表
7.3.4.3.2 RANGE_HASH
- 仅支持数值类型,字符串类型,分片值右移二进制位数,然后按分片数量取余
- 当字符串类型时候,第三个参数生效,根据下标截取其后部分字符串(截取下标不能少于实际值的长度),然后该字符串hash成数值
- 两个字段的数值类型要求一致
# 语法样例
create table travelrecord(
...
)ENGINE=InnoDB DEFAULT CHARSET=utf8?
dbpartition by RANGE_HASH(id,user_id,3) dbpartitions 3
tbpartition by RANGE_HASH(id,user_id,3) tbpartitions 3;7.3.4.3.3 RIGHT_SHIFT
- 仅支持数值类型
- 分片值右移二进制位数,然后按分片数量取余
# 语法样例
create table travelrecord(?
?...
)ENGINE=InnoDB DEFAULT CHARSET=utf8?
dbpartition by RIGHT_SHIFT(id,4) dbpartitions 3
tbpartition by RIGHT_SHIFT(user_id,4) tbpartitions 3;7.3.4.3.4 YYYYDD
# 语法样例,仅用于分库,DD是一年之中的天数,(YYYY*366+DD)%分库数
create table travelrecord (
?....
) ENGINE=InnoDB DEFAULT CHARSET=utf8?
dbpartition by YYYYMM(xxx) dbpartitions 8
tbpartition by xxx(xxx) tbpartitions 12;7.3.4.3.5 YYYYMM
# 语法样例,仅用于分库,MM是1-12,(YYYY*12+MM)%分库数
create table travelrecord (
?....
) ENGINE=InnoDB DEFAULT CHARSET=utf8?
dbpartition by YYYYMM(xxx) dbpartitions 8
tbpartition by xxx(xx) tbpartitions 12;7.3.4.3.6 MMDD
# 语法样例,仅用于分表,仅DATE/DATETIME适用,一年之中第几天%分表数,tbpartitions 不超过 366
create table travelrecord (
?....
) ENGINE=InnoDB DEFAULT CHARSET=utf8?
dbpartition by xxx(xx) dbpartitions 8
tbpartition by MMDD(xx) tbpartitions 366;好了,本次分享就到这里,如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 服务器启动出现问题时,该如何处理?
- Redis学习指南(3)-Redis的应用领域
- 电商社群引流裂变直播实战营
- 喜讯!无垠智能模糊测试系统入选“2023软件供应链优秀成果”
- 蓝凌EIS智慧协同平台 多处SQL注入漏洞复现
- 8 种网络协议
- (每日持续更新)信息系统项目管理(第四版)(高级项目管理)考试重点整理第1章 信息化发展(三)
- LeetCode Hot100 138.随机链表的复制
- 利用Stream流将取到的对象List<对象>形式数据进行分组统计转变成Map<分组条件,数量统计>形式
- 网站服务常用中间件-日志文件存放目录&IIS&Apache&Tomcat&Nginx&Weblogic&Jboss